

数据结构化与保存
1.结构化:
- 单条新闻的详情字典:news
- 一个列表页所有单条新闻汇总列表:newsls.append(news)
- 所有列表页的所有新闻汇总列表:newstotal.extend(newsls)
2.转换成pandas的数据结构DataFrame
3.从DataFrame保存到excel
4.从DataFrame保存到sqlite3数据库
import requests from bs4 import BeautifulSoup #from datetime import datetime import re import pandas res=requests.get('http://news.gzcc.cn/html/xiaoyuanxinwen/') res.encoding='utf-8' soup=BeautifulSoup(res.text,'html.parser') def getclick(newsurl): id=re.search('_(.*).html',newsurl).group(1).split('/')[1] clickurl='http://oa.gzcc.cn/api.php?op=count&id={}&modelid=80'.format(id) click=int(requests.get(clickurl).text.split('.')[-1].lstrip("html('").rstrip("');")) return click def getdetail(url): resd=requests.get(url) resd.encoding='utf-8' soupd=BeautifulSoup(resd.text,'html.parser') news={} news['url']=url news['title']=soupd.select('.show-title')[0].text info=soupd.select('.show-info')[0].text #news['dt']=datetime.strptime(info.lstrip('发表时间:')[0:19],'%Y-%m-%d %H:%M:%S') #news['source']=re.search('来源:(.*)点击',info).group(1).strip() news['click']=getclick(url) return (news) def onepage(pageurl): res=requests.get(pageurl) res.encoding='utf-8' soup=BeautifulSoup(res.text,'html.parser') newsls=[] for news in soup.select('li'): if len(news.select('.news-list-title'))>0: newsls.append(getdetail(news.select('a')[0]['href'])) return (newsls) newstotal=[] newstotal.extend(onepage('http://news.gzcc.cn/html/xiaoyuanxinwen/')) n=int(soup.select('.a1')[0].text.rstrip('条')) pages=n//10+1 for i in range(2,3): listurl='http://news.gzcc.cn/html/xiaoyuanxinwen/{}.html'.format(i) newstotal.extend(onepage(listurl)) #print(len(newstotal)) df=pandas.DataFrame(newstotal) print(df.head()) print(df['title']) df.to_excel('gzccnews.xlsx') #with sqlite3.connect('gzccnewsdb2.sqlite') as db: #df.to_sql('gzccnewsdb2',con=db)

从DataFrame保存到excel:
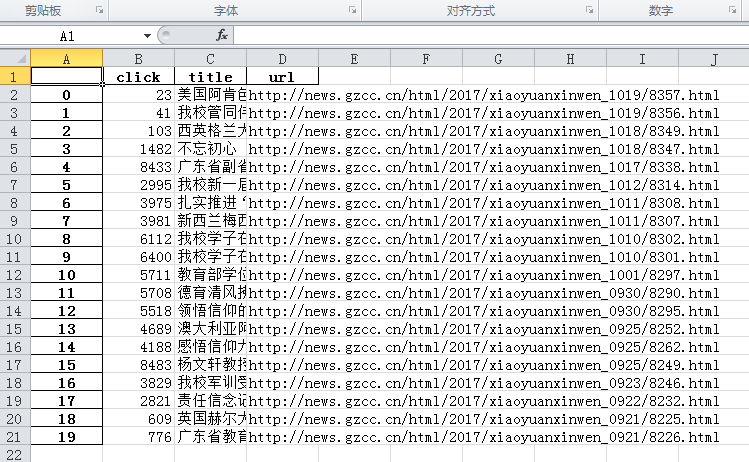

 浙公网安备 33010602011771号
浙公网安备 33010602011771号