Python高级应用程序设计任务
Python高级应用程序设计任务要求
用Python实现一个面向主题的网络爬虫程序,并完成以下内容:
(注:每人一题,主题内容自选,所有设计内容与源代码需提交到博客园平台)
一、主题式网络爬虫设计方案(15分)
1.主题式网络爬虫名称
中华英才网招聘岗位爬虫
2.主题式网络爬虫爬取的内容与数据特征分析
2.主题式网络爬虫爬取的内容与数据特征分析
本爬虫程序爬取中华英才网的岗位信息,主要爬取招聘岗位、公司名称、薪资待遇、学历要求、公司地点、公司类型以及工作经验。爬取的数据基本都是我们求职想要的第一信息。
3.主题式网络爬虫设计方案概述(包括实现思路与技术难点)
3.主题式网络爬虫设计方案概述(包括实现思路与技术难点)
本爬虫首先通过分析,找到其url链接变化,然后爬取url链接,再找到分析的HTML页面中我们想要获取的目标信息,然后再对HTML页面进行数据清洗,获取目标信息,最后将信息存储在文件中。
本次爬虫比较麻烦的是对获取到的数据进行数据清洗,获取目标信息,这也是本爬虫的重点。
二、主题页面的结构特征分析(15分)
1.主题页面的结构特征
1.主题页面的结构特征
首先我们来看下中华英才网的url特征:
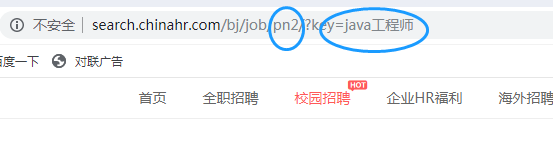
从图中我们可以看到,我们输入的岗位在key后面,页码在pn后面。接下来我们只要对这两处进行修改即可得到我们想要的页面。
2.Htmls页面解析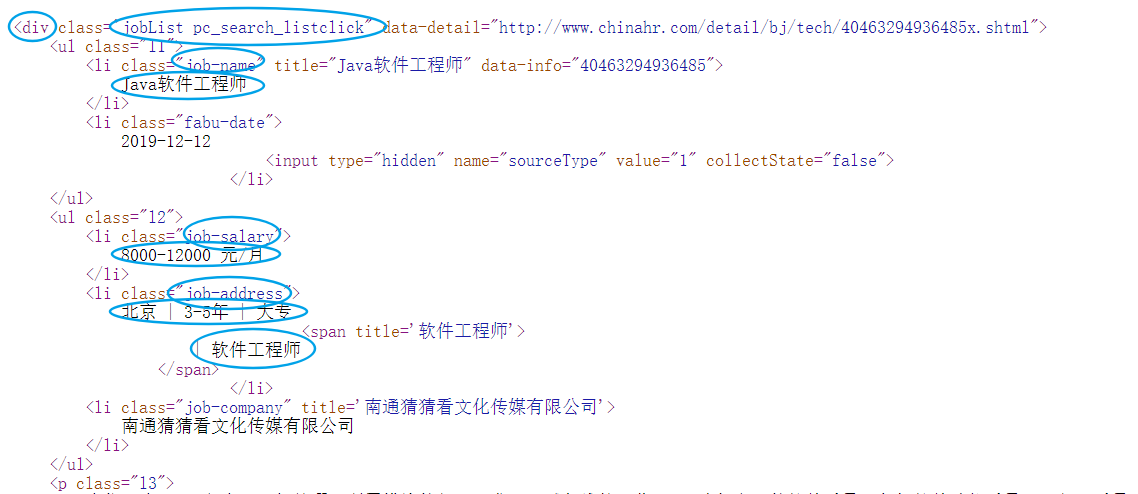
分析页面的HTML代码可以得出,我们想要的数据在属性为class="jobList pc_search_listclick"的div标签中。其中岗位名称在属性为class="job-name"的li标签中;薪资水平在属性为job-salary的li标签中;公司名称在属性为job-company的li标签中;其他信息在属性为job-address的li标签中。
3.节点(标签)查找方法与遍历方法(必要时画出节点树结构)
我们直接用find_all()函数进行遍历即可得到我们想要的信息。
三、网络爬虫程序设计(60分)
爬虫程序主体要包括以下各部分,要附源代码及较详细注释,并在每部分程序后面提供输出结果的截图。
程序代码及运行结果如下:
1 import requests 2 from bs4 import BeautifulSoup 3 import os 4 5 6 #爬取前程无忧目标的HTML页面 7 def getHTMLText(url): 8 try: 9 #假装成浏览器访问 10 kv = {'user-agent':'Mozilla/5.0'} 11 #获取目标页面 12 r = requests.get(url,headers = kv) 13 #判断页面是否链接成功 14 r.raise_for_status() 15 #使用HTML页面内容中分析出的响应内容编码方式 16 r.encoding = r.apparent_encoding 17 #返回页面内容 18 return r.text 19 except: 20 #如果爬取失败,返回“爬取失败” 21 return "爬取失败" 22 23 #获取岗位名称 24 def getData(jlist,slist,clist,alist,html): 25 #创建BeautifulSoup对象 26 soup = BeautifulSoup(html,"html.parser") 27 #遍历所有属性为job-list-box的div标签 28 for div in soup.find_all("div",attrs = "job-list-box"): 29 #将div标签中的标签中属性为job-name的li内容存放在jlist列表中 30 for li in div.find_all("li",attrs = "job-name"): 31 jlist.append(li.string.strip()) 32 #将div标签中的标签中属性为job-salary的li内容存放在slist列表中 33 for li in div.find_all("li",attrs = "job-salary"): 34 slist.append(li.string.strip()) 35 #将div标签中的标签中属性为job-company的li内容存放在clist列表中 36 for