

第一次个人编程作业
第一次个人编程作业
Part1 作业链接
[Github作业链接](https://github.com/chentan01/031802402)
Part2 PSP表格
| PSP2.1 | Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | 60 | 120 |
| Estimate | 估计这个任务需要多少时间 | 30 | 20 |
| Development | 开发 | 600 | 1200 |
| Analysis | 需求分析 (包括学习新技术) | 180 | 300 |
| Design Spec | 生成设计文档 | 60 | 90 |
| Design Review | 设计复审 | 60 | 50 |
| Coding Standard | 代码规范 (为目前的开发制定合适的规范) | 120 | 30 |
| Design | 具体设计 | 30 | 50 |
| Coding | 具体编码 | 30 | 30 |
| Code Review | 代码复审 | 30 | 30 |
| Test | 测试(自我测试,修改代码,提交修改) | 60 | 60 |
| Reporting | 报告 | 120 | 90 |
| Test Report | 测试报告 | 60 | 60 |
| Size Measurement | 计算工作量 | 30 | 30 |
| Postmortem & Process Improvement Plan | 事后总结, 并提出过程改进计划 | 30 | 50 |
| 合计 | 1560 | 2210 |
Part3 流程分析
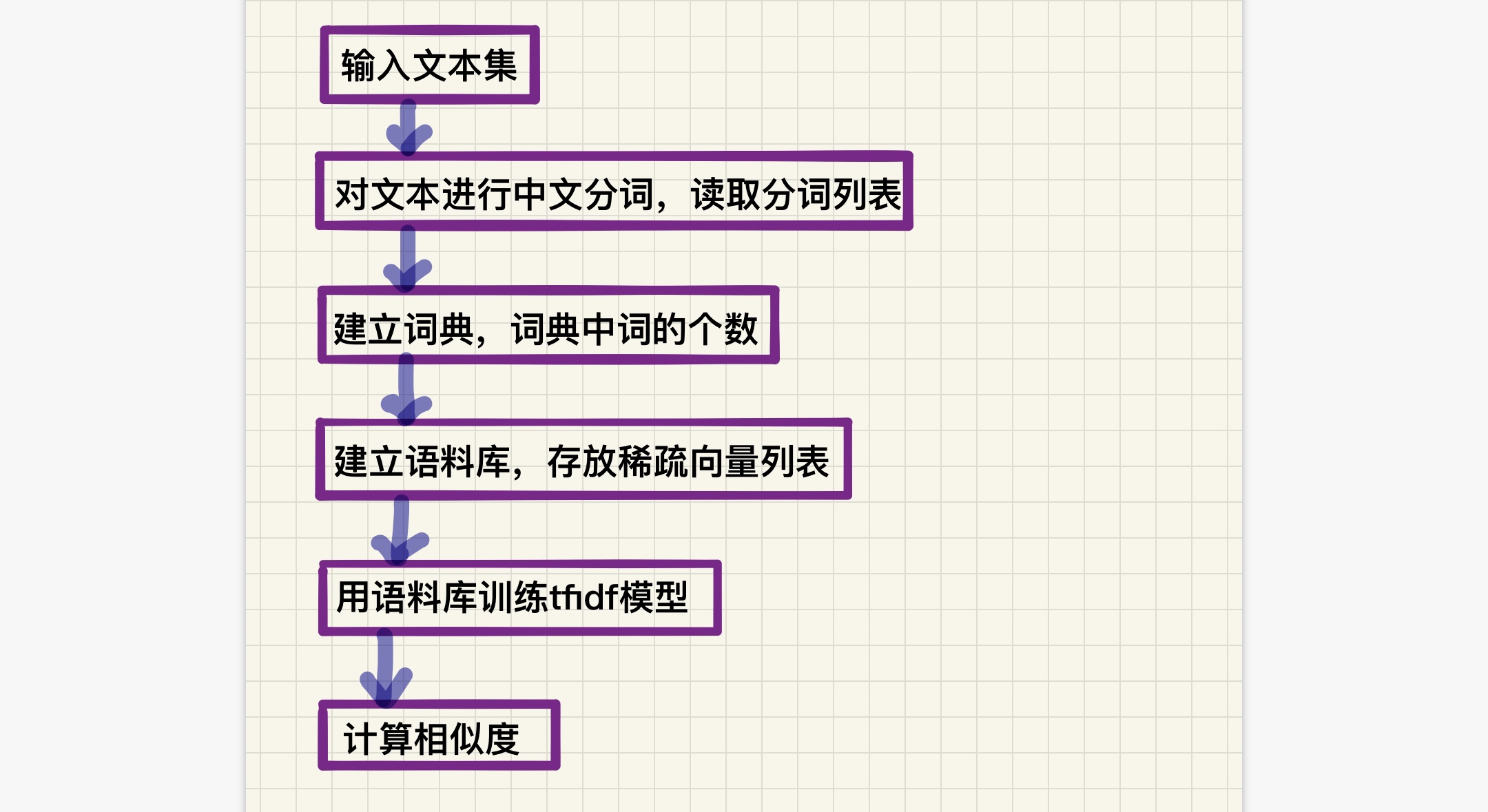
主要算法:
首先当然是利用jieba进行分词,关键词提取!*✧⁺˚⁺ପ(๑・ω・)੭ु⁾⁾
[详细jieba中文分词冲冲冲!](https://blog.csdn.net/yellow_python/article/details/80559586)
接着就是利用gensim下面的corpora,similarities进行语料库建立,模型TF-IDF算法,稀疏矩阵相似度分析
[gensim文本相似度分析冲冲冲!](https://blog.csdn.net/Yellow_python/article/details/81021142)
