【linux】关于分析系统问题的前几分钟
为了解决性能问题,你登入了一台Linux服务器,在最开始的一分钟内需要查看什么?你可以在几分钟内就对系统资源的使用情况和进程的运行状况有大体上的了解。无非是先查看错误信息和饱和指标,再看下资源的使用量
1、之前发生了什么
[root@localhost ~]# history
1 2015-12-11_21:35:16 htop
2 2015-12-11_21:35:19 df -h
3 2015-12-11_21:35:25 cd /data/backup/
4 2015-12-11_21:35:26 ll
查看一下之前服务器上执行过的命令。看一下总是没错的,可以通过HISTTIMEFORMAT来设置一下命令的执行时间
2、用户状态
[root@localhost ~]# last -6 test pts/0 192.168.1.57 Fri Dec 11 21:35 still logged in test pts/0 192.168.1.57 Fri Dec 11 18:24 - 18:24 (00:00) test pts/3 192.168.1.57 Fri Dec 11 18:14 - 18:14 (00:00) test pts/3 192.168.1.57 Fri Dec 11 18:13 - 18:14 (00:00) test pts/0 192.168.1.57 Fri Dec 11 18:02 - 18:14 (00:11) test pts/0 192.168.1.57 Fri Dec 11 17:29 - 17:29 (00:00) [root@localhost ~]# w 21:42:20 up 284 days, 6:12, 1 user, load average: 0.27, 0.23, 0.19 USER TTY FROM LOGIN@ IDLE JCPU PCPU WHAT test pts/0 192.168.1.57 21:35 0.00s 0.02s 0.00s sshd: test [priv]
用这个命令看看都有谁在线,有哪些用户访问过
3. 服务器的运行状态
$ uptime $ top $ htop $ free -m $ df -h
- 查看服务器最大的负载来自什么地方、 平均负载是多少
- 查看服务器还有空余的内存吗,是否正在内存和硬盘之间进行swap
- 查看还有剩余的CPU吗, 是否有某些CPU核负载过多了
- 查看服务器上磁盘是不是满了
4、服务器的进程
[root@localhost ~]# pstree -a [root@localhost ~]# ps aux [root@localhost ~]# htop
服务器在运行什么进程,php-fpm、nginx、cron等
5、系统日志和内核消息
[root@localhost ~]# dmesg | tail [root@localhost ~]# less /var/log/messages [root@localhost ~]# less /var/log/secure [root@localhost ~]# less /var/log/auth
- 查看系统信息,已经导致性能问题的错误信息。比如看看是不是很多关于连接数过多导致
- 看看是否有硬件错误或文件系统错误
- 分析是否能将这些错误事件和前面发现的疑点进行时间上的比对
6、网络连接和负载
[root@localhost ~]# ss
[root@localhost ~]# netstat -n | awk '/^tcp/ {++S[$NF]} END {for(a in S) print a, S[a]}'
[root@localhost ~]# netstat -antlp|grep 'ESTAB' | wc -l
[root@localhost ~]# netstat -antlp|grep 'ESTAB'|awk '{print $5}'|awk -F: '{print $1}'|sort |uniq -c|sort -rn -k 1
[root@localhost ~]# sar -n DEV 1 10
[root@localhost ~]# sar -n TCP,ETCP 1 10
[root@localhost ~]# netstat -nxlp
[root@localhost ~]# netstat -nulp
[root@localhost ~]# netstat -ntlp
这些命令基本上够了,ss响应速度比netstat快很多
查看各个监听端口,以及服务
查看 TIME_WAIT、CLOSE_WAIT等是否过多从而导致服务器运行缓慢,或者是不是服务器遭受到syn flood攻击
sar -n DEV 1 10 可以用于检查网络流量的工作负载:rxkB/s和txkB/s,以及它是否达到限额
sar -n TCP,ETCP 1 10 显示一些关键TCP指标的汇总。其中包括:
- active/s:本地每秒创建的TCP连接数(比如concept()创建的)
- passive/s:远程每秒创建的TCP连接数(比如accept()创建的)
- retrans/s:每秒TCP重传次数
- 主动连接数(active)和被动连接数(passive)通常可以用来粗略地描述系统负载。可以认为主动连接是对外的,而被动连接是对内的,虽然严格来说不完全是这个样子。(比如,一个从localhost到localhost的连接)
7、查看内存、CPU以及IO的使用情况
vmstat