li in div.find_all("li",attrs = "job-company"): 37 clist.append(li.string.strip()) 38 #将div标签中的标签中属性为job-address的li内容存放在alist列表中 39 for li in div.find_all("li",attrs = "job-address"): 40 alist.append(li.get_text().strip().replace(' ','')) 41 #返回列表 42 return jlist,slist,clist,alist 43 44 #打印工作信息函数 45 def printUnivList(jlist,slist,clist,alist,num): 46 for i in range(num): 47 print("##################################################") 48 print("公司名称:{}".format(clist[i])) 49 print("岗位名称:{}".format(jlist[i])) 50 print("薪资待遇:{}".format(slist[i])) 51 print("其他要求:{}".format(alist[i])) 52 53 #数据存储 54 def dataSave(jlist,slist,clist,alist,name,num): 55 try: 56 #创建文件夹 57 os.mkdir("C:\招聘信息") 58 except: 59 #如果文件夹存在则什么也不做 60 "" 61 try: 62 #创建文件用于存储爬取到的数据 63 with open("C:\\招聘信息\\"+ name +".txt","w") as f: 64 for i in range(num): 65 f.write("##################################################`\n") 66 f.write("公司名称:{}\n".format(clist[i])) 67 f.write("岗位名称:{}\n".format(jlist[i])) 68 f.write("薪资待遇:{}\n".format(slist[i])) 69 f.write("其他要求:{}\n".format(alist[i])) 70 except: 71 "存储失败" 72 73 #主函数 74 def main(): 75 #中华英才网url链接 76 job = input("请输入工作名称:") 77 head = "http://search.chinahr.com/bj/job/pn" 78 mid = "/?key=" 79 last = "%20" 80 #页数 81 page = 5 82 #用来存放工作名称 83 jlist = [] 84 #用来存放薪资待遇 85 slist = [] 86 #用来存放公司名称 87 clist = [] 88 #用来存放其他要求 89 alist = [] 90 91 #循环加入页码,将每页的信息存在列表中 92 for i in range(page): 93 #加1表示配置实际页码 94 num = i + 1 95 #url配置 96 url = head + str(num) + mid + job + last 97 #获取html页面 98 html = getHTMLText(url) 99 #获取数据 100 getData(jlist,slist,clist,alist,html) 101 #打印结果 102 printUnivList(jlist,slist,clist,alist,page*30) 103 #存储数据 104 dataSave(jlist,slist,clist,alist,job,page*30) 105 106 107 108 #程序入口 109 if __name__ == "__main__": 110 main()
运行结果:
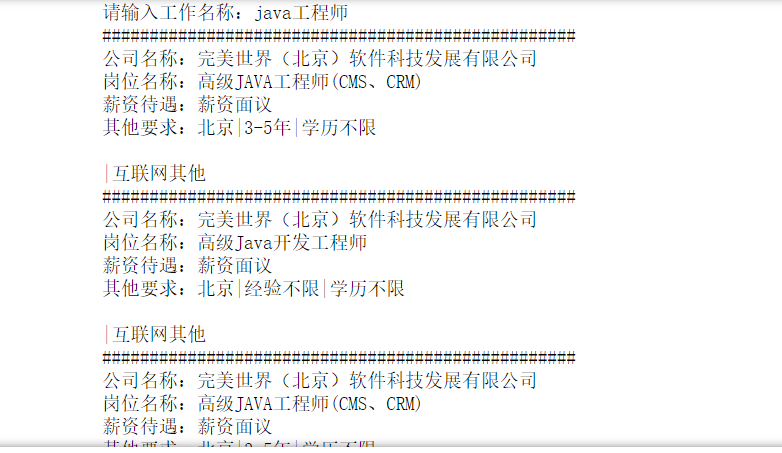
存储文件:
数据爬取与采集模块代码如下:
