GoLang之协程
GoLang之协程
目前,WebServer几种主流的并发模型:
- 多线程,每个线程一次处理一个请求,在当前请求处理完成之前不会接收其它请求;但在高并发环境下,多线程的开销比较大;
- 基于回调的异步IO,如Nginx服务器使用的epoll模型,这种模式通过事件驱动的方式使用异步IO,使服务器持续运转,但人的思维模式是串行的,大量回调函数会把流程分割,对于问题本身的反应不够自然;
- 协程,不需要抢占式调度,可以有效提高线程的任务并发性,而避免多线程的缺点;但原生支持协程的语言还很少。
协程(coroutine)是Go语言中的轻量级线程实现,由Go运行时(runtime)管理。
在一个函数调用前加上go关键字,这次调用就会在一个新的goroutine中并发执行。当被调用的函数返回时,这个goroutine也自动结束。需要注意的是,如果这个函数有返回值,那么这个返回值会被丢弃。
先看下面的例子:
func Add(x, y int) { z := x + y fmt.Println(z) } func main() { for i:=0; i<10; i++ { go Add(i, i) } }
执行上面的代码,会发现屏幕什么也没打印出来,程序就退出了。
对于上面的例子,main()函数启动了10个goroutine,然后返回,这时程序就退出了,而被启动的执行Add()的goroutine没来得及执行。我们想要让main()函数等待所有goroutine退出后再返回,但如何知道goroutine都退出了呢?这就引出了多个goroutine之间通信的问题。
在工程上,有两种最常见的并发通信模型:共享内存和消息。
来看下面的例子,10个goroutine共享了变量counter,每个goroutine执行完成后,将counter值加1.因为10个goroutine是并发执行的,所以我们还引入了锁,也就是代码中的lock变量。在main()函数中,使用for循环来不断检查counter值,当其值达到10时,说明所有goroutine都执行完毕了,这时main()返回,程序退出。
package main import ( "fmt" "sync" "runtime" ) var counter int = 0 func Count(lock *sync.Mutex) { lock.Lock() counter++ fmt.Println("counter =", counter) lock.Unlock() } func main() { lock := &sync.Mutex{} for i:=0; i<10; i++ { go Count(lock) } for { lock.Lock() c := counter lock.Unlock() runtime.Gosched() // 出让时间片 if c >= 10 { break } } }
上面的例子,使用了锁变量(属于一种共享内存)来同步协程,事实上Go语言主要使用消息机制(channel)来作为通信模型。
channel
消息机制认为每个并发单元是自包含的、独立的个体,并且都有自己的变量,但在不同并发单元间这些变量不共享。每个并发单元的输入和输出只有一种,那就是消息。
channel是Go语言在语言级别提供的goroutine间的通信方式,我们可以使用channel在多个goroutine之间传递消息。channel是进程内的通信方式,因此通过channel传递对象的过程和调用函数时的参数传递行为比较一致,比如也可以传递指针等。
channel是类型相关的,一个channel只能传递一种类型的值,这个类型需要在声明channel时指定。
channel的声明形式为:
var chanName chan ElementType
举个例子,声明一个传递int类型的channel:
var ch chan int
使用内置函数make()定义一个channel:
ch := make(chan int)
在channel的用法中,最常见的包括写入和读出:
// 将一个数据value写入至channel,这会导致阻塞,直到有其他goroutine从这个channel中读取数据 ch <- value // 从channel中读取数据,如果channel之前没有写入数据,也会导致阻塞,直到channel中被写入数据为止 value := <-ch
默认情况下,channel的接收和发送都是阻塞的,除非另一端已准备好。
我们还可以创建一个带缓冲的channel:
c := make(chan int, 1024) // 从带缓冲的channel中读数据 for i:=range c { ... }
此时,创建一个大小为1024的int类型的channel,即使没有读取方,写入方也可以一直往channel里写入,在缓冲区被填完之前都不会阻塞。
可以关闭不再使用的channel:
close(ch)
应该在生产者的地方关闭channel,如果在消费者的地方关闭,容易引起panic;
在一个已关闭 channel 上执行接收操作(<-ch)总是能够立即返回,返回值是对应类型的零值。
现在利用channel来重写上面的例子:
func Count(ch chan int) { ch <- 1 fmt.Println("Counting") } func main() { chs := make([] chan int, 10) for i:=0; i<10; i++ { chs[i] = make(chan int) go Count(chs[i]) } for _, ch := range(chs) { <-ch } }
