
06-python语法进阶—迭代器与生成器
一、迭代器
迭代(iteration)
- 迭代是数据处理的基石,扫描内存中放不下的数据时,我们需要找到一种惰性获取数据项的方式,即按需一次获取一个数据项,迭代器对象从集合的第一个元素开始访问,直到所有的元素被访问完结束。迭代器只能往前不会后退,这就是迭代器模式。
- 迭代器是访问集合元素的一种方式,是一个可以自主遍历的位置的对象,主要是为了接近并达到所需目标或结果,每一次对过程重复被称为一次“迭代”,而每一次迭代的结果作为下一次迭代的初始值。
- 迭代器有两个基本的方法:iter() 和 next()。
- 字符串,列表或元组对象都可用于创建迭代器
典型应用:“牛顿法”求根
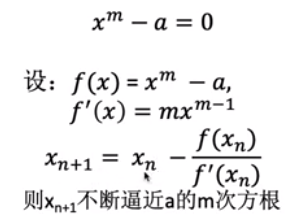
[oldboy@linux-node3 ~]$ cat newton_method_forbase.py #!/usr/bin/env python # -*- coding: utf-8 -*- """ # Author:ChengZi # Version:1.0 # Date:2021-01-07 14:29 # Filename: newton_method_forbase.py # Description:This script is used for """ value = 23 #f(x) = x^2 - 23 epsilon = 0.001 result = value // 2 while abs(result*result - value) >= epsilon: result = result - ((result*result - value) / (2 * result)) print("The square root of {0} is about {1}0".format(value,result)) import math print(math.sqrt(23)) [oldboy@linux-node3 ~]$ python3 newton_method_forbase.py The square root of 23 is about 4.795834600482720 4.795831523312719
可迭代对象(iterable)
可迭代对象的特点
- 能够逐一返回其成员的对象
- 所有序列类型(list、str、tuple)
- 某些非序列类型(dict、文件对象)
- 定义了__iter__()方法或实例Sequence语义的__getitem__()方法的任意自定义类对象
- 判断:__iter__
可迭代对象使用场景
- for循环
- 某些对象的参数,如map等
迭代器(iterator)
- 用来表示一连串数据流的对象。重复调用迭代器的__next__()方法(或将其传给内置函数next()),将逐个返回数据流中的项。当没有数据可用时,将引发StopIteration异常。
- 迭代器必须有__iter__()方法,用来返回迭代器自身,因此迭代器必定也是可迭代对象。
- 使用内置函数iter()创建迭代器对象
- 标准迭代器接口有两个方法,判断:
- __iter__,//返回下一个可用元素,如果没有下一个了,抛出StopIteration异常
- __next__,//返回self,以便在应该使用可迭代对象的地方使用迭代器。
迭代器的特点
- 方便使用,且只能取所有的数据一次;
- 节省内存空间。
迭代器的执行过程
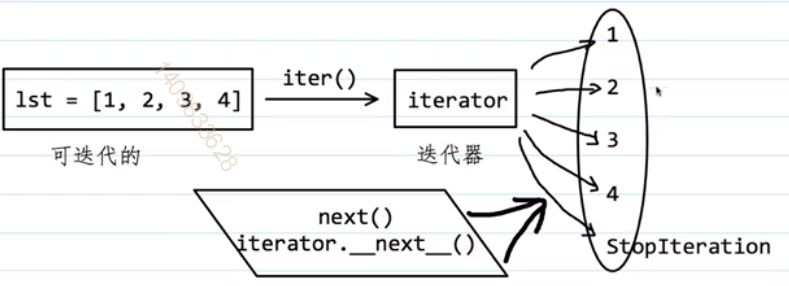
应用:编写斐波那契数列的迭代器对象
[oldboy@linux-node3 ~]$ cat fibs_func_method.py #!/usr/bin/env python # -*- coding: utf-8 -*- """ # Author:ChengZi # Version:1.0 # Date:2021-01-07 18:33 # Filename: fibs_func_method.py # Description:This script is used for """ class Fibs: def __init__(self,max):#初始化方法,设置斐波那契数列最大值 self.max = max self.a = 0#初始值 self.b = 1#初始值 def __iter__(self):#定义该方法,则该方法才是可迭代的 return self def __next__(self):#定义next方法,数据流一项项读取 fib = self.a#读取第一项的值 if fib > self.max:#当前值与最大值比较,即数据是否是最后一个项 raise StopIteration self.a,self.b = self.b,self.a + self.b return fib fibs = Fibs(10000) lst = [ fibs.__next__() for i in range(20) ] print(lst) [oldboy@linux-node3 ~]$ python3 fibs_func_method.py [0, 1, 1, 2, 3, 5, 8, 13, 21, 34, 55, 89, 144, 233, 377, 610, 987, 1597, 2584, 4181]
拓展:import itertools
>>> import itertools >>> c = itertools.count(start=3) >>> dir(c) ['__class__', '__delattr__', '__dir__', '__doc__', '__eq__', '__format__', '__ge__', '__getattribute__', '__gt__', '__hash__', '__init__', '__init_subclass__', '__iter__', '__le__', '__lt__', '__ne__', '__new__', '__next__', '__reduce__', '__reduce_ex__', '__repr__', '__setattr__', '__sizeof__', '__str__', '__subclasshook__'] >>> next(c) 3 >>> next(c) 4 >>> colors = itertools.cycle(['red','green','blue']) >>> dir(colors) ['__class__', '__delattr__', '__dir__', '__doc__', '__eq__', '__format__', '__ge__', '__getattribute__', '__gt__', '__hash__', '__init__', '__init_subclass__', '__iter__', '__le__', '__lt__', '__ne__', '__new__', '__next__', '__reduce__', '__reduce_ex__', '__repr__', '__setattr__', '__setstate__', '__sizeof__', '__str__', '__subclasshook__'] >>> next(colors) 'red' >>> next(colors) 'green' >>> next(colors) 'blue' >>> next(colors) 'red' >>> next(colors) 'green' >>> import itertools >>> d = itertools.count(start=3,step=2) >>> next(d) 3 >>> next(d) 5 >>> next(d) 7
二、生成器(generator)
生成器的简介
- 在 Python 中,使用了yield 的函数被称为生成器(generator)
- 跟普通函数不同的是,生成器是一个返回迭代器的函数,只能用于迭代操作,更简单点理解生成器就是一个迭代器。
- 在调用生成器运行的过程中,每次遇到 yield 时函数会暂停并保存当前所有的运行信息,返回 yield 的值, 并在下一次执行 next() 方法时从当前位置继续运行。
- 调用一个生成器函数,返回的是一个迭代器对象。
>>> def g(): ... yield 0 ... yield 1 ... yield 2 ... >>> ge = g() >>> dir(ge) ['__class__', '__del__', '__delattr__', '__dir__', '__doc__', '__eq__', '__format__', '__ge__', '__getattribute__', '__gt__', '__hash__', '__init__', '__init_subclass__', '__iter__', '__le__', '__lt__', '__name__', '__ne__', '__new__', '__next__', '__qualname__', '__reduce__', '__reduce_ex__', '__repr__', '__setattr__', '__sizeof__', '__str__', '__subclasshook__', 'close', 'gi_code', 'gi_frame', 'gi_running', 'gi_yieldfrom', 'send', 'throw'] >>> ge <generator object g at 0x7f810ad34750> >>> ge.__next__() 0 >>> ge.__next__() 1 >>> ge.__next__() 2 >>> ge.__next__() Traceback (most recent call last): File "<stdin>", line 1, in <module> StopIteration
