




01-prometheus
prometheus
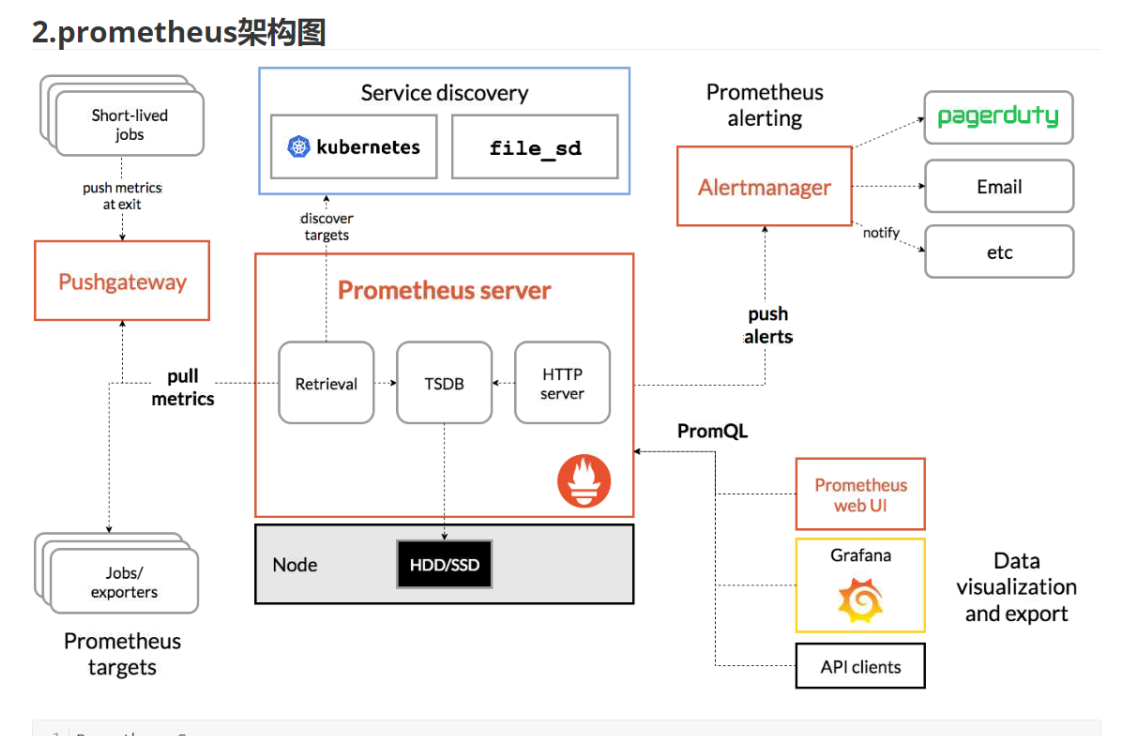
使用prometheus监控Linux主机:
1.部署prometheus server:
[root@k8s151 ~]# docker run -d --network host --restart always --name prometheus_server prom/prometheus:v2.37.0
启动之后再查看暴露的端口
[root@k8s151 ~]# docker history prom/prometheus:v2.37.0
IMAGE CREATED CREATED BY SIZE
<missing> 9 months ago /bin/sh -c #(nop) EXPOSE 9090 0B
2.部署node exporter:
node exporter是监控linux结点的一个服务,还有别的类型的exporter根据自己的需要进行选择即可
# 这个是部署在被监控端的服务器上。想要被prometheus监控就必须部署exporter。
[root@k8s152 ~]# docker run -d --network host --restart always --name node-exporter prom/node-exporter:v1.3.1
查看他的配置
[root@k8s152 ~]# docker history prom/node-exporter:v1.3.1
IMAGE CREATED CREATED BY SIZE
<missing> 16 months ago /bin/sh -c #(nop) EXPOSE 9100 0B
3.修改prometheus server的配置文件
[root@k8s151 ~]# docker exec -it prometheus_server sh
/prometheus $ vi /etc/prometheus/prometheus.yml
global: # 通用配置。
scrape_interval: 5s # 指定抓取数据的间隔时间为5秒,默认是1分钟。
evaluation_interval: 15s # 间隔多长时间去检查规则,默认是1分钟。
# 抓取数据的配置
scrape_configs:
- job_name: "prometheus" # 指定job的名称,会打上一个标签job="prometheus"。
# metrics_path defaults to '/metrics'
# scheme defaults to 'http'.
static_configs: # 静态配置
- targets: ["localhost:9090"] # 指定要监控的目标,默认的协议是http,默认的metrics_path是'/metrics'.
# 注意格式
- job_name: "oldboyedu-linux82-nodes"
static_configs: # 配置被监控端
- targets: ["10.0.0.152:9100"]
4.重启服务
[root@k8s151 ~]# docker restart prometheus_server
prometheus_server
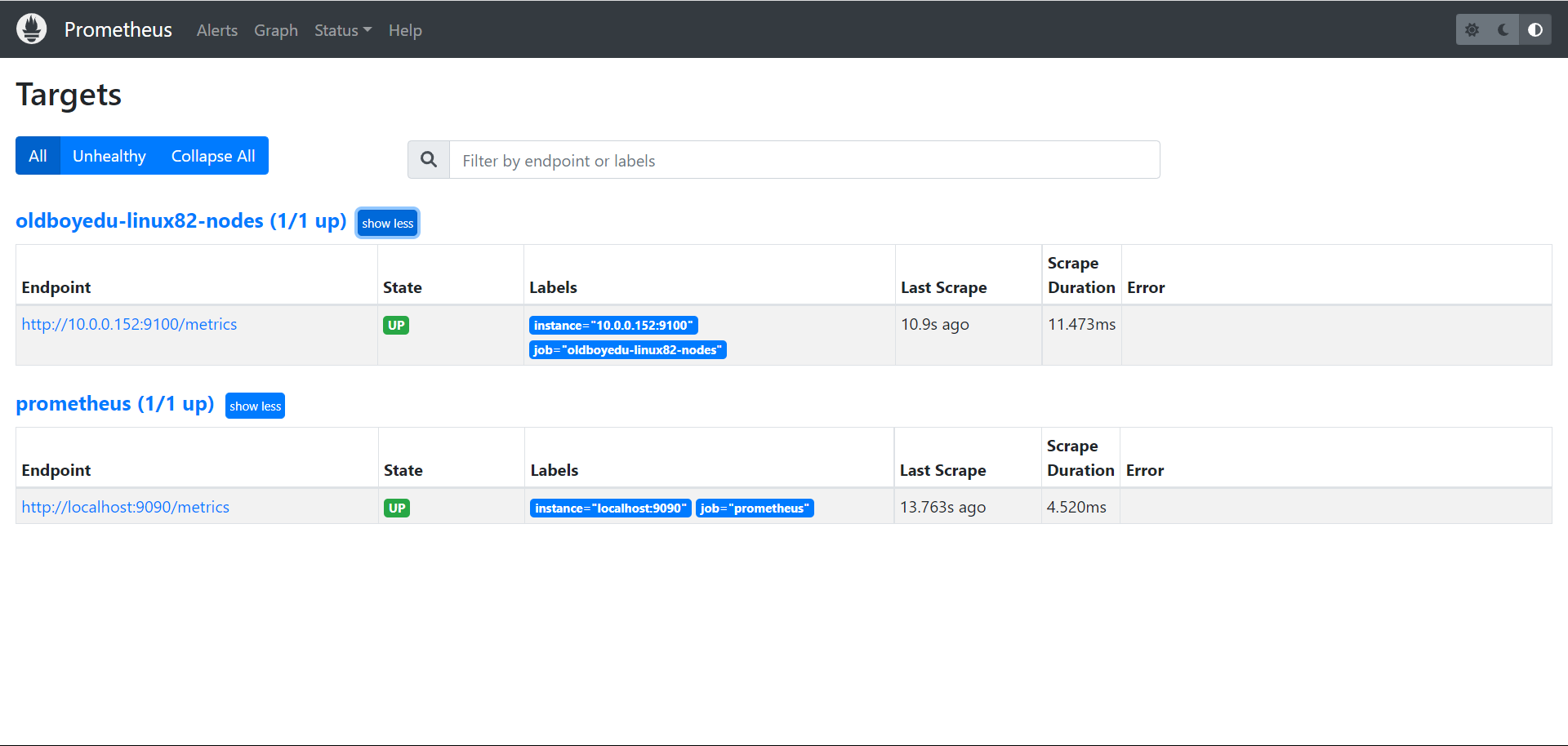
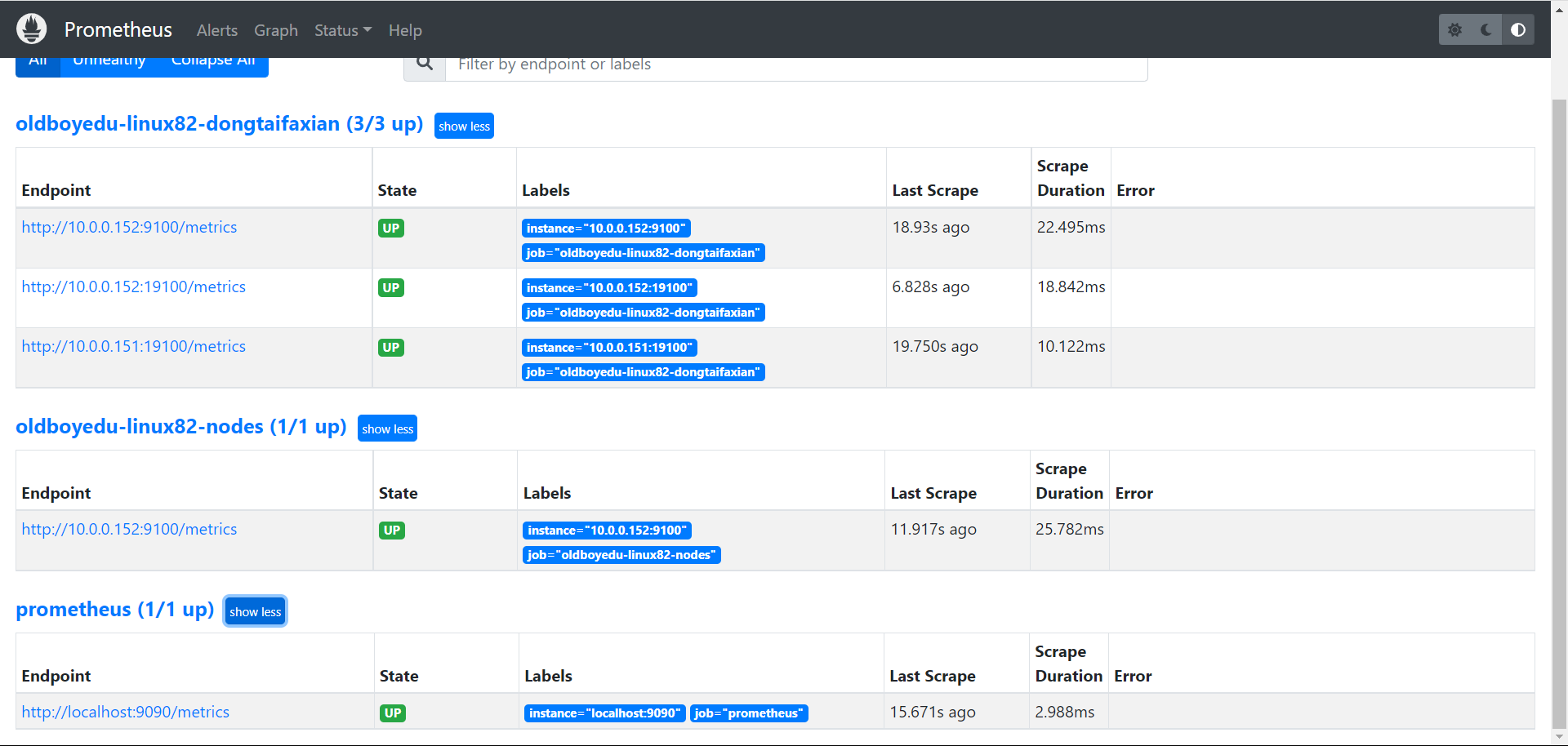
5.查看节点是否被监控
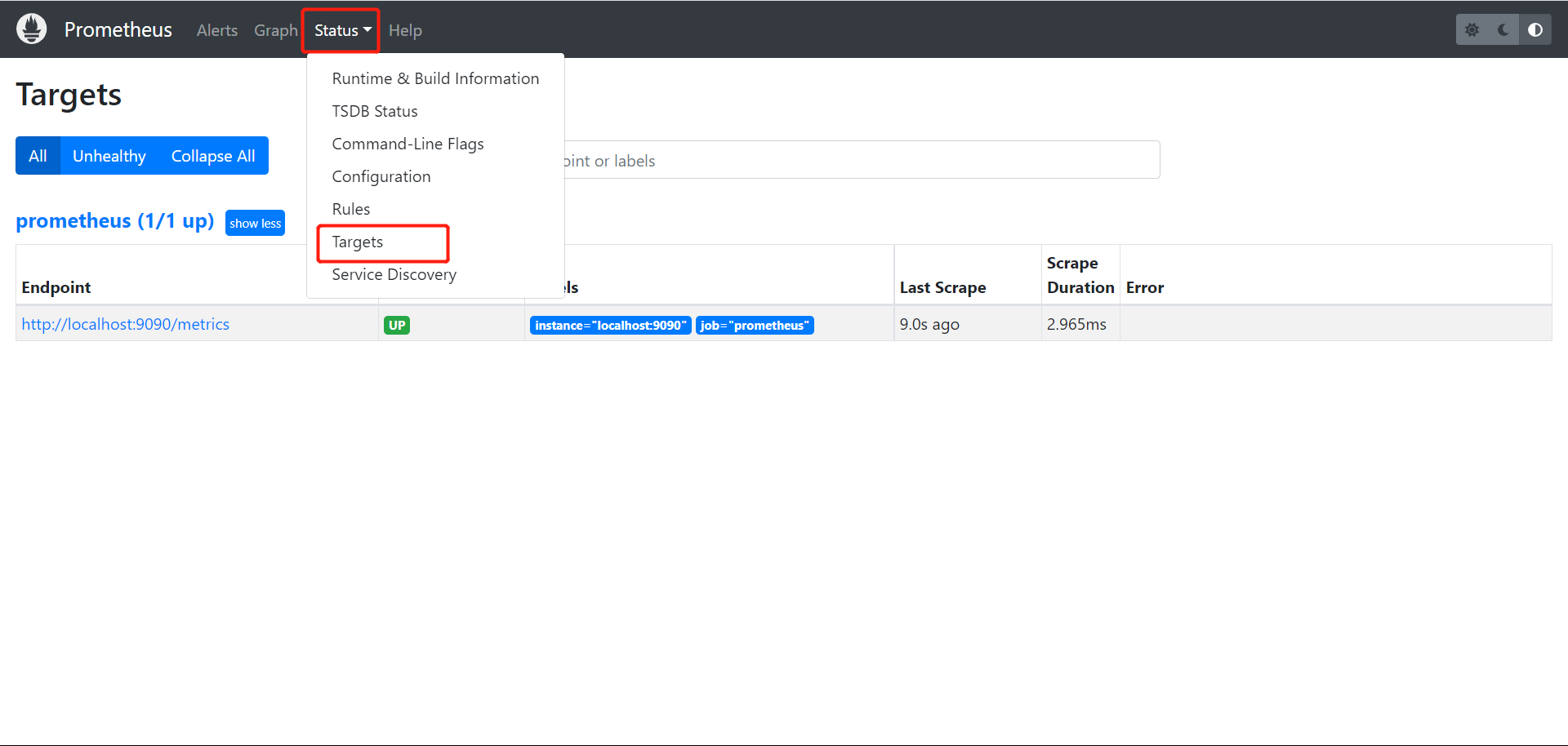
5.1 验证监控目标
Status ---> Targets
5.2 验证数据
node_cpu_seconds_total
配置服务的动态发现(基于二进制部署,不建议使用官方的镜像,有问题!)