$ vmstat 1 procs ---------memory---------- ---swap-- -----io---- -system-- ------cpu----- r b swpd free buff cache si so bi bo in cs us sy id wa st 34 0 0 200889792 73708 591828 0 0 0 5 6 10 96 1 3 0 0 32 0 0 200889920 73708 591860 0 0 0 592 13284 4282 98 1 1 0 0 32 0 0 200890112 73708 591860 0 0 0 0 9501 2154 99 1 0 0 0 32 0 0 200889568 73712 591856 0 0 0 48 11900 2459 99 0 0 0 0 32 0 0 200890208 73712 591860 0 0 0 0 15898 4840 98 1 1 0 0
虚拟内存原理
在系统中运行的每个进程都需要使用到内存,但不是每个进程都需要每时每刻使用系统分配的内存空间。当系统运行所需内存超过实际的物理内存,内核会释放某些进程所占用但未使用的部分或所有物理内存,将这部分资料存储在磁盘上直到进程下一次调用,并将释放出的内存提供给有需要的进程使用。
在Linux内存管理中,主要是通过“调页Paging”和“交换Swapping”来完成上述的内存调度。调页算法是将内存中最近不常使用的页面换到磁盘上,把活动页面保留在内存中供进程使用。交换技术是将整个进程,而不是部分页面,全部交换到磁盘上。
分页(Page)写入磁盘的过程被称作Page-Out,分页(Page)从磁盘重新回到内存的过程被称作Page-In。当内核需要一个分页时,但发现此分页不在物理内存中(因为已经被Page-Out了),此时就发生了分页错误(Page Fault)。
当系统内核发现可运行内存变少时,就会通过Page-Out来释放一部分物理内存。尽管Page-Out不是经常发生,但是如果Page-out频繁不断的发生,直到当内核管理分页的时间超过运行程式的时间时,系统效能会急剧下降。这时的系统已经运行非常慢或进入暂停状态,这种状态亦被称作thrashing(颠簸)
vmstat 的含义为虚拟内存状态(“Viryual Memor Statics”),但是它可以报告关于进程、内存、I/O等系统整体运行状态。
指定1作为vmstat的输入参数,它会输出每一秒内的统计结果
Procs(进程) r: 运行队列中进程数量,这个值也可以判断是否需要增加CPU。(长期大于1) b: 等待IO的进程数量。 Memory(内存) swpd: 使用虚拟内存大小,如果swpd的值不为0,但是SI,SO的值长期为0,这种情况不会影响系统性能。 free: 空闲物理内存大小。 buff: 用作缓冲的内存大小。 cache: 用作缓存的内存大小,如果cache的值大的时候,说明cache处的文件数多,如果频繁访问到的文件都能被cache处,那么磁盘的读IO bi会非常小。 Swap si: 每秒从交换区写到内存的大小,由磁盘调入内存。 so: 每秒写入交换区的内存大小,由内存调入磁盘。 注意:内存够用的时候,这2个值都是0,如果这2个值长期大于0时,系统性能会受到影响,磁盘IO和CPU资源都会被消耗。有些朋友看到空闲内存(free)很少的或接近于0时,就认为内存不够用了,不能光看这一点,还要结合si和so,如果free很少,但是si和so也很少(大多时候是0),那么不用担心,系统性能这时不会受到影响的。 IO(现在的Linux版本块的大小为1kb) bi: 每秒读取的块数 bo: 每秒写入的块数 注意:随机磁盘读写的时候,这2个值越大(如超出1024k),能看到CPU在IO等待的值也会越大。 system(系统) in: 每秒中断数,包括时钟中断。 cs: 每秒上下文切换数。 注意:上面2个值越大,会看到由内核消耗的CPU时间会越大。 CPU(以百分比表示) us: 用户进程执行时间百分比(user time),us的值比较高时,说明用户进程消耗的CPU时间多,但是如果长期超50%的使用,那么我们就该考虑优化程序算法或者进行加速。 sy: 内核系统进程执行时间百分比(system time) sy的值高时,说明系统内核消耗的CPU资源多,这并不是良性表现,我们应该检查原因。 wa: IO等待时间百分比,wa的值高时,说明IO等待比较严重,这可能由于磁盘大量作随机访问造成,也有可能磁盘出现瓶颈(块操作)。 id: 空闲时间百分比 st:被其它租户,或者是租户自己的Xen隔离设备驱动域(isolated driver domain),所占用的时间
通过相加us和sy的百分比,你可以确定CPU是否处于忙碌状态。一个持续不变的wait I/O意味着瓶颈在硬盘上,这种情况往往伴随着CPU的空闲,因为任务都卡在磁盘I/O上了。你可以把wait I/O当作CPU空闲的另一种形式,它额外给出了CPU空闲的线索。
I/O处理同样会消耗系统时间。一个高于20%的平均系统时间,往往值得进一步发掘:也许系统花在I/O的时太长了。
在上面的例子中,CPU基本把时间花在用户态里面,意味着跑在上面的应用占用了大部分时间。检查下“r”列,看看是否饱和了
mpstat -P ALL 1