Part4 主要代码
读取文件并分词
test_1 = open(test1, encoding='utf-8').read()
test_2 = open(test2, encoding='utf-8').read()
data1 = jieba.cut(test_1)
data2 = jieba.cut(test_2)
合并分词
doc1 = [data_1, data_2]
t1 = [[word for word in doc.split()] for doc in doc1]
建立词典语料库
t1 = [[word for word in doc.split()] for doc in doc1]
# corpora语料库建立字典
dictionary = corpora.Dictionary(t1)
# 通过doc2bow把文件变成一个稀疏向量
new_vec = dictionary.doc2bow(new_doc.split())
# 对字典进行doc2bow处理,得到新语料库
new_corpor = [dictionary.doc2bow(t3) for t3 in t1]
tfidf = models.TfidfModel(new_corpor)
利用模型tfidf算法、稀疏矩阵相似度分析
index = similarities.SparseMatrixSimilarity(tfidf[new_corpor], num_features=featurenum)
sims = index[tfidf[new_vec]]
# sims[0]和sims[1]分别为文1文2与总文本的相似度
# 相除之后得两文本之间相似度
if (sims[1]<sims[0]):
ans = sims[1]/sims[0]
else:
ans = sims[0]/sims[1]
Part5 单元测试
(啊啊啊为啥还有几个文本相似度这么奇怪awsl
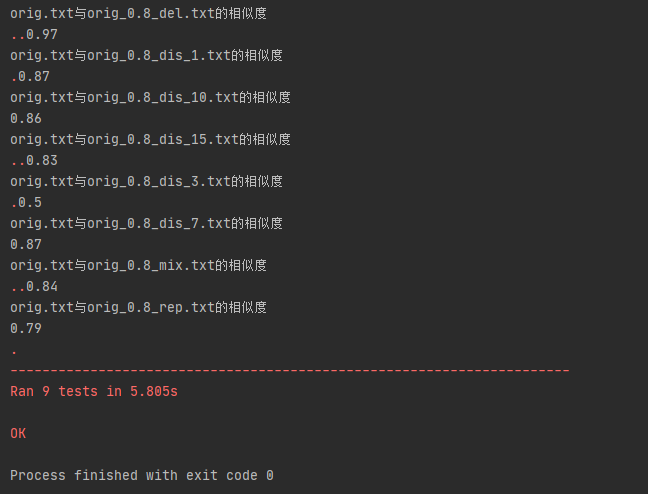
单元测试覆盖率:

单元测试代码:
import unittest
from chachong import SimilarityCalculate
class SimilarityTest (unittest.TestCase):
def test_add (self):