1.基于二进制的方式部署prometheus服务端
[root@k8s151 ~]# wget http://192.168.11.253/Docker/day06-/softwares/prometheus-2.36.0.linux-amd64.tar.gz
[root@k8s151 ~]# mkdir /oldboyedu/softwares/prometheus
[root@k8s151 ~]# tar xf prometheus-2.36.0.linux-amd64.tar.gz -C /oldboyedu/softwares/prometheus
2.编写配置文件
[root@k8s151 ~]# vim /oldboyedu/softwares/prometheus/prometheus-2.36.0.linux-amd64/prometheus.yml
...
scrape_configs:
- job_name: "prometheus"
static_configs:
- targets: ["localhost:9090"]
- job_name: "oldboyedu-linux82-nodes"
static_configs:
- targets: ["10.0.0.152:9100"]
- job_name: "oldboyedu-linux82-dongtaifaxian"
file_sd_configs:
- files:
- /tmp/linux82.yml
3.启动node
# 想要监控哪个结点就部署在哪个结点
[root@k8s151 ]# docker run -dp 19100:9100 --restart unless-stopped -v "/:/host:ro,rslave" --name=node_exporter prom/node-exporter:v1.3.1 --path.rootfs /host
[root@k8s152 ~]# docker run -dp 19100:9100 --restart unless-stopped -v "/:/host:ro,rslave" --name=node_exporter prom/node-exporter:v1.3.1 --path.rootfs /host
4.动态服务发现脚本
[root@k8s151 prometheus-2.36.0.linux-amd64]# cat > /tmp/linux82.yml <<EOF
> [
> {
> "targets": ["10.0.0.152:9100","10.0.0.151:19100","10.0.0.152:19100"]
> }
> ]
> EOF
5.启动服务
[root@k8s151 prometheus-2.36.0.linux-amd64]# ./prometheus
6.查看webUI
PromQL语句
1.prometheus metrics type
prometheus监控中采集过来的数据统一称为Metrics数据,其并不是代表具体的数据格式,而是一种统计度量计算单位。
当我们需要为某个系统或者某个服务做监控是,就需要使用到metrics。
prometheus支持的metrics包括但不限于以下几种数据类型:
guage: *****
最简单的度量指标,只是一个简单的返回值,或者叫瞬时状态。
比如说统计硬盘,内存等使用情况。
couter: *****
就是一个计数器,从数据量0开始累积计算,在理想情况下,只能是永远的增长,不会降低(有特殊情况,比如粉丝量)。
比如统计1小时,1天,1周,1一个月的用户访问量,这就是一个累加的操作。
