
结对第二次—文献摘要热词统计及进阶需求
**课程: ** 软件工程1916|W(福州大学)
**作业要求: ** 结对第二次—文献摘要热词统计及进阶需求
结对成员:131601207 陈序展、221600440 郑晓彪
**本次作业目标: **在实现对文本文件中的单词的词频进行统计的控制台程序的基础上,编程实现顶会热词统计器
项目:Github地址
目录
WordCount
(一) WordCount基本需求
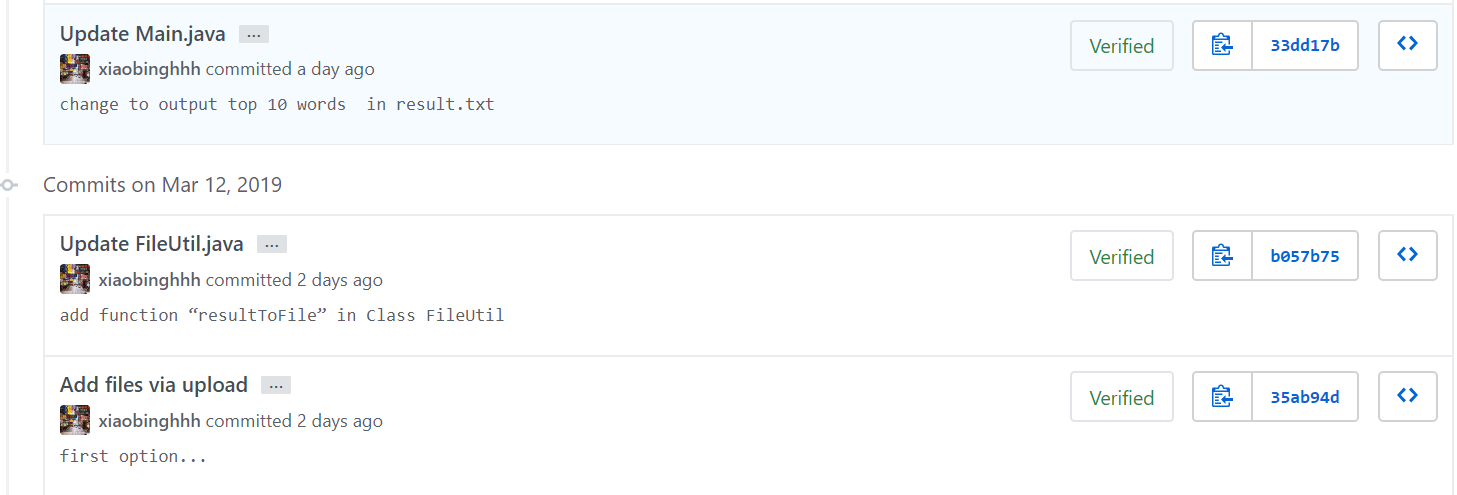
GitHub地址:PairProject1-Java
GitHub代码签入记录
解题思路
- 实现功能
- 统计文件的字符数:利用正则表达式“\p{ASCII}”或“[\x00-\x7F]”匹配ascii码
- 统计文件的单词总数:同样利用正则表达式对特殊定义的单词进行匹配
- 统计文件的有效行数:在文件读入过程中进行统计
- 统计文件中各单词的出现次数,最终只输出频率最高的10个,频率相同的单词,优先输出字典序靠前的单词:利用键值对存储结构分别存储单词和其次数,再进行排序输出
- 按照格式输出:将结果连接成字符串,输出到文件result.txt(当前目录,一般为bin文件夹下)
- 接口封装
可以将文件处理与字符串处理分开:
- 编写FileUtil工具类,通过Main主类传进来的第一个参数解析对应路径文件的文本,并在解析过程中利用java读取文本文件的readLine( )方法对文本行数进行统计,并最后解析为一个字符串传给统计类进行统计;
- 接着编写Counter类,通过FileUtil解析来的文本构造Counter类,在构造函数中利用replaceAll( )方法将换行‘\r\n’换做‘\n’以达到换行符只统计一次,而后编写类中的charCnt方法进行字符统计;编写wordCnt方法进行单词统计处理,单词的匹配过程可以通过正则表达式提高效率
实现过程
-
整体想法流程图
![]()
-
具体类图
![]()
-
代码说明
- 文件内容转字符串


@SuppressWarnings("resource")
public String FiletoText() throws IOException {
InputStream is = new FileInputStream(filePath);
int char_type; // 用来保存每行读取的内容
BufferedReader reader = new BufferedReader(new InputStreamReader(is));
while ((char_type = reader.read()) != -1) { // 如果 line 为空说明读完了
sb.append((char) char_type); // 将读到的内容添加到 buffer 中
}
return sb.toString();
}
- 统计行数
@SuppressWarnings("resource")
public void lineCount() throws IOException {
BufferedReader br = new BufferedReader(new FileReader(filePath));
String readline;
while ((readline = br.readLine()) != null) {
readline = readline.trim();// 去除空白行
if (readline.length() != 0)
lineCnt++;
}
}
- 统计字符数
public void charCount() {
String charRegex = "[\\x00-\\x7F]";// [\p{ASCII}]
Pattern p = Pattern.compile(charRegex);
Matcher m = p.matcher(text);
while (m.find()) {
charCnt++;
}
}
- map按单词数降序单词按字典序排序