with open("D:\\sim_0.8\\orig.txt", "r", encoding='utf-8') as fp:
test_1=fp.read()
with open("D:\\sim_0.8\\orig_0.8_add.txt", "r", encoding='utf-8') as fp:
test_2 = fp.read()
print("orig.txt与orig_0.8_add.txt的相似度")
SimilarityCalculate(test_1, test_2)
def test_mix (self):
with open("D:\\sim_0.8\\orig.txt", "r", encoding='utf-8') as fp:
test_1 = fp.read()
with open("D:\\sim_0.8\\orig_0.8_mix.txt", "r", encoding='utf-8') as fp:
test_2 = fp.read()
print("orig.txt与orig_0.8_mix.txt的相似度")
SimilarityCalculate(test_1, test_2)
def test_del (self):
with open("D:\\sim_0.8\\orig.txt", "r", encoding='utf-8') as fp:
test_1 = fp.read()
with open("D:\\sim_0.8\\orig_0.8_del.txt", "r", encoding='utf-8') as fp:
test_2 = fp.read()
print("orig.txt与orig_0.8_del.txt的相似度")
SimilarityCalculate(test_1, test_2)
def test_rep(self):
with open("D:\\sim_0.8\\orig.txt", "r", encoding='utf-8') as fp:
test_1 = fp.read()
with open("D:\\sim_0.8\\orig_0.8_rep.txt", "r", encoding='utf-8') as fp:
test_2 = fp.read()
print("orig.txt与orig_0.8_rep.txt的相似度")