$ mpstat -P ALL 1 Linux 3.13.0-49-generic (titanclusters-xxxxx) 07/14/2015 _x86_64_ (32 CPU) 07:38:49 PM CPU %usr %nice %sys %iowait %irq %soft %steal %guest %gnice %idle 07:38:50 PM all 98.47 0.00 0.75 0.00 0.00 0.00 0.00 0.00 0.00 0.78 07:38:50 PM 0 96.04 0.00 2.97 0.00 0.00 0.00 0.00 0.00 0.00 0.99 07:38:50 PM 1 97.00 0.00 1.00 0.00 0.00 0.00 0.00 0.00 0.00 2.00 07:38:50 PM 2 98.00 0.00 1.00 0.00 0.00 0.00 0.00 0.00 0.00 1.00 07:38:50 PM 3 96.97 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 3.03 [...]
- %user 在internal时间段里,用户态的CPU时间(%),不包含nice值为负进程 (usr/total)*100
- %nice 在internal时间段里,nice值为负进程的CPU时间(%) (nice/total)*100
- %sys 在internal时间段里,内核时间(%) (system/total)*100
- %iowait 在internal时间段里,硬盘IO等待时间(%) (iowait/total)*100
- %irq 在internal时间段里,硬中断时间(%) (irq/total)*100
- %soft 在internal时间段里,软中断时间(%) (softirq/total)*100
- %idle 在internal时间段里,CPU除去等待磁盘IO操作外的因为任何原因而空闲的时间闲置时间(%) (idle/total)*100
mpstat是Multiprocessor Statistics的缩写,是实时系统监控工具。其报告与CPU的一些统计信息,这些信息存放在/proc/stat文件中。在多CPUs系统里,其不但能查看所有CPU的平均状况信息,而且能够查看特定CPU的信息。
mpstat最大的特点是:可以查看多核心cpu中每个计算核心的统计数据;而类似工具vmstat只能查看系统整体cpu情况,还可以显示每个CPU的时间使用百分比,你可以用它来检查CPU是否存在负载不均衡。单个过于忙碌的CPU可能意味着整个应用只有单个线程在工作。
pidstat 1
$ pidstat 1 Linux 3.13.0-49-generic (titanclusters-xxxxx) 07/14/2015 _x86_64_ (32 CPU) 07:41:02 PM UID PID %usr %system %guest %CPU CPU Command 07:41:03 PM 0 9 0.00 0.94 0.00 0.94 1 rcuos/0 07:41:03 PM 0 4214 5.66 5.66 0.00 11.32 15 mesos-slave 07:41:03 PM 0 4354 0.94 0.94 0.00 1.89 8 java 07:41:03 PM 0 6521 1596.23 1.89 0.00 1598.11 27 java 07:41:03 PM 0 6564 1571.70 7.55 0.00 1579.25 28 java 07:41:03 PM 60004 60154 0.94 4.72 0.00 5.66 9 pidstat 07:41:03 PM UID PID %usr %system %guest %CPU CPU Command 07:41:04 PM 0 4214 6.00 2.00 0.00 8.00 15 mesos-slave 07:41:04 PM 0 6521 1590.00 1.00 0.00 1591.00 27 java 07:41:04 PM 0 6564 1573.00 10.00 0.00 1583.00 28 java 07:41:04 PM 108 6718 1.00 0.00 0.00 1.00 0 snmp-pass 07:41:04 PM 60004 60154 1.00 4.00 0.00 5.00 9 pidstat
pidstat主要用于监控全部或指定进程占用系统资源的情况,如CPU,内存、设备IO、任务切换、线程等。pidstat首次运行时显示自系统启动开始的各项统计信息,之后运行pidstat将显示自上次运行该命令以后的统计信息。用户可以通过指定统计的次数和时间来获得所需的统计信息
上面的例子表明,CPU主要消耗在两个java进程上。%CPU列是在各个CPU上的使用量的总和;1591%意味着java进程消耗了将近16个CPU
比如常用的pidstat命令
pidstat -u 1 //cpu pidstat -r 1 //mem pidstat -d 1 //io
以上命令以1秒为信息采集周期,分别获取cpu、内存和磁盘IO的统计信息
iostat -xz 1
$ iostat -xz 1
Linux 3.13.0-49-generic (titanclusters-xxxxx) 07/14/2015 _x86_64_ (32 CPU)
avg-cpu: %user %nice %system %iowait %steal %idle
73.96 0.00 3.73 0.03 0.06 22.21
Device: rrqm/s wrqm/s r/s w/s rkB/s wkB/s avgrq-sz avgqu-sz await r_await w_await svctm %util