return与yield的区别
>>> def r_return(n): ... while n >0: ... print("before return") ... return n ... n -=1 ... print("after return") ... >>> re = r_return(3) before return >>> re 3 >>> def y_yield(n): ... while n >0: ... print("before yield") ... yield n ... n -= 1 ... print("after yield") ... >>> yy = y_yield(3) >>> yy <generator object y_yield at 0x7f810abf43d0> >>> yy.__next__() before yield 3 >>> yy.__next__() after yield before yield 2 >>> yy.__next__() after yield before yield 1 >>> yy.__next__() after yield Traceback (most recent call last): File "<stdin>", line 1, in <module> StopIteration
应用:编写斐波那契数列的生成器
- 普通方法
#方法1:斐波那契数列普通版 def Fibonacci(n): i, a, b = 2, 0, 1 if n < 2: return n print(0) while i <= n: print(b) a, b = b, a+b i += 1 Fibonacci(4) #方法2: [oldboy@linux-node3 ~]$ cat fibs_cacula_num.py #!/usr/bin/env python # -*- coding: utf-8 -*- def fibs(n): res = [0,1] for i in range(n-2): res.append(res[-2] + res[-1]) return res num = int(input("请输入想要查询的斐波那契数列的值:")) cnum = fibs(num) print("斐波那契数列值为:",cnum) [oldboy@linux-node3 ~]$ python3 fibs_cacula_num.py 请输入想要查询的斐波那契数列的值:5 斐波那契数列值为: [0, 1, 1, 2, 3] [oldboy@linux-node3 ~]$ python3 fibs_cacula_num.py 请输入想要查询的斐波那契数列的值:10 斐波那契数列值为: [0, 1, 1, 2, 3, 5, 8, 13, 21, 34]
- 生成器方法
#方法3:斐波那契数列生成器1 def Fibonacci(n): i, a, b = 2, 0, 1 if n < 2: yield n print(0) while i <= n: yield b a, b = b, a+b i += 1 print(list(Fibonacci(4))) #方法4:斐波那契数列生成器2 #!/usr/bin/env python # -*- coding: utf-8 -*- def Fibos(): prev,curr = 0,1 while True: yield prev prev,curr = curr,prev + curr import itertools print(list(itertools.islice(Fibos(),15))) [oldboy@linux-node3 ~]$ python3 fibs_func_method.py [0, 1, 1, 2, 3, 5, 8, 13, 21, 34, 55, 89, 144, 233, 377]
问题:迭代器和生成器是没法执行普通的切片操作的,这是因为不知道它们的长度是多少(而且它们也没有实现索引),那么如何切片?
解决方案:使用itertools.islice()来对迭代器和生成器做切片操作
def count(n): while True: yield n n += 1 c = count(0) # 生成器的绝妙之处:它只会在迭代时才会运行,所以死循环也没有问题,返回一个generator # print(c[:]) # TypeError: 'generator' object is not subscriptable import itertools for x in itertools.islice(c, 10, 13): print(x) #输出结果 python3 fibs_func_method.py 10 11 12
itertools模块
- itertools模块的count方法
#1.0 itertools模块的count方法(有限循环) def count(n): while True: yield n n += 1 c = count(0) # 生成器的绝妙之处:它只会在迭代时才会运行,所以死循环也没有问题,返回一个generator # print(c[:]) # TypeError: 'generator' object is not subscriptable import itertools for x in itertools.islice(c, 10, 13): print(x)
- itertools模块的islice方法
#2.0 itertools模块的islice方法(无限循环) # islice的第二个参数控制何时停止迭代。但其含义并不是”达到数字5时停止“,而是”当迭代了5次之后停止“。 from itertools import islice from itertools import count for i in islice(count(10), 5): print(i)
- itertools模块的cycle方法
#3.0 itertools模块的cycle方法(轮询执行) from itertools import cycle count = 0 for item in cycle('X4Z'): if count > 7: break print(item) count += 1
- itertools模块repeat方法
#4.0 repeat(对象[, 次数]),迭代器会一遍遍地返回传入的对象直至永远,除非你设定了times参数 from itertools import repeat repeat(5, 5) itor = repeat(5, 5) next(itor) next(itor) next(itor) next(itor) next(itor) next(itor)
- itertools模块accumulate方法
#5.0 accumulate迭代器将返回累计求和结果,或者传入两个参数的话,由传入的函数累积计算的结果。默认设定为相加 from itertools import accumulate lst1 = list(accumulate(range(10))) lst2 = list(accumulate(range(5,10))) print(lst1) print(lst2)
- itertools模块的operator方法
#6.0 operator模块,数字依次相乘 import operator mul_num = list(accumulate(range(1,5),operator.mul)) print(mul_num)
- itertools模块的chain方法
#7.0 chain(*可迭代对象) #chain迭代器能够将多个可迭代对象合并成一个更长的可迭代对象 my_list = ['foo', 'bar'] numbers = list(range(5)) cmd = ['ls','/some/dir'] my_list.extend(cmd) my_list.extend(numbers) print(my_list) #结果为['foo', 'bar', ['ls', '/some/dir'], [0, 1, 2, 3, 4]],这并不是我想要的 #使用chain方法合并列表 # from itertools import chain # my_list = list(chain(['foo', 'bar'], cmd, numbers)) # print(my_list) #chain.from_iterable(可迭代对象) from itertools import chain numbers = list(range(5)) cmd = ['ls', '/some/dir'] # chain.from_iterable(cmd, numbers) list(chain.from_iterable([cmd, numbers]))#结果为['foo', 'bar', 'ls', '/some/dir', 0, 1, 2, 3, 4]
