Oracle分析函数Over()
Over()分析函数
说明:聚合函数(如sum()、max()等)可以计算基于组的某种聚合值,但是聚合函数对于某个组只能返回一行记录。若想对于某组返回多行记录,则需要使用分析函数。
rank()/dense_rank over(partition by ... order by ...)
说明:over()在什么条件之上;
partition by 按哪个字段划分组;
order by 按哪个字段排序;
注意:
(1)使用rank()/dense_rank() 时,必须要带order by否则非法
(2)rank()/dense_rank()分级的区别:
rank(): 跳跃排序,如果有两个第一级时,接下来就是第三级。
dense_rank(): 连续排序,如果有两个第一级时,接下来仍然是第二级。
示例:查询每个部门工资最高的员工信息
一般的写法
SELECT E.ENAME, E.JOB, E.SAL, E.DEPTNO FROM SCOTT.EMP E, (SELECT E.DEPTNO, MAX(E.SAL) SAL FROM SCOTT.EMP E GROUP BY E.DEPTNO) ME WHERE E.DEPTNO = ME.DEPTNO AND E.SAL = ME.SAL;
使用Over()函数
方法一:
SELECT E.ENAME, E.JOB, E.SAL, E.DEPTNO FROM (SELECT E.ENAME, E.JOB, E.SAL, E.DEPTNO, RANK() OVER(PARTITION BY E.DEPTNO ORDER BY E.SAL DESC) RANK --在按部门划分的基础上,工资从高到低分级,级别RANK从1开始依次递增 FROM EMP E) E WHERE E.RANK = 1 ;
方法二:
SELECT E.ENAME, E.JOB, E.SAL, E.DEPTNO FROM (SELECT E.ENAME, E.JOB, E.SAL, E.DEPTNO, DENSE_RANK() OVER(PARTITION BY E.DEPTNO ORDER BY E.SAL DESC) RANK FROM EMP E) E WHERE E.RANK = 1;
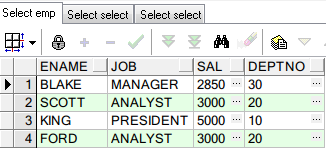
对比查询结果:左边的是用一般的方法查询结果,右边的是分析函数查询结果(两种方法结果相同)

min()/max() over(partition by ...)
查询员工信息的同时,查询员工工资与所在部门最低、最高工资的差额
一般的写法:
SELECT E.ENAME, E.JOB, E.SAL, E.DEPTNO, E.SAL - ME.MIN_SAL DIFF_MIN_SAL, ME.MAX_SAL - E.SAL DIFF_MAX_SAL FROM SCOTT.EMP E, (SELECT E.DEPTNO, MIN(E.SAL) MIN_SAL, MAX(E.SAL) MAX_SAL FROM SCOTT.EMP E GROUP BY E.DEPTNO) ME WHERE E.DEPTNO = ME.DEPTNO ORDER BY E.DEPTNO, E.SAL;
使用分析函数:
SELECT E.ENAME, E.JOB, E.SAL, E.DEPTNO, MIN(E.SAL) OVER(PARTITION BY E.DEPTNO) MIN_SAL, MAX(E.SAL) OVER(PARTITION BY E.DEPTNO) MAX_SAL, NVL(E.SAL - MIN(E.SAL) OVER(PARTITION BY E.DEPTNO), 0) DIFF_MIN_SAL, NVL(MAX(E.SAL) OVER(PARTITION BY E.DEPTNO) - E.SAL, 0) DIFF_MAX_SAL FROM EMP E;
注:这里没有排序条件,若加上order by 排序条件,
MAX() OVER(PARTITION BY .. ORDER BY .. DESC) 排序规则只能为desc,否则不起作用,将查询到目前为止排序值最高字段的对应值
MIN() OVER(PARTITION BY .. ORDER BY .. ASC ) 排序规则只能为asc,否则不起作用,将查询到目前为止排序值最低的字段的对应值,
如下:
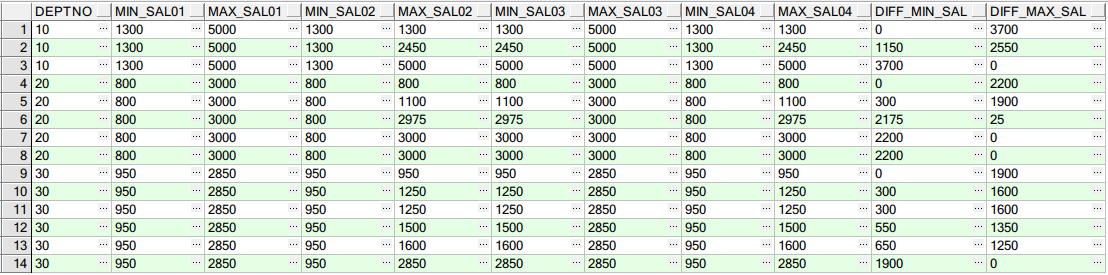
SELECT E.ENAME, E.JOB, E.SAL, E.DEPTNO, MIN(E.SAL) OVER(PARTITION BY E.DEPTNO) MIN_SAL01, MAX(E.SAL) OVER(PARTITION BY E.DEPTNO) MAX_SAL01, MIN(E.SAL) OVER(PARTITION BY E.DEPTNO ORDER BY E.SAL) MIN_SAL02, MAX(E.SAL) OVER(PARTITION BY E.DEPTNO ORDER BY E.SAL) MAX_SAL02, --不起作用 MIN(E.SAL) OVER(PARTITION BY E.DEPTNO ORDER BY E.SAL DESC) MIN_SAL03, --不起作用 MAX(E.SAL) OVER(PARTITION BY E.DEPTNO ORDER BY E.SAL DESC) MAX_SAL03, MIN(E.SAL) OVER(PARTITION BY E.DEPTNO ORDER BY E.SAL ASC) MIN_SAL04, MAX(E.SAL) OVER(PARTITION BY E.DEPTNO ORDER BY E.SAL ASC) MAX_SAL04, --不起作用 NVL(E.SAL - MIN(E.SAL) OVER(PARTITION BY E.DEPTNO), 0) DIFF_MIN_SAL, NVL(MAX(E.SAL) OVER(PARTITION BY E.DEPTNO) - E.SAL, 0) DIFF_MAX_SAL FROM EMP E;
结果如下:
lead()/lag() over(partition by ... order by ...) 取前面/后面第n行记录
说明:
lead(列名,n,m): 当前记录后面第n行记录的<列名>的值,没有则默认值为m;如果不带参数n,m,则查找当前记录后面第一行的记录<列名>的值,没有则默认值为null。
lag(列名,n,m): 当前记录前面第n行记录的<列名>的值,没有则默认值为m;如果不带参数n,m,则查找当前记录前面第一行的记录<列名>的值,没有则默认值为null。
示例:查询个人工资与比自己高一位、第一位的工资的差额
使用分析函数
