

BAT机器学习面试1000题系列(86-90题)
BAT机器学习面试1000题系列(86-90题)
86.已知一组数据的协方差矩阵P,下面关于主分量说法错误的是(C)
A、主分量分析的最佳准则是对一组数据进行按一组正交基分解, 在只取相同数量分量的条件下,以均方误差计算截尾误差最小
B、在经主分量分解后,协方差矩阵成为对角矩阵
C、主分量分析就是K-L变换
D、主分量是通过求协方差矩阵的特征值得到
@BlackEyes_SGC:K-L变换与PCA变换是不同的概念,PCA的变换矩阵是协方差矩阵,K-L变换的变换矩阵可以有很多种(二阶矩阵、协方差矩阵、总类内离散度矩阵等等)。当K-L变换矩阵为协方差矩阵时,等同于PCA。
87.kmeans的复杂度
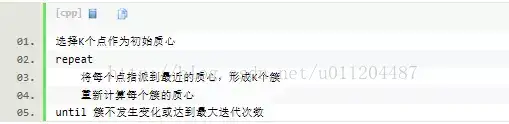
时间复杂度:O(tKmn),其中,t为迭代次数,K为簇的数目,m为记录数,n为维数空间复杂度:O((m+K)n),其中,K为簇的数目,m为记录数,n为维数
88.关于logit 回归和SVM 不正确的是(A)
A. Logit回归本质上是一种根据样本对权值进行极大似然估计的方法,而后验概率正比于先验概率和似然函数的乘积。logit仅仅是最大化似然函数,并没有最大化后验概率,更谈不上最小化后验概率。A错误
B. Logit回归的输出就是样本属于正类别的几率,可以计算出概率,正确
C. SVM的目标是找到使得训练数据尽可能分开且分类间隔最大的超平面,应该属于结构风险最小化。
D. SVM可以通过正则化系数控制模型的复杂度,避免过拟合。
@BlackEyes_SGC:Logit回归目标函数是最小化后验概率,Logit回归可以用于预测事件发生概率的大小,SVM目标是结构风险最小化,SVM可以有效避免模型过拟合。
89.输入图片大小为200×200,依次经过一层卷积(kernel size 5×5,padding 1,stride 2),pooling(kernel size 3×3,padding 0,stride 1),又一层卷积(kernel size 3×3,padding 1,stride 1)之后,输出特征图大小为(97): @BlackEyes_SGC:计算尺寸不被整除只在GoogLeNet中遇到过。卷积向下取整,池化向上取整。
本题 (200-5+2*1)/2+1 为99.5,取99
(99-3)/1+1 为97
(97-3+2*1)/1+1 为97
研究过网络的话看到stride为1的时候,当kernel为 3 padding为1或者kernel为5 padding为2 一看就是卷积前后尺寸不变。计算GoogLeNet全过程的尺寸也一样。
90.影响聚类算法结果的主要因素有(B、C、D )。
A.已知类别的样本质量; B.分类准则; C.特征选取; D.模式相似性测度
文章被以下专栏收录
推荐阅读

BAT机器学习面试1000题系列(11-20题)

秋招在即,这6道AI经典算法面试题,值得收藏!

机器学习面试笔试求职必背!八股文(5/5)


 浙公网安备 33010602011771号
浙公网安备 33010602011771号
3 条评论
88题a的后半句也没问题吧,"logit仅仅是最大化似然函数,并没有最大化后验概率,更谈不上最小化后验概率"。 反而解析中说是最小化后验概率这个说法是错的吧,即没有后验概率,也不应该是最小化。
logit函数的输出应该是对数几率,logistic回归输出应该是概率。统计学习方法第78页,希望有高手指点我的看法。
没有错的。B选项,文中说“Logit回归的输出就是样本属于正类别的几率,可以计算出概率”,输出几率,然后可以计算出概率。而A选项,前半句是没问题的,错在了后半句。(觉得引起误解的原因是作者把问题和解释放在了一起,分不清哪个是题,哪个是解析,故可能会引起歧义)