原子操作与内存屏障之三——内存屏障
内存屏障
首先需要明确的是,程序在运行起来,内存访问的顺序和程序员编写的顺序不一定一致,编译器和CPU都可能对代码优化导致乱序执行。
编译器乱序
编译器会做非常多的优化,指令重排序是其中一种,如下例
int a, b; void foo(void) { a = b + 1; b = 0; }
执行编译命令
gcc -c -S test.c
编译器生成的结果如下:
movl b(%rip), %eax addl $1, %eax movl %eax, a(%rip) movl $0, b(%rip)
先对a赋值,再对b赋值,和C源码顺序一致。
如果加上-O2,结果如下
movl b(%rip), %eax movl $0, b(%rip) addl $1, %eax movl %eax, a(%rip)
实际执行就变成了先对b赋值,再对a赋值,这就是compiler reordering(编译器重排)。为什么可以这么做呢?对于单线程来说,a 和 b 的写入顺序,compiler认为没有任何问题。并且最终的结果也是正确的(a == 1 && b == 0),因此编译器才会这么做。
再看一个例子,我们拥有2个线程,一个用来更新数据,另一个读数据,读线程等待flag被置位,然后返回读取的数据data
// global variables int flag, data; // thread1 void write_data(int value) { data = value; flag = 1; } // thread2 void read_data(void) {while (flag == 0);return data; }
如果compiler产生的汇编代码是 flag 比 data先写入内存,read_data()发现flag已经置1,错误认为data的数据已经准别就绪。
这是因为compiler是不知道data和flag之间有严格的依赖关系。为了解决上述变量之间存在依赖关系导致compiler错误优化,compiler为我们提供了编译器屏障(compiler barriers),可用来告诉compiler不要reorder。我们继续使用上面的foo()函数作为演示实验,在代码之间插入compiler barriers:
#define barrier() __asm__ __volatile__("": : :"memory") int a, b; void foo(void) { a = b + 1; barrier(); b = 0; }
此时,生成的汇编如下
movl b(%rip), %eax addl $1, %eax movl %eax, a(%rip) movl $0, b(%rip)
barrier()就是compiler提供的屏障,作用是告诉compiler内存中的值已经改变,之前对内存的缓存(缓存到寄存器)都需要抛弃,barrier()之后的内存操作需要重新从内存load,而不能使用之前寄存器缓存的值。并且可以防止compiler优化barrier()前后的内存访问顺序。barrier()就像是代码中的一道不可逾越的屏障,barrier前的 load/store 操作不能跑到barrier后面;同样,barrier后面的 load/store 操作不能在barrier之前。
除了显式调用barrier()外,还有别的方法阻止compiler reordering。实际上,大多数的函数调用都表现出compiler barriers的作用,例如
int a, b; void foo(void) { a = b + 1; printf("hello\n"); b = 0; }
加上-O2编译的汇编结果
movl b(%rip), %eax movl $.LC0, %edi addl $1, %eax movl %eax, a(%rip) call puts movl $0, b(%rip)
compiler不能假设printf()不会使用或者修改 a 变量。因此在调用printf()之前会将 a 赋值,以保证printf()可能会用到新值。
注意,inline函数不具有compiler barriers的作用,当我们需要考虑compiler barriers时,一定要显示的插入barrier(),而不是依靠函数调用附加的隐式compiler barriers。因为,谁也无法保证调用的函数不会被compiler优化成inline方式。
再看一个例子
#include <stdlib.h> #include <stdio.h> #include <pthread.h> #include <unistd.h> int run = 1; void* foo(void* data) { while (run) ; } void* bar(void* data) { sleep(1); run = 0; } void test1() { printf("test1 ready\n"); pthread_t pt[2]; pthread_create(&pt[0], NULL, foo, NULL); pthread_create(&pt[1], NULL, bar, NULL); pthread_join(pt[0], NULL); pthread_join(pt[1], NULL); printf("test1 done\n"); } int main() { test1(); }
