

PaddleOCR搭建
如果是PyCharm端,则只需安装:paddlepaddle、paddleocr、requirements.txt
基于PaddleHub部署CPU版本的PaddleOCR实操过程记录。
- PaddleOCR:release/2.2分支
- PaddlePaddle 2.1.3
- Paddlehub 2.1.0
(一)、windows10环境部署
1.Python环境准备
python安装过程略(本文基于Python 3.7.7)
2.安装飞桨预训练模型管理和迁移学习工具PaddleHub
pip install paddlehub -i https://pypi.tuna.tsinghua.edu.cn/simple3.安装第三方库shapely、pyclipper
pip install pyclipper -i https://pypi.tuna.tsinghua.edu.cn/simple安装shapely不能直接用pip install shapely命令安装,否则后面在安装文字识别模块的时候会发生错误:
File "c:\programdata\anaconda3\lib\site-packages\shapely\geos.py", line 145, in <module>
_lgeos = CDLL(os.path.join(sys.prefix, 'Library', 'bin', 'geos_c.dll'))
File "c:\programdata\anaconda3\lib\ctypes\__init__.py", line 364, in __init__
self._handle = _dlopen(self._name, mode)
OSError: [WinError 126] 找不到指定的模块。
正确的安装方法是先执行脚本
import pip._internal.pep425tags
print(pip._internal.pep425tags.get_supported())查看python支持的whl,再到https://www.lfd.uci.edu/~gohlke/pythonlibs/#shapely 页面下载对应的shapely whl文件,我的文件是Shapely-1.7.1-cp37-cp37m-win_amd64.whl。最后基于whl文件安装shapely,命令如下:
pip install .\Shapely-1.7.1-cp37-cp37m-win_amd64.whl
如果没有如下环境,则需要安装
python -m pip install paddlepaddle -i https://mirror.baidu.com/pypi/simple
pip install scikit-image
4.下载PaddleOCR代码
git clone https://github.com/PaddlePaddle/PaddleOCR5.下载推理模型
5.1.在PaddleOCR目录下新建inference文件夹用于存放模型文件
5.2.下载中英文识别模型ch_PP-OCRv2_rec推理模型并解压到inference文件夹
https://github.com/PaddlePaddle/PaddleOCR/blob/release/2.3/doc/doc_ch/models_list.md#多语言识别模型
模型的位置最好按照此目录存放,否则后面文字识别模块安装的时候可能发生错误:
ModuleNotFoundError: No module named 'tools'
6.修改params.py的模型路径
PaddleOCR\deploy\hubserving\ocr_rec\params.py 文件的cfg.rec_model_dir配置项修改为上述下载的模型文件路径"./inference/ch_PP-OCRv2_rec_infer/"
7.安装PaddleOCR的文字识别服务模块到Paddlehub
在PaddleOCR目录下执行命令
hub install deploy\hubserving\ocr_rec\8.启动服务
hub serving start -m ocr_rec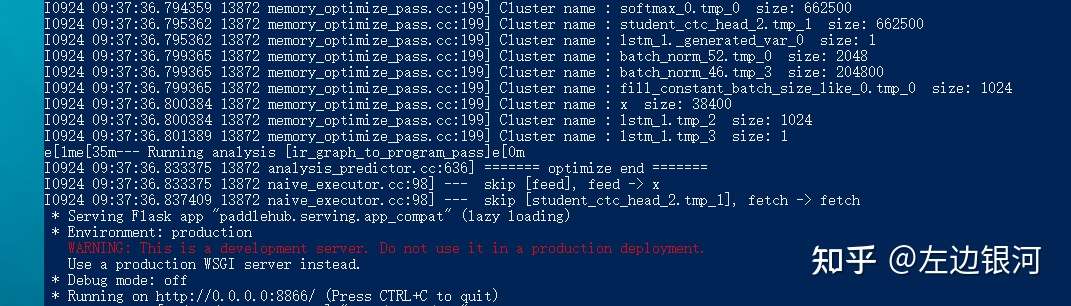
(二)、Linux 环境部署(CentOS Linux release 7.5.1804 (Core))
1.Python环境准备
python安装过程略(本文基于Python 3.7.7)
2.安装飞桨预训练模型管理和迁移学习工具PaddleHub
pip install paddlehub -i https://pypi.tuna.tsinghua.edu.cn/simple3.安装第三方库shapely、pyclipper
pip install shapely -i https://pypi.tuna.tsinghua.edu.cn/simple
pip install pyclipper -i https://pypi.tuna.tsinghua.edu.cn/simple4.下载PaddleOCR代码
git clone https://github.com/PaddlePaddle/PaddleOCR5.下载推理模型
5.1.在PaddleOCR目录下新建inference文件夹用于存放模型文件
5.2.下载中英文识别模型ch_PP-OCRv2_rec推理模型并解压到inference文件夹
https://github.com/PaddlePaddle/PaddleOCR/blob/release/2.3/doc/doc_ch/models_list.md#多语言识别模型
解压命令使用tar xvf ch_PP-OCRv2_rec_infer.tar,不能使用tar zxvf ch_PP-OCRv2_rec_infer.tar,否则会发生错误:
gzip: stdin: not in gzip format
tar: Child returned status 1
tar: Error is not recoverable: exiting now模型的位置最好按照此目录存放,否则后面文字识别模块安装的时候可能发生错误:
ModuleNotFoundError: No module named 'tools'
6.修改params.py的模型路径
PaddleOCR\deploy\hubserving\ocr_rec\params.py 文件的cfg.rec_model_dir配置项修改为上述下载的模型文件路径"./inference/ch_PP-OCRv2_rec_infer/"
7.安装PaddleOCR的文字识别服务模块到Paddlehub
在PaddleOCR目录下执行命令
hub install deploy\hubserving\ocr_rec\8.启动服务
hub serving start -m ocr_rec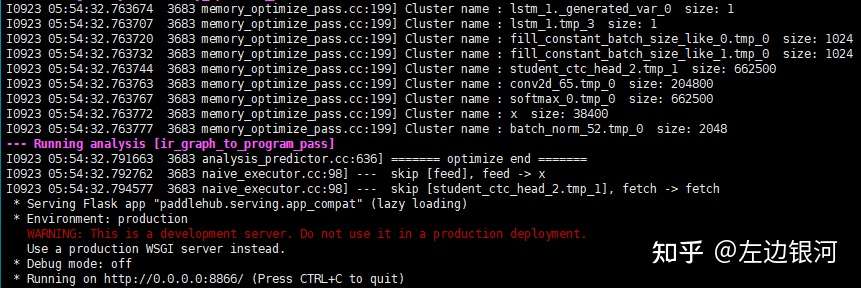
另外,在使用paddlehub调用ocr模型的时候发生了错误:
AttributeError: module 'paddlehub' has no attribute 'Module'
简单的两行代码:
import paddlehub as hub
ocr = hub.Module(name="chinese_ocr_db_crnn_server")在命令行里执行没有问题,在python文件里执行就报上面的错误。折腾了半天,原因是自己给python文件命名时简单地命名成了paddlehub.py,和引用的包paddlehub重名了。
(三)、文字识别测试
进入PaddleOCR\tools目录,为了简单起见,在目录下放入一张命名为4.jpg的图片,在命令行执行命令:
python test_hubserving.py http://127.0.0.1:8866/predict/ocr_rec 4.jpg
(四)、JAVA服务化(实验)
便于工程化应用,将识别服务封装成java服务。
@Autowired
private RestTemplate restTemplate;
4.1.组装请求头
/**
* 组装请求头
* @param imageFile
* @return
* @throws Exception
*/
private static HttpEntity<String> makeHttpEntityHub( MultipartFile imageFile) throws Exception{
String content = Base64Utils.encodeToString(IOUtils.toByteArray(imageFile.getInputStream()));
JSONObject params = new JSONObject();
params.put("images", new String[] { content });
HttpHeaders headers = new HttpHeaders();
headers.setContentType(MediaType.parseMediaType("application/json"));
return new HttpEntity<String>(params.toJSONString(), headers);
}4.2.识别请求
@PostMapping("/text/recognition")
public List<String> textRecognition(@RequestParam("file") MultipartFile imageFile) throws Exception {
// 服务地址 TODO 动态配置
String url = "http://127.0.0.1:8866/predict/ocr_rec";
// 组装请求头
HttpEntity<String> httpEntity = makeHttpEntityHub(imageFile);
// 文字识别
ResponseEntity<JSONObject> responseEntity = restTemplate.exchange(url, HttpMethod.POST, httpEntity, JSONObject.class);
// 识别结果解析
List<String> list = Lists.newArrayList();
if (responseEntity.getStatusCodeValue() == 200 && "000".equals(responseEntity.getBody().getString("status"))) {
JSONArray results = responseEntity.getBody().getJSONArray("results");
for (int i = 0; i < results.size(); i++) {
JSONArray contents = results.getJSONArray(i);
for (int j = 0; j < contents.size(); j++) {
JSONObject content = contents.getJSONObject(j);
list.add(content.getString("text"));
}
}
}
// 有效信息提取
return list ;
}
(五)、串联多模块,改善识别效果
上面步骤中只部署了文字识别模块,效果不忍直视,串联分类和检测模块后效果提升明显。
1.下载分类、和检测推理模型并解压到inference文件夹
PaddleOCR/models_list.md at release/2.3 · PaddlePaddle/PaddleOCR
分类模型:ch_ppocr_mobile_slim_v2.0_cls
检测模型:ch_PP-OCRv2_det
2.修改params.py的模型路径
修改PaddleOCR\deploy\hubserving\ocr_system\params.py 文件的模型配置:
#检测模块模型配置
cfg.det_model_dir = "./inference/ch_PP-OCRv2_det_infer/"
#识别模块模型配置
cfg.rec_model_dir = "./inference/ch_PP-OCRv2_rec_infer/"
#分类模块模型配置
cfg.cls_model_dir = "./inference/ch_ppocr_mobile_v2.0_cls_infer/"3.安装PaddleOCR的文字识别服务模块到Paddlehub
在PaddleOCR目录下执行命令
windows10:
hub install deploy\hubserving\ocr_system\
linux:
hub install deploy/hubserving/ocr_system/在linux环境下需要安装imgaug、lmdb,否则会报错:
ModuleNotFoundError: No module named 'imgaug'
ModuleNotFoundError: No module named 'lmdb'安装命令:
pip install imgaug -i https://pypi.tuna.tsinghua.edu.cn/simple
pip install lmdb -i https://pypi.tuna.tsinghua.edu.cn/simple4.启动串联服务
windows:
hub serving start -m ocr_system
linux:
nohup hub serving start -m ocr_system &5.文字识别测试
进入PaddleOCR\tools目录,为了简单起见,在目录下放入一张命名为4.jpg的图片,在命令行执行命令:
python test_hubserving.py http://127.0.0.1:8866/predict/ocr_system 4.jpg
参考文章:

 浙公网安备 33010602011771号
浙公网安备 33010602011771号