public static <K extends Comparable<? super K>, V extends Comparable<? super V>> Map<K, V> sortMap(Map<K, V> map) {
List<Map.Entry<K, V>> list = new LinkedList<Map.Entry<K, V>>(map.entrySet());
Collections.sort(list, new Comparator<Map.Entry<K, V>>() {
public int compare(Map.Entry<K, V> o1, Map.Entry<K, V> o2) {
int re = o2.getValue().compareTo(o1.getValue());
if (re != 0)
return re;
else
return o1.getKey().compareTo(o2.getKey());
}
});
Map<K, V> result = new LinkedHashMap<K, V>();
for (Map.Entry<K, V> entry : list) {
result.put(entry.getKey(), entry.getValue());
}
return result;
}
- 统计单词数
Map<String, Integer> wordCount() {
String lowerText = text.toLowerCase();
String splitRegex = "[^a-z0-9]";// 分隔符
lowerText = lowerText.replaceAll(splitRegex, " ");// 将非字母数字替换为空格
String words[] = lowerText.split("\\s+");// 利用空白分割所有单词
String wordRegex = "[a-z]{4,}[a-z0-9]*";// 单词匹配正则表达式
for (int i = 0; i < words.length; i++) {
Pattern p = Pattern.compile(wordRegex);
Matcher m = p.matcher(words[i]);
if (m.find()) {// 符合单词定义
wordCnt++;
Integer num = map.get(words[i]);
if (num == null || num == 0) {
map.put(words[i], 1); // map中无该单词,数量置1
} else if (num > 0) {
map.put(words[i], num + 1); // map中有该单词,数量加1
}
}
}
map = sortMap(map);
return map;
}
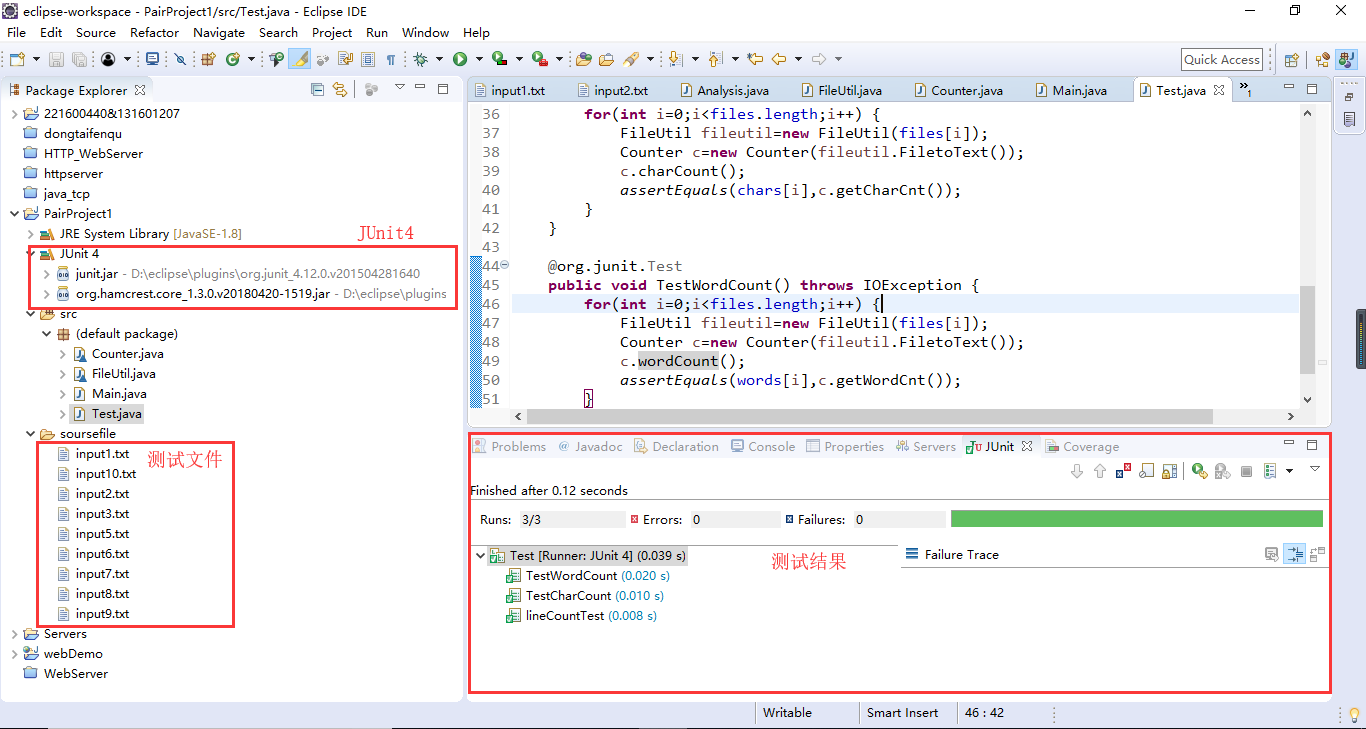
- 单元测试
利用包括助教所给的两个用例(input1.txt、input2.txt)以及一个空文件(input3.txt)等近10个测试文件对代码进行了简单的测试
测试数据主要测试特殊定义单词格式(单词定义:至少以4个英文字母开头,跟上字母数字符号,单词以分隔符分割,不区分大小写)是否能正确匹配并统计以及测试处理一些空白符、换行符、空行等,以下给出部分测试数据:
a0a0a0a0a0a0a0a0a0a0a0a0a0a0a0a0
aaa0a0a0a0a0a0a0a0a0a0a0a0a0a0a0
0aa0a0a0a0a0a0a0a0a0a0a0a0a0a0a0
00a0a0a0a0a0a0a0a0a0a0a0a0a0a0a0
aaaaa0a0a0a0a0a0a0a0a0a0a0a0a0a0
aaaa00a0a0a0a0a0a0a0a0a0a0a0a0a0
NOT_EMPTY_LINE
利用JUnit将测试数据一起进行字符统计、行数统计、单词数统计单元测试后结果如下
另,对单词字典序输出过程未进行单元测试,以下给出字典序测试数据及运行结果
- 字典序测试数据:
windows2000
windows8
windows7
win7
windows2000
windows2000
windows2000
windows2000
windows2000