如果不使用编译优化选项,运行是ok的,如果加上 -O2,foo() 函数会进入死循环,compiler首先将run加载到一个寄存器reg中,即使即使其他线程修改run的值为0,它也不会重新加载。
加上barrier()可以解决这个问题
#define barrier() __asm__ __volatile__("": : :"memory") int run = 1; void* foo(void* data) { while (run) barrier(); }
当然,通过volatile也可以解决
volatile int run = 1; void* foo(void* data) { while (run) ; }
CPU乱序
现在的CPU一般采用流水线(pipeline) 来执行指令 ,一条指令的执行被分成:取指(Fetch)、译码(Decode)、访存、执行(Execute)、写回(Write-back)、等若干个阶段。
指令流水线并不是串行的,多条指令可以同时存在于流水线中,同时被执行。并不会因为一个耗时很长的指令在“执行”阶段呆很长时间,而导致后续的指令都卡在“执行”之前的阶段上。
比如说CPU有一个加法器和一个除法器,那么一条加法指令和一条除法指令就可能同时处于“执行”阶段,而两条加法指令在“执行”阶段就只能串行工作。然而,这样一来,乱序可能就产生了。比如一条加法指令原本出现在一条除法指令的后面,但是由于除法的执行时间很长,在它执行完之前,加法可能先执行完了。再比如两条访存指令,可能由于第二条指令命中了cache而导致它先于第一条指令完成。
一般情况下,指令乱序并不是CPU在执行指令之前刻意去调整顺序。CPU总是顺序的去内存里面取指令,然后将其顺序的放入指令流水线。但是指令执行时的各种条件,指令与指令之间的相互影响,可能导致顺序放入流水线的指令,最终乱序执行完成。这就是所谓的“顺序流入,乱序流出”。
另外,CPU的乱序执行并不是任意的乱序,比如:
a++; b=a+1; c--;
由于b=a+1依赖于前一条指令a++的执行结果,所以b=a+1将在“执行”阶段之前被阻塞,直到a++的执行结果被生成出来;而c--跟前面没有依赖,它可能在b=a+1之前就能执行完。
像这样有依赖关系的指令如果挨得很近,后一条指令必定会因为等待前一条执行的结果,而在流水线中阻塞很久,占用流水线的资源。
而编译器的乱序,作为编译优化的一种手段,则试图通过指令重排将这样的两条指令拉开距离, 以至于后一条指令进入CPU的时候,前一条指令结果已经得到了,那么也就不再需要阻塞等待了。比如将指令重排为:
a++; c--; b=a+1;
分支预测
先看个例子,用256的模数随机填充一个固定大小的大数组,然后统计该数组中值不小于128的元素个数,循环1w次
void test2(int sort) { const unsigned arraySize = 32768; int* data = malloc(sizeof(int) * arraySize); for (unsigned c = 0; c < arraySize; ++c) data[c] = rand() % 256; if (sort) qsort(data, arraySize, sizeof(int), comp); /* for (unsigned c = 0; c < arraySize; ++c) { printf("%d\t", data[c]); } printf("\n"); */ // loop begin clock_t start = clock(); long long sum = 0; for (unsigned i = 0; i < 10000; ++i) { for (unsigned c = 0; c < arraySize; ++c) { if (data[c] >= 128) sum ++; } } double elapsedTime = (double)(clock() - start) / CLOCKS_PER_SEC; // loop end free(data); printf("sort=%d, elapsedTime=%.3f seconds\n", sort, elapsedTime); } test2(0); test2(1);
运行结果:
sort=0, elapsedTime=2.434 seconds
sort=1, elapsedTime=0.680 seconds
我们比较数组在有序和无序的耗时对比,可以发现对有序数组的执行时间要比无序数组快4倍,从循环本身来看,遍历次数应该是一样的,这是为什么呢?
在CPU遇到 if (data[c] >= 128) sum ++; 这条命令时,并不能决定该如何往下走,该如何做?只能暂停运行,等待之前的指令运行结束。然后才能继续沿着正确地路径往下走。
要知道,现代编译器是非常复杂的,运行时有着非常长的pipelines, 减速和热启动将耗费巨量的时间。那么,有没有好的办法可以节省这些状态切换的时间呢?你可以猜测分支的下一步走向!
