第3次作业-MOOC学习笔记:Python网络爬虫与信息提取
1.注册中国大学MOOC
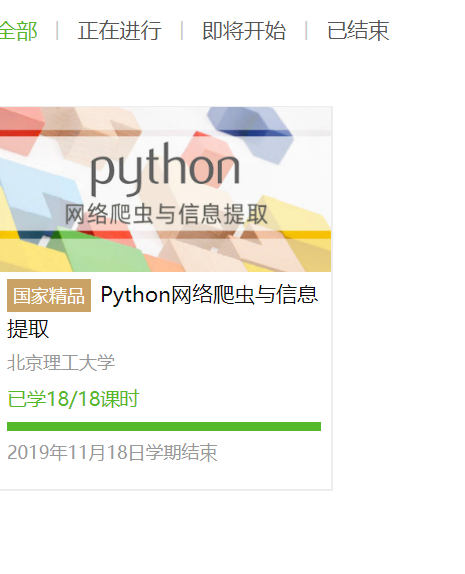
2.选择北京理工大学嵩天老师的《Python网络爬虫与信息提取》MOOC课程
3.学习完成第0周至第4周的课程内容,并完成各周作业


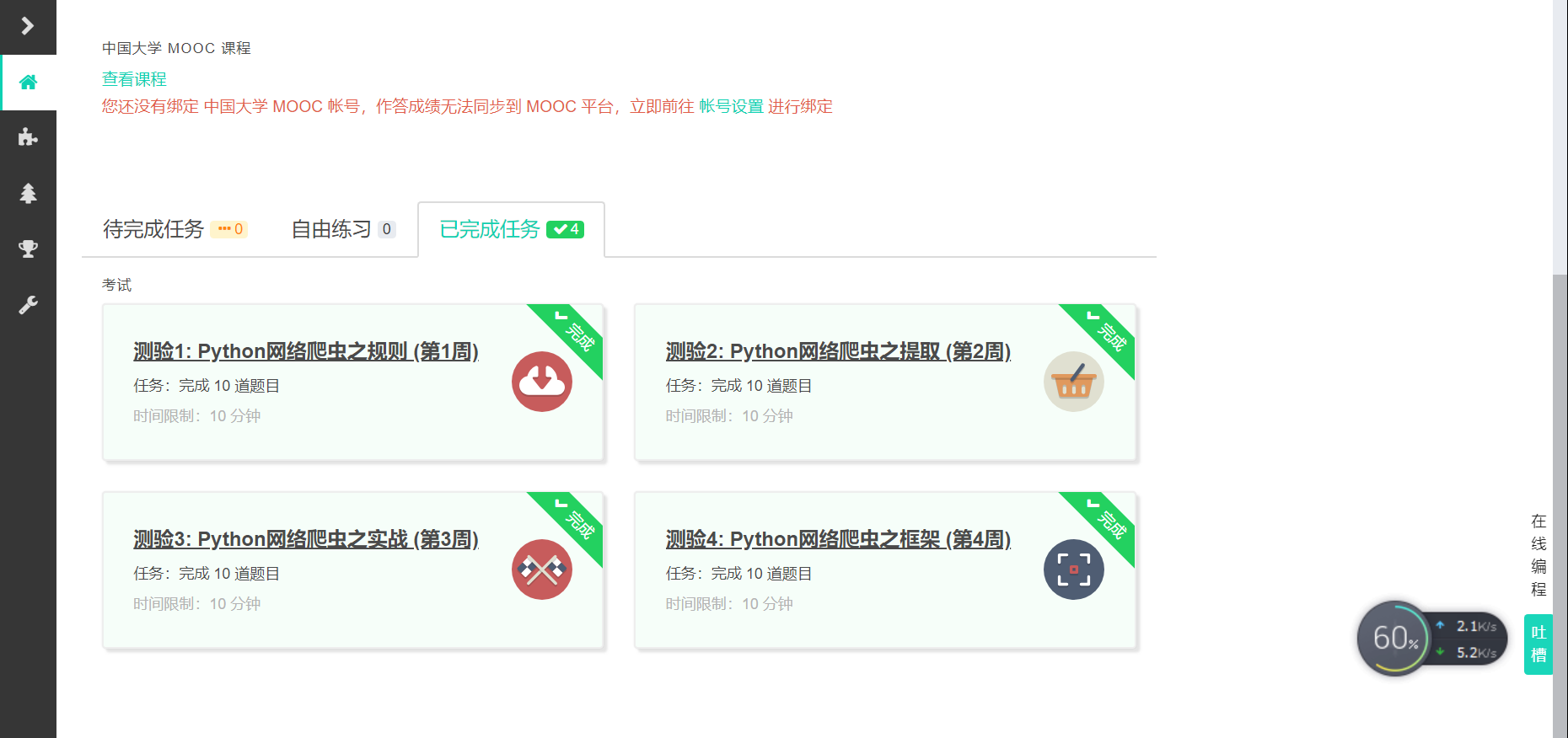
4.提供图片或网站显示的学习进度,证明学习的过程。
5.写一篇不少于1000字的学习笔记,谈一下学习的体会和收获。
很高兴能有机会在网上学习 Python 网络爬虫与信息提取这门课,通过这门课的学习,我一步步加深了对Python的理解,教学主要分为网络爬虫之前奏,规则,提取,实战,框架,这五个五部分。
在前奏中,个给我们介绍了常用的Python IDE 工具,以及各类开发工具的选择。在网络爬虫之规则中着重介绍了Requests 库,requests库是Python实现的最简单易用的HTTP库,是网络爬虫入学推荐使用的。在此单元中的网络爬虫的盗亦有道中还介绍了网络爬虫会遇到的一系列问题:1性能骚扰:受限于编写水平和目的,网络爬虫将会为web服务器带来巨大的资源开销2法律风险:服务器上的数据有产权归属,网路爬虫获取数据后牟利将带来法律风险。3隐私泄露:网络爬虫可能具备突破简单访问控制的能力,获得被保护数据从而泄露个人隐私。以及如何遵守Robots协议,及其重要性危险性。在requests库网络爬虫实战中介绍了五个实例,分别为京东商品页面亚马逊商品页面的抓取等。
在第二周网络爬虫之提取中,我们继续学习了beautiful soup库入门,信息组织与提取方法以及一个实例。
在第三周中我们认识了Re库(正则表达式)的入门,则表达式(英文名称:regular expression,regex,RE)是用来简洁表达一组字符串特征的表达式。最主要应用在字符串匹配中。