windows2000
windows95
windows98
windows98
windows95
windows98
windows98
windows95
windows95
windows9
windows9
windows9
windows9
- 运行结果如下:
characters: 224
words: 21
lines: 22
<windows2000>: 7
<windows9>: 4
<windows95>: 4
<windows98>: 4
<windows7>: 1
<windows8>: 1
- 测试代码
分别对lineCount()、CharCount()、WordCount()三个方法进行测试
import static org.junit.Assert.*;
import java.io.IOException;
import org.junit.AfterClass;
import org.junit.BeforeClass;
public class Test {
String files[]= {"soursefile\\input1.txt","soursefile\\input2.txt","soursefile\\input3.txt",
"soursefile\\input5.txt","soursefile\\input6.txt","soursefile\\input7.txt",
"soursefile\\input8.txt","soursefile\\input9.txt","soursefile\\input10.txt"};
int lines[]= {2,3,0,6,1,1,7,22,20};
int chars[]= {102,76,0,197,40,36,358,224,99};
int words[]= {2,1,0,2,2,0,14,21,20};
@BeforeClass
public static void setUpBeforeClass() {
System.out.println("开始测试...");
}
@AfterClass
public static void tearDownAfterClass() {
System.out.println("测试结束...");
}
@org.junit.Test
public void lineCountTest() throws IOException {
for(int i=0;i<files.length;i++) {
FileUtil fileutil=new FileUtil(files[i]);
fileutil.lineCount();
assertEquals(lines[i],fileutil.getLineCnt());
}
}
@org.junit.Test
public void TestCharCount() throws IOException {
for(int i=0;i<files.length;i++) {
FileUtil fileutil=new FileUtil(files[i]);
Counter c=new Counter(fileutil.FiletoText());
c.charCount();
assertEquals(chars[i],c.getCharCnt());
}
}
@org.junit.Test
public void TestWordCount() throws IOException {
for(int i=0;i<files.length;i++) {
FileUtil fileutil=new FileUtil(files[i]);
Counter c=new Counter(fileutil.FiletoText());
c.wordCount();
assertEquals(words[i],c.getWordCnt());
}
}
}
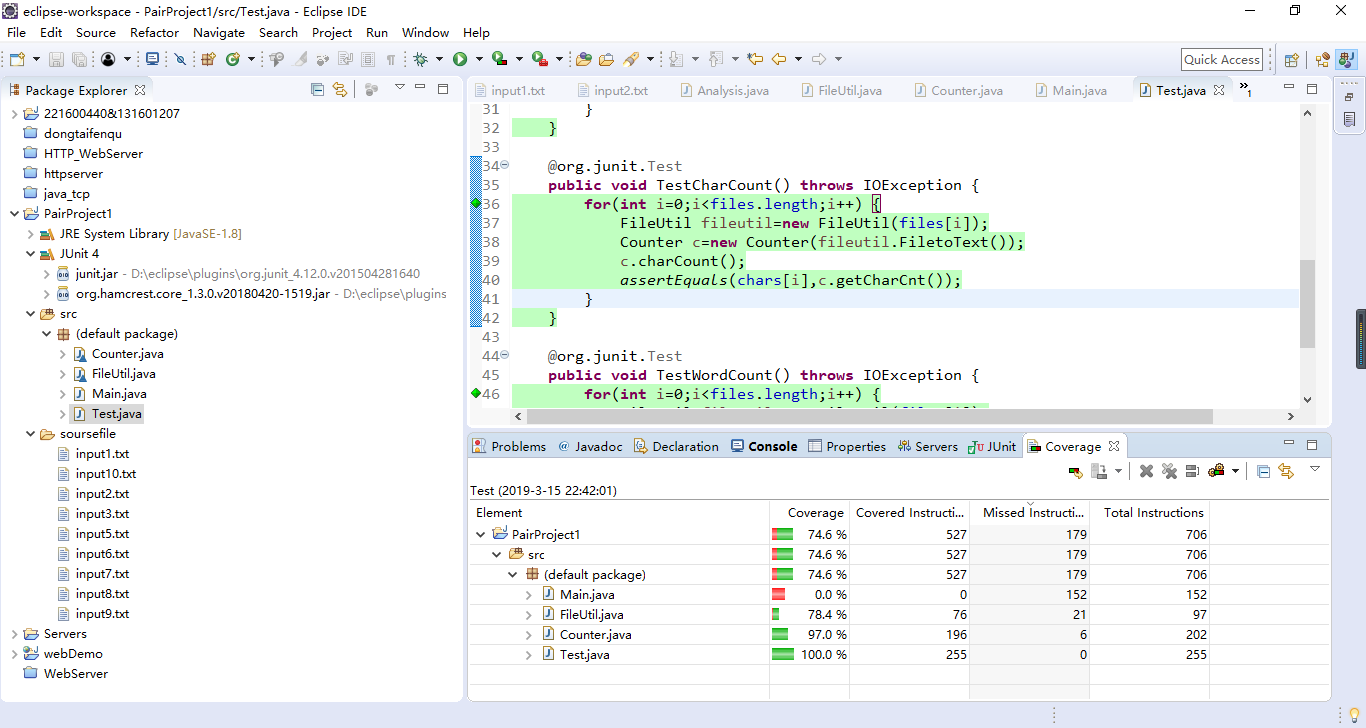
- 代码覆盖率
![]()
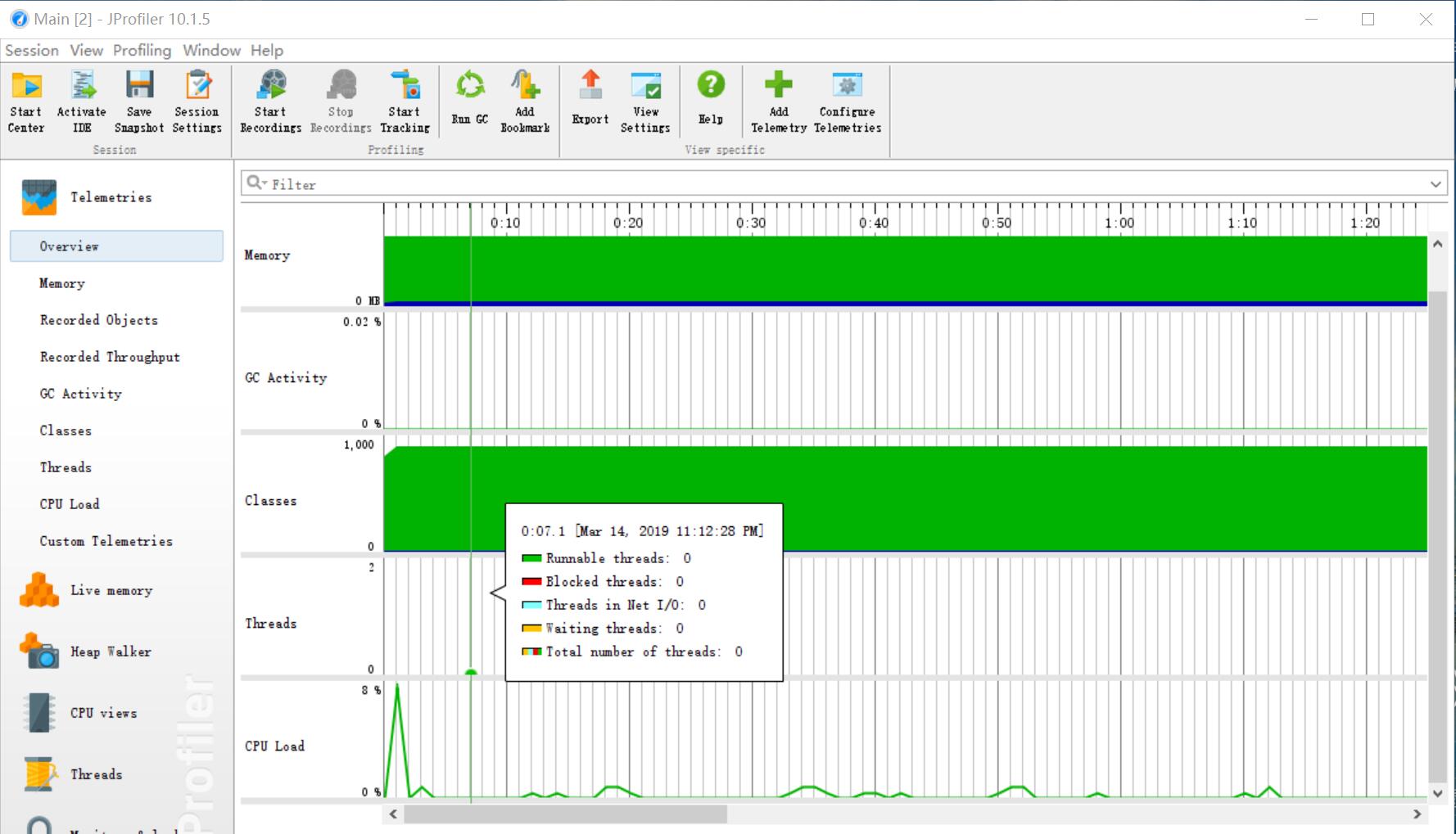