histograms:
是统计数据的分布情况,比如最小值,最大值,中间值,中位数等,代表的是一种近似百分比估算数值。
通过histograms可以分别统计处在一个时间段(1s,2s,5s,10s)内nginx访问用户的响应时间。
summary:
summary是histograms的扩展类型,主要弥补histograms不足。
2.初识PromQL
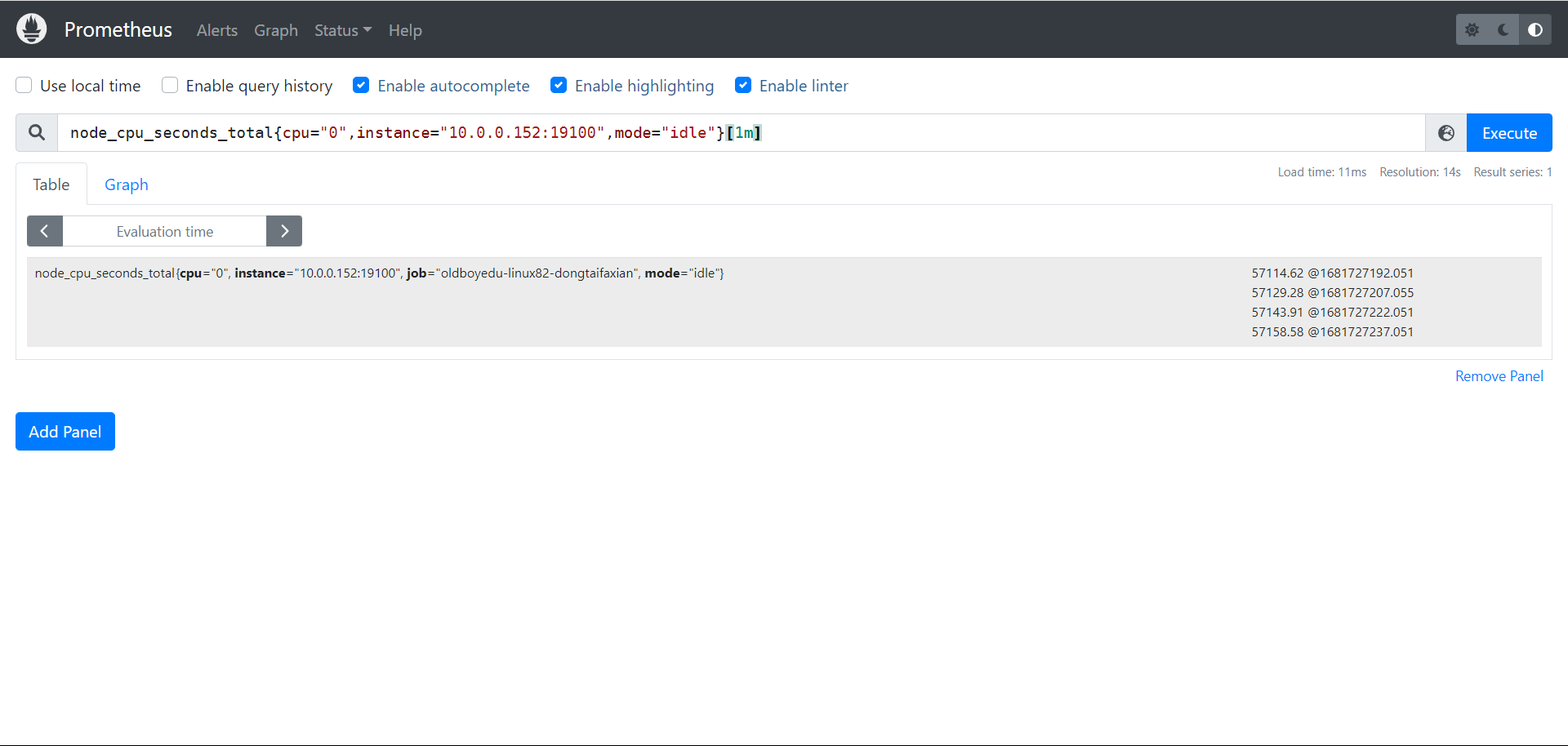
node_cpu_seconds_total{mode="idle",cpu="0", instance="10.0.0.102:9100"}
使用标签过滤器查看"10.0.0.102:9100"节点的第0颗CPU,空闲状态使用的总时间。
node_cpu_seconds_total{mode="idle",cpu="0", instance="10.0.0.102:9100"}[1m]
统计1分钟内,使用标签过滤器查看"10.0.0.102:9100"节点的第0颗CPU,空闲状态使用的总时间。
node_cpu_seconds_total{mode!="idle",cpu="0", instance="10.0.0.102:9100"}[1m]
统计1分钟内,使用标签过滤器查看"10.0.0.102:9100"节点的第0颗CPU,非空闲状态使用的总时间。
node_cpu_seconds_total{mode=~"i.*",cpu="0", instance="10.0.0.102:9100"}[1m]
统计1分钟内,使用标签过滤器查看"10.0.0.102:9100"节点的第0颗CPU,mode名称以字母"i"开头的所有CPU核心。
node_cpu_seconds_total{mode!~"i.*",cpu="0", instance="10.0.0.102:9100"}[1m]
统计1分钟内,使用标签过滤器查看"10.0.0.102:9100"节点的第0颗CPU,mode名称不是以字母"i"开头的所有CPU核心。
CPU讲解
计算机组成部分:
- 输入设备
- 输出设备
- 控制器
- CPU
一台电脑中:
只有一个CPU。
CPU ---> 多个应用程序。
QQ , 微信, LOL
10ns 10ns 10ns
10ns 10ns 10ns
10ns 10ns 10ns
---> CPU
1秒 ---> 1000000 ns ----> 10ns ---> 100000
---> cpu时间分片。
0.5秒 --->
1秒---》眨一次眼睛, CPU切换了10w次。
--->
1 --->
QQ ---> 10ns + 10ns +10ns ....
微信 ---> 10ns + 10ns +10ns ....
空闲状态 ---> 10ns + 10ns +10ns ....
----> id , user ,system, iowait , ....
Prometheus常用的函数
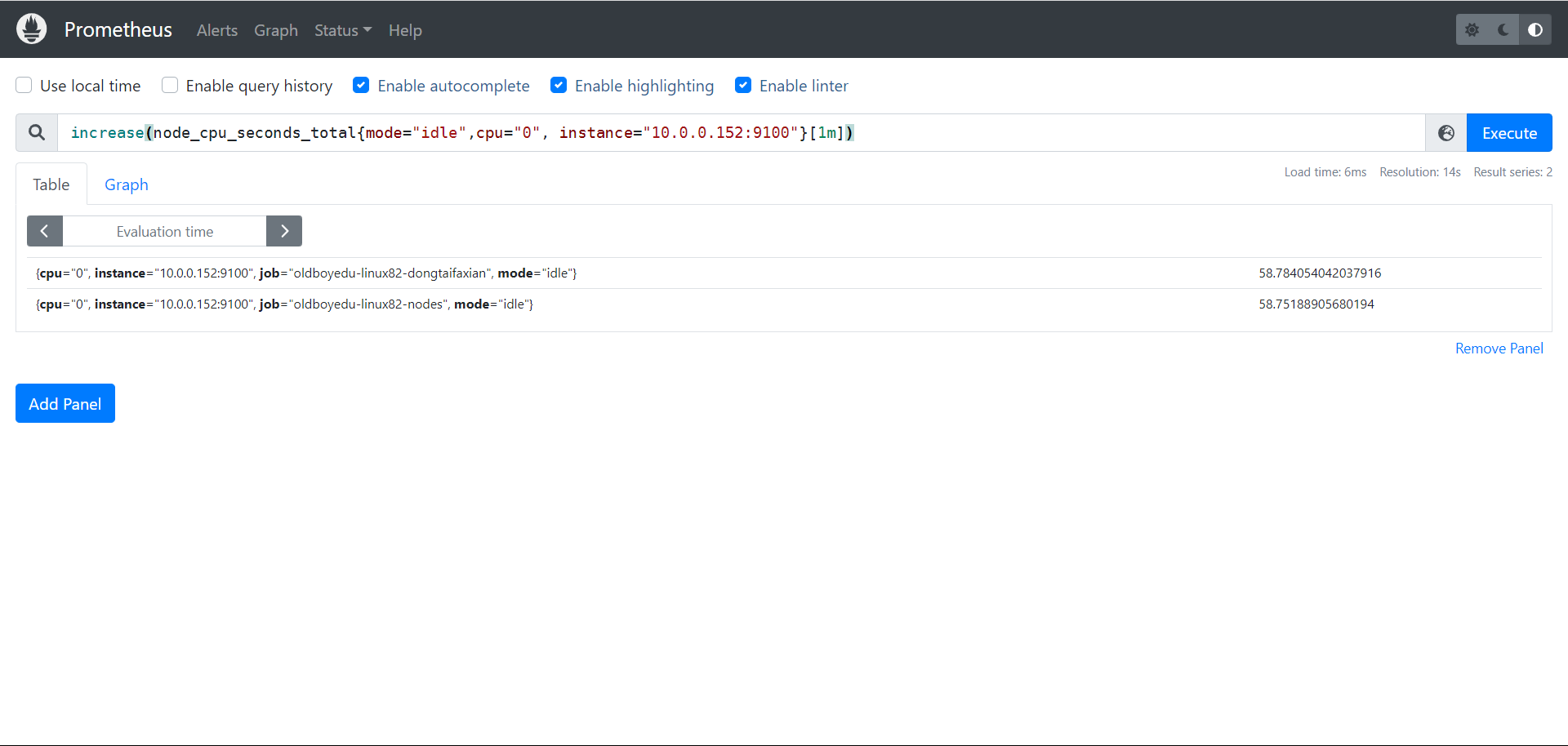
increase
increase函数:
用来针对counter数据类型,截取其中一段时间总的增量。
举个例子:
increase(node_cpu_seconds_total{mode="idle",cpu="0", instance="10.0.0.152:9100"}[1m])
统计1分钟内,使用标签过滤器查看"10.0.0.102:9100"节点的第0颗CPU,空闲状态使用的总时间增量。
一分钟内cpu空闲世界为58秒,58秒都在闲着
sum
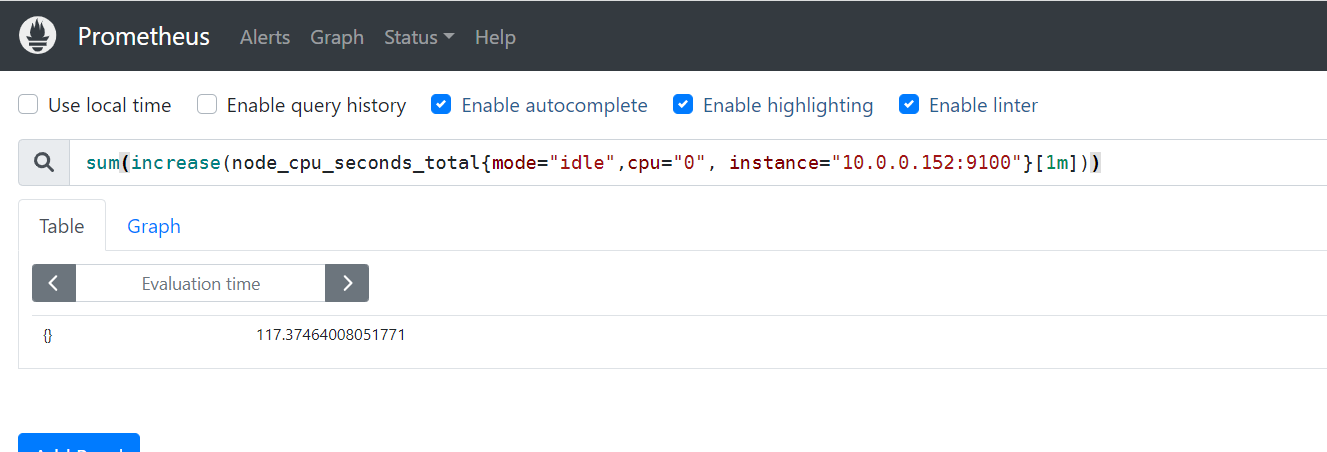