xvda 0.00 0.23 0.21 0.18 4.52 2.08 34.37 0.00 9.98 13.80 5.42 2.44 0.09
xvdb 0.01 0.00 1.02 8.94 127.97 598.53 145.79 0.00 0.43 1.78 0.28 0.25 0.25
xvdc 0.01 0.00 1.02 8.86 127.79 595.94 146.50 0.00 0.45 1.82 0.30 0.27 0.26
dm-0 0.00 0.00 0.69 2.32 10.47 31.69 28.01 0.01 3.23 0.71 3.98 0.13 0.04
dm-1 0.00 0.00 0.00 0.94 0.01 3.78 8.00 0.33 345.84 0.04 346.81 0.01 0.00
dm-2 0.00 0.00 0.09 0.07 1.35 0.36 22.50 0.00 2.55 0.23 5.62 1.78 0.03
[...]
这个命令可以弄清块设备(磁盘)的状况,包括工作负载和处理性能。注意以下各项:
- r/s,w/s,rkB/s,wkB/s:分别表示每秒设备读次数,写次数,读的KB数,写的KB数。它们描述了磁盘的工作负载。也许性能问题就是由过高的负载所造成的。
- await:I/O平均时间,以毫秒作单位。它是应用中I/O处理所实际消耗的时间,因为其中既包括排队用时也包括处理用时。如果它比预期的大,就意味着设备饱和了,或者设备出了问题。
- avgqu-sz:分配给设备的平均请求数。大于1表示设备已经饱和了。(不过有些设备可以并行处理请求,比如由多个磁盘组成的虚拟设备)
- %util:设备使用率。这个值显示了设备每秒内工作时间的百分比,一般都处于高位。低于60%通常是低性能的表现(也可以从await中看出),不过这个得看设备的类型。接近100%通常意味着饱和。
如果某个存储设备是由多个物理磁盘组成的逻辑磁盘设备,100%的使用率可能只是意味着I/O占用
请牢记于心,disk I/O性能低不一定是个问题。应用的I/O往往是异步的(比如预读(read-ahead)和写缓冲(buffering for writes)),所以不一定会被阻塞并遭受延迟。
free -m
$ free -m
total used free shared buffers cached
Mem: 245998 24545 221453 83 59 541
-/+ buffers/cache: 23944 222053
Swap: 0 0 0
- buffers:用于块设备I/O的缓冲区缓存
- cached:用于文件系统的页缓存
它们的值接近于0时,往往导致较高的磁盘I/O(可以通过iostat确认)和糟糕的性能。上面的例子里没有这个问题,每一列都有好几M呢。
比起第一行,-/+ buffers/cache提供的内存使用量会更加准确些。Linux会把暂时用不上的内存用作缓存,一旦应用需要的时候立刻重新分配给它。所以部分被用作缓存的内存其实也算是空闲内存,第二行以此修订了实际的内存使用量
如果你在Linux上安装了ZFS,正如我们在一些服务上所做的,这一点会变得更加迷惑,因为ZFS它自己的文件系统缓存不算入free -m。有时系统看上去已经没有多少空闲内存可用了,其实内存都待在ZFS的缓存里呢。
lsof -a -u root -d txt
lsof 是 linux 下的一个非常实用的系统级的监控、诊断工具。它的意思是 List Open Files,很容易你就记住了它是 “ls + of”的组合~它可以用来列出被各种进程打开的文件信息,记住:linux 下 “一切皆文件”,包括但不限于 pipes, sockets, directories, devices, 等等。因此,使用 lsof,你可以获取任何被打开文件的各种信息。只需输入 lsof 就可以生成大量的信息,因为 lsof 需要访问核心内存和各种文件,所以必须以 root 用户的身份运行它才能够充分地发挥其功能
[root@localhost ~]# lsof -u www -c nginx COMMAND PID USER FD TYPE DEVICE SIZE/OFF NODE NAME nginx 7407 root cwd DIR 202,1 4096 128 / nginx 7407 root rtd DIR 202,1 4096 128 / nginx 7407 root txt REG 202,1 6694801 100963532 /usr/sbin/nginx nginx 7407 root DEL REG 0,4 1142022948 /dev/zero nginx 7407 root DEL REG 0,4 1142022946 /dev/zero nginx 7407 root DEL REG 0,4 1142022945 /dev/zero nginx 7407 root DEL REG 0,4 1142022944 /dev/zero nginx 7407 root mem REG 202,1 65928 67516073 /lib64/libnss_files-2.12.so nginx 7407 root mem REG 202,1 10856 67240493 /usr/lib64/libXau.so.6.0.0 nginx 7407 root mem REG 202,1 122040 67516740 /lib64/libselinux.so.1 