性能分析
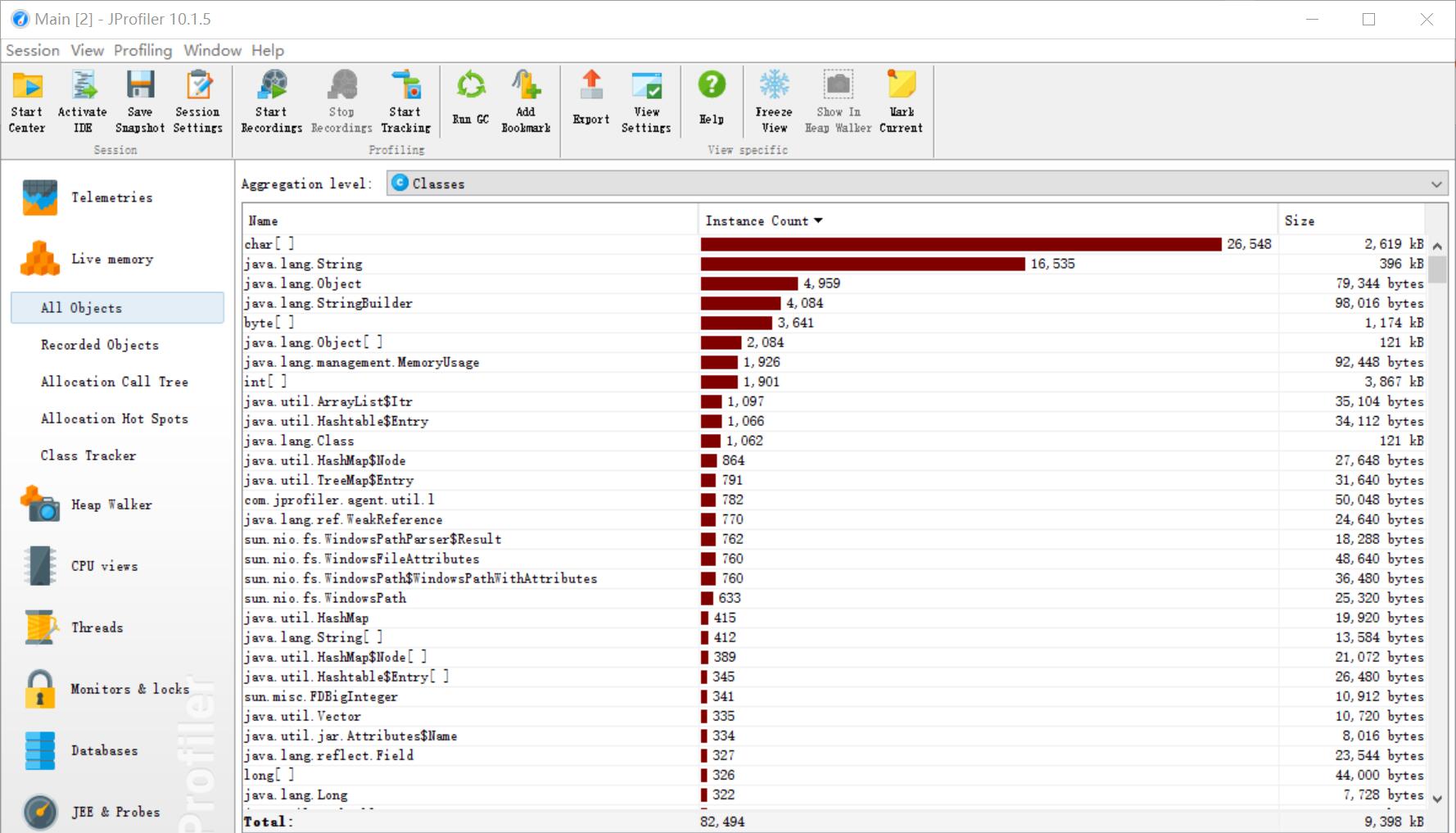
- 改进思路:考虑到单词匹配的方便快捷性,本次学习使用了Java中利用正则表达式匹配的方法,并主要利用jdk提供的工具类编写代码
利用工具JProfiler测试助教其中一个样例后得到以下分析结果,可见Counter类中的wordCount方法消耗最大,其中不仅使用了map的排序还使用了String对象的split方法方便使用正则匹配
![]()
![]()
(二)WordCount进阶需求
GitHub地址:PairProject2-Java
GitHub代码签入记录

爬虫部分
解题思路
爬虫工具使用了jsoup,jsoup 是一款Java 的HTML解析器,可直接解析某个URL地址、HTML文本内容。观察CVPR2018官网的页面元素,发现论文的链接都在ptitle类下

通过选择器得到对应的ptitle类的Elements列表,在进一步通过选择器得到具有href属性的a标签Elements列表,再连接列表中每个a标签对应的href对应的url地址,通过选择器分别选择论文的Title和Abstract


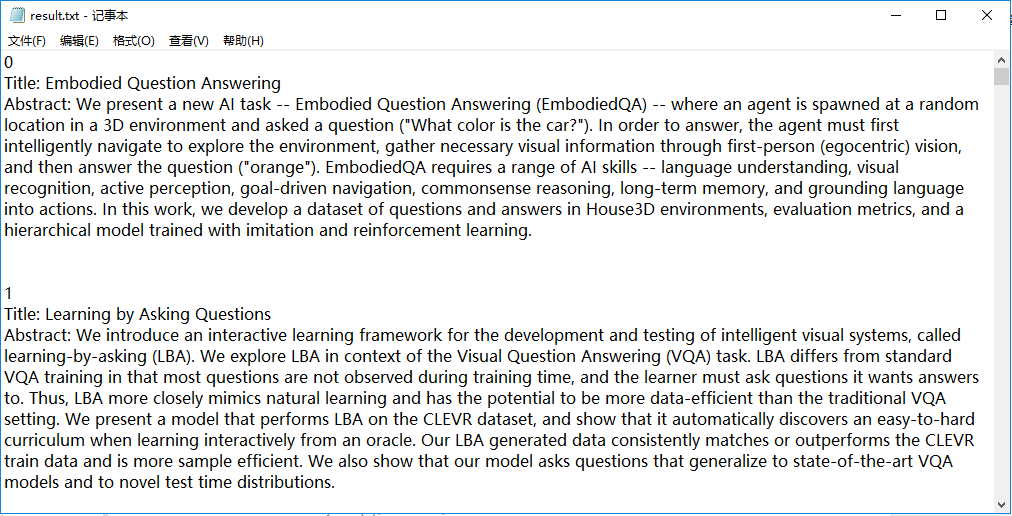
最后按格式输出到result.txt文件中
1、在属性名前加 abs: 前缀。这样就可以返回包含根路径的URL地址attr("abs:href")
2、在刚开始爬取的时候,一直不能爬取全部的论文列表,后来通过向同学请教得知,jsoup最大获取的响应长度正好是1M。只要设置 connection.maxBodySize(0),设置为0,就可以得到不限响应长度的数据了。
代码说明
public static void main(String[] args) throws IOException {
int cnt = 0;
String fileName = "result.txt";
String url = "http://openaccess.thecvf.com/CVPR2018.py";
File resultFile = new File(fileName);
resultFile.createNewFile();
BufferedWriter out = new BufferedWriter(new FileWriter(resultFile));
Connection connection = Jsoup.connect(url).ignoreContentType(true);
connection.timeout(2000000);
connection.maxBodySize(0);
// jsoup最大获取的响应长度正好是1M。只要设置 connection.maxBodySize(0),设置为0,就可以得到不限响应长度的数据了。
Document document = connection.get();
Elements ptitle = document.select(".ptitle");
// 通过选择器得到类ptitle的Elements列表
Elements links = ptitle.select("a[href]");
// 通过选择器进一步得到具有href属性的a标签Elements列表
for (Element link : links) {
out.write(cnt + "\r\n");
cnt++;
String eachUrl = link.attr("abs:href");
// 在属性名前加 abs: 前缀。这样就可以返回包含根路径的URL地址attr("abs:href")
Connection eachConnection = Jsoup.connect(eachUrl).ignoreContentType(true);
eachConnection.timeout(2000000);
eachConnection.maxBodySize(0);
// jsoup最大获取的响应长度正好是1M。只要设置 connection.maxBodySize(0),设置为0,就可以得到不限响应长度的数据了。