sum函数:
加和的作用。
举个例子:
sum(increase(node_cpu_seconds_total{mode="idle",cpu="0", instance="10.0.0.152:9100"}[1m]))
统计1分钟内,使用标签过滤器查看"10.0.0.102:9100"节点的第0颗CPU,空闲状态使用的总时间增量,并将返回结果累加。
把这两个空闲的值相加等于117秒
by
by函数:
将数据进行分组,类似于MySQL的"GROUP BY"。
举个例子:
sum(increase(node_cpu_seconds_total{mode="idle",cpu="0"}[1m])) by (instance)
统计1分钟内,使用标签过滤器查看第0颗CPU空闲状态,并将结果进行累加,基于instance进行分组。
根据instance进行分组,查看cpu一分钟的空闲相加的值

rate
rate函数:
它的功能是按照设置的时间段,取counter在这个时间段中平均每秒的增量。
举个例子:
rate(node_cpu_seconds_total{mode="idle",cpu="0", instance="10.0.0.152:9100"}[1m])
统计1分钟内,使用标签过滤器查看"10.0.0.102:9100"节点的第0颗CPU,空闲状态使用的每秒的增量。
increase和rate如何选择:
(1)对于采集数据频率较低的场景建议使用increase函数,因为使用rate函数可能会出现断点,比如针对硬盘容量监控。
(2)对于采集数据频率较高的场景建议使用rate函数,比如针对CPU,内存,网络流量等都是可以基于rate函数来采集等。
就是做了一个空闲值的百分比
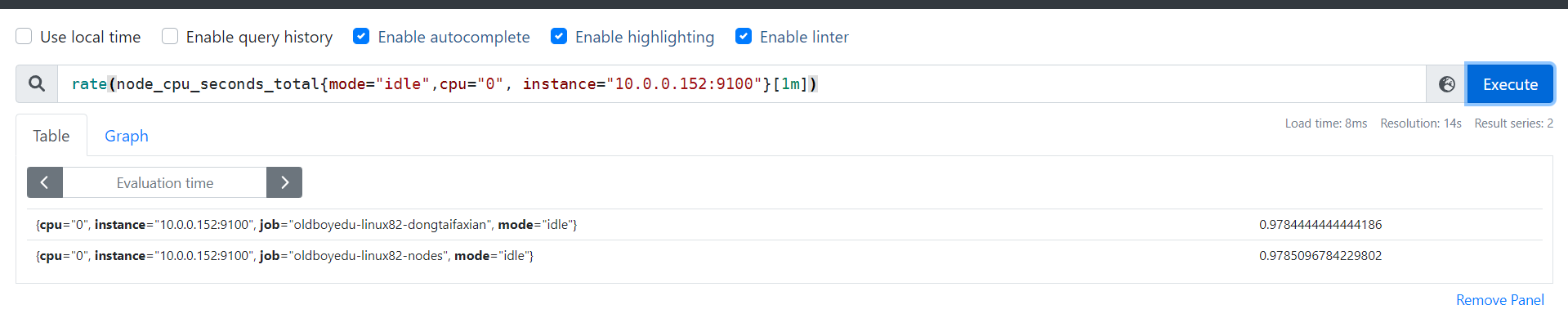
topk
topk函数:
取前几位的最高值,实际使用的时候一般会用该函数进行瞬时报警,而不是为了观察曲线图。
举个例子:
topk(3, rate(node_cpu_seconds_total{mode="idle",cpu="0"}[1m]))
统计1分钟内,使用标签过滤器查看第0颗CPU,空闲状态使用的每秒的增量,只查看前3个节点。
查看前三个空闲的结点
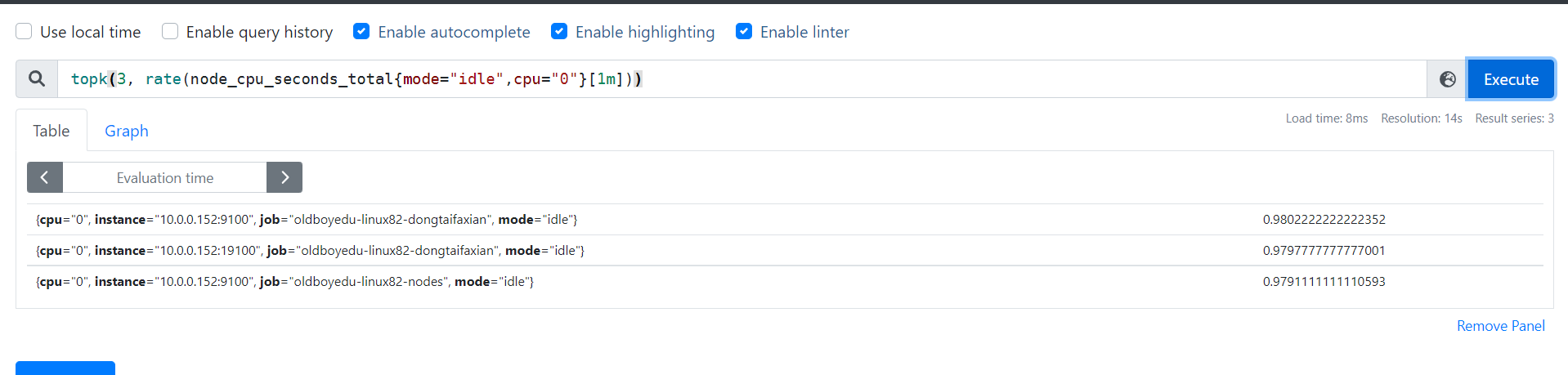
count
count函数:
把数值符合条件的,输出数目进行累加加和,一般用它进行一些某户的监控判断。
比如说企业中有100台服务器,如果只有10台服务器CPU使用率高于80%时候是不需要报警的,但是数量操作70台时就需要报警了。
举个例子:
count(oldboyedu_tcp_wait_conn > 500):
假设oldboyedu_tcp_wait_conn是咱们自定义的KEY。
整改成果一大部分去啊吧TCP等待数量大于500的机器数量。
其他函数
推荐阅读:
https://prometheus.io/docs/prometheus/latest/querying/functions/
监控CPU的使用情况案例
统计各个节点CPU的使用率
(1)我们需要先找到CPU相关的KEY
node_cpu_seconds_total
(2)过滤出CPU的空闲时间({mode='idle'})和全部CPU的时间('{}')
node_cpu_seconds_total{mode='idle'}
过滤CPU的空闲时间。
node_cpu_seconds_total{}
此处的'{}'可以不写,因为里面没有任何参数,代表获取CPU的所有状态时间。
(3)统计1分钟内CPU的增量时间