nginx 7407 root mem REG 202,1 165264 67516922 /lib64/libexpat.so.1.5.2 nginx 7407 root mem REG 202,1 122520 67251486 /usr/lib64/libxcb.so.1.1.0 nginx 7407 root mem REG 202,1 110960 67516085 /lib64/libresolv-2.12.so nginx 7407 root mem REG 202,1 10192 67295653 /lib64/libkeyutils.so.1.3 nginx 7407 root mem REG 202,1 43728 67516910 /lib64/libkrb5support.so.0.1 nginx 7407 root mem REG 202,1 90880 67151447 /lib64/libgcc_s-4.4.7-20120601.so.1 nginx 7407 root mem REG 202,1 987096 67239461 /usr/lib64/libstdc++.so.6.0.13 nginx 7407 root mem REG 202,1 375687 559315 /usr/local/lib/libunwind.so.8.0.1 nginx 7407 root mem REG 202,1 596272 67516143 /lib64/libm-2.12.so nginx 7407 root mem REG 202,1 155456 67240447 /usr/lib64/libpng12.so.0.49.0 nginx 7407 root mem REG 202,1 642600 67231558 /usr/lib64/libfreetype.so.6.3.22 nginx 7407 root mem REG 202,1 220584 67236392 /usr/lib64/libfontconfig.so.1.4.4 nginx 7407 root mem REG 202,1 262896 67239380 /usr/lib64/libjpeg.so.62.0.0 nginx 7407 root mem REG 202,1 1297928 67150496 /usr/lib64/libX11.so.6.3.0 nginx 7407 root mem REG 202,1 70320 67150499 /usr/lib64/libXpm.so.4.11.0 nginx 7407 root mem REG 202,1 174840 67295675 /lib64/libk5crypto.so.3.1 nginx 7407 root mem REG 202,1 14664 67226162 /lib64/libcom_err.so.2.1 nginx 7407 root mem REG 202,1 941920 67516681 /lib64/libkrb5.so.3.3 nginx 7407 root mem REG 202,1 277704 67516675 /lib64/libgssapi_krb5.so.2.2 nginx 7407 root mem REG 202,1 469528 67226123 /lib64/libfreebl3.so nginx 7407 root mem REG 202,1 1920936 67516136 /lib64/libc-2.12.so nginx 7407 root mem REG 202,1 289777 459327 /usr/local/lib/libprofiler.so.0.3.0 nginx 7407 root mem REG 202,1 898748 1724697 /usr/local/lib/libGeoIP.so.1.4.6 nginx 7407 root mem REG 202,1 272552 67150501 /usr/lib64/libgd.so.2.0.0 nginx 7407 root mem REG 202,1 88600 67226134 /lib64/libz.so.1.2.3 nginx 7407 root mem REG 202,1 1950976 67244040 /usr/lib64/libcrypto.so.1.0.1e nginx 7407 root mem REG 202,1 441112 67244042 /usr/lib64/libssl.so.1.0.1e nginx 7407 root mem REG 202,1 181432 67516701 /lib64/libpcre.so.0.0.1 nginx 7407 root mem REG 202,1 40400 67516139 /lib64/libcrypt-2.12.so nginx 7407 root mem REG 202,1 19536 67516141 /lib64/libdl-2.12.so nginx 7407 root mem REG 202,1 142640 67516083 /lib64/libpthread-2.12.so nginx 7407 root mem REG 202,1 154664 67516128 /lib64/ld-2.12.so nginx 7407 root 0u CHR 1,3 0t0 3866 /dev/null nginx 7407 root 1u CHR 1,3 0t0 3866 /dev/null nginx 7407 root 2w REG 202,1 748837066 33826169 /usr/local/nginx/logs/error.log