在这个例子中,定义了一个包含10个channel的数组,并把数组中的每个channel分配给10个不同的goroutine。在每个goroutine完成后,向goroutine写入一个数据,在这个channel被读取前,这个操作是阻塞的。在所有的goroutine启动完成后,依次从10个channel中读取数据,在对应的channel写入数据前,这个操作也是阻塞的。这样,就用channel实现了类似锁的功能,并保证了所有goroutine完成后main()才返回。
另外,我们在将一个channel变量传递到一个函数时,可以通过将其指定为单向channel变量,从而限制该函数中可以对此channel的操作。
单向channel变量的声明:
var ch1 chan int // 普通channel var ch2 chan <- int // 只用于写int数据 var ch3 <-chan int // 只用于读int数据
可以通过类型转换,将一个channel转换为单向的:
ch4 := make(chan int) ch5 := <-chan int(ch4) // 单向读 ch6 := chan<- int(ch4) //单向写
单向channel的作用有点类似于c++中的const关键字,用于遵循代码“最小权限原则”。
例如在一个函数中使用单向读channel:
func Parse(ch <-chan int) { for value := range ch { fmt.Println("Parsing value", value) } }
channel作为一种原生类型,本身也可以通过channel进行传递,例如下面这个流式处理结构:
type PipeData struct { value int handler func(int) int next chan int } func handle(queue chan *PipeData) { for data := range queue { data.next <- data.handler(data.value) } }
select
在UNIX中,select()函数用来监控一组描述符,该机制常被用于实现高并发的socket服务器程序。Go语言直接在语言级别支持select关键字,用于处理异步IO问题,大致结构如下:
select { case <- chan1: // 如果chan1成功读到数据 case chan2 <- 1: // 如果成功向chan2写入数据 default: // 默认分支 }
select默认是阻塞的,只有当监听的channel中有发送或接收可以进行时才会运行,当多个channel都准备好的时候,select是随机的选择一个执行的。
Go语言没有对channel提供直接的超时处理机制,但我们可以利用select来间接实现,例如:
timeout := make(chan bool, 1) go func() { time.Sleep(1e9) timeout <- true }() switch { case <- ch: // 从ch中读取到数据 case <- timeout: // 没有从ch中读取到数据,但从timeout中读取到了数据 }
这样使用select就可以避免永久等待的问题,因为程序会在timeout中获取到一个数据后继续执行,而无论对ch的读取是否还处于等待状态。
并发
早期版本的Go编译器并不能很智能的发现和利用多核的优势,即使在我们的代码中创建了多个goroutine,但实际上所有这些goroutine都允许在同一个CPU上,在一个goroutine得到时间片执行的时候其它goroutine都会处于等待状态。
实现下面的代码可以显式指定编译器将goroutine调度到多个CPU上运行。
import "runtime"
...
runtime.GOMAXPROCS(4)
PS:runtime包中有几个处理goroutine的函数,
|
函数 |
说明 |
|
Goexit |
退出当前执行的goroutine,但是defer函数还会继续调用 |
|
Gosched |
让出当前goroutine的执行权限,调度器安排其他等待的任务运行,并在下次某个时候从该位置恢复执行 |
|
NumCPU |
返回 CPU 核数量 |
|
NumGoroutine |
返回正在执行和排队的任务总数 |
|
GOMAXPROCS |
用来设置可以并行计算的CPU核数的最大值,并返回之前的值 |
调度
Go调度的几个概念:
M:内核线程;
G:go routine,并发的最小逻辑单元,由程序员创建;
P:处理器,执行G的上下文环境,每个P会维护一个本地的go routine队列;
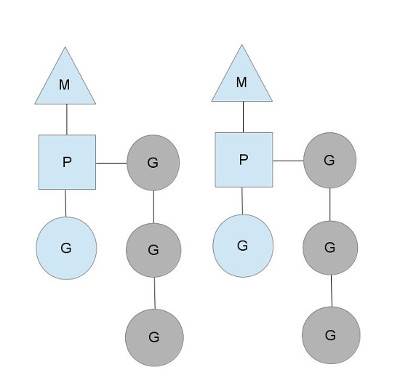
除了每个P拥有一个本地的go routine队列外,还存在一个全局的go routine队列。
具体调度原理:
- P的数量在初始化由GOMAXPROCS决定;
- 我们要做的就是添加G;
- G的数量超出了M的处理能力,且还有空余P的话,runtime就会自动创建新的M;
- M拿到P后才能干活,取G的顺序:本地队列>全局队列>其他P的队列,如果所有队列都没有可用的G,M会归还P并进入休眠;
一个G如果发生阻塞等事件会进行阻塞,如下图:
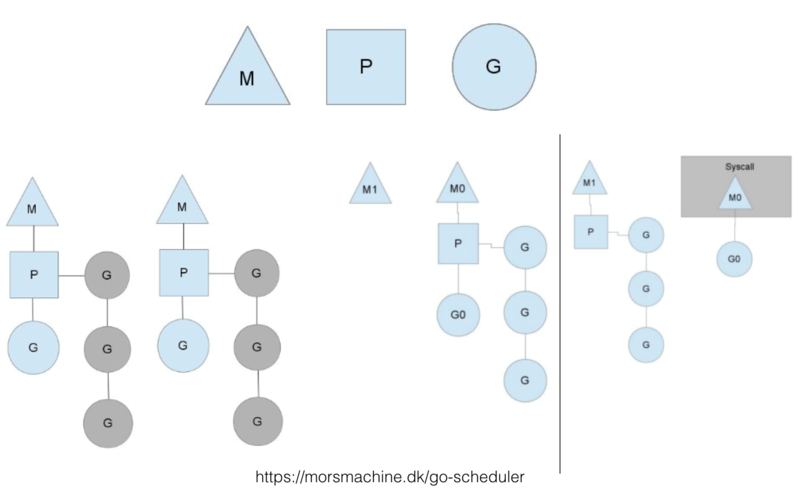
G发生上下文切换条件:
- 系统调用;
- 读写channel;
- gosched主动放弃,会将G扔进全局队列;
如上图,一个G发生阻塞时,M0让出P,由M1接管其任务队列;当M0执行的阻塞调用返回后,再将G0扔到全局队列,自己则进入睡眠(没有P了无法干活);

 浙公网安备 33010602011771号
浙公网安备 33010602011771号