1 #爬取前程无忧目标的HTML页面 2 def getHTMLText(url): 3 try: 4 #假装成浏览器访问 5 kv = {'user-agent':'Mozilla/5.0'} 6 #获取目标页面 7 r = requests.get(url,headers = kv) 8 #判断页面是否链接成功 9 r.raise_for_status() 10 #使用HTML页面内容中分析出的响应内容编码方式 11 r.encoding = r.apparent_encoding 12 #返回页面内容 13 return r.text 14 except: 15 #如果爬取失败,返回“爬取失败” 16 return "爬取失败"
代码如下:
1 #获取岗位名称 2 def getData(jlist,slist,clist,alist,html): 3 #创建BeautifulSoup对象 4 soup = BeautifulSoup(html,"html.parser") 5 #遍历所有属性为job-list-box的div标签 6 for div in soup.find_all("div",attrs = "job-list-box"): 7 #将div标签中的标签中属性为job-name的li内容存放在jlist列表中 8 for li in div.find_all("li",attrs = "job-name"): 9 jlist.append(li.string.strip()) 10 #将div标签中的标签中属性为job-salary的li内容存放在slist列表中 11 for li in div.find_all("li",attrs = "job-salary"): 12 slist.append(li.string.strip()) 13 #将div标签中的标签中属性为job-company的li内容存放在clist列表中 14 for li in div.find_all("li",attrs = "job-company"): 15 clist.append(li.string.strip()) 16 #将div标签中的标签中属性为job-address的li内容存放在alist列表中 17 for li in div.find_all("li",attrs = "job-address"): 18 alist.append(li.get_text().strip().replace(' ','')) 19 #返回列表 20 return jlist,slist,clist,alist
无
4.数据分析与可视化
4.数据分析与可视化
(例如:数据柱形图、直方图、散点图、盒图、分布图、数据回归分析等)
由于爬取到的岗位薪资大多数为面谈,数据缺乏,故难做分析。
5.数据持久化
5.数据持久化
代码如下:
1 #数据存储 2 def dataSave(jlist,slist,clist,alist,name,num): 3 try: 4 #创建文件夹 5 os.mkdir("C:\招聘信息") 6 except: 7 #如果文件夹存在则什么也不做 8 "" 9 try: 10 #创建文件用于存储爬取到的数据 11 with open("C:\\招聘信息\\"+ name +".txt","w") as f: 12 for i in range(num): 13 f.write("##################################################\n") 14 f.write("公司名称:{}\n".format(clist[i])) 15 f.write("岗位名称:{}\n".format(jlist[i])) 16 f.write("薪资待遇:{}\n".format(slist[i])) 17 f.write("其他要求:{}\n".format(alist[i])) 18 except: 19 "存储失败"
四、结论(10分)
1.经过对主题数据的分析与可视化,可以得到哪些结论?
1.经过对主题数据的分析与可视化,可以得到哪些结论?
通过对中华英才网的岗位信息爬取发现,中华英才网的岗位信息太少,而且大多数信息没给出一个明确的薪资待遇水平,故若想找工作,不建议在这上面进行查找。
2.对本次程序设计任务完成的情况做一个简单的小结。
2.对本次程序设计任务完成的情况做一个简单的小结。
通过本次程序设计,巩固了课堂上学到的知识,加深的自己的编程能力,也为自己能够自己写出一套较为系统的爬虫程序而感到高兴。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号