.re.I(re.IGNORECASE): 忽略大小写
2).re.M(MULTILINE): 多行模式,改变’^‘和’$‘的行为
3).re.S(DOTALL): 点任意匹配模式,改变’.'的行为
4).re.L(LOCALE): 使预定字符类 \w \W \b \B \s \S 取决于当前区域设定
.re.U(UNICODE): 使预定字符类 \w \W \b \B \s \S \d \D 取决于unicode定义的字符属性6).re.X(VERBOSE): 详细模式。这个模式下正则表达式可以是多行,忽略空白字符,并可以加入注释
在最后一周的学习中我们了解了Scrapy 爬虫架构,在基本使用中,介绍了yield关键字和生成器,requests,response,item,selector,scrapy是应用最广泛的爬虫框架,没有之一,而且是成熟度最高的框架,可利用成熟产品,避免重复“造轮子”,可以更快速的构建项目。Scrap也是Python开发的一个快速、高层次的屏幕抓取和web抓取框架,用于抓取web站点并从页面中提取结构化的数据。Scrapy用途广泛,可以用于数据挖掘、监测和自动化测试。是你学习爬虫绝对会用到的一个框架。学习一些抓包知识,有些网站防爬,需要人工浏览一些页面,抓取数据包分析防爬机制,然后做出应对措施。比如解决cookie问题,或者模拟设备等。
“互联网是功能集合,更是存储空间;海量数据孕育巨大价值,数据采集需求迫切。网络爬虫已经成为自动获取互联网数据的主要方式,数据就在那里,它是你的吗?”正如课程介绍的这句话说的一样,掌握利用Python爬取网络数据并提取信息的"小"本领是一个对我们十分受用的。通过这一系列的学习,对网络爬虫不敢说有多大程度的认知。但也有了初步了解,希望在将来有机会进一步对其深入了解,学以致用!

 浙公网安备 33010602011771号
浙公网安备 33010602011771号