- itertools模块的compress方法
#8.0 compress(数据, 选择器) #子模块compress在用一个可迭代对象过滤另一个可迭代对象时十分有用。这是通过将作为选择器的可迭代对象取为布尔值列表来实现的 from itertools import compress letters = 'ABCDEFG' bools = [True, False, True, True, False] str_list = list(compress(letters,bools)) print(str_list)#结果为['A', 'C', 'D']
- itertools模块的dropwhile方法
#9.0 dropwhile(断言, 可迭代对象) #itertools还提供了一个小清新的迭代器dropwhile。只要过滤器判定是True,dropwhile迭代器就会排除这些元素。 # 因此,在出现断言为False之前,你不会看到任何输出结果。这可能导致启动时间非常长,这点应当注意 from itertools import dropwhile lst_num1 = list(dropwhile(lambda x: x < 5,[1, 4, 6, 4, 1])) lst_num2 = list(dropwhile(lambda x: x < 5,[1,3,4,5,6, 4, 1])) print(lst_num1)#遇到6,lambda返回false,则保留6及其之后的数字,结果为[6, 4, 1] print(lst_num2) from itertools import dropwhile def greater_than_five(x): return x > 5 re_lst = list(dropwhile(greater_than_five, [6, 7, 8, 9, 1, 2, 3, 10])) print(re_lst)#遇到小于5的值,则该值及其其后的值都保留,故结果为[1, 2, 3, 10]
- itertools模块的takewhile方法
#takewhile(断言, 可迭代对象) #takewhile模块与dropwhile迭代器刚好相反。takewhile所创建的迭代器,一旦可迭代对象的断言或过滤器结果为True就返回元素 from itertools import takewhile take_lst = list(takewhile(lambda x: x < 5,[1,3,4,5,6,4,1])) print(take_lst)#结果为[1, 3, 4]
- itertools模块的filterfalse方法
#10.0 filterfalse(断言, 可迭代对象) #itertools中的filterfalse函数与dropwhile非常类似。但filterfalse返回断言为False的那些值,而不是舍弃断言为True的值。 from itertools import filterfalse def greater_than_five(x): return x > 5 filter_lst = list(filterfalse(greater_than_five, [6, 7, 8, 9, 1, 10, 3, 5])) print(filter_lst)#结果为[1, 3, 5]
- itertools模块的groupby方法
#11.0 groupby(可迭代对象, 键=None) #groupby迭代器,会从传入的可迭代对象返回连续的键和组。 from itertools import groupby vehicles = [('Ford','Taurus'),('Dodge','Durango'),('Chevrolet','Cobalt'),('Ford','F150'),('Dodge','Charger'),('Ford','GT')] sorted_vehicles = sorted(vehicles) for key, group in groupby(sorted_vehicles,lambda make: make[0]): for make, model in group: print('{model} is made by {make}'.format(model=model,make=make)) print("**** END OF GROUP ***n") #结果为: Cobalt is made by Chevrolet **** END OF GROUP ***n Charger is made by Dodge Durango is made by Dodge **** END OF GROUP ***n F150 is made by Ford GT is made by Ford Taurus is made by Ford **** END OF GROUP ***n
- itertools模块的tee方法
#14.0 tee(可迭代对象, n=2) #tee工具能够从一个可迭代对象创建n个迭代器。这意味着你能够用一个可迭代对象创建多个迭代器。 from itertools import tee data = 'ABCDE' iter1, iter2 = tee(data) for item in iter1: print(item) for item in iter2: print(item)
- itertools模块的zip_longest方法
#15.0 zip_longest(*可迭代对象, 填充值=None) #zip_longest迭代器可以用于将两个可迭代对象配对。如果可迭代对象的长度不同,也可以传入填充值。 from itertools import zip_longest for item in zip_longest('ABCD','xy',fillvalue='BLANK'): print(item) #结果为: # ('A', 'x') # ('B', 'y') # ('C', 'BLANK') # ('D', 'BLANK')
组合生成器
itertools库提供了四个可用于生成数据排列和组合的迭代器:
- combinations(可迭代对象,r)
#16.0 如果你需要生成数据的组合,itertools.combinations将组合数据,但combinations函数不会将每个单独的元素自己跟自己组合。 from itertools import combinations combi_lst = list(combinations('WXYZ', 2)) print(combi_lst)#结果为[('W', 'X'), ('W', 'Y'), ('W', 'Z'), ('X', 'Y'), ('X', 'Z'), ('Y', 'Z')] #为了使输出结果更具可读性,可以遍历迭代器将元组组合成字符串 for item in combinations('WXYZ', 2): print(''.join(item)) # 结果为: # WX # WY # WZ # XY # XZ # YZ
- combination_with_replacement(可迭代对象,r)
#17.0 combinationa_with_replacement #combinationa_with_replacement迭代器与combinations唯一的区别是,它会创建元素自己与自己的组合 from itertools import combinations_with_replacement for item in combinations_with_replacement('WXYZ', 2): print(''.join(item)) #结果为: # WW # WX # WY # WZ # XX # XY # XZ # YY # YZ # ZZ
- itertools模块的product方法
#18.0 product(*可迭代对象, 重复=1) #product用于根据一系列输入的可迭代对象计算笛卡尔积 from itertools import product arrays = [(-1, 1), (-3, 3), (-5, 5)] cp = list(product(*arrays)) print(cp) #结果为:[(-1, -3, -5), (-1, -3, 5), (-1, 3, -5), (-1, 3, 5), (1, -3, -5), (1, -3, 5), (1, 3, -5), (1, 3, 5)]
标准库中的生成器函数
- 参考地址:https://www.cnblogs.com/lht-record/p/10321820.html
-
用于过滤的生成器函数
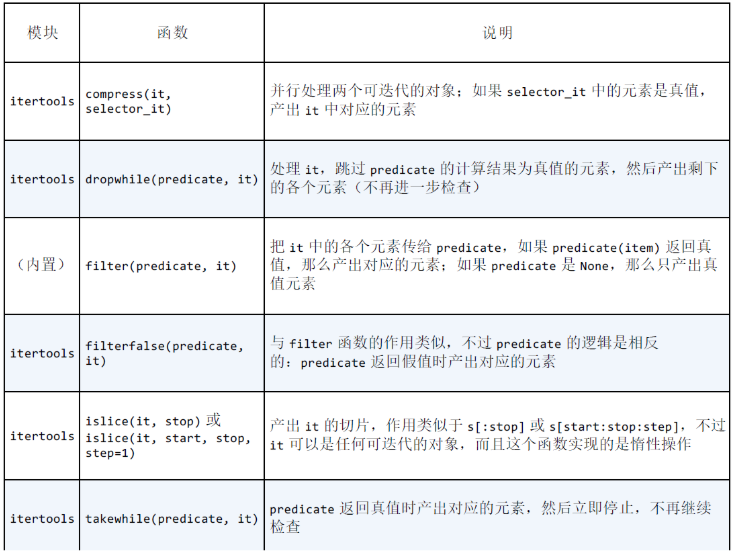