查看设备打开的文件
[root@localhost ~]# lsof /dev/xvdb1 COMMAND PID USER FD TYPE DEVICE SIZE/OFF NODE NAME php-fpm 7222 root 2w REG 202,17 161403107 262180 /data/logs/error/php-fpm-error.log php-fpm 7222 root 3w REG 202,17 161403107 262180 /data/logs/error/php-fpm-error.log nginx 7407 root 6w REG 202,17 0 262256 /data/logs/error/app.test.com_error.log nginx 8011 www 49r REG 202,17 3762 3166039 /data/www/www.test.com/Common/js/new_header.js nginx 8011 www 50r REG 202,17 33915 2763270 /data/www/bbs.test.com/static/js/home.js nginx 8011 www 51r REG 202,17 8345 3147082 /data/www/www.test.com/Common/js/raty/jquery.raty.min.js nginx 8011 www 53u REG 202,17 4119 2383851 /data/www/bbs.test.com/404.html nginx 8011 www 54r REG 202,17 12030 3146240 /data/www/www.test.com/Common/js/iframeTools.source.js nginx 8011 www 56u REG 202,17 603 2763375 /data/www/bbs.test.com/static/js/logging.js nginx 8011 www 67r REG 202,17 139 2490917 /data/www/www.test.com/index.php nginx 8012 www 4w REG 202,17 350277 262242 /data/logs/access/app.test.com_access.log nginx 8012 www 6w REG 202,17 0 262256 /data/logs/error/app.test.com_error.log nginx 8012 www 7w REG 202,17 5067450 267977 /data/logs/access/bbs.test.com_access.log nginx 8012 www 8w REG 202,17 55522 262497 /data/logs/error/bbs.test.com_error.log nginx 8012 www 10w REG 202,17 0 267978 /data/logs/access/edu.test.com_access.log nginx 8012 www 11w REG 202,17 2480 262277 /data/logs/error/edu.test.com_error.log nginx 8012 www 12w REG 202,17 4634491 267979 /data/logs/access/www.test.com_access.log nginx 8012 www 13w REG 202,17 63323232 262257 /data/logs/error/www.test.com_error.log nginx 8012 www 15w REG 202,17 718 267980 /data/logs/access/tyb.test.com_access.log nginx 8012 www 17w REG 202,17 0 262258 /data/logs/error/tyb.test.com_error.log nginx 8012 www 25w REG 202,17 0 2386258 /data/www/tmp/tcmalloc.8012 php-fpm 18179 www cwd DIR 202,17 4096 2400257 /data/www/bbs.test.com bash 18367 root 255r REG 202,17 1303 2097160 /data/scripts/backup.sh php-fpm 18406 www cwd DIR 202,17 4096 2400257 /data/www/bbs.test.com gzip 18445 root 1w REG 202,17 0 10485795 /data/backup/db/rbc/rbc2014_test_2015_12_12_00.sql.gz
8、定时任务
[root@localhost ~]# ls /etc/cron* [root@localhost ~]# for user in $(cat /etc/passwd | cut -f1 -d:); do crontab -l -u $user; done
- 是否有某个定时任务运行过于频繁?