increase(node_cpu_seconds_total{mode='idle'}[1m])
统计1分钟内CPU空闲状态的增量。
increase(node_cpu_seconds_total[1m])
统计1分钟内CPU所有状态的增量。
(4)将结果进行加和统计
sum(increase(node_cpu_seconds_total{mode='idle'}[1m]))
将1分钟内所有CPU空闲时间的增量进行加和计算。
sum(increase(node_cpu_seconds_total[1m]))
将1分钟内所有CPU空闲时间的增量进行加和计算。
(5)按照不同节点进行分组
sum(increase(node_cpu_seconds_total{mode='idle'}[1m])) by (instance)
将1分钟内所有CPU空闲时间的增量进行加和计算,并按照机器实例进行分组。
sum(increase(node_cpu_seconds_total[1m])) by (instance)
将1分钟内所有CPU空闲时间的增量进行加和计算,并按照机器实例进行分组。
(6)计算1分钟内CPU空闲时间的百分比
sum(increase(node_cpu_seconds_total{mode='idle'}[1m])) by (instance) / sum(increase(node_cpu_seconds_total[1m])) by (instance)
(7)统计1分钟内CPU的使用率,计算公式: (1 - CPU空闲时间的百分比) * 100%。
(1 - sum(increase(node_cpu_seconds_total{mode='idle'}[1m])) by (instance) / sum(increase(node_cpu_seconds_total[1m])) by (instance)) * 100
(8)统计1小时内CPU的使用率,计算公式: (1 - CPU空闲时间的百分比) * 100%。
(1 - sum(increase(node_cpu_seconds_total{mode='idle'}[1h])) by (instance) / sum(increase(node_cpu_seconds_total[1h])) by (instance)) * 100
计算CPU用户态的1分钟内百分比
(sum(increase(node_cpu_seconds_total{mode='user'}[1m])) by (instance) / sum(increase(node_cpu_seconds_total[1m])) by (instance)) * 100
温馨提示:
可以使用stress命令来进行压测CPU,即执行"stress -c 2 -v"命令即可。
计算CPU内核态的1分钟内百分比
(sum(increase(node_cpu_seconds_total{mode='system'}[1m])) by (instance) / sum(increase(node_cpu_seconds_total[1m])) by (instance)) * 100
计算CPU IO等待时间的1分钟内百分比
(sum(increase(node_cpu_seconds_total{mode='iowait'}[1m])) by (instance) / sum(increase(node_cpu_seconds_total[1m])) by (instance)) * 100
通过top指令查看CPU
请自行对比咱们的数据和Linux系统的top命令数据是否有太大的差距。
使用Grafana展示数据