-
用于映射的生成器函数

-
合并多个可迭代对象的生成器函数
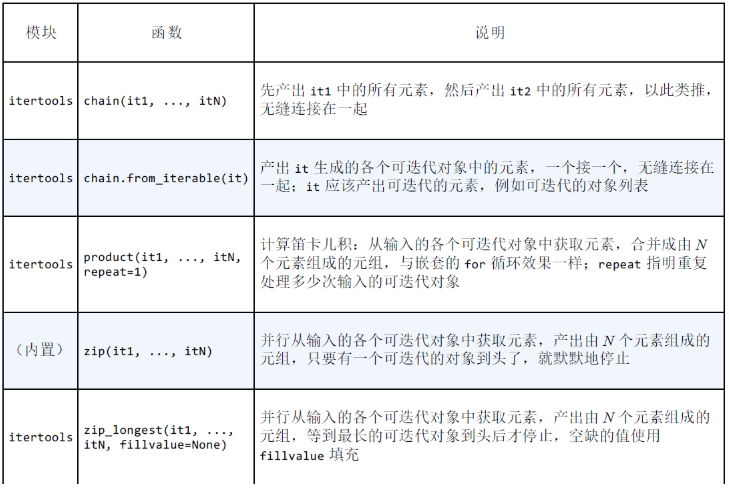
-
把输入的各个元素扩展成多个输出元素的生成器函数

-
用于重新排列元素的生成器函数
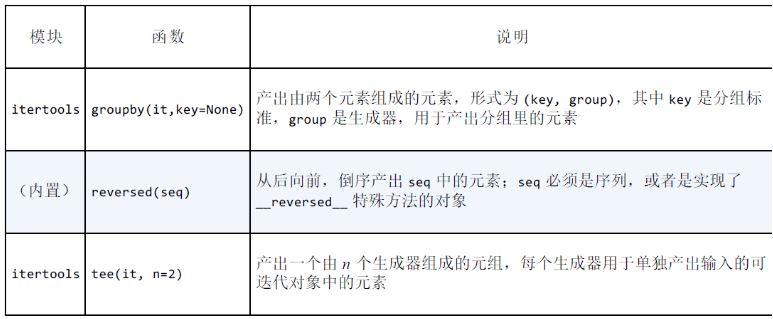
-
读取迭代器返回单个值的内置函数
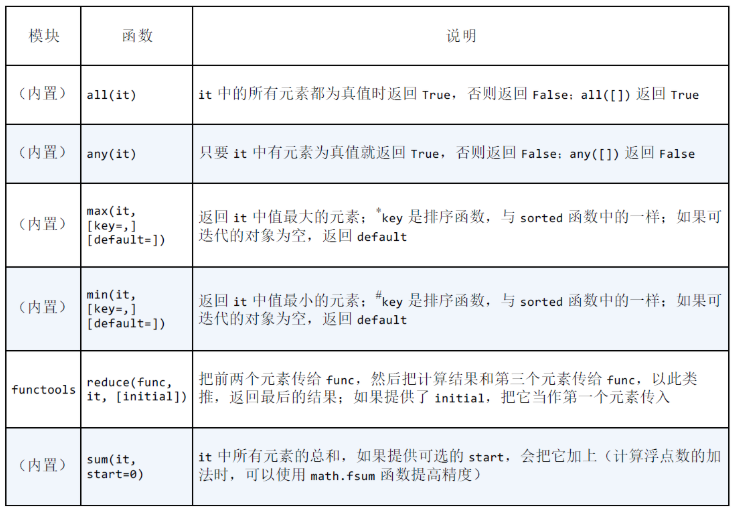
生成器解析
列表解析
>>> [x ** 2 for x in range(10) ] [0, 1, 4, 9, 16, 25, 36, 49, 64, 81]
生成器解析
#列表解析的[]括号,换成()圆括号,即可 >>> gt = (x ** 2 for x in range(10)) >>> gt <generator object <genexpr> at 0x7f810abf4550>
作业:内置函数range的参数必须是整数。请编写一个生成器函数,以浮点数为参数(开始值,结束值,步长)生成某范围的序列。
import itertools def frange(start, end=None, step=1.0): if end is None: end = float(start) start = 0.0 assert step # 当step不为True时,抛出错误 for i in itertools.count(): nxt = start + i * step if (step > 0.0 and nxt >= end) or (step < 0.0 and nxt <= end): break yield nxt f = frange(1.2, 9) print(list(f)) # [1.2, 2.2, 3.2, 4.2, 5.2, 6.2, 7.2, 8.2]
三、自定义对象类型
自定义对象类型的基本方法
类就是类型
- 自定义对象类型就是创建类
- 将类实例化,得到具体对象
例题:创建一个对任何数都保留一位小数的对象类型
class RoundFloat: def __init__(self, val): self.value = round(val,1) def __str__(self): return "{0:.1f}".format(self.value) __repr__ = __str__ numb = float(input("input your float number:")) r = RoundFloat(numb) print(r) #测试结果 input your float number:10.26 10.3
实现特有的属性和方法
使用特定函数
重写某些特殊方法
- 实现特有的程序
- 控制属性
- 属性私有化——不允许外部访问
- 控制属性访问:property(),@property
- 拦截属性
- 特殊方法
- __setattr__(self,name,value)
- __getattr__(self,name)
- __getattribute__(self,name)
- __delattr__(self,name)
- 特殊方法
例题:编写实现温度单位摄氏度转化华氏度的对象类型
#版本1 class Celsius: def __init__(self,temperature = 0): self.temperature = temperature def to_fahrenheit(self): return (self.temperature * 1.8) + 32 #用摄氏度实例化 c2f = Celsius(32) print("实例的属性和值:",c2f.__dict__)#实例属性__dict__,是显示该实例的属性 c2f.temperature = -300#如果温度是负值则出错,不符合现实世界物理规则 #对应的华氏度值 fah = c2f.to_fahrenheit() print("{C}C = {F}F".format(C=c2f.temperature,F=fah)) #版本2 class Celsius: def __init__(self,temperature = 0): self.set_temperature(temperature)#初始化调用设置温度的方法 def to_fahrenheit(self): return (self.temperature * 1.8) + 32 #new update def get_temperature(self): return self.temperature def set_temperature(self,value): if value < -273.5: raise ValueError("Temperature below -273.5 is impossible") self.temperature = value while True: t = float(input("input your temperature(Celsius):")) try: c = Celsius(t) print("{C}C = {F}F".format(C=c.get_temperature(), F=c.to_fahrenheit())) except ValueError as e: print(e) continue
#版本3 class Celsius: def __init__(self,temperature = 0): self.set_temperature(temperature)#初始化调用设置温度的方法 def to_fahrenheit(self): return (self.temperature * 1.8) + 32 #new update def get_temperature(self): return self.temperature def set_temperature(self,value): if value < -273.5: raise ValueError("Temperature below -273.5 is impossible") self.temperature = value c = Celsius(-200) print(c.__dict__)#当前实例的属性 c.temperature = -300#覆盖原来的属性 print("{C}C = {F}F".format(C=c.get_temperature(), F=c.to_fahrenheit())) print(c.__dict__) #版本4 class Celsius: def __init__(self,temperature = 0): self.temperature = temperature #初始化调用设置温度的方法 def to_fahrenheit(self): return (self.__temperature * 1.8) + 32 #new update def get_temperature(self): print("Getting value") return self.__temperature def set_temperature(self,value): if value < -273.5: raise ValueError("Temperature below -273.5 is impossible") print("Setting value") self.__temperature = value temperature = property(get_temperature,set_temperature) c = Celsius(-200) print(c.__dict__)#当前实例的属性 c.temperature #覆盖原来的属性 print("{C}C = {F}F".format(C=c.get_temperature(), F=c.to_fahrenheit())) print("{C}C = {F}F".format(C=c.temperature,F=c.to_fahrenheit()))
#版本5 class Celsius: def __init__(self,temperature = 0): self.temperature = temperature #初始化调用设置温度的方法 def to_fahrenheit(self): return (self.__temperature * 1.8) + 32 @property def temperature(self): print("Getting value") return self.__temperature @temperature.setter def temperature(self,value): if value < -273.5: raise ValueError("Temperature below -273.5 is impossible") print("Setting value") self.__temperature = value # temperature = property(get_temperature,set_temperature) c = Celsius(-200) print(c.__dict__)#当前实例的属性 # c.temperature #覆盖原来的属性 print("{C}C = {F}F".format(C=c.temperature,F=c.to_fahrenheit())) print("{C}C = {F}F".format(C=c.temperature,F=c.to_fahrenheit()))