- 是否有些用户提交了隐藏的定时任务?
- 在出现故障的时候,是否正好有某个备份任务在执行?
9、内核、中断
[root@localhost ~]# sysctl -a | grep [root@localhost ~]# cat /proc/interrupts [root@localhost ~]# cat /proc/net/ip_conntrack
- 你的中断请求是否是均衡地分配给CPU处理,还是会有某个CPU的核因为大量的网络中断请求或者RAID请求而过载了?
- SWAP交换的设置是什么?对于工作站来说swappinness 设为 60 就很好, 不过对于服务器就太糟了:你最好永远不要让服务器做SWAP交换,不然对磁盘的读写会锁死SWAP进程。
- conntrack_max 是否设的足够大,能应付你服务器的流量?
- 在不同状态下(TIME_WAIT, …)TCP连接时间的设置是怎样的?
- 如果要显示所有存在的连接,netstat 会比较慢, 你可以先用 ss 看一下总体情况。
10、系统挂载
[root@localhost ~]# mount [root@localhost ~]# cat /etc/fstab [root@localhost ~]# df -h [root@localhost ~]# lsof +D /data/test
- 一共挂载了多少文件系统?
- 有没有某个服务专用的文件系统? (比如MySQL?)
- 文件系统的挂载选项是什么: noatime? default? 有没有文件系统被重新挂载为只读模式了?
- 磁盘空间是否还有剩余?
- 是否有大文件被删除但没有清空?
- 如果磁盘空间有问题,你是否还有空间来扩展一个分区?
11、应用系统日志
这里边可分析的东西就多了, 不过恐怕你作为运维人员是没功夫去仔细研究它的。关注那些明显的问题,比如在一个典型的LAMP(Linux+Apache+Mysql+Perl)应用环境里:
- Apache & Nginx; 查找访问和错误日志, 直接找 5xx 错误, 再看看是否有 limit_zone 错误。
- MySQL; 在mysql.log找错误消息,看看有没有结构损坏的表, 是否有innodb修复进程在运行,是否有disk/index/query 问题.
- PHP-FPM; 如果设定了 php-slow 日志, 直接找错误信息 (php, mysql, memcache, …),如果没设定,赶紧设定。
- Varnish; 在varnishlog 和 varnishstat 里, 检查 hit/miss比. 看看配置信息里是否遗漏了什么规则,使最终用户可以直接攻击你的后端?
- HA-Proxy; 后端的状况如何?健康状况检查是否成功?是前端还是后端的队列大小达到最大值了?