Document eachDocument = eachConnection.get();
Elements eachTitle = eachDocument.select("#papertitle");
// 在文章中通过选择器找到Title
String paperTitle = eachTitle.text();
out.write("Title: " + paperTitle + "\r\n");
Elements eachAbstract = eachDocument.select("#abstract");
// 在文章中通过选择器找到Abstract
String paperAbstract = eachAbstract.text();
out.write("Abstract: " + paperAbstract + "\r\n");
out.write("\r\n\r\n");
out.flush();
}
out.close(); // 关闭文件
}
WordCount命令行多参数部分
新增功能,并在命令行程序中支持下述命令行参数,且可多参数混合使用
- -i 参数设定读入文件的存储路径
- -o 参数设定生成文件的存储路径
- -w 参数设定是否采用不同权重计数:加入权重词频统计,属于Title的单词权重为10,属于Abstract 单词权重为1
- -m 参数设定统计的词组长度:统计文件夹中指定长度的词组的词频
- -n 参数设定输出的单词数量:用户指定输出前 n 多的单词(词组)与其频数
解题思路
- 命令行多参数:增加命令行参数的分析类,提取出用户要求的对应操作信息
- 不同权重:将基础需求中的文本解析类FileUtil中加入title文本提取方法和abstract文本提取方法,分成两部分进入Conuter中统计,以区分权重的异同
- 词组:同样将文本解析为标题和摘要两种字符串,对每个串提取单词和分隔符,判断连续m个单词是否均符合要求,符合则将单词与分隔符连成词组,再存储、统计
- 单词、词组词频统计:将单词或是词组存为对应的Map,再根据传入的m参数以及n参数,进行权重计算和词频输出(这里还需要merge标题和摘要统计下来的两个Map)
接口封装
在基础部分的设计中,已经将主要操作封装成了FileUtil类和Counter类,在进阶提出多参数的要求,我们认为多封装一个对参数的解析类,对于文本过滤和统计的修改其实是不多的
实现过程
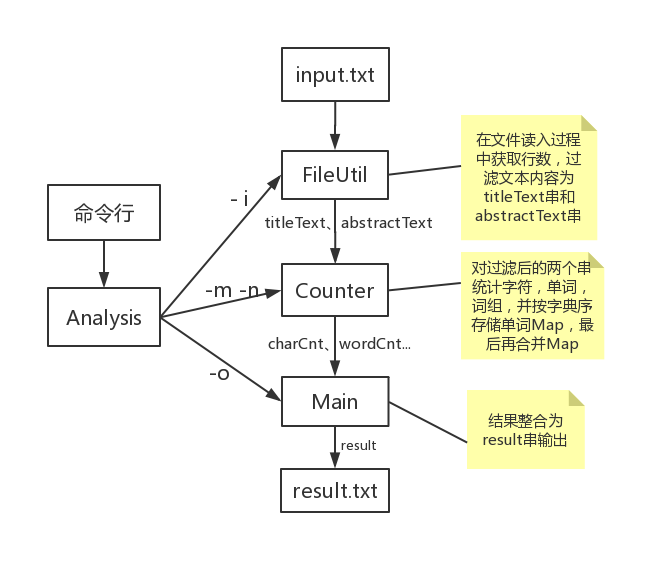
-
整体想法流程图
在基础部分的整体流程中多添加了一个用于解析命令行参数的过程
![]()
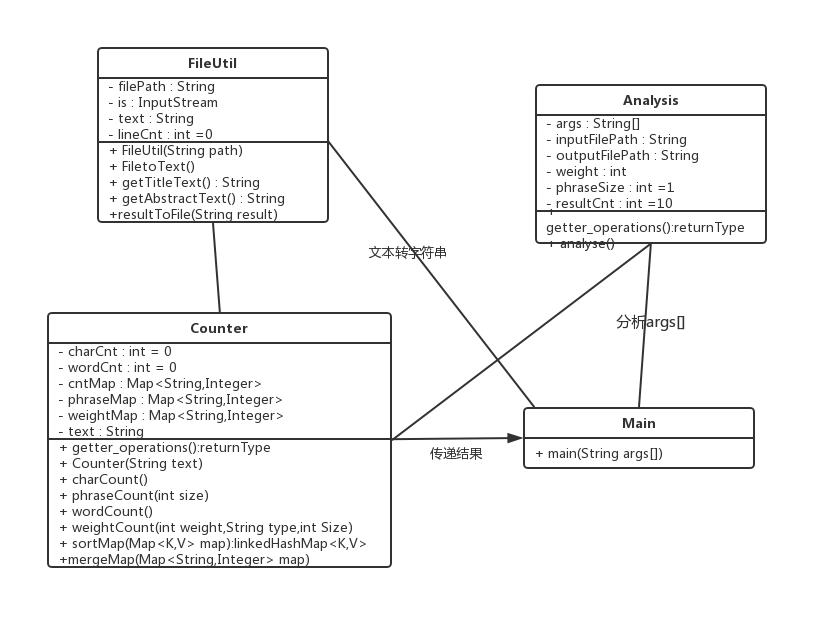
-
具体类图
![]()
-
代码说明
- 命令行参数解析
public void analyse() {
for (int i = 0; i < args.length; i++) {
if (args[i].equals("-i"))
inputFilePath = args[i + 1];
else if (args[i].equals("-o"))
outputFilePath = args[i + 1];
else if (args[i].equals("-w"))
weight = Integer.parseInt(args[i + 1]);
else if (args[i].equals("-m")) {
if(Integer.parseInt(args[i+1])>=0)
phraseSize = Integer.parseInt(args[i + 1]);
else System.out.println("-m参数应为自然数,默认进行单词统计");
}
else if (args[i].equals("-n"))
if(Integer.parseInt(args[i+1])>=0)
resultCnt = Integer.parseInt(args[i + 1]);
else System.out.println("-n参数应为自然数,默认输出前十位数据");
}
}
- 文件内容转为字符串过程在进阶需求中分成两部分,分别提取Title和Abstract