例题:编写一个关于矩形的对象类型,能够通过长、宽设置属性值
class Rectangle: def __init__(self): self.width = 0 self.length = 0 def __getattr__(self, name): if name == 'size': return self.width,self.length else: raise AttributeError def __setattr__(self, name,value): if name == 'size': self.width,self.length = value else: self.__dict__[name] = value rect = Rectangle() rect.width = 3 rect.length = 4 print(rect.size) rect.size = 30,40 print(rect.width) print(rect.length) #结果为 (3, 4) 30 40
优化
class Rectangle: def __init__(self): self.width = 0 self.length = 0 def __getattr__(self, name): if name == 'size': return self.width, self.length else: raise AttributeError def __setattr__(self, name, value): # 此处增加了 try/except代码 try: if name == 'size': self.width, self.length = value else: self.__dict__[name] = value except TypeError: print('There are two numbers!') rect = Rectangle() rect.width = 3 rect.length = 4 print(rect.size) print('---'*15) rect.size = 30 print(rect.width) print(rect.length)
例题:
- 分数的表示形式如3/2这样,但是这种形式在python中是按照除法进行处理。Python的内置对象类型中又没有分数类型(不仅Python没有,是相当多高级语言都没有),所以,有必要自定义一个相关的类型。
- 附加题:在上述基础上,实现分数加法运算
class Fraction: def __init__(self, number, denom=1):#分母初始化设置为1 self.number = number self.denom = denom def __str__(self): return str(self.number) + '/' + str(self.denom) __repr__ = __str__ f = Fraction(2, 3) print(f) # 2/3
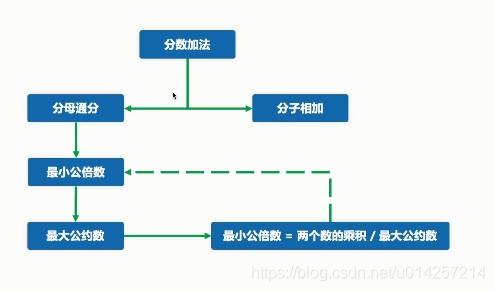
class Fraction: def __init__(self, number, denom = 1): self.number = number self.denom = denom def __str__(self): return str(self.number) + '/' + str(self.denom) __repr__ = __str__ @staticmethod def gcd(a, b): # 最大公约数 if not a > b: a, b = b, a while b != 0: remainder = a % b a, b = b, remainder return a @staticmethod def lcm(a, b): # 最小公倍数 return (a * b) / Fraction.gcd(a, b) def __add__(self, other): lcm_num = Fraction.lcm(self.denom, other.denom) number_num = (lcm_num / self.denom * self.number ) + (lcm_num / other.denom * other.number) return Fraction(number_num, lcm_num) m = Fraction(1, 3) n = Fraction(1, 2) s = m + n print(s)
四、本章总结
python中*号的作用
作为运算符
- 乘法和乘方的运算符
>>> 2 ** 3 8 >>> 2 * 3 6
- 重复元素
>>> lst = [0] * 10 >>> lst [0, 0, 0, 0, 0, 0, 0, 0, 0, 0] >>> "*" * 15 '***************' >>> (1,2) * 10 (1, 2, 1, 2, 1, 2, 1, 2, 1, 2, 1, 2, 1, 2, 1, 2, 1, 2, 1, 2)
收集参数
- 一个星(*):表示接收的参数作为元组来处理
- 两个星(**):表示接收的参数作为字典来处理
#一个星(*):表示接收的参数作为元组来处理 >>> def save_ranking(*args): ... print(args) ... >>> save_ranking('ming','alice','tom','wilson','roy') ('ming', 'alice', 'tom', 'wilson', 'roy') #两个星(**):表示接收的参数作为字典来处理 >>> def save_rank(*args,**kwargs): ... print(args) ... print(kwargs) ... >>> save_rank('ming','alice','tom',fourth='wilson',firth='roy') ('ming', 'alice', 'tom') {'fourth': 'wilson', 'firth': 'roy'}
解包容器类对象
- 解包序列
>>> lst = [1,2,3,4] >>> a,*b,c = lst >>> a 1 >>> b [2, 3] >>> c 4 #a和c分别接受lst的第一个值、最后一个值 >>> a,*b = lst >>> a 1 >>> b [2, 3, 4] #*b表示接受除了a之外的所有值
命名空间和作用域
- 命名空间
- 任何一个对象都出于某个空间
- 命名空间:当前定义的符号及其应用的对象信息的集合
- 命名空间类似字典,键:对象名称;值:对象
-
python中三种命名空间
- 每个命名空间有不同的生命周期
- python执行一个程序时,会根据需要创建命名空间,并在不需要时删除。
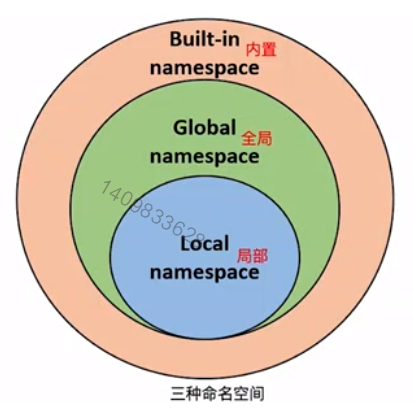
- 内置命名空间
- 内置命名空间包含python所以内置对象的名称,当python运行时,这些内置命名空间可以直接使用。
- python解释器在启动时直接创建内置命名空间,并且这个命名空间一直存在,直到解释器终止。
>>> dir(__builtins__) ['ArithmeticError', 'AssertionError', 'AttributeError', 'BaseException', 'BlockingIOError', 'BrokenPipeError', 'BufferError', 'BytesWarning', 'ChildProcessError', 'ConnectionAbortedError', 'ConnectionError', 'ConnectionRefusedError', 'ConnectionResetError', 'DeprecationWarning', 'EOFError', 'Ellipsis', 'EnvironmentError', 'Exception', 'False', 'FileExistsError', 'FileNotFoundError', 'FloatingPointError', 'FutureWarning', 'GeneratorExit', 'IOError', 'ImportError', 'ImportWarning', 'IndentationError', 'IndexError', 'InterruptedError', 'IsADirectoryError', 'KeyError', 'KeyboardInterrupt', 'LookupError', 'MemoryError', 'ModuleNotFoundError', 