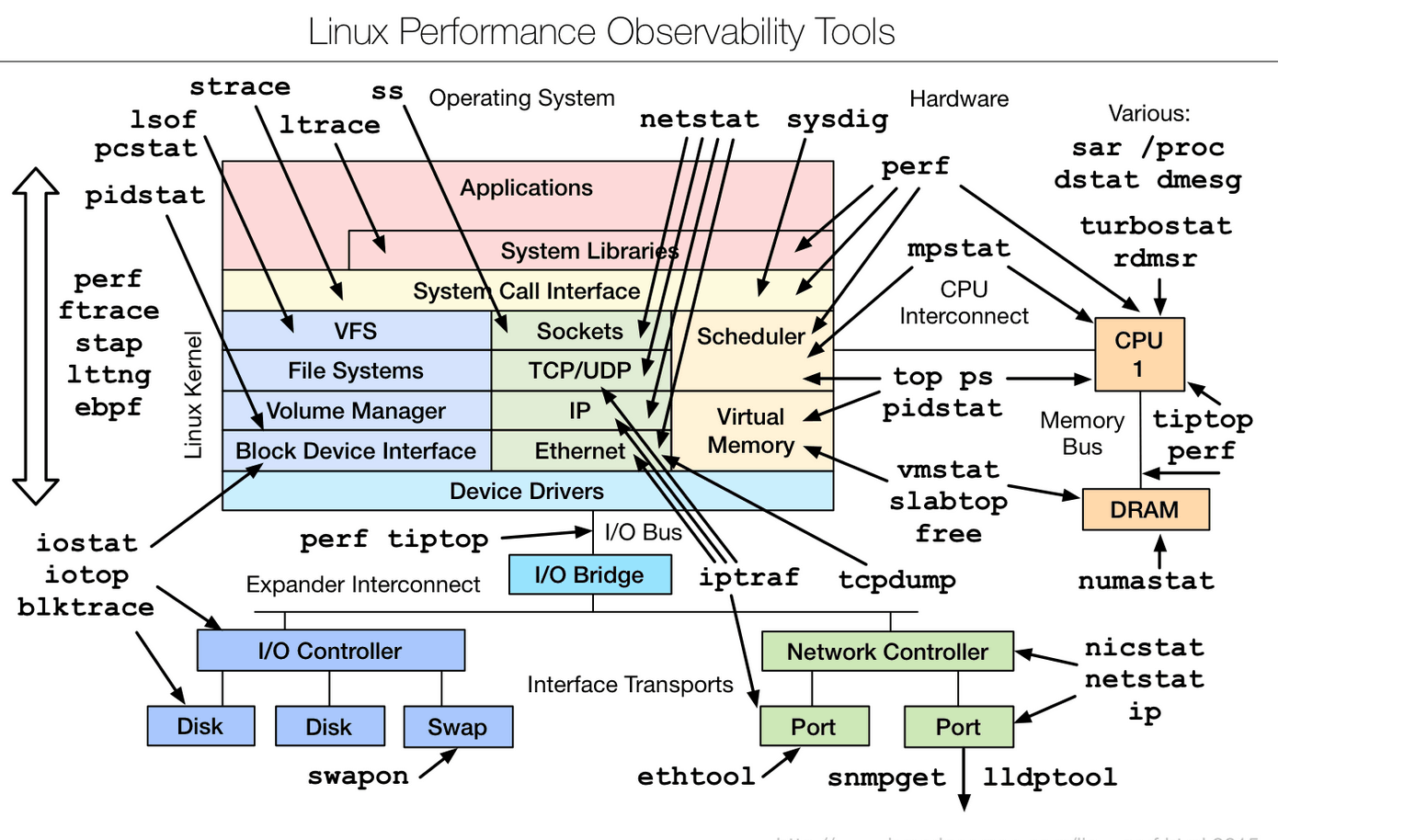
分享一张来自网络上的图片
参考文章
https://github.com/spacewander/blogWithMarkdown/issues/36
http://www.cnetsec.com/article/12858.html
https://www.ibm.com/developerworks/cn/linux/l-cn-perf1/
http://techblog.netflix.com/2015/11/linux-performance-analysis-in-60s.html
- 作者:踏雪无痕
- 出处:http://www.cnblogs.com/chenpingzhao/
- 本文版权归作者和博客园共有,如需转载,请联系 pingzhao1990#163.com

 浙公网安备 33010602011771号
浙公网安备 33010602011771号