SimilarityCalculate(test_1, test_2)
def test_dis_1 (self):
with open("D:\\sim_0.8\\orig.txt", "r", encoding='utf-8') as fp:
test_1 = fp.read()
with open("D:\\sim_0.8\\orig_0.8_dis_1.txt", "r", encoding='utf-8') as fp:
test_2 = fp.read()
print("orig.txt与orig_0.8_dis_1.txt的相似度")
SimilarityCalculate(test_1, test_2)
def test_dis_3 (self):
with open("D:\\sim_0.8\\orig.txt", "r", encoding='utf-8') as fp:
test_1 = fp.read()
with open("D:\\sim_0.8\\orig_0.8_dis_3.txt", "r", encoding='utf-8') as fp:
test_2 = fp.read()
print("orig.txt与orig_0.8_dis_3.txt的相似度")
SimilarityCalculate(test_1, test_2)
def test_dis_7 (self):
with open("D:\\sim_0.8\\orig.txt", "r", encoding='utf-8') as fp:
test_1 = fp.read()
with open("D:\\sim_0.8\\orig_0.8_dis_7.txt", "r", encoding='utf-8') as fp:
test_2 = fp.read()
print("orig.txt与orig_0.8_dis_7.txt的相似度")
SimilarityCalculate(test_1, test_2)
def test_dis_10 (self):
with open("D:\\sim_0.8\\orig.txt", "r", encoding='utf-8') as fp:
test_1 = fp.read()
with open("D:\\sim_0.8\\orig_0.8_dis_10.txt", "r", encoding='utf-8') as fp:
test_2 = fp.read()
print("orig.txt与orig_0.8_dis_10.txt的相似度")
SimilarityCalculate(test_1, test_2)
def test_dis_15 (self):
with open("D:\\sim_0.8\\orig.txt", "r", encoding='utf-8') as fp:
test_1 = fp.read()
with open("D:\\sim_0.8\\orig_0.8_dis_15.txt", "r", encoding='utf-8') as fp:
test_2 = fp.read()
print("orig.txt与orig_0.8_dis_15.txt的相似度")
SimilarityCalculate(test_1, test_2)
if __name__ == '__main__':
unittest.main()
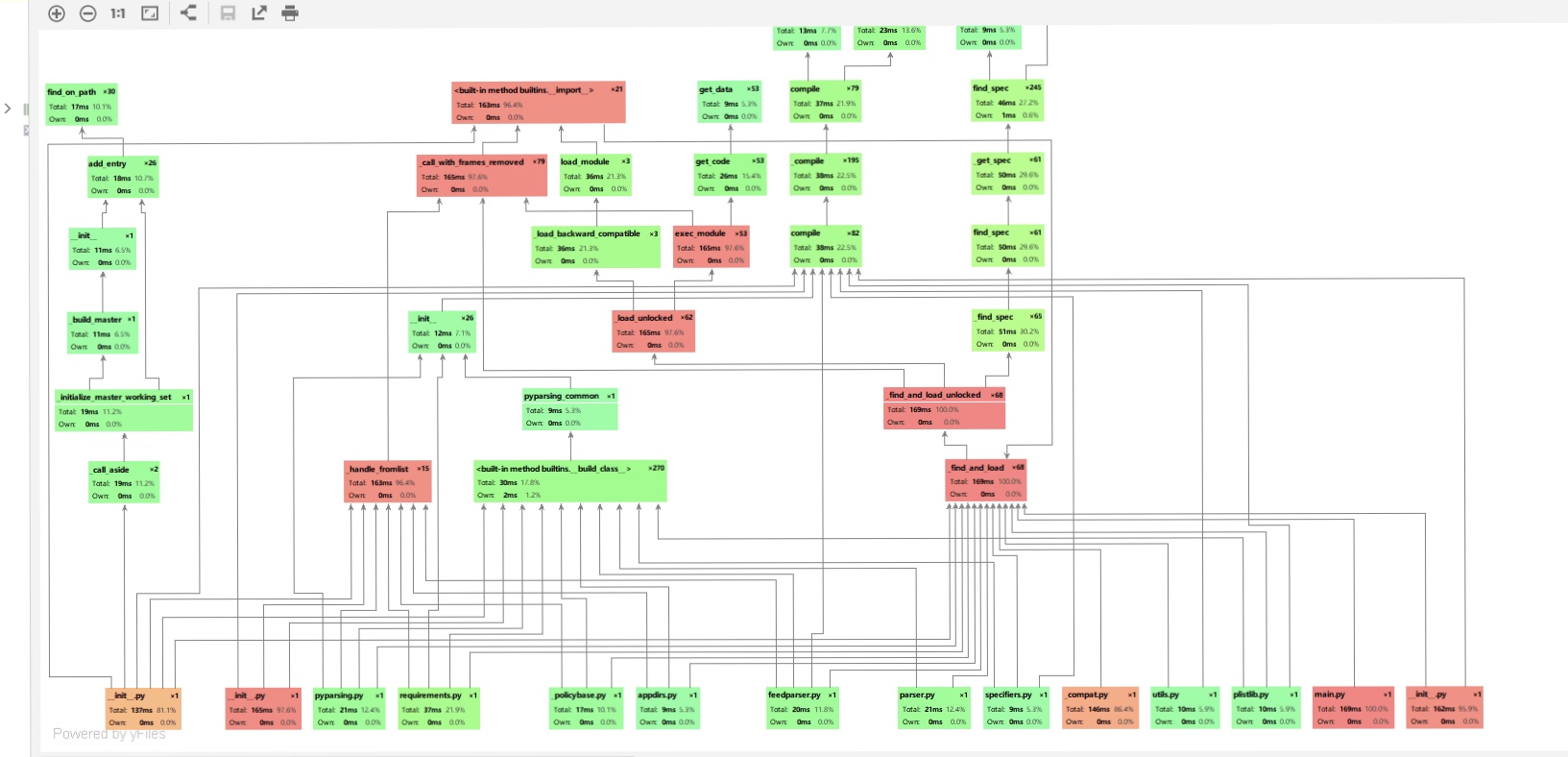
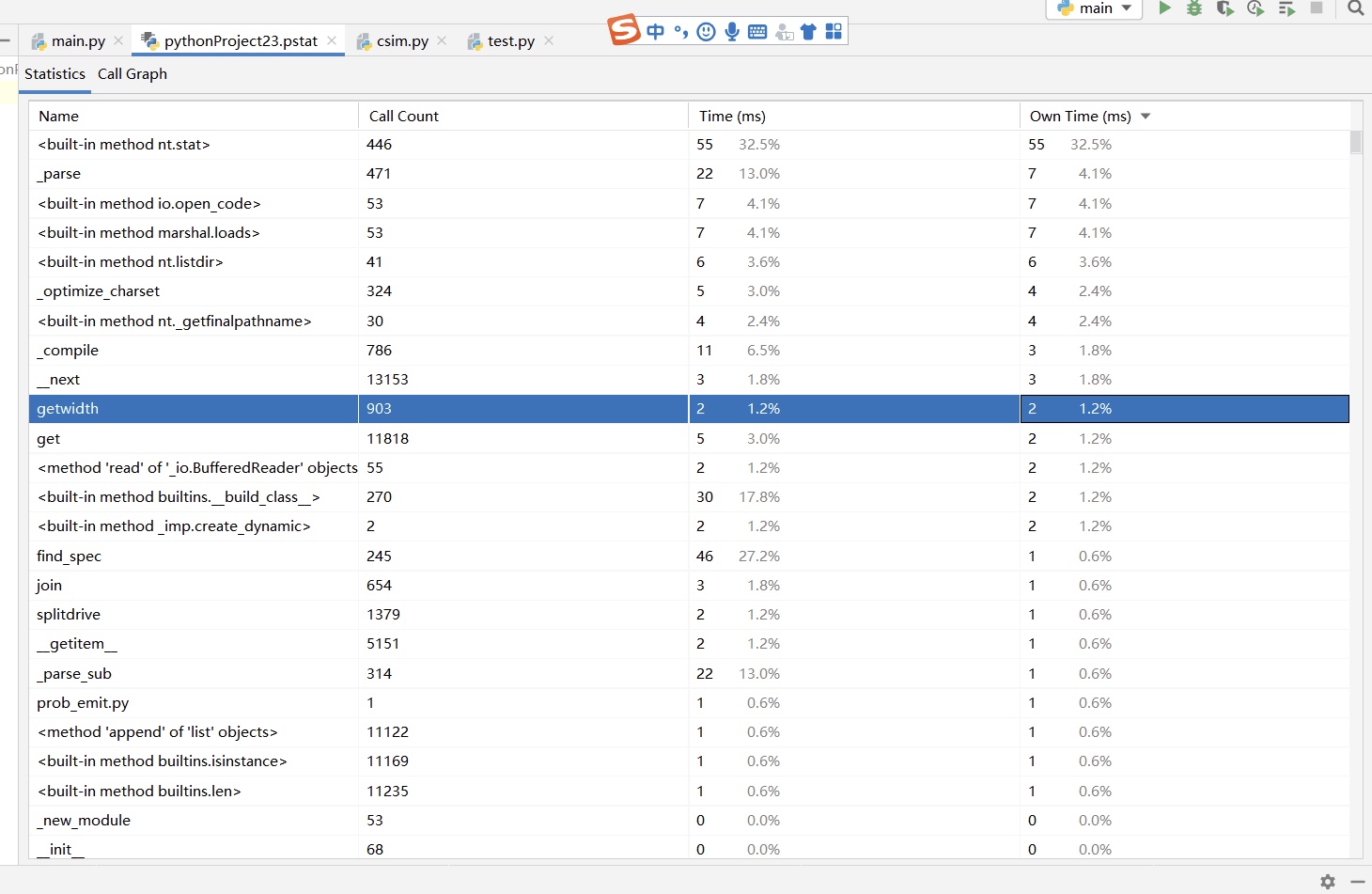
Part6 计算模块接口部分的性能改进
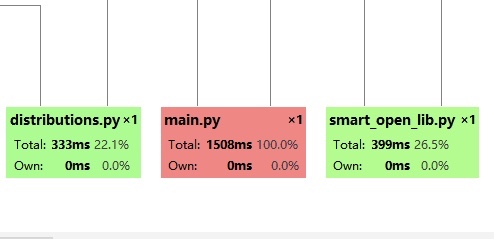
Part7 总结
在写第一次个人编程作业的十个日夜里,我用时最多的地方就是在学习各种各样的新
知识上。第一天看到这个题目的时候我是懵的,一开始是想用Java基于非深度学习的
方法用余弦相似度的计算方法来查相似度,但是在面向CSDN和面向GitHub编程的过程
中苦苦码字不得正解的过程中偶然看到Python语言里利用jieba和gensim进行相似度
分析…φ(๑˃∀˂๑)♪ 于是在deadline还有四天的时候推翻之前的东西重新开始。在这
个过程中真的学习到了许多东西,不仅仅是python和Java关于这道题目的知识,更是
在学习知识查找资料之中翻了许多网站和帖子更系统结构地地得到认知。虽然最后得到
的结果和答案还有很大偏差,但是俺会继续学习来改进的。٩(*Ӧ)و
Part8 写在最后
自从开始写软工作业之后,妈妈再也不用担心我打游戏了,每天起床第一句:“我真的学不完了!!!”٩(*Ӧ)و


 浙公网安备 33010602011771号
浙公网安备 33010602011771号