'NameError', 'None', 'NotADirectoryError', 'NotImplemented', 'NotImplementedError', 'OSError', 'OverflowError', 'PendingDeprecationWarning', 'PermissionError', 'ProcessLookupError', 'RecursionError', 'ReferenceError', 'ResourceWarning', 'RuntimeError', 'RuntimeWarning', 'StopAsyncIteration', 'StopIteration', 'SyntaxError', 'SyntaxWarning', 'SystemError', 'SystemExit', 'TabError', 'TimeoutError', 'True', 'TypeError', 'UnboundLocalError', 'UnicodeDecodeError', 'UnicodeEncodeError', 'UnicodeError', 'UnicodeTranslateError', 'UnicodeWarning', 'UserWarning', 'ValueError', 'Warning', 'ZeroDivisionError', '_', '__build_class__', '__debug__', '__doc__', '__import__', '__loader__', '__name__', '__package__', '__spec__', 'abs', 'all', 'any', 'ascii', 'bin', 'bool', 'breakpoint', 'bytearray', 'bytes', 'callable', 'chr', 'classmethod', 'compile', 'complex', 'copyright', 'credits', 'delattr', 'dict', 'dir', 'divmod', 'enumerate', 'eval', 'exec', 'exit', 'filter', 'float', 'format', 'frozenset', 'getattr', 'globals', 'hasattr', 'hash', 'help', 'hex', 'id', 'input', 'int', 'isinstance', 'issubclass', 'iter', 'len', 'license', 'list', 'locals', 'map', 'max', 'memoryview', 'min', 'next', 'object', 'oct', 'open', 'ord', 'pow', 'print', 'property', 'quit', 'range', 'repr', 'reversed', 'round', 'set', 'setattr', 'slice', 'sorted', 'staticmethod', 'str', 'sum', 'super', 'tuple', 'type', 'vars', 'zip']
- 全局命名空间
- 全局命名空间包含主程序级别定义的任何名称。
- 全局命名空间在主程序启动时创建,直到解释器终止。
- 使用import语句加载的任何模块也是全局命名空间
- 局部命名空间
- 也可以称为“本地命名空间”。
- 比如函数,每一个函数一旦运行,就创建了一个新的命名空间。该命名空间是函数的本地命名空间,它的存在一直持续到函数终止。
- 局部命名空间的生命周期是自其建立开始,到它们各自的函数执行完毕终止
>>> def f(): ... print("start f()") ... def g(): ... print("start g()") ... print("end g()") ... return ... g() ... print("end f()") ... return ... >>> f() start f() start g() end g() end f()
- 变量作用域
- 命名空间意味着允许python程序可以在不同命名空间中有几个不同的实例同时存在——但是这些实例名称相同
- 由此产生一个问题:假设代码中引用了名称x,并且x存在于多个命名空间,python怎么知道你指的是哪个命名空间?
- 名称的作用域是某个程序的区域,而在这个区域中该名称具有意义。
- 解释器在运行时根据名称定义的位置以及名称在代码中被引用的位置来确定其作用域。
- 命名空间意味着允许python程序可以在不同命名空间中有几个不同的实例同时存在——但是这些实例名称相同
- 作用域搜索顺序
- 本地作用域:如果在一个函数中引用x,则先在该函数本地最内部作用域中搜索
- 闭包作用域:如果x不在本地作用域中,而是出现在另一个函数的内部函数中,则解释器将搜索闭包函数的作用域。
- 全局作用域:如果以上两个搜索都没有结果,则解释器将搜索全局作用域。
- 内置作用域:如果在其他地方找不到x,那么解释器尝试搜索内置的作用域。
- 如果以上作用域里,都找不到名称x,则抛出NameError异常。
- 解释器从内到外搜索名称:本地—>闭包—>全局—>内置作用域—>抛出异常
>>> x = "global"#全局作用域 >>> def f(): ... def g(): ... print(x) ... g() ... >>> f() global >>> x = "global"#全局作用域 >>> def f(): ... x = "enclosing"#闭包作用域 ... def g(): ... print(x) ... g() ... >>> f() enclosing >>> x = "global"#全局作用域 >>> def f(): ... x = "enclosing"#闭包作用域定义 ... def g(): ... x = "local"#函数内部本地 ... print(x) ... g() ... >>> f() local >>> def f(): ... def g(): ... print(y)#y未定义,故所有作用域搜索不到则报错NameError ... g() ... >>> f() Traceback (most recent call last): File "<stdin>", line 1, in <module> File "<stdin>", line 4, in f File "<stdin>", line 3, in g NameError: name 'y' is not defined
- 作用域之外的变量
- 可变对象
>>> lst = [1,2,3] >>> def f(): ... lst.append(100)#本地没有lst,则搜索全局变量,然后追加100 ... >>> f() >>> lst [1, 2, 3, 100]#此结果是显示全局变量lst,即通过本地作用域修改了全局作用域的变量 >>> lst [1, 2, 3, 100] >>> def f(): ... lst = [100,200]#本地作用域赋值无法修改全局作用域变量 ... >>> f() >>> lst [1, 2, 3, 100]
-
- 不可变对象
>>> x = 20 >>> def f(): ... x = 40 ... print(x) ... >>> f() 40 >>> x#函数内本地作用域的变量x,不影响全局变量x的值 20
- 全局声明
如果全局声明中指定的名称,在函数启动时不存在于全局作用域中,则global语句和赋值的组合将创建这一名称
>>> def f(): ... global x#全局作用域中不存在x,则创建并赋值全局命名空间x变量 ... x = 40 ... print(x) ... >>> f() 40 >>> x 40 >>> x = 20#全局作用域中存在x,而x=40输出为本地x,且将其赋值给全局命名空间的变量x >>> def f(): ... global x ... x = 40 ... print(x) ... >>> f() 40 >>> x 40
- 非本地声明
>>> def f(): ... x = 20 ... def g(): ... x = 40#本地声明的x=40,仅在g()函数内部作用域生效 ... g() ... print(x) >>> f() 20 #而x=20属于g()函数外层空间的闭包作用域,print则从其所在作用域(即闭包作用域)开始向外搜索x,而不会向g()函数内部搜索 #如果想在g()函数中修改或者使用闭包作用域x的值,则使用nonlocal >>> def f(): ... x = 20 ... def g(): ... nonlocal x ... x = 50 ... g() ... print(x)#非本地声明(即不是闭包作用域)的变量,则从其最近作用域搜索,故打印50 ... >>> f() 50
注意事项
- 尽量少用global和nonlocal
- 尽量避免修改全局变量
- 不要再本地作用域之外修改变量
- 使用函数返回值
is和==的应用
- is检查两个变量是否指向内存中的同一个对象