安装grafana
这里我们选择使用容器的方式运行
(1)基于rpm方式安装
wget https://dl.grafana.com/enterprise/release/grafana-enterprise-8.5.4-1.x86_64.rpm
sudo yum install grafana-enterprise-8.5.4-1.x86_64.rpm
(2)基于docker方式部署
docker run -d --name=grafana -p 3000:3000 grafana/grafana-enterprise
账号:admin
密码:admin
参考链接:
https://grafana.com/grafana/download
选择添加数据源
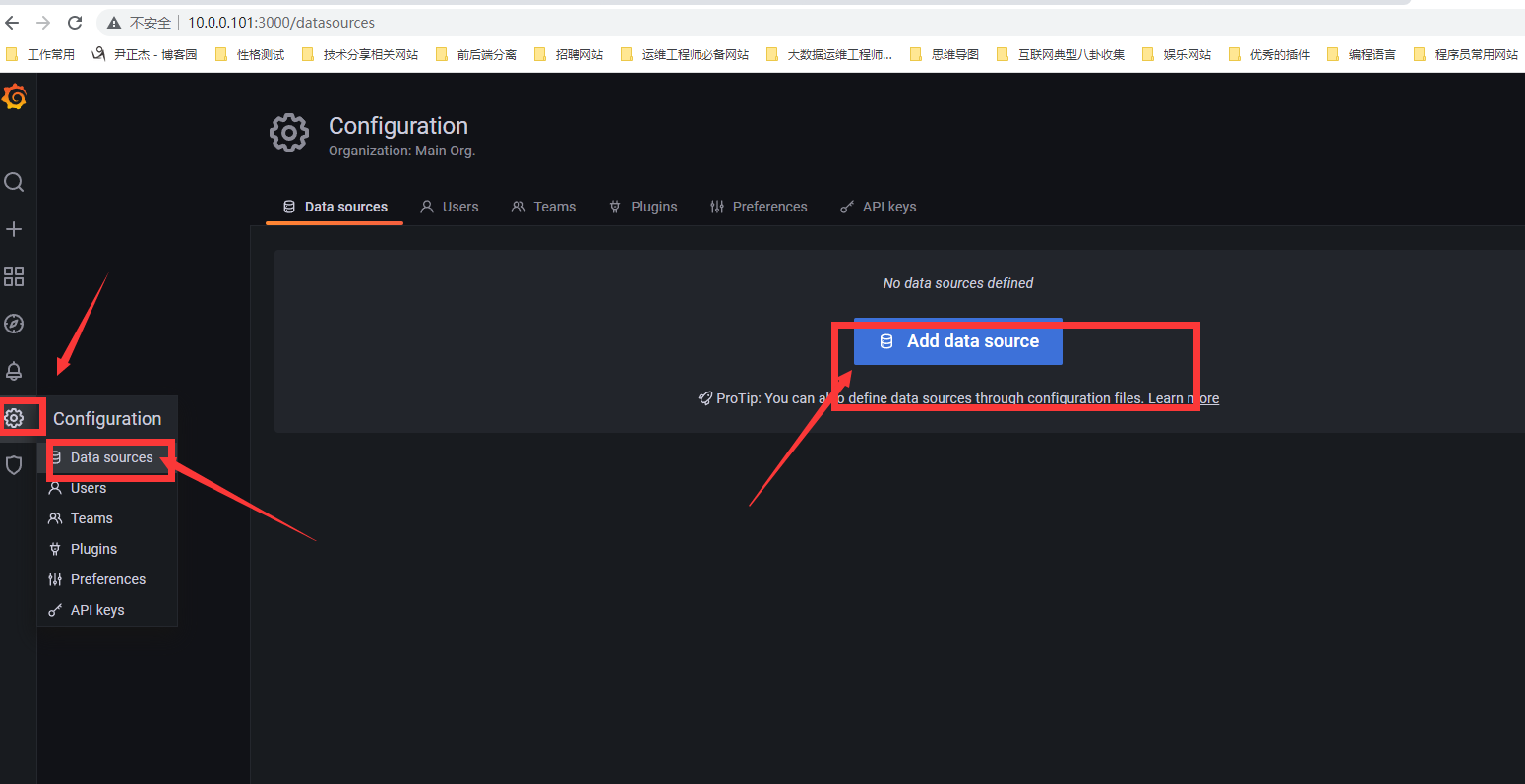
添加prometheus数据源

设置名称和URL地址
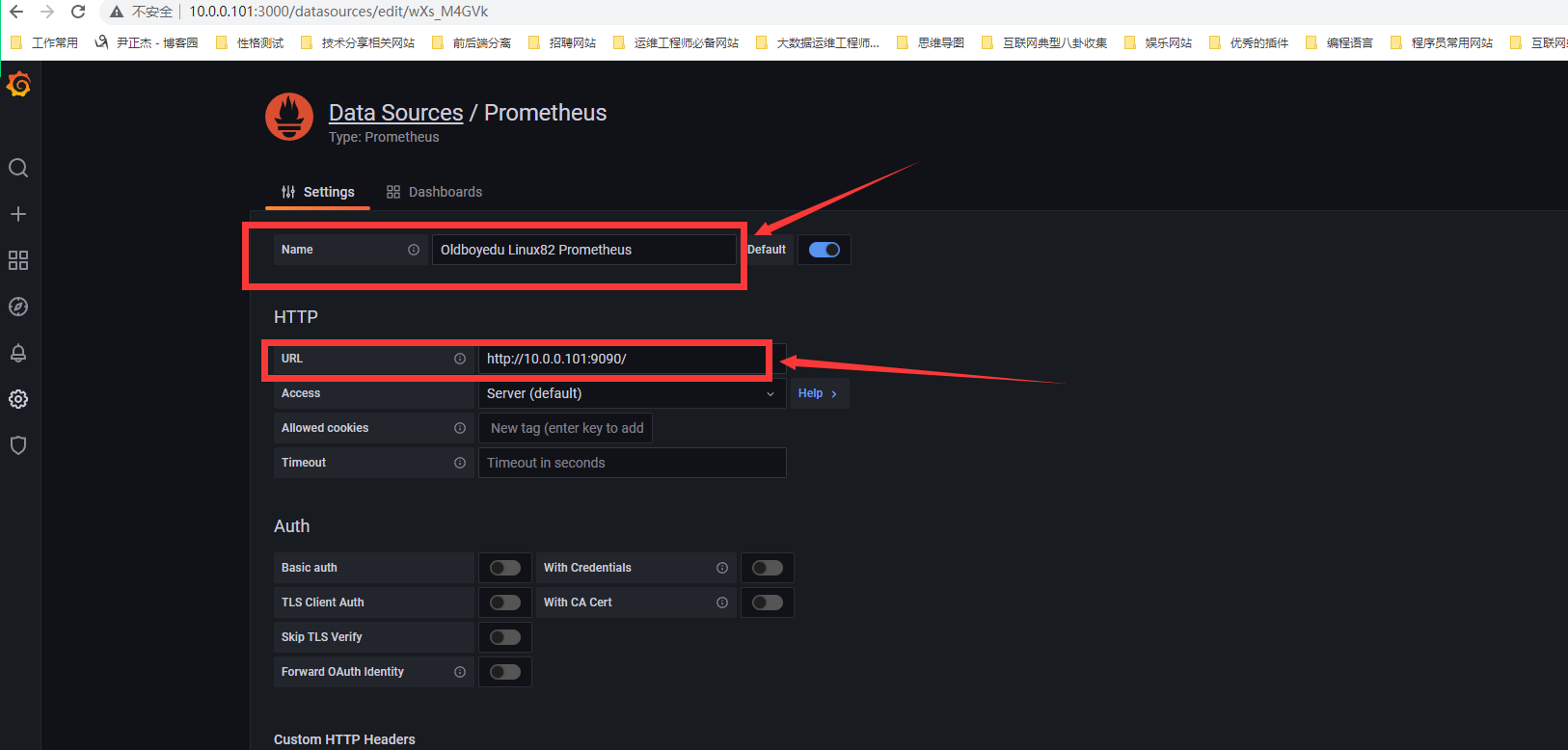
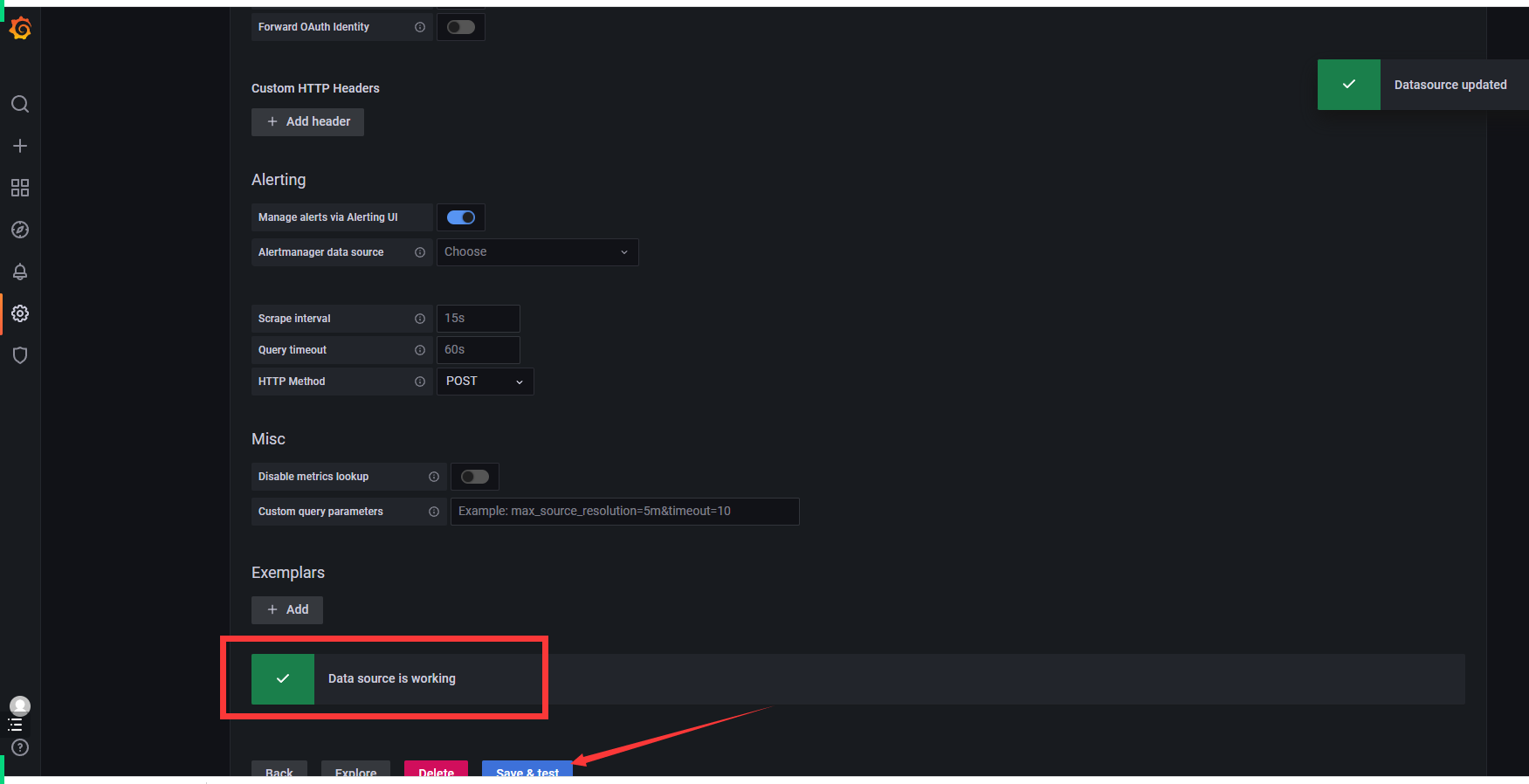
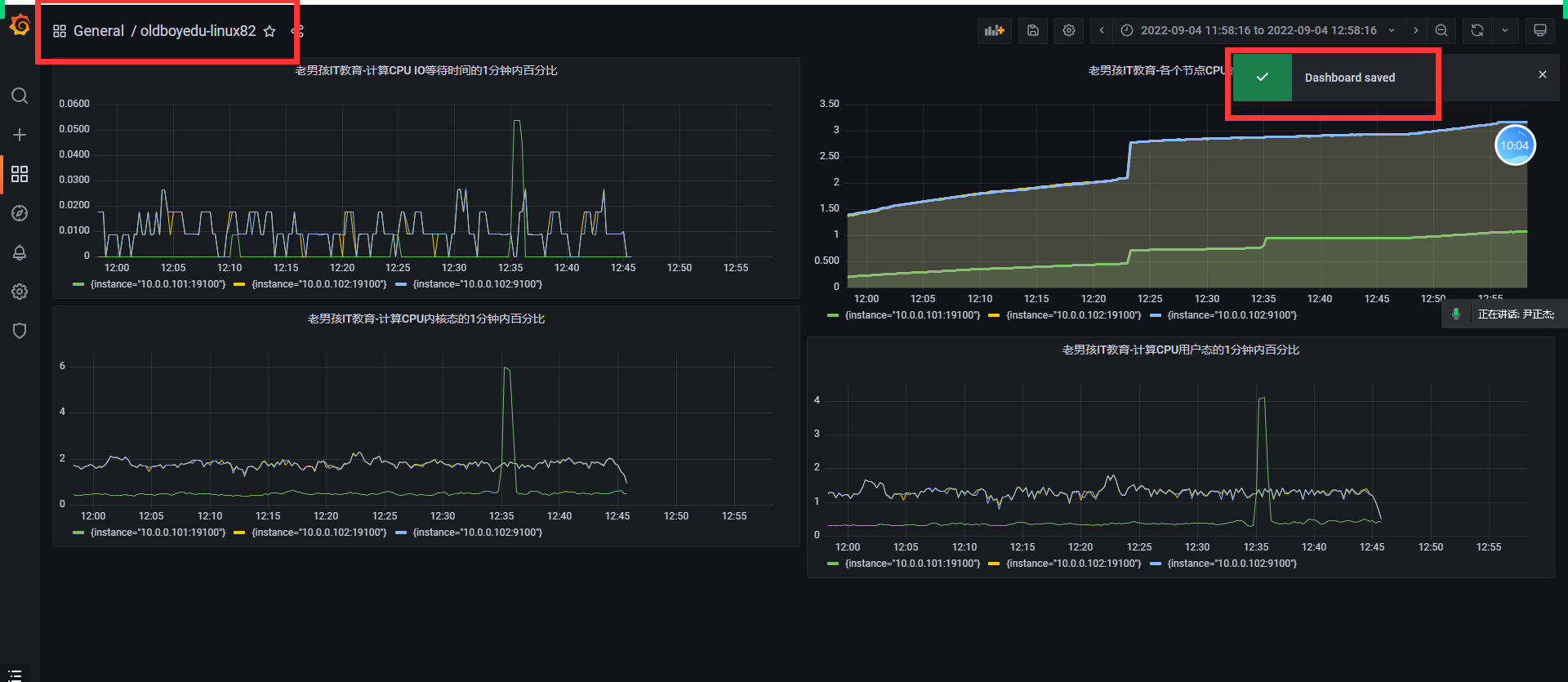
出现这个说明已经配置成功了
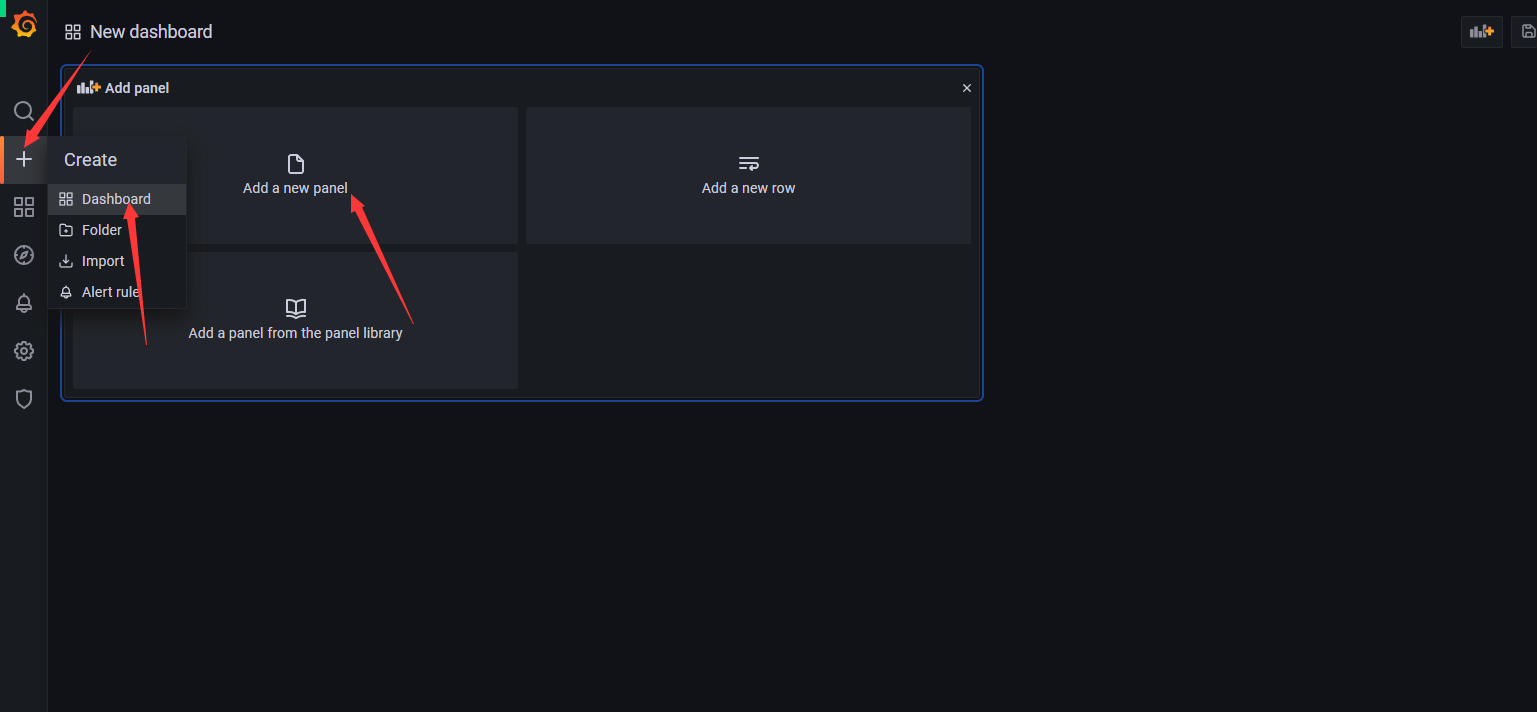
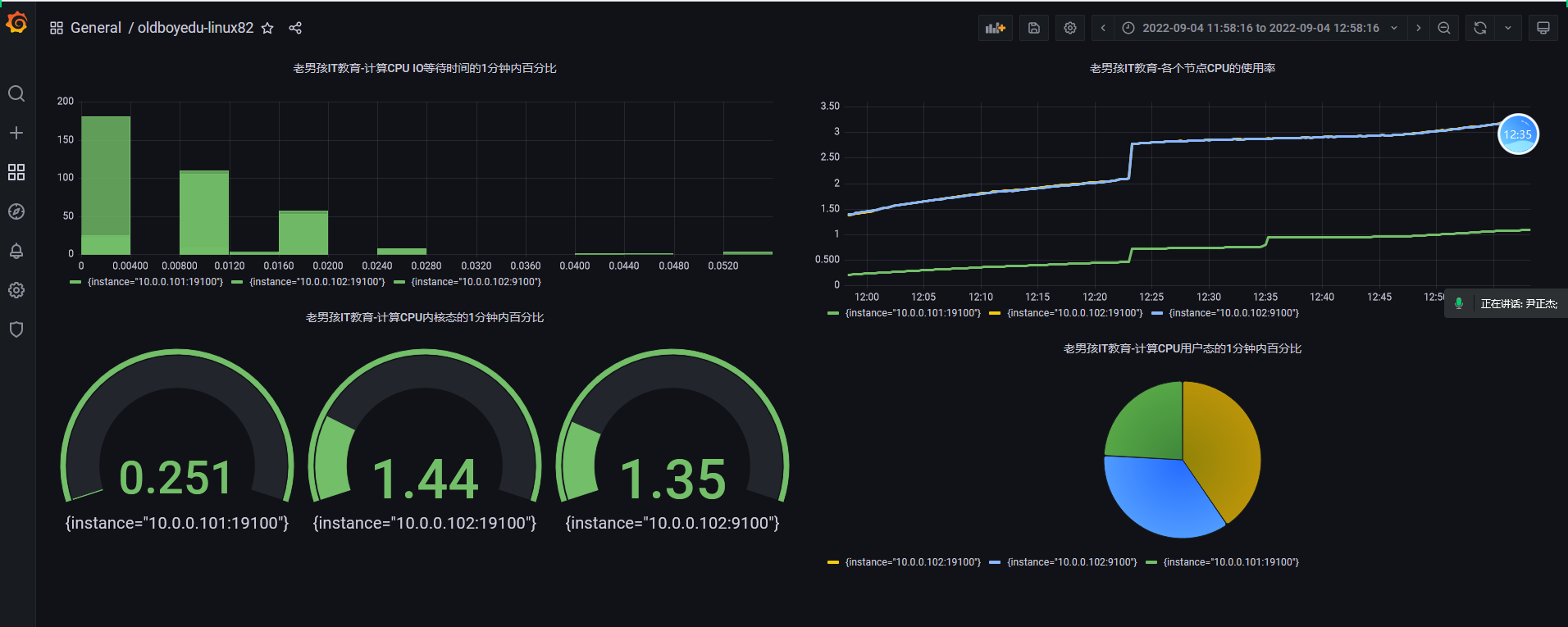
创建一个新的面板
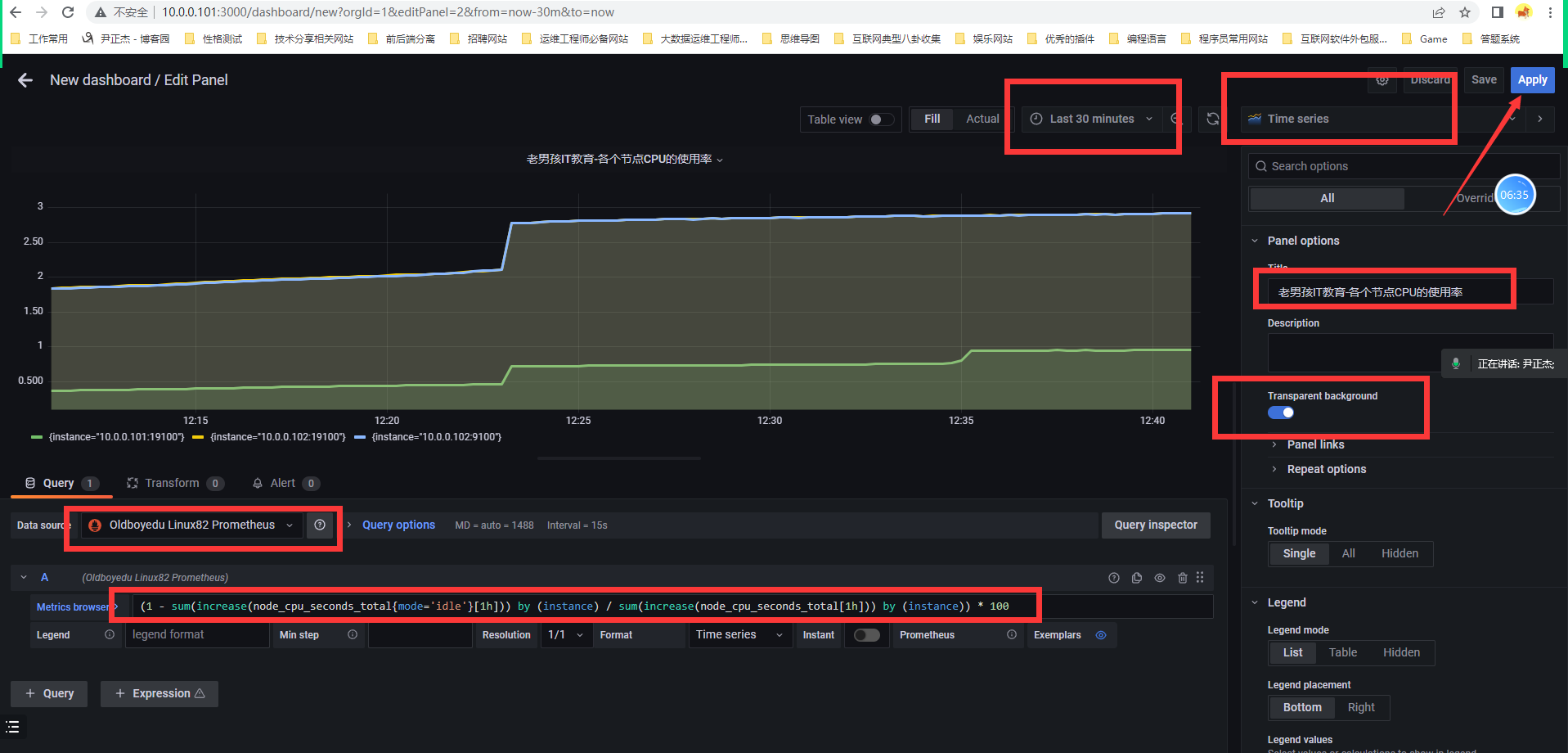
添加想要监控的PQL语言
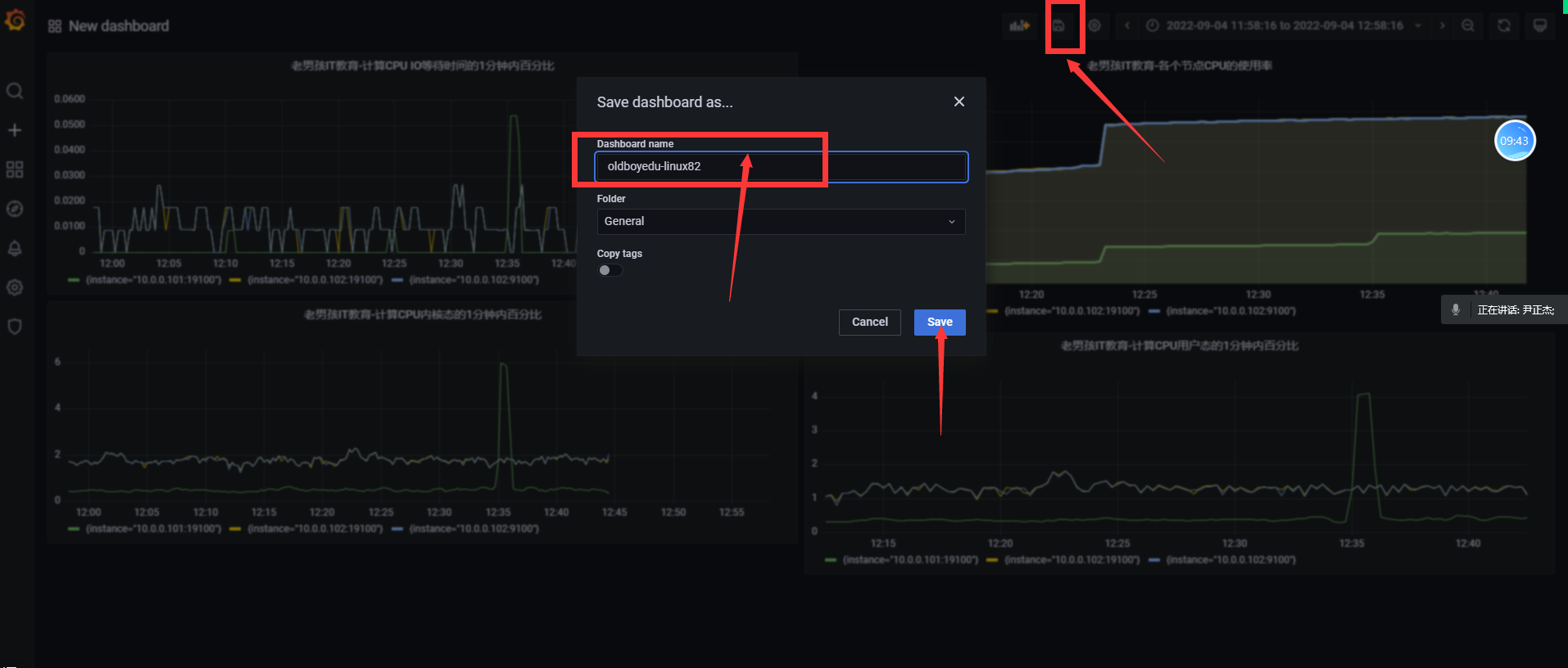
cadvisor:
1、通过容 器启动cadvisor
cadvisor监控当前结点有多少个容器,这些容器的信息,监控容器
node_exports是监控linux主机的指标,内存,磁盘,网络
docker run --volume=/:/rootfs:ro --volume=/var/run:/var/run:rw --volume=/sys:/sys:ro --volume=/var/lib/docker/:/var/lib/docker:ro --publish=8090:8080 --detach=true --name=cadvisor google/cadvisor:latest
温馨提示:
--volume=/:/rootfs:ro
相当于"-v /:/rootfs:ro"。
--publish=8080:8080
相当于"-p 8080:8080"。
--detach=true
相当于"-d"。
参考链接:
https://github.com/google/cadvisor
https://github.com/google/cadvisor/blob/master/deploy/Dockerfile
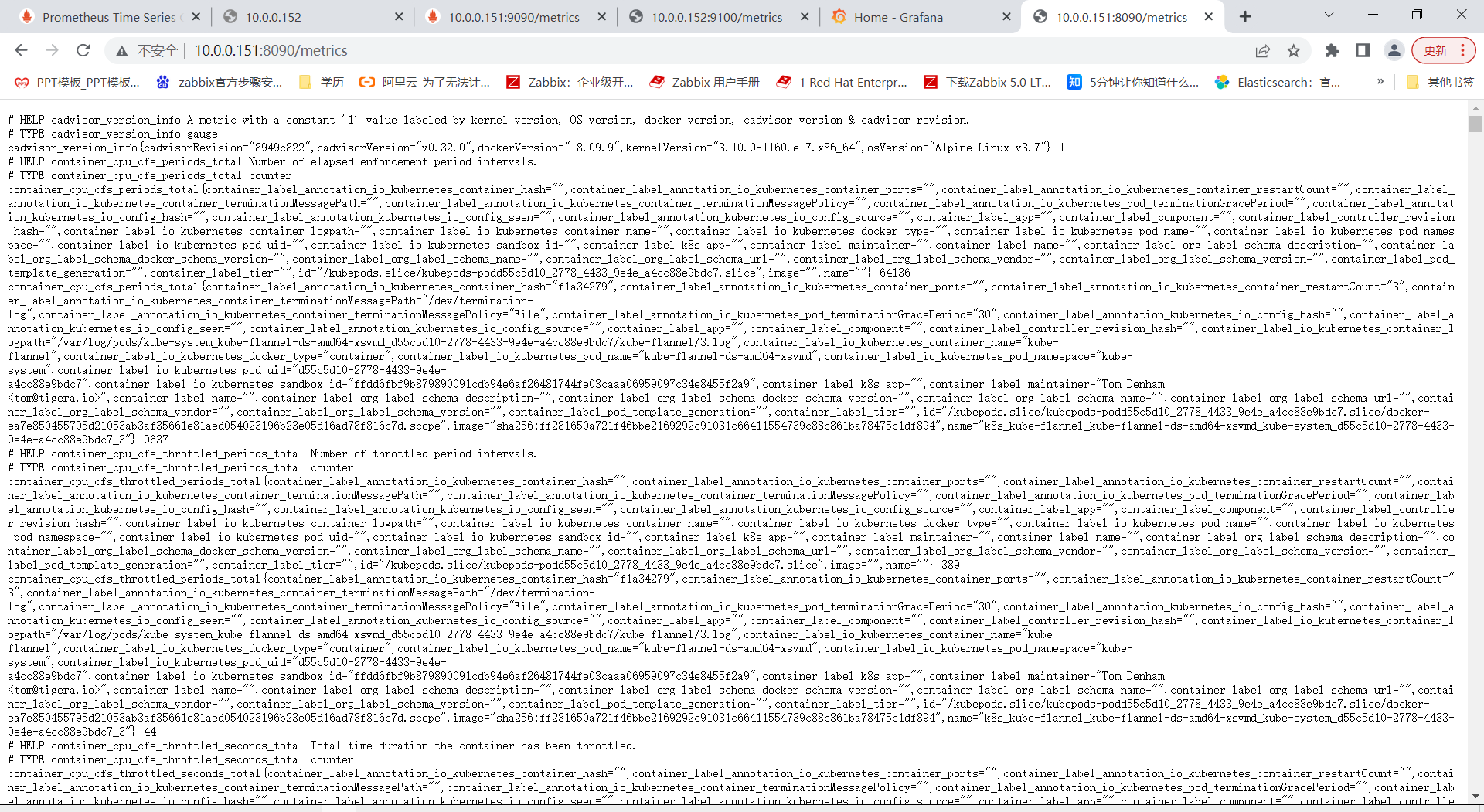
访问8090查看cadvisor监控的内容

在URL后面加metrics衡量指标
2.动态加载配置
[root@k8s151 ~]# cat /tmp/linux82.yml
[
{
"targets": ["10.0.0.151:8090","10.0.0.152:9100","10.0.0.151:19100","10.0.0.152:19100"]
}
]
配置变量指标
点击设置
点击添加变量
自定义变量
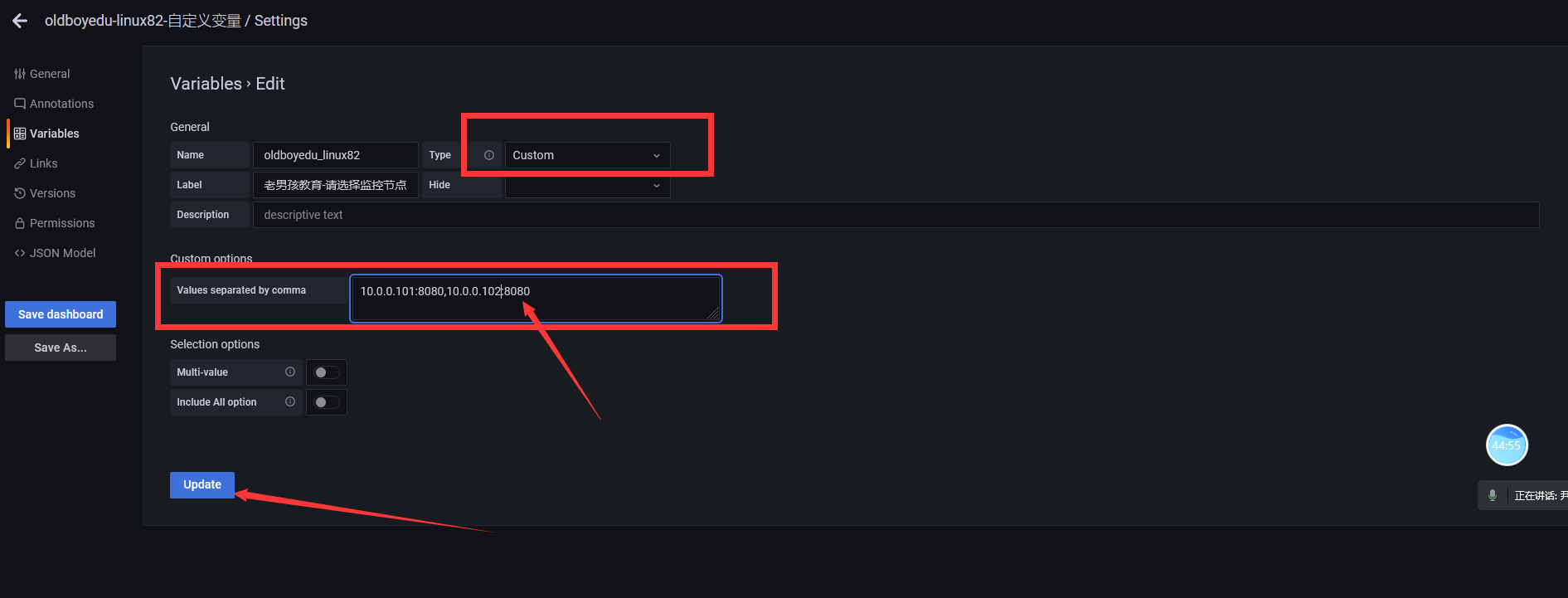
设置的监控指标
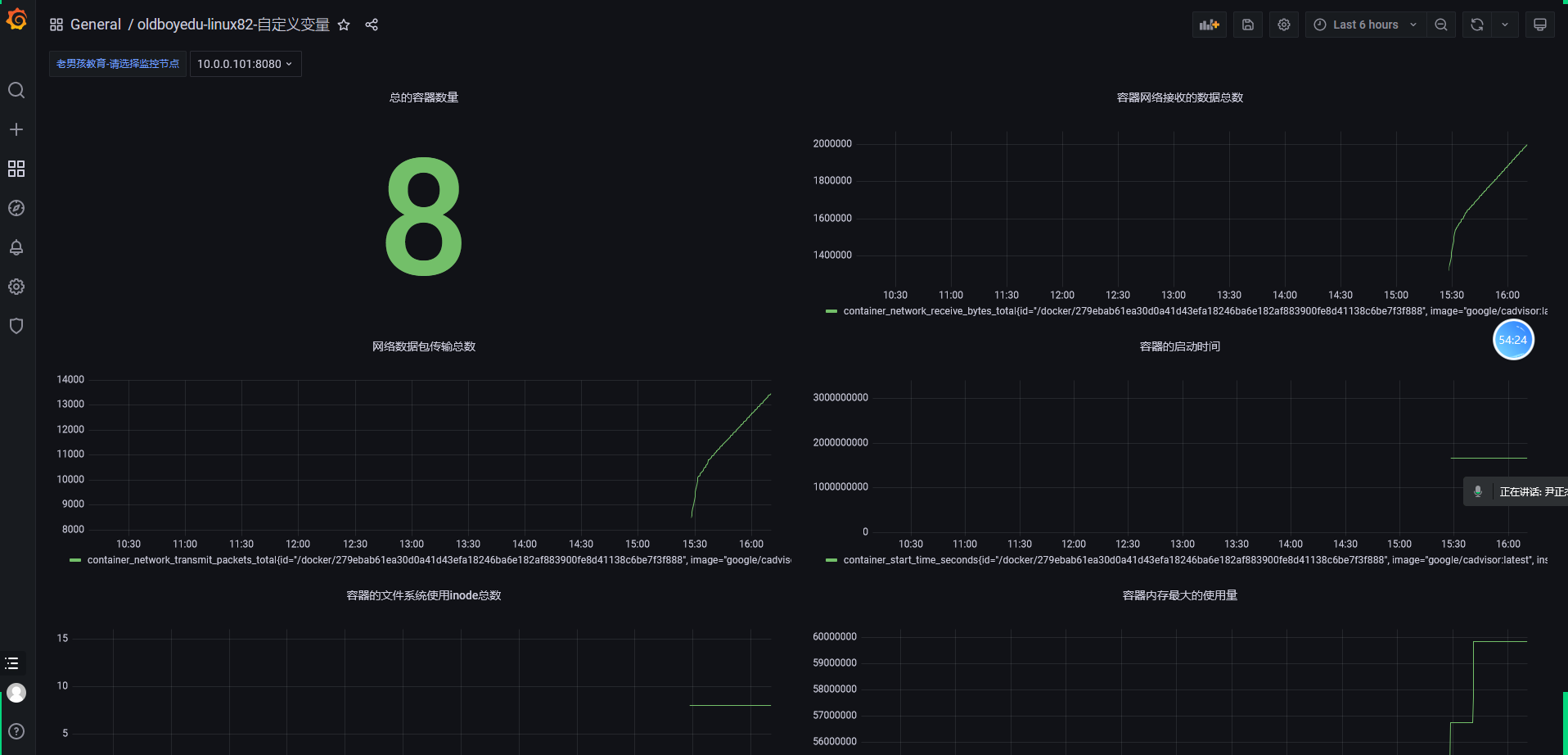