@SuppressWarnings("resource")
public String getTitleText() throws IOException {
StringBuffer sb = new StringBuffer();
BufferedReader br = new BufferedReader(new FileReader(filePath));
String readtext;
while ((readtext = br.readLine()) != null) {
if (readtext.contains("Title: ")) {//提取Title行
lineCnt++;
readtext = readtext.substring(7);//剔除"Title: "
sb.append(readtext + "\r\n");//补上readLine缺少的换行
}
}
return sb.toString();
}
@SuppressWarnings("resource")
public String getAbstractText() throws IOException {
StringBuffer sb = new StringBuffer();
BufferedReader br = new BufferedReader(new FileReader(filePath));
String readtext;
while ((readtext = br.readLine()) != null) {
if (readtext.contains("Abstract: ")) {//提取Abstract行
lineCnt++;
readtext = readtext.substring(10);//剔除"Abstract: "
sb.append(readtext+ "\r\n");//补上readLine缺少的换行
}
}
return sb.toString();
}
- 词组统计
public void phraseCount(int size) {
String splittext = text.replaceAll("[a-z0-9]", "0");// 将字母数字替换为0
String splits[] = splittext.split("[0]+");// 剔除0,得到单词跟着的分隔符
String splitRegex = "[^a-z0-9]";// 分隔符
String lowerText = text.replaceAll(splitRegex, " ");// 将非字母数字替换为空格
String words[] = lowerText.split("\\s+");// 利用空白分割所有单词
String wordRegex = "[a-z]{4,}[a-z0-9]*";// 单词匹配正则表达式
for (int i = 0; i < words.length; i++) {
boolean canPhrase = true;
if (i + size <= words.length) {//当前单词的第后size个单词不超过单词总数
for (int j = i; j < i + size; j++) {
if (!Pattern.matches(wordRegex, words[j])) {//单词的后size个单词均要符合单词定义
canPhrase = false;
break;
}
}
for (int k = i + 1; k < i + size; k++) {
if (Pattern.matches("\n", splits[k])) {//不同篇论文的title与abstract不能组成词组,用回车符区分
canPhrase = false;
}
}
} else
canPhrase = false;
if (canPhrase) {
String phrase = new String();
for (int m = 0; m < size; m++) {
int pos = i + m;
if (m == size - 1)
phrase += words[pos];