SELECT E.ENAME, E.JOB, E.SAL, E.DEPTNO, LEAD(E.SAL, 1, 0) OVER(PARTITION BY E.DEPTNO ORDER BY E.SAL) LEAD_SAL, --记录后面第n行记录 LAG(E.SAL, 1, 0) OVER(PARTITION BY E.DEPTNO ORDER BY E.SAL) LAG_SAL, --记录前面第N行记录 NVL(LEAD(E.SAL) OVER(PARTITION BY E.DEPTNO ORDER BY E.SAL) - E.SAL, 0) DIFF_LEAD_SAL, NVL(E.SAL - LEAD(E.SAL) OVER(PARTITION BY E.DEPTNO ORDER BY E.SAL), 0) DIFF_LAG_SAL FROM EMP E;
查询结果:

FIRST_VALUE/LAST_VALUE() OVER(PARTITION BY ...) 取首尾记录
示例:
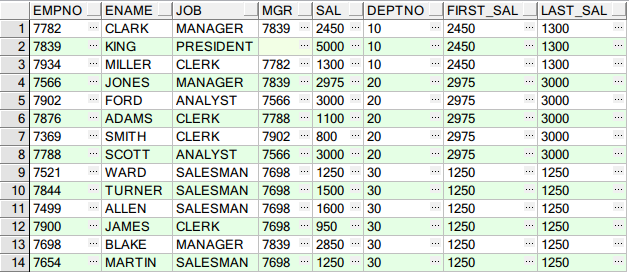
SELECT E.EMPNO, E.ENAME, E.JOB, E.MGR, E.SAL, E.DEPTNO, FIRST_VALUE(E.SAL) OVER(PARTITION BY E.DEPTNO) FIRST_SAL, LAST_VALUE(E.SAL) OVER(PARTITION BY E.DEPTNO) LAST_SAL FROM EMP E;
查询结果:
ROW_NUMBER() OVER(PARTITION BY.. ORDER BY ..) 排序(应用:分页)
SELECT E.ENAME, E.JOB, E.SAL, E.DEPTNO,E.ROW_NUM FROM (SELECT E.ENAME, E.JOB, E.SAL, E.DEPTNO, ROW_NUMBER() OVER(PARTITION BY E.DEPTNO ORDER BY E.SAL) ROW_NUM FROM EMP E) E WHERE E.ROW_NUM > 3;
查询结果:

补充:
类似分页的操作还可以用rownum、fetch(Oracle12C后的新特性)实现
sum/avg/count() over(partition by ..)
示例1:
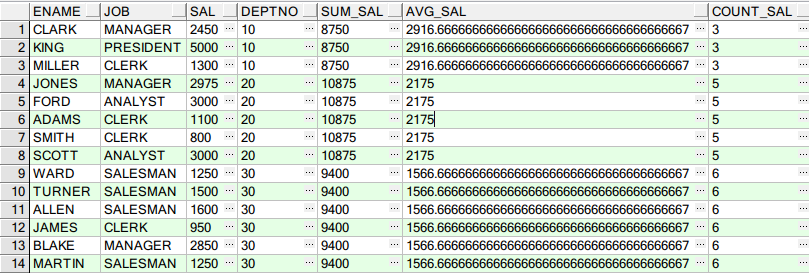
SELECT E.ENAME, E.JOB, E.SAL, E.DEPTNO, SUM(E.SAL) OVER(PARTITION BY E.DEPTNO) SUM_SAL, --统计某组中的总计值 AVG(E.SAL) OVER(PARTITION BY E.DEPTNO) AVG_SAL, --统计某组中的平均值 COUNT(E.SAL) OVER(PARTITION BY E.DEPTNO) COUNT_SAL --按某列分组,并统计该组中记录数量 FROM EMP E;
查询结果:
示例2(全统计):为数据集统计部门销售总和,全公司销售总和,部门销售均值,全公司销售均值
SELECT A.DEPT_ID, A.SALE_DATE, A.GOODS_TYPE, A.SALE_CNT, SUM(A.SALE_CNT) OVER(PARTITION BY A.DEPT_ID) DEPT_TOTAL, --部门销售总和 SUM(A.SALE_CNT) OVER() CMP_TOTAL, --公司销售总额 AVG(A.SALE_CNT) OVER(PARTITION BY A.DEPT_ID) DEPT_AVG, --部门销售均值 AVG(A.SALE_CNT) OVER() CMP_AVG --公司销售均值 FROM LEARN_FUN_KEEP A;
rows/range between … preceding and … following 上下范围内求值
说明:unbounded:不受控制的,无限的
preceding:在...之前
following:在...之后