修改指标
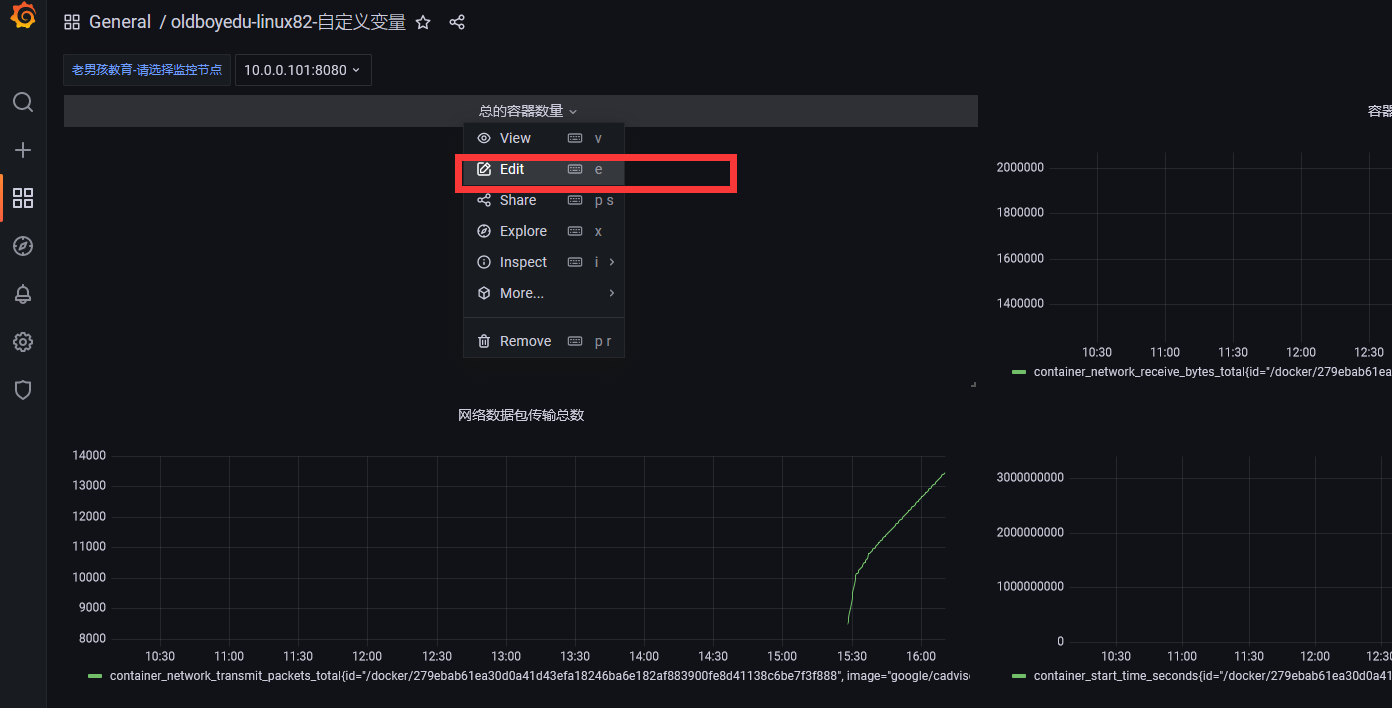
加入我们设置的变量值即可,instance="$oldboyedu_linux82"
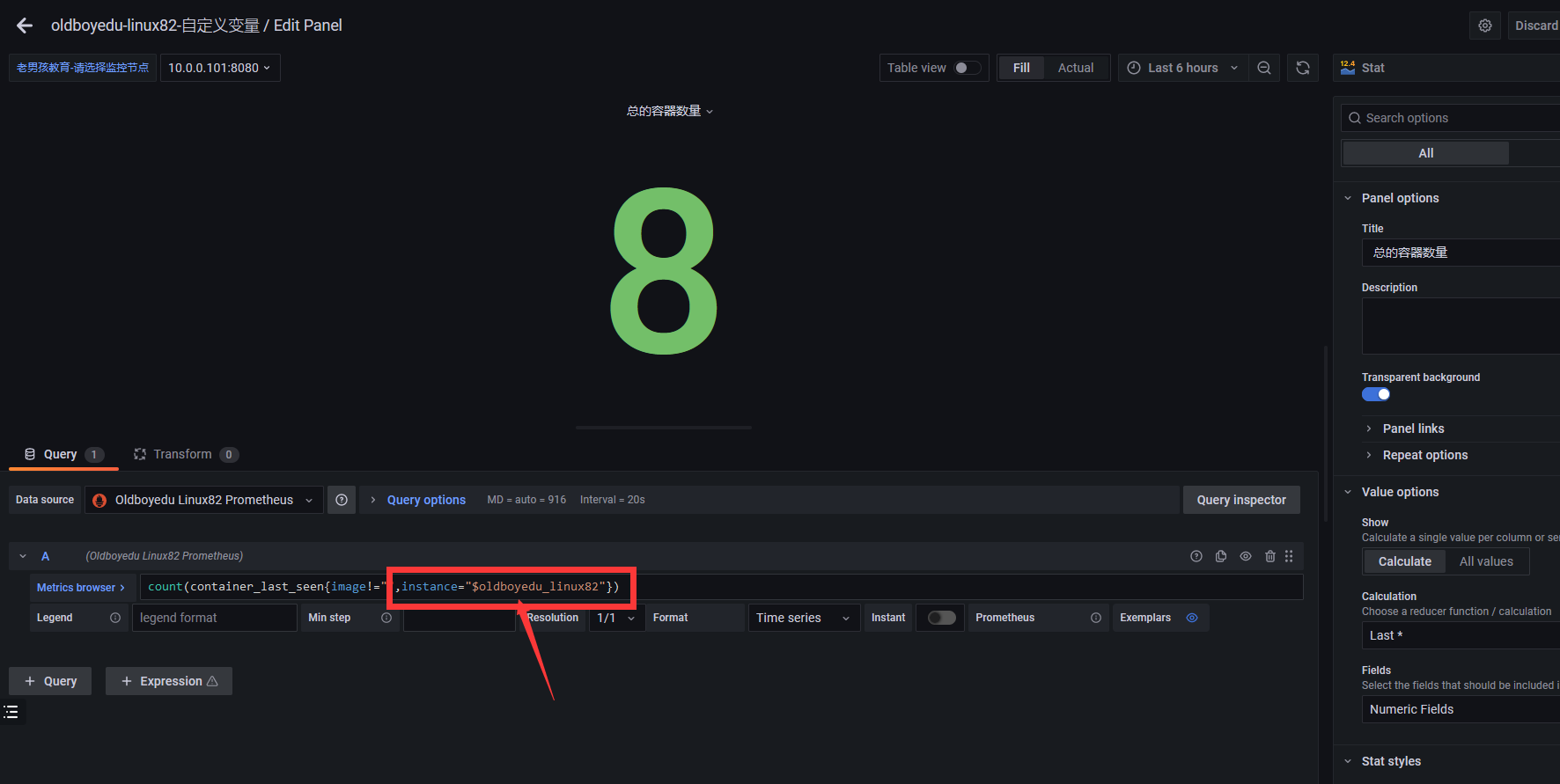
3.grafana手动定制PQL
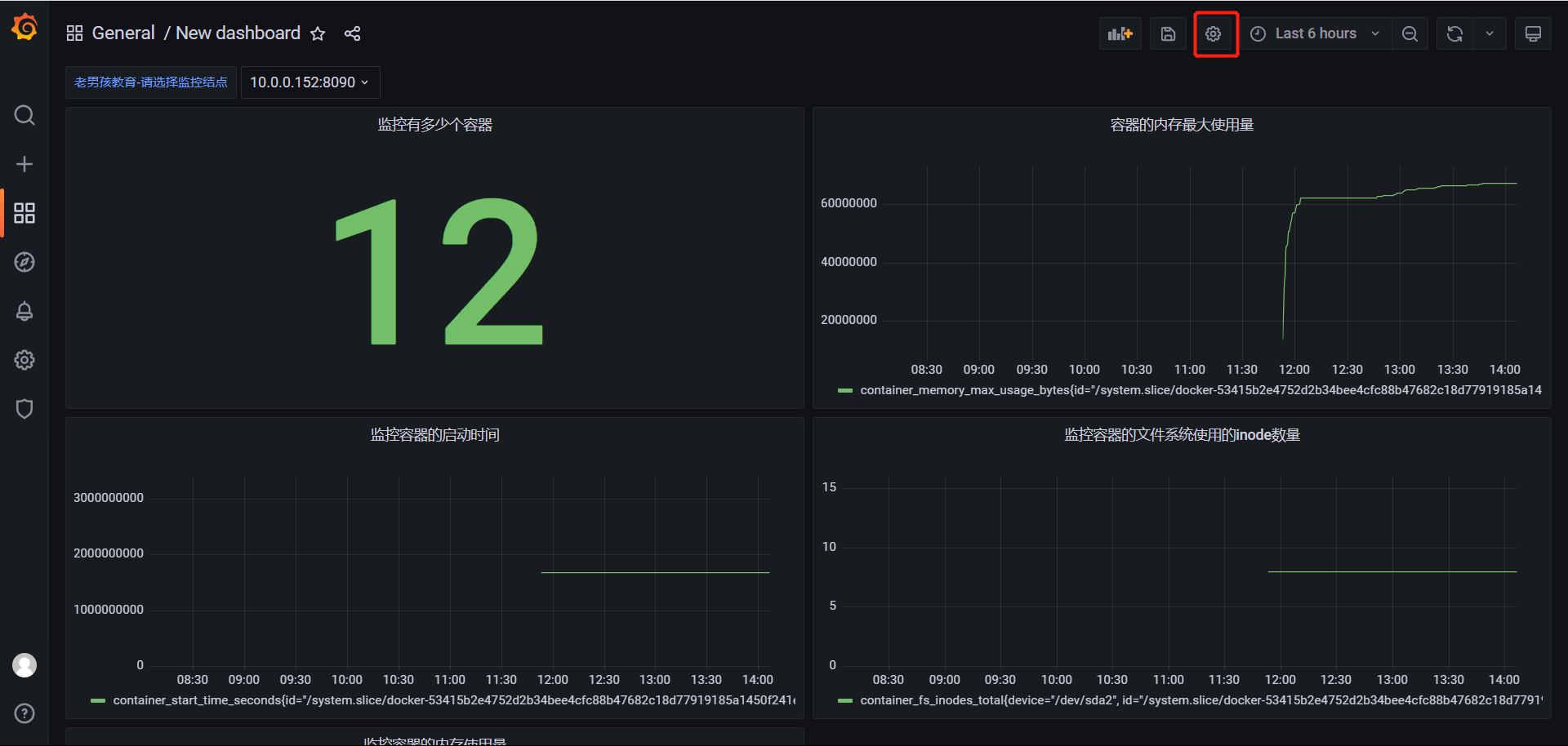
# 上图就是根据这些指标进行监控的
参考PQL:
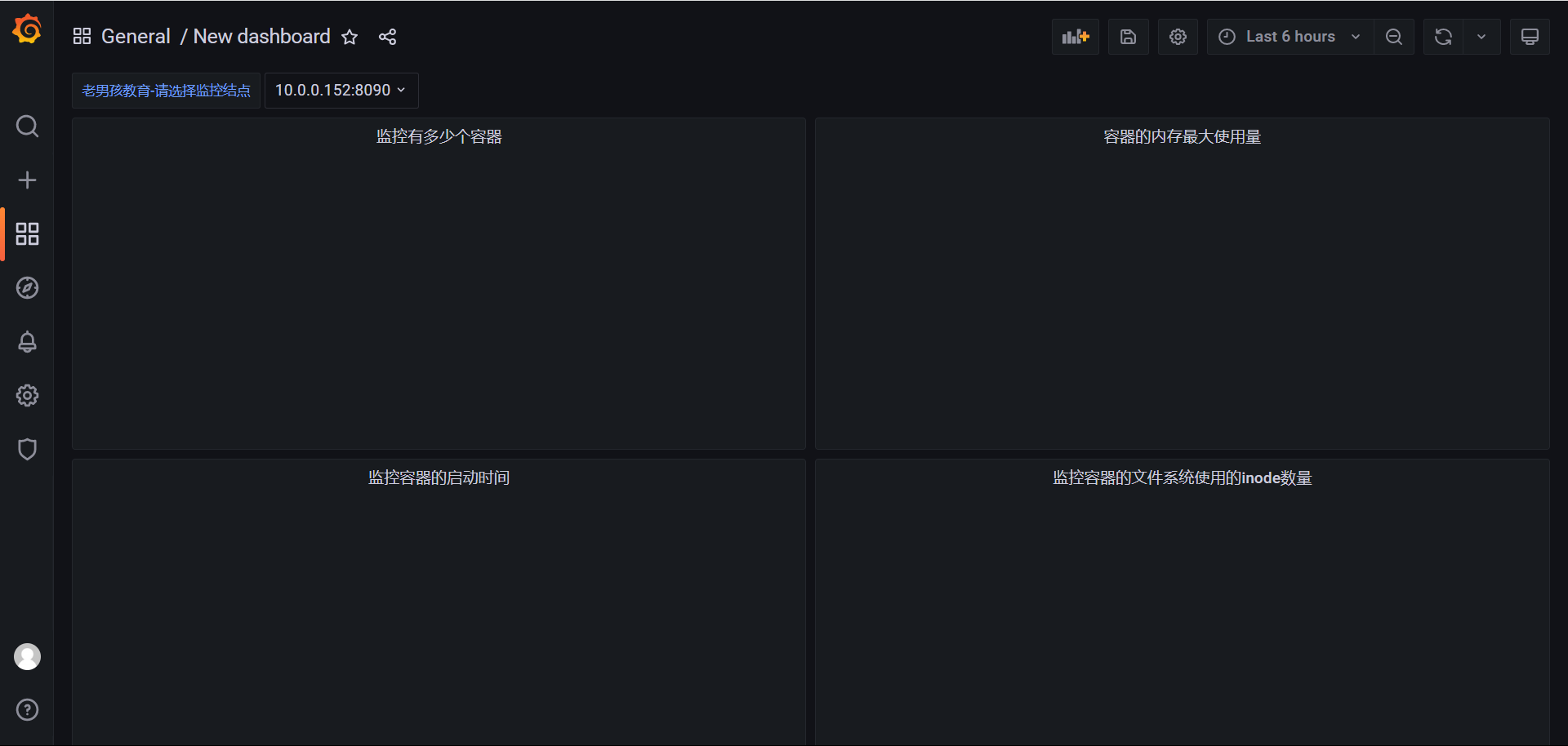
# 监控容器的内存使用量
container_memory_usage_bytes{image!="",name="cadvisor"}
# 监控容器的内存最大使用量
container_memory_max_usage_bytes{image!="",name="cadvisor"}
# 监控容器的启动时间
container_start_time_seconds{image!="",name="cadvisor"}
# 监控容器的文件系统使用的inode数量
container_fs_inodes_total{image != "", name="cadvisor"}
# 监控容器的网络接受数据的总数
container_network_receive_bytes_total{image != "", name="cadvisor"}
# 监控容器的网络数据包传输总数
container_network_transmit_packets_total{image != "", name="cadvisor"}
优秀模板的参考:
count(container_last_seen{image!=""})
监控有多少个容器。
sum(container_memory_usage_bytes{image!=""})/1024/1024
监控容器总的使用内存,并换算成MB。
time() - process_start_time_seconds{job="prometheus"}
查询Prometheus启动的时间,dashboard选择"Stat"类型。
(sum(node_memory_MemTotal_bytes) - sum(node_memory_MemFree_bytes +node_memory_Buffers_bytes + node_memory_Cached_bytes) ) / sum(node_memory_MemTotal_bytes) * 100
查询内存的使用率,dashboard选择"Gauge"类型。
sum(sum by (container_name)( rate(container_cpu_usage_seconds_total[1m] ) )) / count(node_cpu_seconds_total{mode="system"}) * 100
查询CPU的使用率,dashboard选择"Gauge"类型。
sum(up)
查询有多少个监控目标在线,dashboard选择"Stat"类型。
4.验证
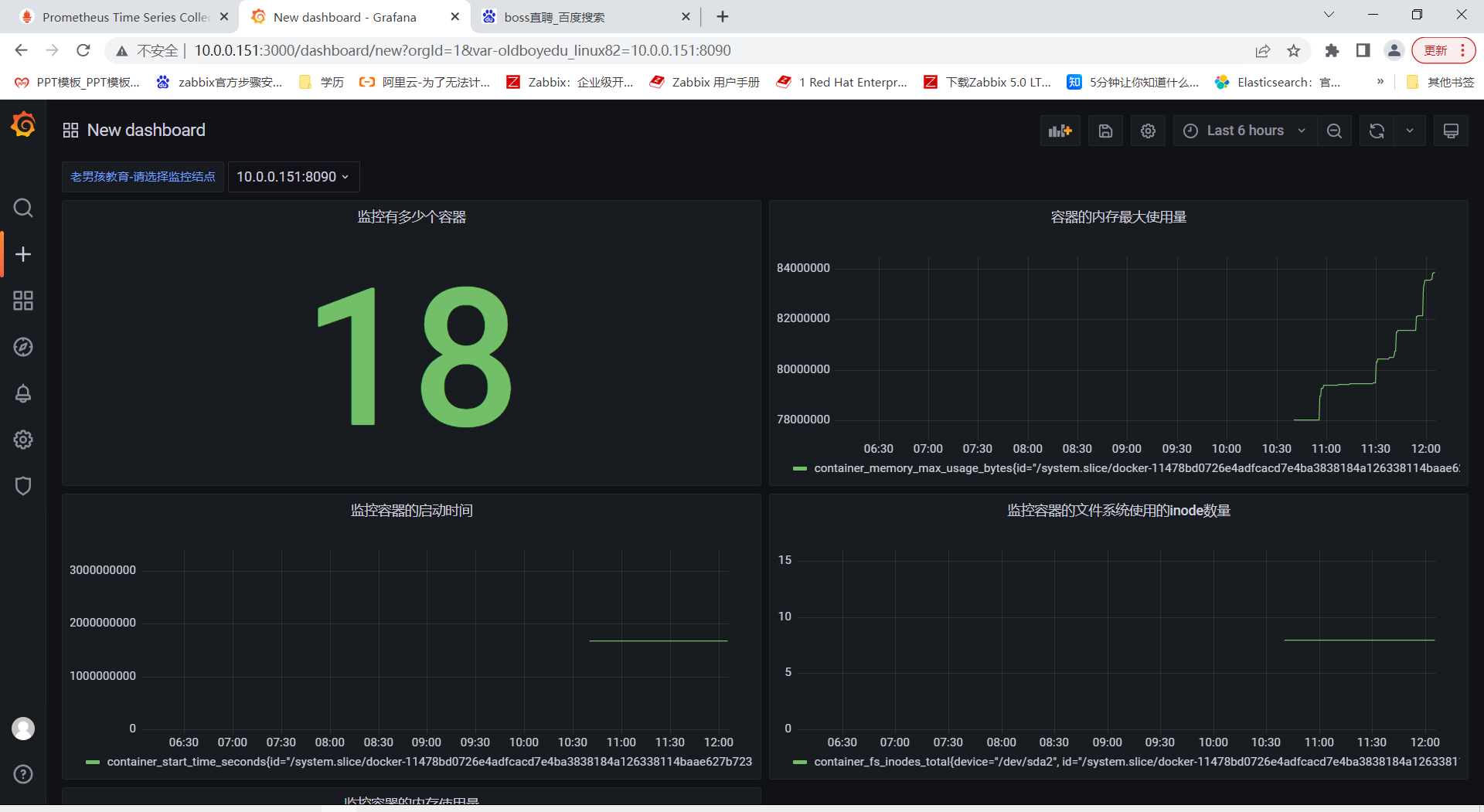
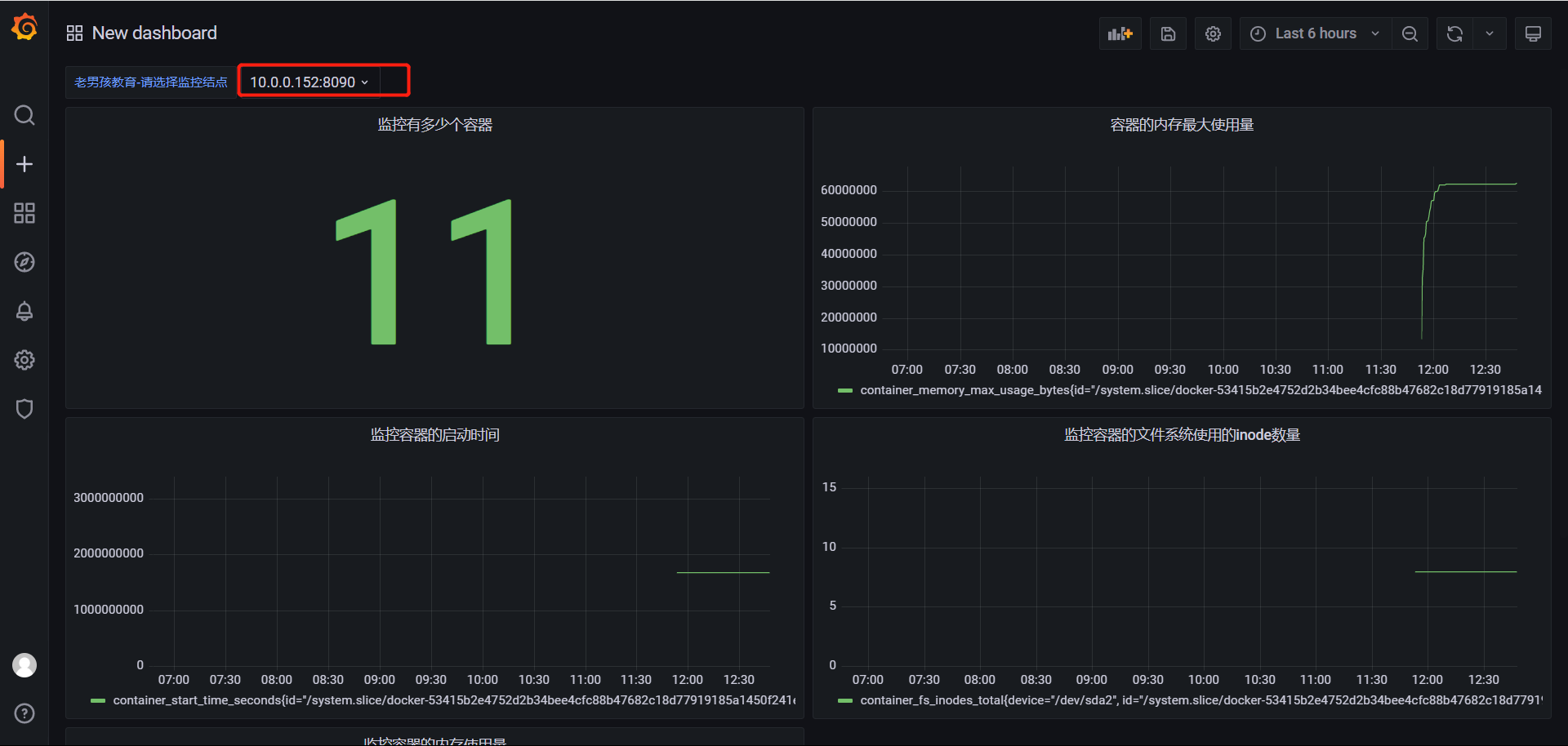
从grafana官方进行拿去定义好的监控
1、搜索grafana.com---》dashboard下搜索你想要监控的内容,下图是搜索的docker
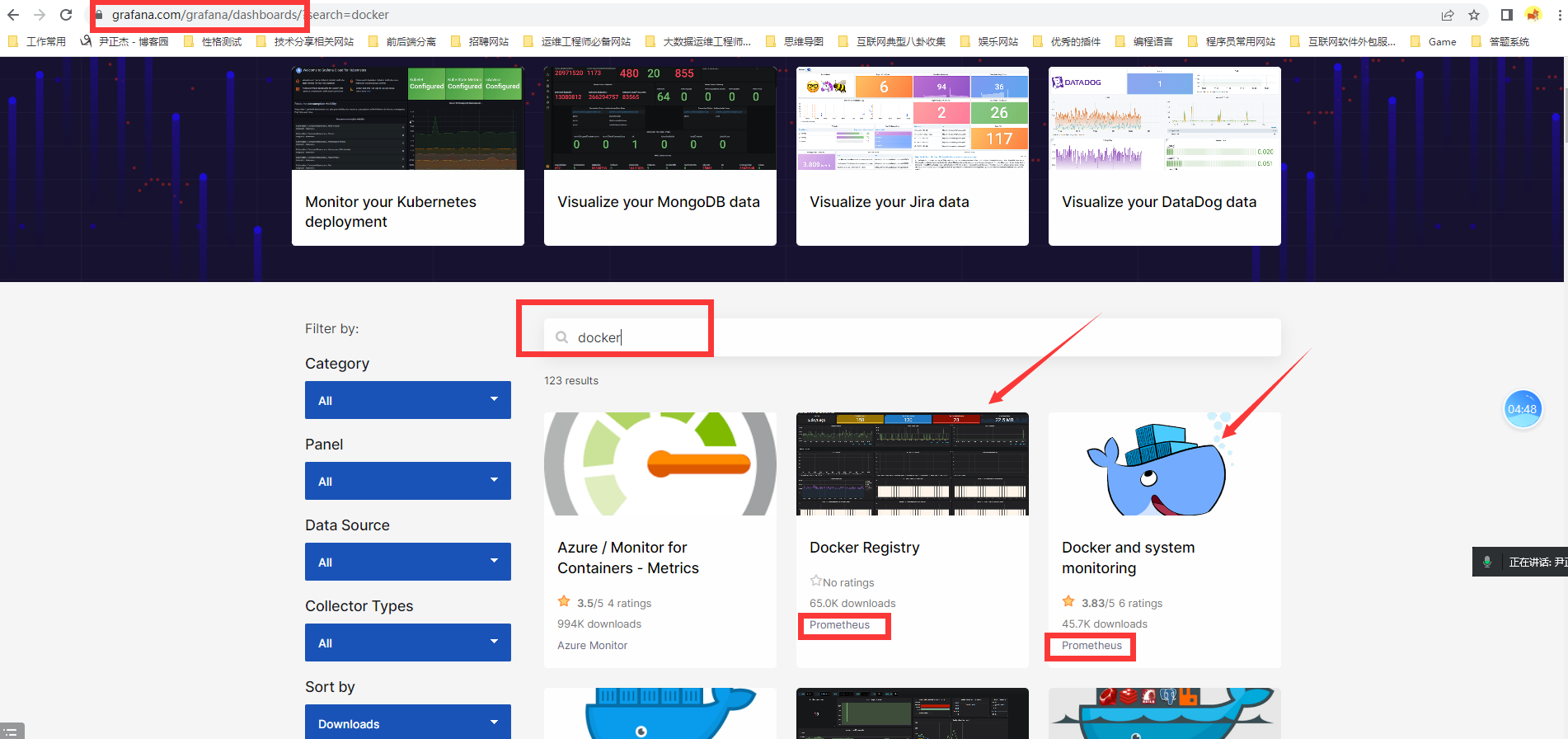
2、复制ID号
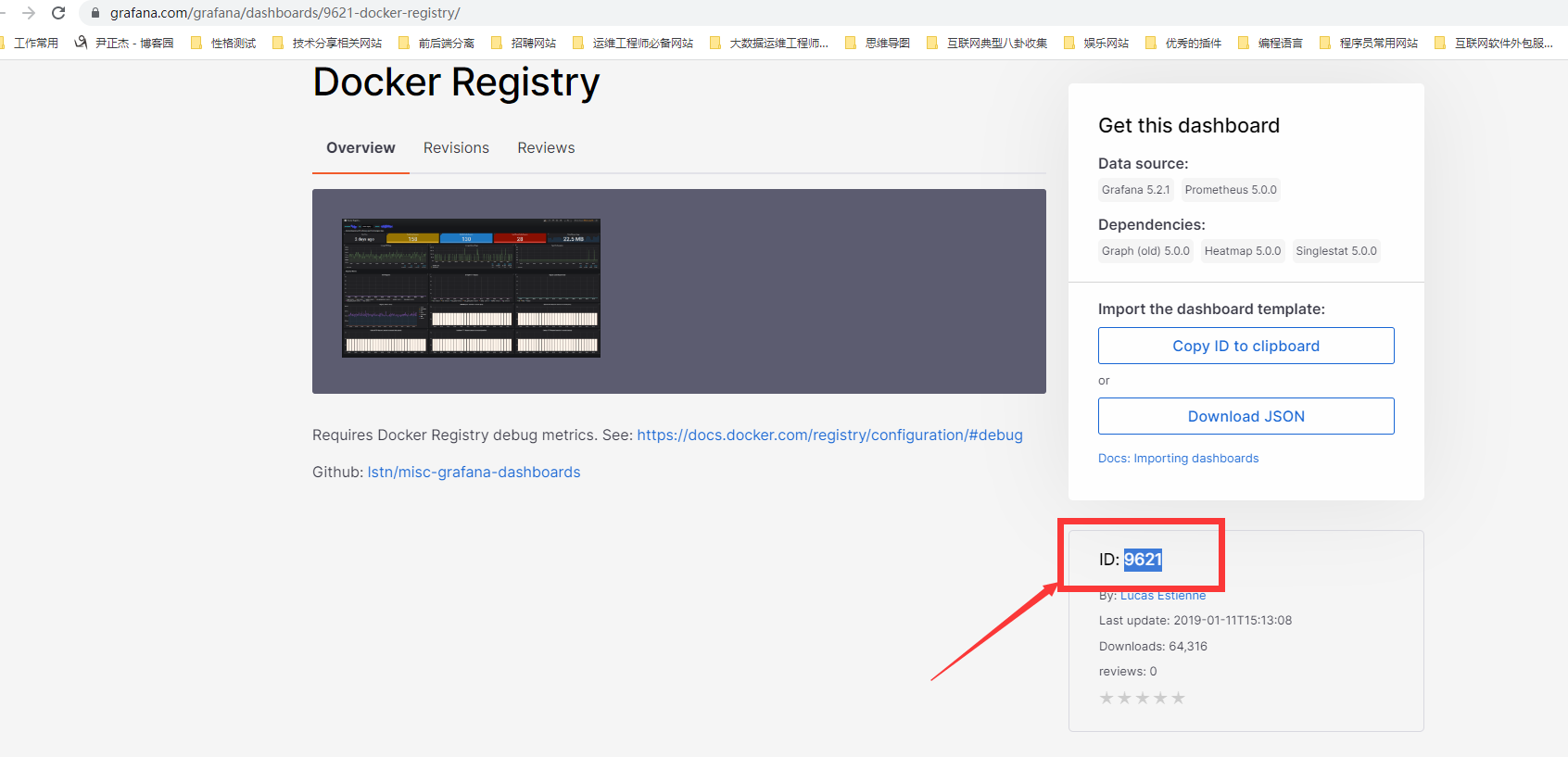