else
phrase += (words[pos] + splits[pos + 1]);
}
Integer num = phraseMap.get(phrase);
if (num == null || num == 0) {
phraseMap.put(phrase, 1);
} else if (num > 0) {
phraseMap.put(phrase, num + 1);
}
}
}
}
- Map合并
// 合并map,value值叠加
public void mergeMap(Map<String, Integer> map) {
Set<String> set = map.keySet();
for (String key : set) {
if (weightMap.containsKey(key)) {
weightMap.put(key, weightMap.get(key) + map.get(key));
} else {
weightMap.put(key, map.get(key));
}
}
weightMap = sortMap(weightMap);
}
- 词频统计
public void weightCount(int weight, String type, int Size) {
if (Size == 1) {// 单词词频计算
if (weight == 1) {
if (type.equals("title")) {
for (Map.Entry<String, Integer> word : cntMap.entrySet()) {
weightMap.put(word.getKey(), word.getValue() * 10);
}
}
if (type.equals("abstract")) {
for (Map.Entry<String, Integer> word : cntMap.entrySet()) {
weightMap.put(word.getKey(), word.getValue());
}
}
} else if (weight == 0) {
for (Map.Entry<String, Integer> word : cntMap.entrySet()) {
weightMap.put(word.getKey(), word.getValue());
}
} else {
System.out.println("w参数只能与数字 0|1 搭配使用");
}
} else {// 词组词频计算
if (weight == 1) {
if (type.equals("title")) {
for (Map.Entry<String, Integer> phrase : phraseMap.entrySet()) {
weightMap.put(phrase.getKey(), phrase.getValue() * 10);
}
}
if (type.equals("abstract")) {
for (Map.Entry<String, Integer> phrase : phraseMap.entrySet()) {
weightMap.put(phrase.getKey(), phrase.getValue());
}
}
} else if (weight == 0) {
for (Map.Entry<String, Integer> phrase : phraseMap.entrySet()) {
weightMap.put(phrase.getKey(), phrase.getValue());
}
} else {
System.out.println("w参数只能与数字 0|1 搭配使用");
}
}
}
- 测试部分
对进阶部分的测试未能完善,字符单词统计处理要求过于精细,时间原因还未细测,词组词频测试对爬虫爬取的978篇结果(d:\result.txt)进行处理,数据量较多,不知结果正确与否,未进行JUnit白盒测试,只贴出统计结果(测试文件与输出文件均存放于d:盘中)