rows between … preceding and … following
示例1:显示各部门员工的工资,并附带显示该部门的最高工资
SELECT E.DEPTNO, E.EMPNO, E.ENAME, E.SAL, LAST_VALUE(E.SAL) OVER(PARTITION BY E.DEPTNO ORDER BY E.SAL ROWS /*MAX(E.SAL) OVER(PARTITION BY E.DEPTNO ORDER BY E.SAL ROWS*/ --unbounded preceding and unbouned following针对当前所有记录的前一条、后一条记录,也就是表中的所有记录 --unbounded:不受控制的,无限的 --preceding:在...之前 --following:在...之后 BETWEEN UNBOUNDED PRECEDING AND UNBOUNDED FOLLOWING) MAX_SAL FROM EMP E;
结果如下:
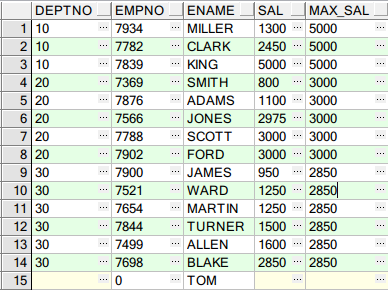
写法二;
SELECT E.DEPTNO, E.EMPNO, E.ENAME, E.SAL, MAX(E.SAL) OVER(PARTITION BY E.DEPTNO /*ORDER BY E.SAL*/) MAX_SAL FROM EMP E;
示例2:对各部门进行分组,并附带显示第一行至当前行的汇总
SELECT EMPNO, ENAME, DEPTNO, SAL, --注意ROWS BETWEEN unbounded preceding AND current row 是指第一行至当前行的汇总 SUM(SAL) OVER(PARTITION BY DEPTNO ORDER BY ENAME ROWS BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW) max_sal FROM SCOTT.EMP;
结果如下:
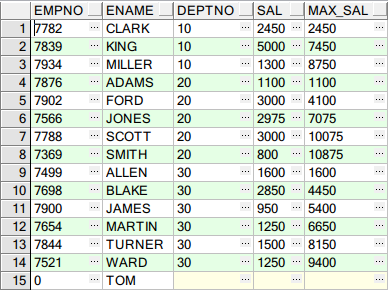
示例3:当前行至最后一行的汇总
SELECT EMPNO, ENAME, DEPTNO, SAL, --注意ROWS BETWEEN current row AND unbounded following 指当前行到最后一行的汇总 SUM(SAL) OVER(PARTITION BY DEPTNO ORDER BY ENAME ROWS BETWEEN CURRENT ROW AND UNBOUNDED FOLLOWING) max_sal FROM SCOTT.EMP;
结果如下:
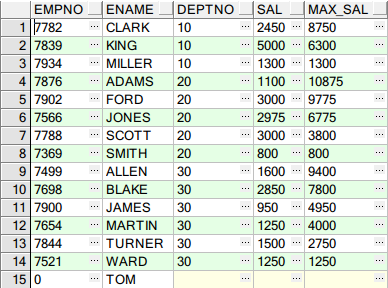
示例4:当前行的上一行(rownum-1)到当前行的汇总
SELECT EMPNO, ENAME, DEPTNO, SAL, --注意ROWS BETWEEN 1 preceding AND current row 是指当前行的上一行(rownum-1)到当前行的汇总 SUM(SAL) OVER(PARTITION BY DEPTNO ORDER BY ENAME ROWS BETWEEN 1 PRECEDING AND CURRENT ROW) max_sal FROM SCOTT.EMP;
结果如下:
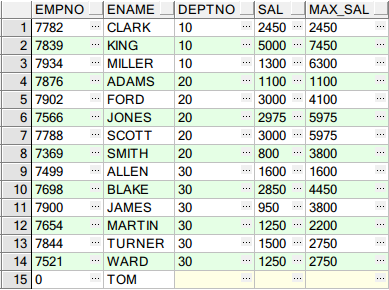
示例5:当前行的上一行(rownum-1)到当前行的下两行(rownum+2)的汇总