3、import导入id号
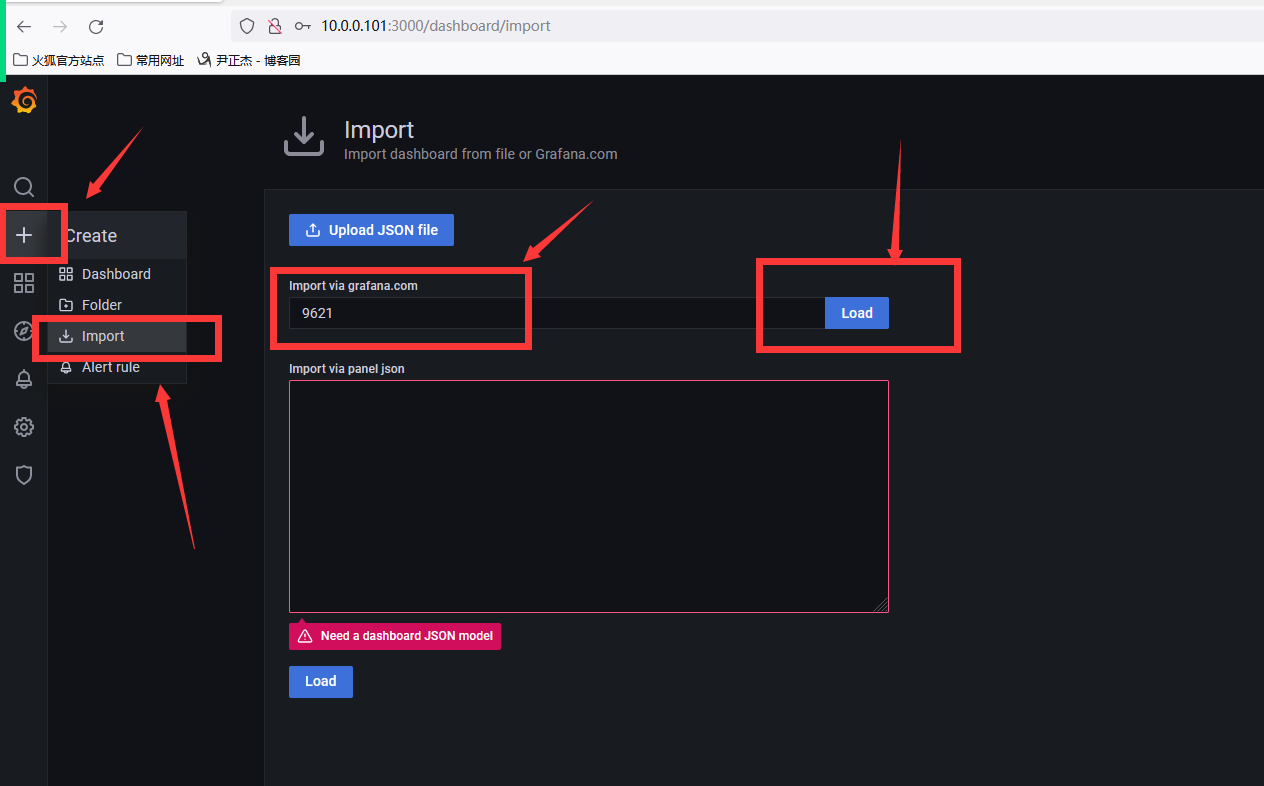
4、设置名字,数据源是选择prometheus数据源
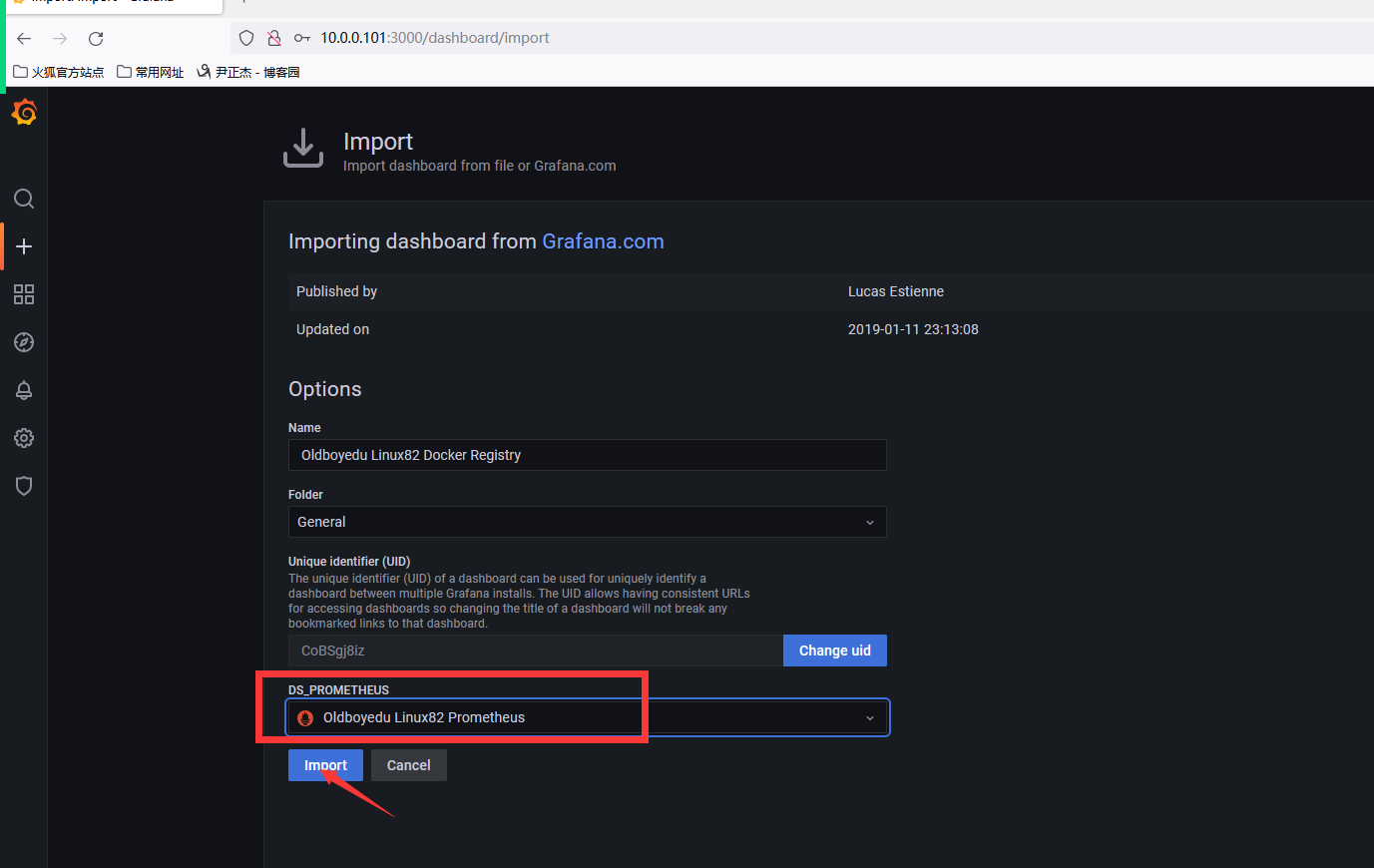
各种好的仪表盘
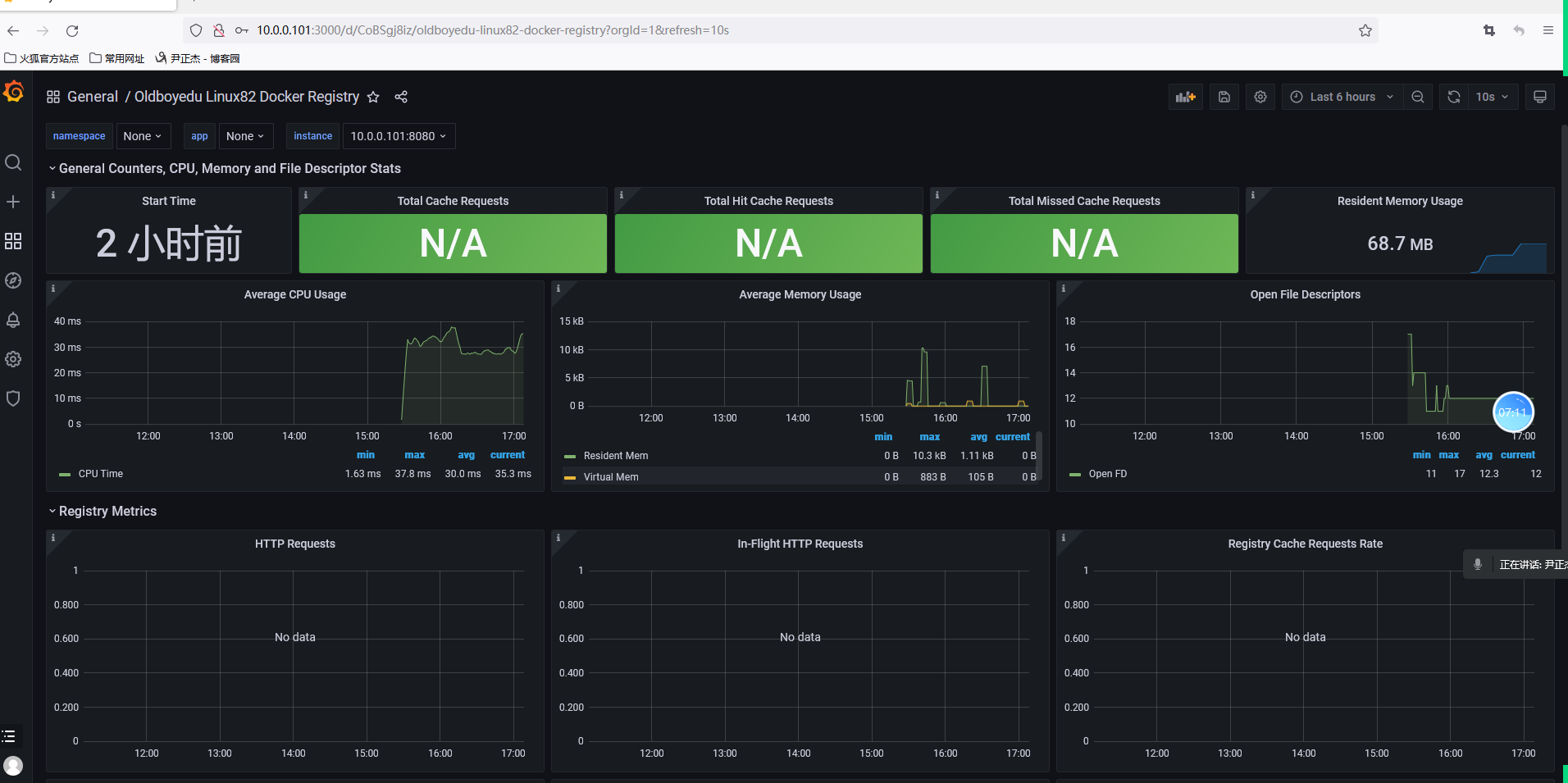
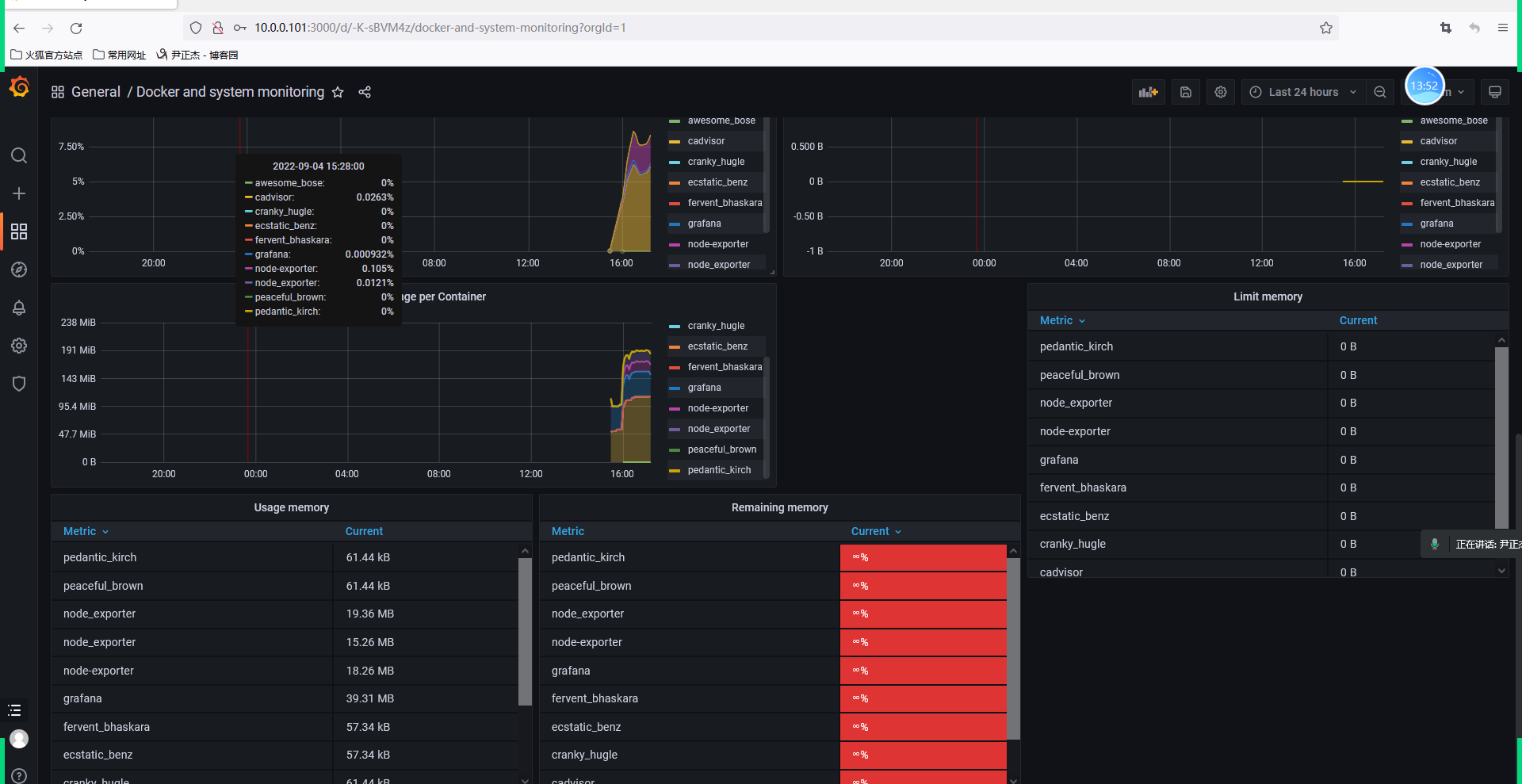
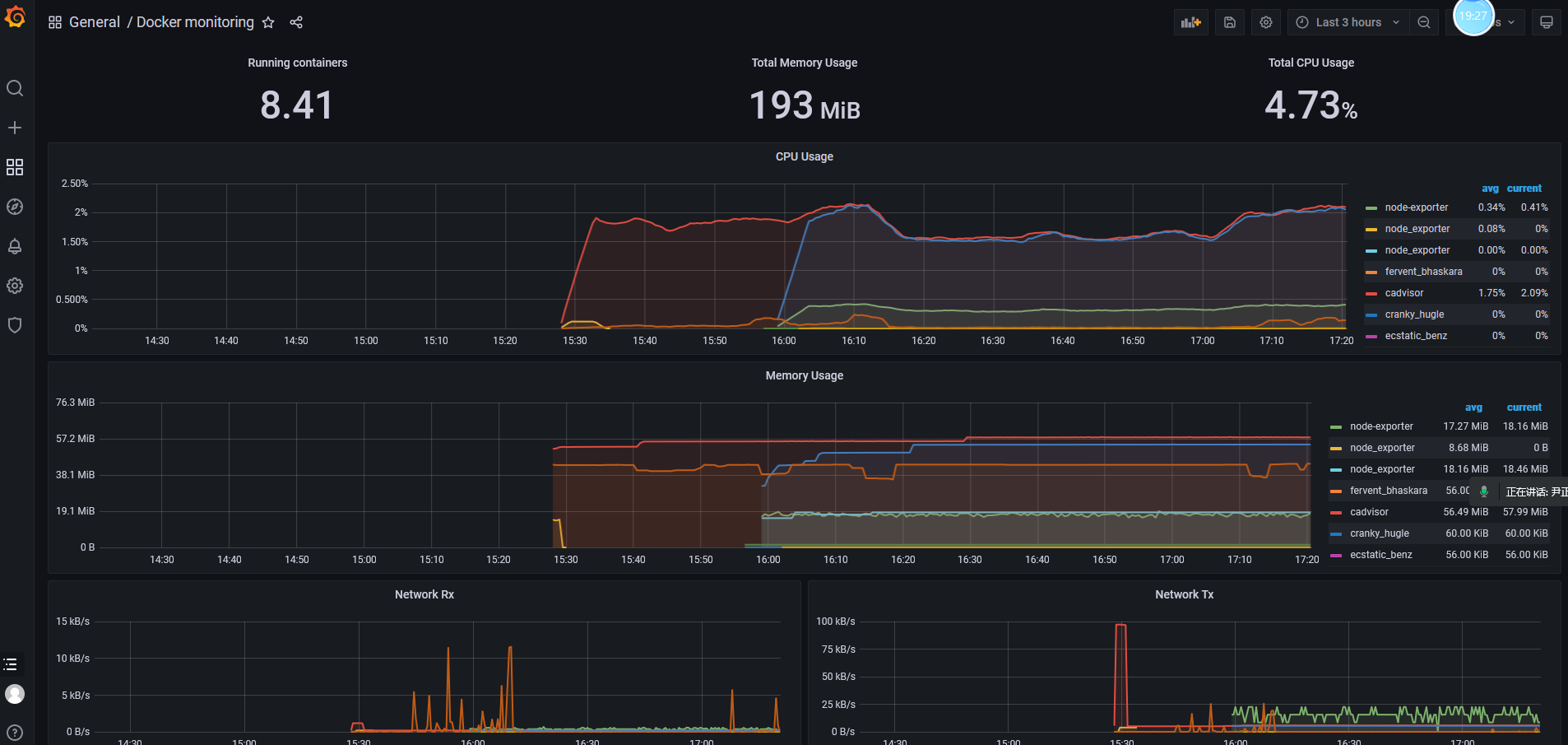
不错的仪表盘
比较不错的仪表盘ID:
179
193
395
893
10566
10619
11600
参考链接:
https://grafana.com/grafana/dashboards/179
https://grafana.com/grafana/dashboards/193
https://grafana.com/grafana/dashboards/395
https://grafana.com/grafana/dashboards/893
https://grafana.com/grafana/dashboards/10566
https://grafana.com/grafana/dashboards/10619
https://grafana.com/grafana/dashboards/11600
推荐阅读:
https://grafana.com/grafana/dashboards/
grafana迁移
1、152结点部署grafana
[root@k8s152 ~]# docker run -d --name=grafana -p 3000:3000 grafana/grafana-enterprise
部署完成
2、配置数据源
选择数据源,添加prometheus数据源,然后把prometheus的网址复制过来,起个名字即可。
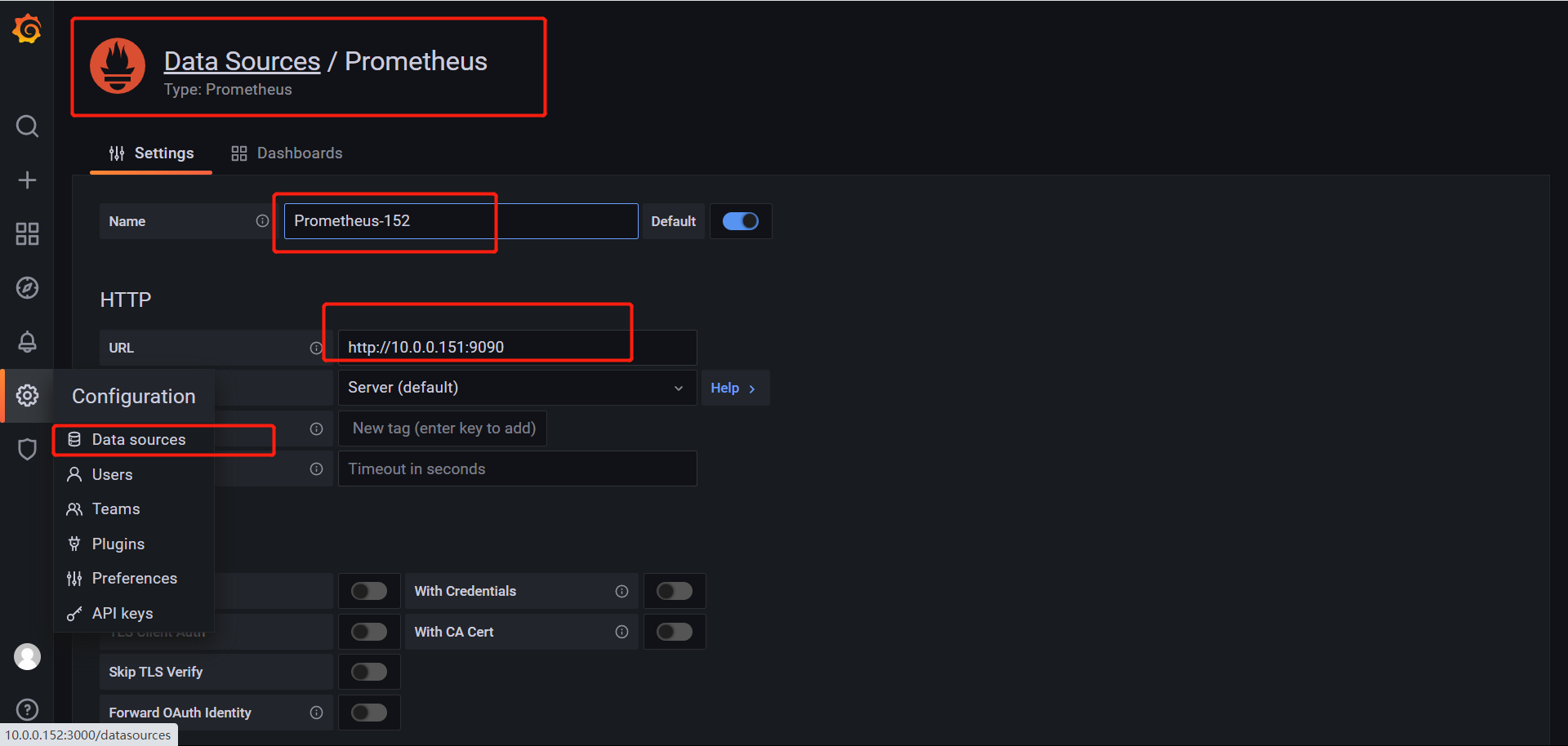
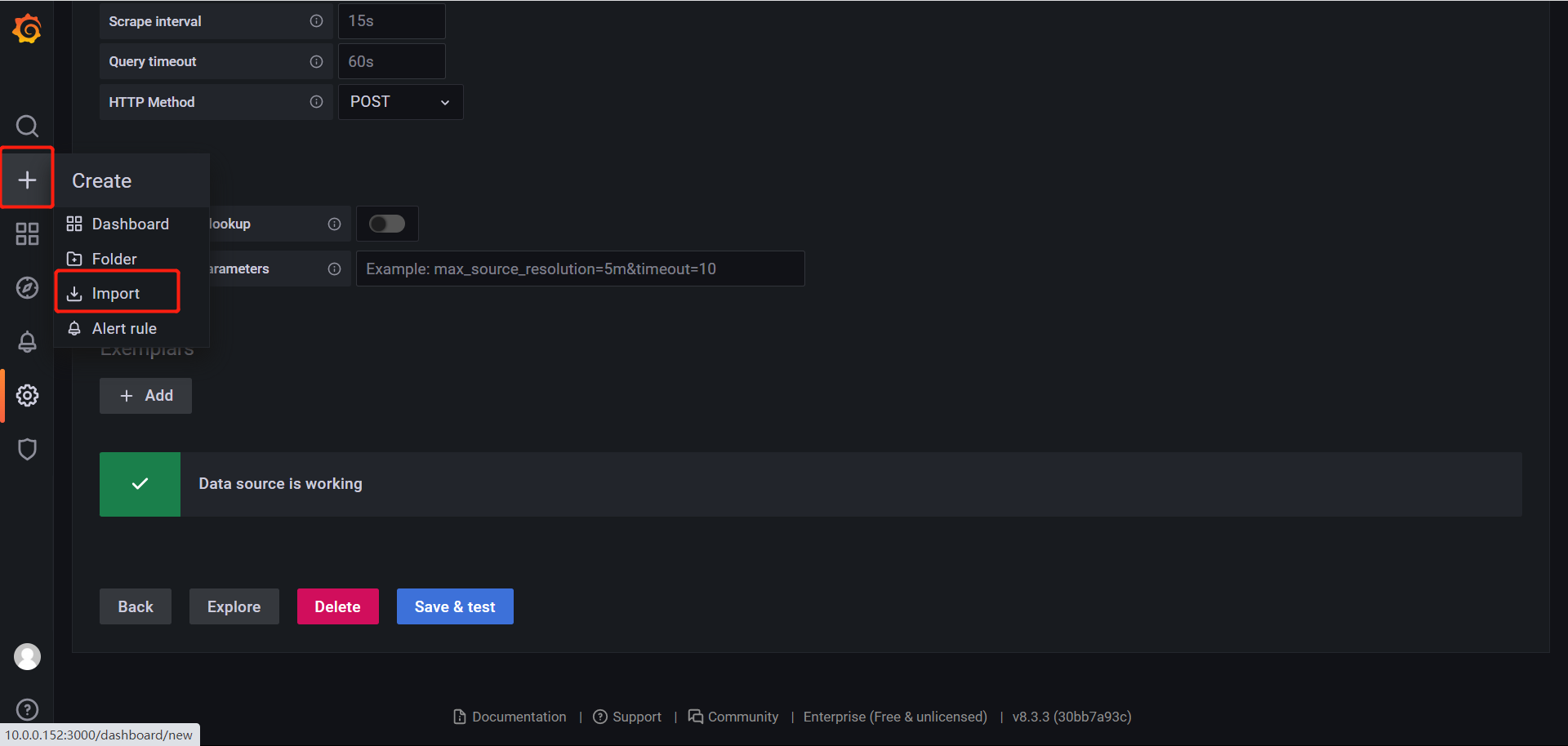
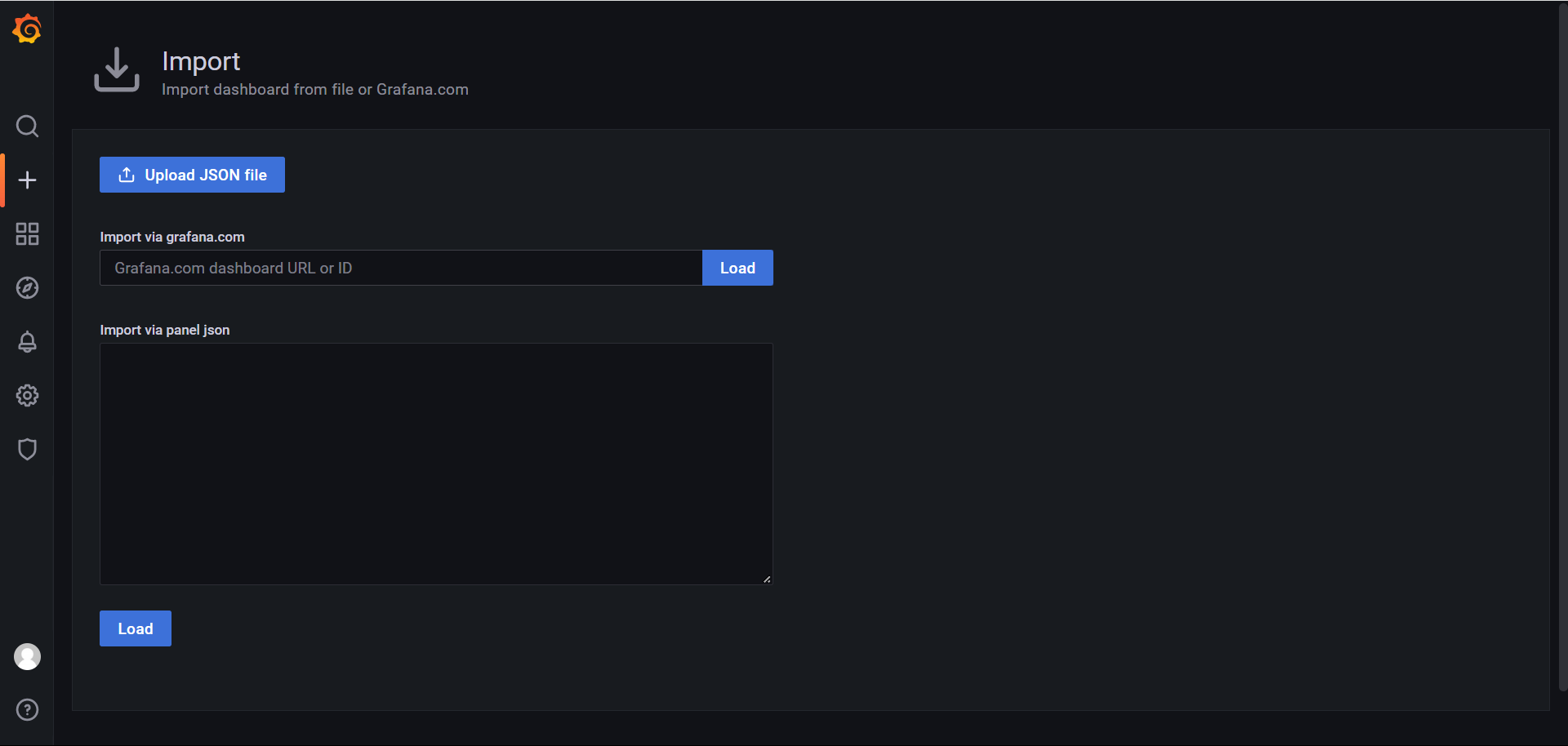
需要导入内容
这个是151结点的仪表盘--点击设置
点击json格式,把这一串复制下来

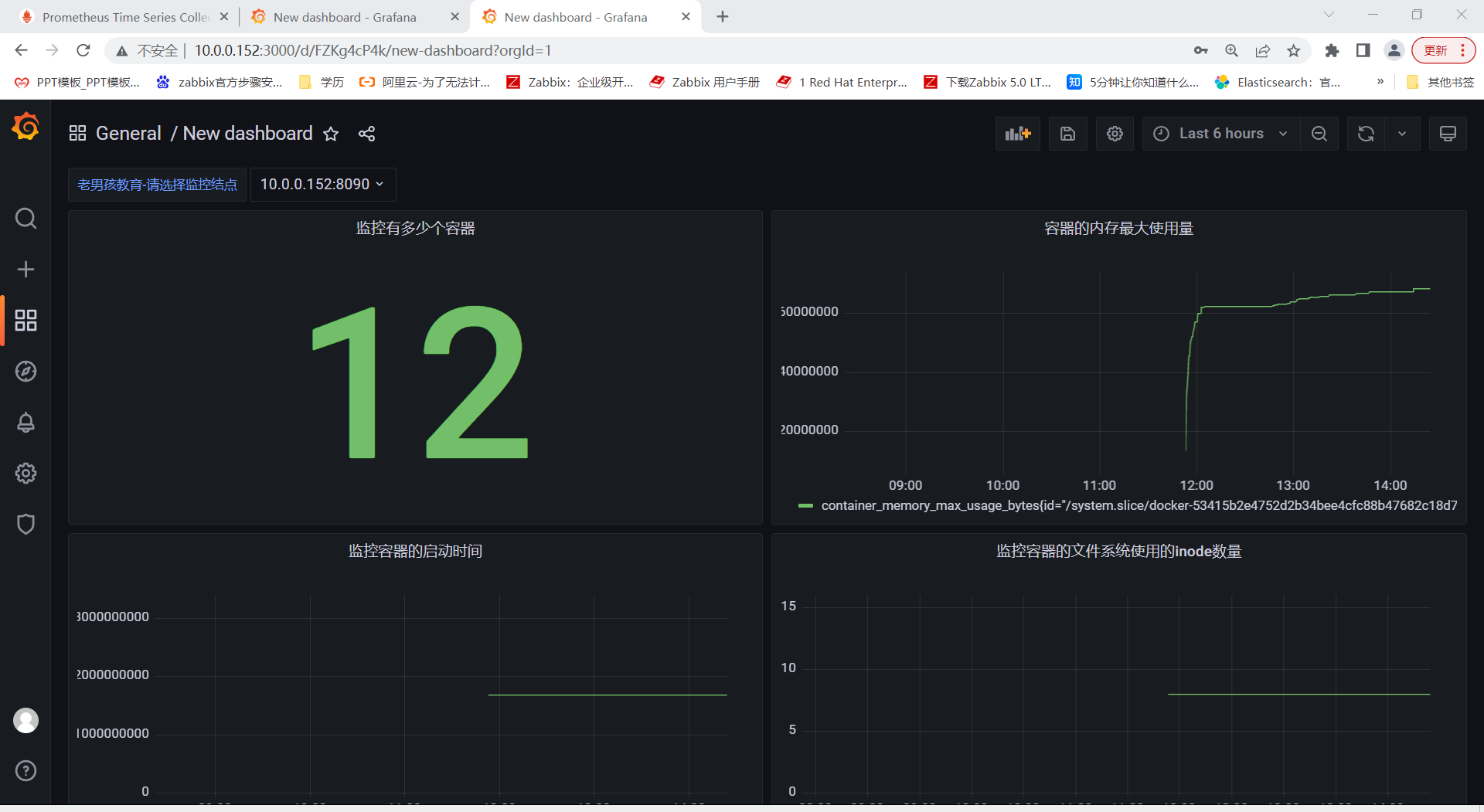
拿到152这个结点搭建的grafana进行load导入
这里的folder数据源记得选择prometheus我的没选所以后面是空白,不过edit进行选可以。
除了官网导入和json导入,还有一种导入方式
基于文件导入
导入即可
今日作业:
(1)完成课堂的所有练习并完善思维导图;
(2)调研使用grafana实现邮件告警;
(3)准备3台干净的环境,2核心4GB,不允许使用交换分区(不然K8S集群起不来); 拍快照!干净的环境!
cat >> /etc/hosts <<EOF
10.0.0.151 k8s151.oldboyedu.com
10.0.0.152 k8s152.oldboyedu.com
10.0.0.153 k8s153.oldboyedu.com
EOF
关闭swap
1.查看swapon分区
swapon -s
2.关闭swapoff
swapoff /dev/sda2
3.再查看一下
swapon -s
4.删除swapon路径
rm -rf /dev/sda2
5.在开机自启里删除swapon
vim /etc/fstab


 浙公网安备 33010602011771号
浙公网安备 33010602011771号