- 具有相同值的对象,在默认情况下具有相同的id值(内存地址)
- 数字-5~256,每个数字都存储在内存中单一且固定的位置,这为常用数字节省了内存。
>>> a = 256 >>> b = 256 >>> a is b True >>> id(a) 9499008 >>> id(b) 9499008
>>> c = 257 >>> d = 257 >>> id(c) 140155397375376 >>> id(d) 140155397375664 >>> c is d False #如果是在.py程序文件中,结果则与上面的不同 #交互模式中,执行完一行之后,就会“忘记”上面的变量赋值 c = 257 d = 257 print(id(c)) print(id(d)) if (c is d): print("a is b") else: print("a is not b") #结果 2146441982928 2146441982928 a is b
>>> a = "hello world" >>> b = "hello world" >>> a is b False >>> id(a) 140155396894384 >>> id(b) 140155396894448 >>> >>> from sys import intern >>> c = intern(a) >>> d = intern(b) >>> c is d True >>> id(c) 140155396894384 >>> id(d) 140155396894384
#intern的参数一般是简单字符串、None、True、False
- 结论:
- is比较对象的内存地址
- 不用is来比较值是否相同,而是用==、!=
- ==比较两个对象值是否相等
- ==:比较两个对象的值,实际是调用方法__eq__()
- 两个对象(实例)比较时,如果没有此方法,则比较对象的内存地址
- !=:实际是调用方法__ne__()
>>> class SillyString(str): ... #当使用== 时,调用下面的方法 ... def __eq__(self,other): ... print("comparing {self} to {other}") ... return len(self) == len(other)#如果两个实例长度,则返回True ... >>> >>> c = SillyString("laoqi") >>> d = SillyString("12345") >>> if c == d: ... print("a == b") ... else: ... print("a != b") ... comparing {self} to {other} a == b
- 结论:
- 比较值是否相等:==、!=
- 比较对象的唯一标识(内存地址):is、is not
- 与None进行比较:is、is not
- is不依赖任何类似__eq__()方法
- ==、!=、is、is not的应用
python中的魔法方法
- __new__和__init__
- 下划线:
- 函数或变量命名:calculate_var_value
- 私有化:
- 在方法名称前面加上一个下划线:_method
- 在方法名称前面加上两个下划线:__method
- 魔法方法,也称为“特殊方法”:
- 在方法名称前、后分别加上两个下划线:__my_method__
- 还可以称为:dunders
- __init__:初始化方法,实例化的时候,首先要调用此方法
- 下划线:
#__init__:初始化方法 >>> class Product: ... def __init__(self,name,price): ... self.name = name ... self.price = price ... #__init__方法默认返回值是None >>> product = Product("Vacuum",150.0) >>> product <__main__.Product object at 0x7f610ef63090> >>> >>> product.name 'Vacuum' >>> product.price 150.0
-
- __new__:构造方法
#__new__:构造方法>>> class Product: ... def __new__(cls,*args): ... new_product = object.__new__(cls) ... print("Product __new__ gets called") ... return new_product ... def __init__(self,name,price): ... self.name = name ... self.price = price ... print("Product __init__ gets called") ... #__init__方法默认返回值是None,不能返回其他的非None值 >>> product = Product("Vacuum",200.0) Product __new__ gets called Product __init__ gets called
#说明__new__构造方法优先于__init__初始化方法返回值
- 说明:什么情况下使用 __new__() 呢?答案很简单,在 __init__() 不够用的时候。对 Python 不可变的内置类型(如 int、str、float 等)进行了子类化,这是因为一旦创建了这样不可变的对象实例,就无法在 __init__() 方法中对其进行修改。
- 比较两个方法的参数,发现__new__方法是传入类对象(cls),而__init__方法传入类的实例化对象(self)。__new__方法返回的值就是一个实例化对象(ps:如果__new__方法返回None,则__init__方法不会被执行,并且返回值只能调用父类中的__new__方法,而不能调用毫无关系的类的__new__方法)。可以这么理解它们之间的关系,__new__是开辟疆域的大将军,而__init__是在这片疆域上辛勤劳作的小老百姓,只有__new__执行完后,开辟好疆域后,__init__才能工作,结合到代码,也就是__new__的返回值正是__init__中self。
class CapStr(str): def __new__(cls, string): self_in_init = super().__new__(cls, string) print(id(self_in_init)) return self_in_init def __init__(self,string): print(id(self)) a = CapStr("I love China!") print(id(a)) 执行结果为: 2691640428616 2691640428616 2691640428616
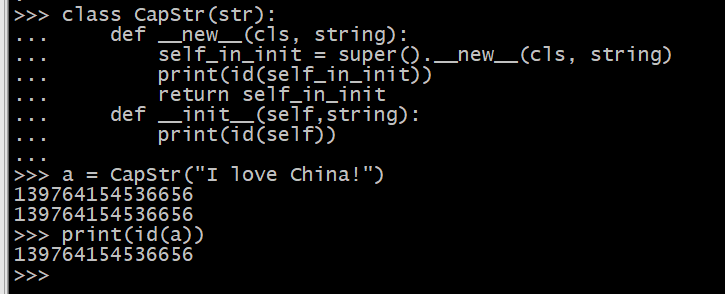
- __repr__和__str__
- __repr__:对机器友好
- __str__:对人友好
#字符串表示法
>>> class Product: ... def __init__(self,name,price): ... self.name = name ... self.price = price ... def __repr__(self): ... return f"Product({self.name!r},{self.price!r})"#r标记该值能被后面的product函数调用 ... def __str__(self): ... return f"Product:{self.name},${self.price:.2f}"#f返回字符串 ... >>> product = Product("Vacuum",300.0) >>> repr(product) "Product('Vacuum',300.0)" >>> evaluated = eval(repr(product))#eval内置函数的作用是如果参数是字符串,则将其里面的函数执行一遍 >>> type(evaluated) <class '__main__.Product'> >>> print(product) Product:Vacuum,$300.00
- __iter__和__next__
- __iter__:将可迭代对象转换为迭代器,为每次循环提供可迭代对象中的项
- __next__:读取迭代器的下一项