SELECT EMPNO, ENAME, DEPTNO, SAL, --注意ROWS BETWEEN 1 preceding AND 1 following 是指当前行的上一行(rownum-1)到当前行的下辆行(rownum+2)的汇总 SUM(SAL) OVER(PARTITION BY DEPTNO ORDER BY ENAME ROWS BETWEEN 1 PRECEDING AND 2 FOLLOWING) max_sal FROM SCOTT.EMP;
结果如下:
其他
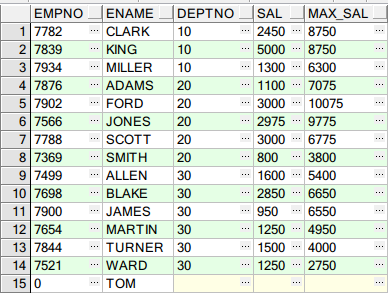
NULLS FIRST/LAST 将空值字段记录放到最前或最后显示
说明:
通过RANK()、DENSE_RANK()、ROW_NUMBER()对记录进行全排列、分组排列取值,但有时候,会遇到空值的情况,空值会影响得到的结果的正确性
NULLS FIRST/LAST 可以帮助我们在处理含有空值的排序排列中,将空值字段记录放到最前或最后显示,帮助我们得到期望的结果。
SELECT E.ENAME, E.JOB, E.SAL, E.DEPTNO, RANK() OVER(PARTITION BY E.DEPTNO ORDER BY E.SAL NULLS LAST) FROM EMP E;
结果如下:
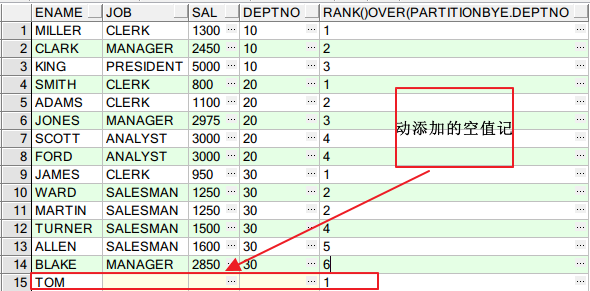
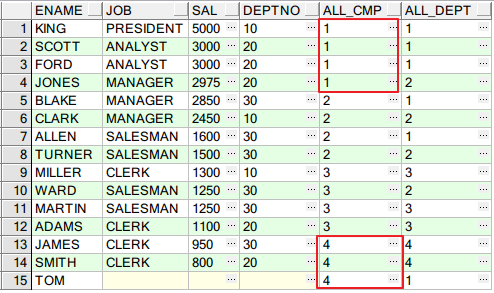
NTILE(n)
SELECT E.ENAME, E.JOB, E.SAL, E.DEPTNO, NTILE(3) OVER(ORDER BY E.SAL DESC NULLS LAST) ALL_CMP, --若只取前三分之一,all_cmp=1即可,若只取中间三分之一,all_cmp=2即可 NTILE(3) OVER(PARTITION BY E.DEPTNO ORDER BY E.SAL DESC NULLS LAST) ALL_DEPT --每个部门的分成三部分 FROM EMP E
结果如下:
keep(dense_rank first/last)
说明:
1.keep(dense_rank first/last) 这句话的含义是什么?
keep 字面意思就是'保持',也就是说保存满足keep()括号内条件的记录
这里我们应该可以想象到,会有多条记录的情况,即存在多个last或first的情况)
dense_rank 是排序策略
first/last 是筛选策略
关于问题2:
使用min的原因是让最后得到的结果唯一,因为有时会存在多个last或first的情况。
3.为什么使用dense_rank ? rank不可以吗?
ORA-02000: 缺失 DENSE_RANK 关键字
换成rank以后直接报错了,至于原因,我的理解是rank不能表示记录排序的相对顺序
例如: 记录 rank dense_rank
100 1 1
100 1 1
95 3 2
第三条记录与第一条和第二条记录的相对位置应该差1,但是用rank无法表示这一点。
示例:
查看部门 D02 内,销售记录时间最早,销售量最小的记录。
SELECT A.DEPT_ID, MIN(A.SALE_CNT) KEEP(DENSE_RANK FIRST ORDER BY A.SALE_DATE) MIN_EARLY_DATE FROM LEARN_FUN_KEEP A WHERE A.DEPT_ID = 'D02' GROUP BY A.DEPT_ID;

 浙公网安备 33010602011771号
浙公网安备 33010602011771号