在命令行窗口中输入:java Main -i d:\result -o d:\output.txt -w 1 -m 3
d:盘下output.txt中词组统计及词频输出结果如下:

性能测试
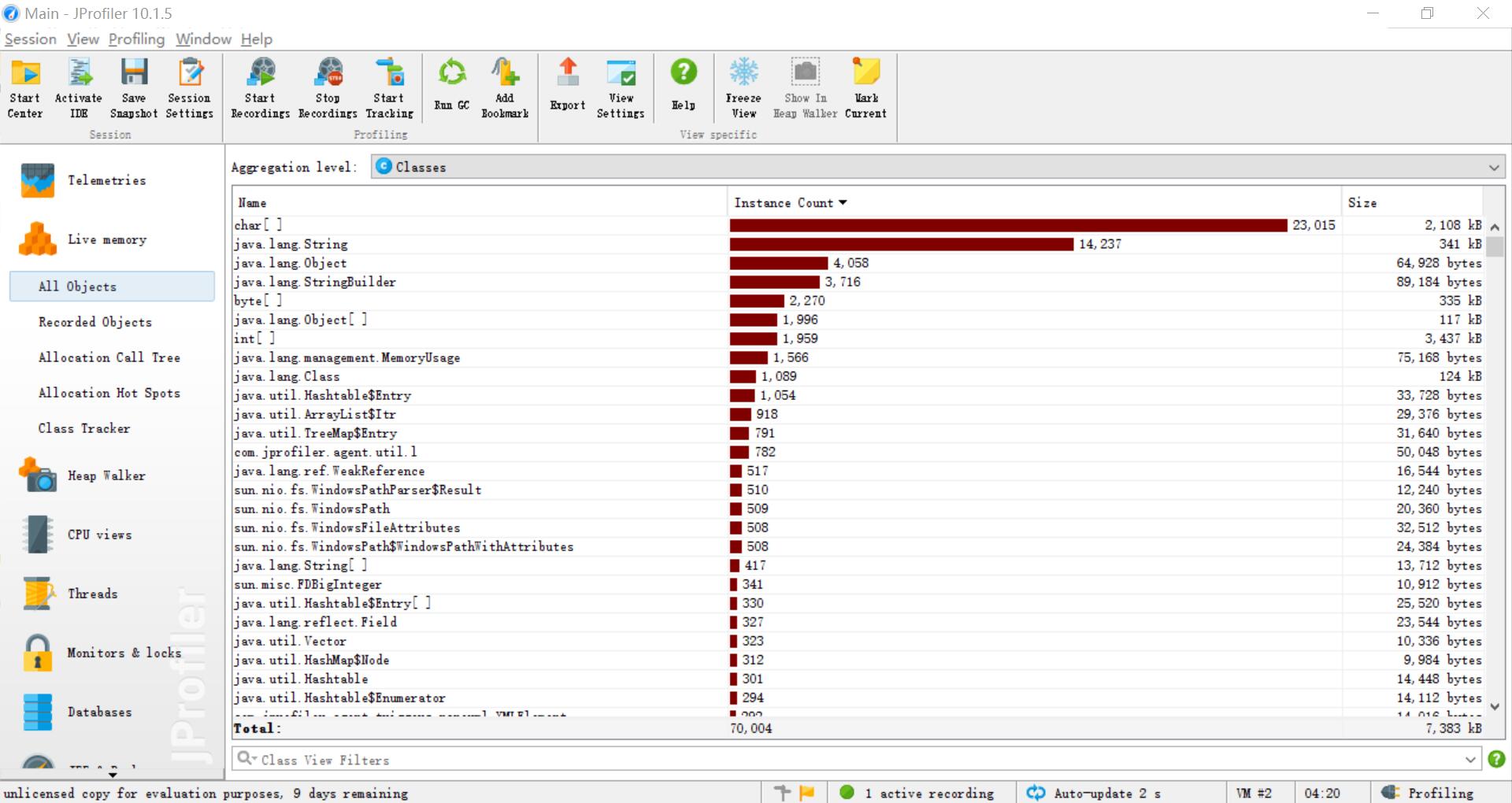
以下测试结果使用工具JProfiler爬取得到的2018年CVPR论文数据,加入了参数-w 1 -m 3得到,可见在Counter中的map排序sortMap还有mergeMap方法消耗最大

(三)附加题设计与展示
实现功能
- 从网站爬取了论文除题目摘要外的其他信息,如作者、pdf地址等
- 分析论文列表中的作者关系,进行可视化处理
- 对爬取的摘要数据,生成关键词图谱
- 词频分析可视化
设计思路
- 从网站爬取论文的其他信息,如作者、pdf地址等的方法与之前爬取论文题目,摘要的方法类似,主要是通过找到对应结点,得到对应结点的文本值。
- 分析论文列表中各位作者之间的关系,图形化显示,主要是先爬取每篇论文的作者信息,由于爬取的作者信息以 ,分隔,因此可以直接将其转化为csv文件,通过使用Gephi导入csv文件,生成可视化的联系
- 关键词图谱部分通过将爬取的摘要内容放在在线生成词云的网站生成可视化词云
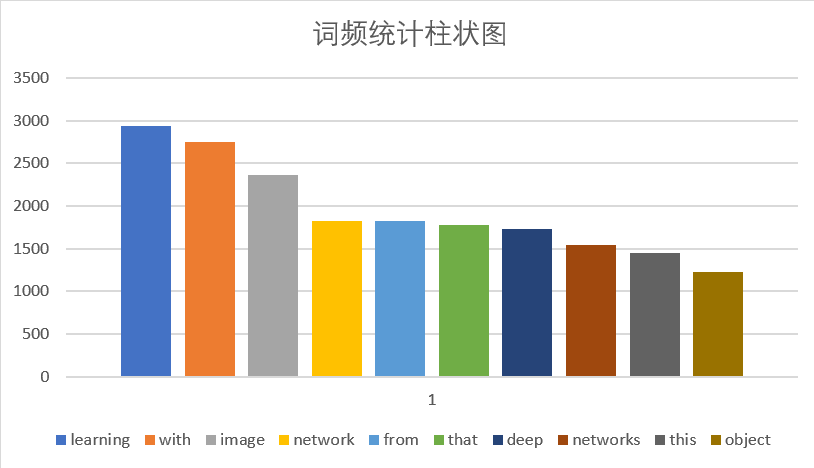
- 论文摘要中出现的词频统计,主要是先爬取每篇论文的摘要信息,再通过我们写的WordCount进阶需求程序进行词频统计,将出现频率最高的前十个单词通过Excel转化为柱状图显示
成果展示
result.txt

作者联系

关键词图谱
Top10单词柱状图
结对过程
具体分工
实际过程中,我与结对伙伴划分各自的工作,但却并非各做各的,在过程中的"领航者"与“驾驶员”身份时常互换,相互帮助。一开始困惑很多,完成基础部分的时候,本不打算继续完善进阶甚至做附加任务,因为时间安排不合理,觉得做不来也无法做好,不过两人还是互相搀扶着完成结对任务,我想这也是结对编程带来的。
- 郑晓彪:WordCount编写,单元测试,编写文档
- 陈序展:爬虫部分及附加功能编写,性能测试,代码质量分析,覆盖率监测,部分文档编写
评价队友
- 值得学习的地方:我的队友认真负责,处理任务目标明确、条理清晰,学习能力强
- 值得改进的地方:实际工作时效率有待提高
PSP
PSP是卡耐基梅隆大学(CMU)的专家们针对软件工程师所提出的一套模型:Personal Software Process (PSP, 个人开发流程,或称个体软件过程)。
| PSP2.1 | Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | 30 | 20 |
| • Estimate | • 估计这个任务需要多少时间 | 30 | 20 |
| Development | 开发 | 1160 | 1470 |
| • Analysis | • 需求分析 (包括学习新技术) | 90 | 150 |
| • Design Spec | • 生成设计文档 | 40 | 20 |
| • Design Review | • 设计复审 | 40 | 20 |
| • Coding Standard | • 代码规范 (为目前的开发制定合适的规范) | 30 | 20 |
| • Design | • 具体设计 | 60 | 90 |
| • Coding | • 具体编码 | 720 | 900 |
| • Code Review | • 代码复审 | 120 | 180 |
| • Test | • 测试(自我测试,修改代码,提交修改) | 60 | 90 |
| Reporting | 报告 | 70 | 70 |
| • Test Report | • 测试报告 | 30 | 30 |
| • Size Measurement | • 计算工作量 | 20 | 20 |
| • Postmortem & Process Improvement Plan | • 事后总结, 并提出过程改进计划 | 20 | 20 |
| 合计 | 1260 | 1560 |

 浙公网安备 33010602011771号
浙公网安备 33010602011771号