class Product: def __init__(self, name, price): self.name = name self.price = price def __str__(self): return f"Product:{self.name},${self.price:.2f}" def __iter__(self): self._free_samples = [Product(self.name,0) for _ in range(3)] print("Iterator of product is created") return self def __next__(self): if self._free_samples: return self._free_samples.pop() else: raise StopIteration("All free samples have been dispensed") product = Product("Perfume",5.0) for i,sample in enumerate(product,1): print(f"Dispense the next sample #{i}:{sample}") #执行结果 Iterator of product is created Dispense the next sample #1:Product:Perfume,$0.00 Dispense the next sample #2:Product:Perfume,$0.00 Dispense the next sample #3:Product:Perfume,$0.00
- __enter__和__exit__
- __enter__:设置上下文管理器,准备操作所需的资源
- __exit__:清理应释放的任何已用资源,参数值有3个:
- 异常类型
- 异常对象
- 异常回溯
- 参考资料:https://www.cnblogs.com/haitaoli/p/10779632.html
- 自定义open方法
class MyOpen3(object): def __init__(self, file_obj, mode='r', encoding='utf-8'): self.file_obj = file_obj self.mode = mode self.encoding = encoding def __enter__(self): self.f = open(file=self.file_obj, mode=self.mode, encoding=self.encoding) return self.f def __exit__(self, exc_type, exc_val, exc_tb): self.f.close() with MyOpen3('a.txt', mode='w', encoding='utf-8') as f3: f3.write('custom with ... as ...')
- __hasattr__、__getattr和__setattr__
- __hasattr__(object, name):判断object里是否有name属性,有就返回True,没有则返回False。
- __getattr__(object, name, [default]):访问对对象的属性时调用,用来获取object的属性或方法,有就打印出来. 没有就打印默认值,若是没有设置默认值则报错
- __setattr__setattr(object, key, value):设置实例对象属性时调用,用来对object的属性key赋值value. 若是key存在,则更新value的值. 若key不存在,则先创建属性key再对其赋值value.
- 注意:name参数是string类型,所以不管是要判断变量还是方法,其名称都以字符串形式传参;getattr和setattr也同样;
- 参考资料:
- https://www.php.cn/python-tutorials-414079.html
- https://www.cnblogs.com/cheyunhua/p/11016127.html
- https://www.bbsmax.com/A/kjdw83xEzN/
- 方法说明:
- 获取object对象的属性的值,如果存在则返回属性值,如果不存在分为两种情况:一种是没有default参数时,会直接报错;给定了default参数,若对象本身没有name属性,则会返回给定的default值;如果给定的属性name是对象的方法,则返回的是函数对象,需要调用函数对象来获得函数的返回值;调用的话就是函数对象后面加括号,如func之于func();
- 'func')(),因为fun()是实例函数的话,是不能用A类对象来调用的,应该写成getattr(A(), 'func')();实例函数和类函数的区别可以简单的理解一下,实例函数定义时,直接def func(self):,这样定义的函数只能是将类实例化后,用类的实例化对象来调用;而类函数定义时,需要用@classmethod来装饰,函数默认的参数一般是cls,类函数可以通过类对象来直接调用,而不需要对类进行实例化;
#getattr
class A(): name = 'python' def func(self): return 'Hello world' getattr(A, 'name') # 结果:'python' getattr(A, 'age') # age变量不存在则报错 # 结果:Traceback (most recent call last): # File "<pyshell#464>", line 1, in <module> # getattr(A, 'age') # AttributeError: class A has no attribute 'age' getattr(A, 'age', 20) # 结果:20 getattr(A, 'func') # 结果:<unbound method A.func> getattr(A, 'func')() # func()函数不能被A类对象调用,所以报错 # 结果:Traceback (most recent call last): # File "<pyshell#470>", line 1, in <module> # getattr(A, 'func')() # TypeError: unbound method func() must be called with A instance as first argument (got nothing instead) getattr(A(), 'func')() # 结果:'Hello world' class A(object): name = 'python' @classmethod def func(cls): return 'the method of A object.' getattr(A, 'func')() # 结果:'the method of A object.'
#setattr class A(): name = 'python' def func(self): return 'Hello world' setattr(A, 'name', 'java') getattr(A, 'name') # 结果:'java' setattr(A, 'age', 20) getattr(A, 'age') # 结果:20
- __hasattr__、__getattr和__setattr__三个方法一起使用
class MyClass(object): name = 'jack' age = '22' # 判断Myclass是否有gender属性,有则打印,没有则添加 def if_attr(gender='male'): if hasattr(MyClass, 'gender'): return getattr(MyClass, 'gender') return setattr(MyClass, 'gender', gender) if_attr(gender='female') print(getattr(MyClass, 'gender')) # female
class Product: def __init__(self,name): self.name = name def __getattr__(self,item): if item == "formatted_name": print(f"__getattr__ is called for {item!r}") formatted = self.name.capitalize() setattr(self,"formatted_name",formatted) return formatted else: raise AttributeError(f"no attribute of {item}") def __setattr__(self, key, value): print(f"__setattr__ is called for {key!r}:{value!r}") super().__setattr__(key,value) book = Product("machine leraning") # book.formatted_name book.name = 'x' book.test = 'y' #执行结果 __setattr__ is called for 'name':'machine leraning' __setattr__ is called for 'name':'x' __setattr__ is called for 'test':'y'
数据类型的内置函数
- 参考地址:https://www.cnblogs.com/llj0403/p/9223558.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号