-
如果猜错了,处理器要flush掉pipelines, 回滚到之前的分支,然后重新热启动,选择另一条路径。
-
如果猜对了,处理器不需要暂停,继续往下执行。
如果每次都猜错了,处理器将耗费大量时间在停止-回滚-热启动这一周期性过程里。如果侥幸每次都猜对了,那么处理器将从不暂停,一直运行至结束。
上述过程就是分支预测(branch prediction),那么处理器该采用怎样的策略来用最小的次数来尽量猜对指令分支的下一步走向呢?答案就是分析历史运行记录,这样的持续朝同一个方向切换的迭代对分支预测器来说是非常友好的。
乱序执行
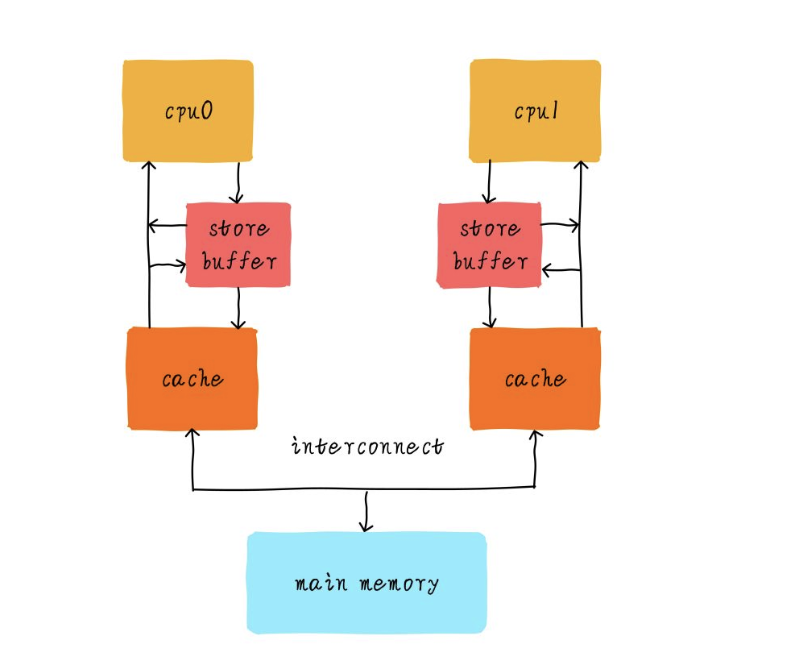
从前面的 CPU缓存 看,每个CPU都会有自己私有L1 Cache,硬件工程师为了追求极致的性能,在CPU和L1 Cache之间又加入一级缓存,我们称之为store buffer。store buffer和L1 Cache还有点区别,store buffer只缓存CPU的写操作。store buffer访问一般只需要1个指令周期,这在一定程度上降低了内存写延迟。不管cache是否命中,CPU都是将数据写入store buffer,store buffer大小一般只有几十个字节。store buffer负责后续以FIFO次序写入L1 Cache(TSO模型)。
也看个例子
static int x = 0, y = 0; static int r1, r2; static void int thread_cpu0(void){ x = 1; /* 1) */ r1 = y; /* 2) */ } static void int thread_cpu1(void){ y = 1; /* 3) */ r2 = x; /* 4) */ } static void check_after_assign(void){ printk("r1 = %d, r2 = %d\n", r1, r2); }
假设thread_cpu0在CPU0上执行,thread_cpu1在CPU1上执行。在多核系统上,我们知道两个函数4条操作执行可以互相交错。
我们就以1) 3) 2) 4)的执行次序说明问题。当CPU0执行x = 1时,x的值会被写入CPU0的store buffer。CPU1指令y = 1操作,同样y的值会被写入CPU1的store buffer。接下来,r1 = y执行时,CPU0读取y的值,由于y的新值依然在CPU1的store buffer里面,所以CPU0看到y的值依然是0。所以r1的值是0。为什么CPU0看到r1的值是0呢?因为硬件MESI协议只会保证Cache一致性,只要值没有被写入Cache(依然躺在store buffer里面),MESI就管不着。同样的道理,r2的值也会是0。此时我们看到了一个意外的结果。
这里有个注意点,虽然store buffer主要是用来缓存CPU的写操作,但是CPU读取数据时也会检查私有store buffer是否命中,如果没有命中才会查找L1 Cache。这主要是为了CPU自己看到自己写进store buffer的值。所以CPU0是可以看到x值更新,但是CPU1不能及时看到x。所以说“单核乱序对程序员是透明的,只有其他核才会受到乱序影响”。
我们应该如何去理解这样的结果呢?我们先简单了解下一致性问题。一致性分为两种:
- cache一致性,关注的是多个CPU看到一个地址的数据是否一致,比如通过MESI协议,主要由硬件保证;
- 内存一致性,关注的是多个CPU看到多个地址数据读写的次序。
回到上面的例子,如果以 2) 4) 1) 3) 的执行次序,在其他CPU看来,CPU0似乎是1)和2)指令互换,CPU1似乎是3)和4)指令互换,我们针对写操作称之为store,读操作称之为load。所以我们可以这么理解,CPU0的store-load操作,在别的CPU看来乱序执行了,变成了load-store次序。
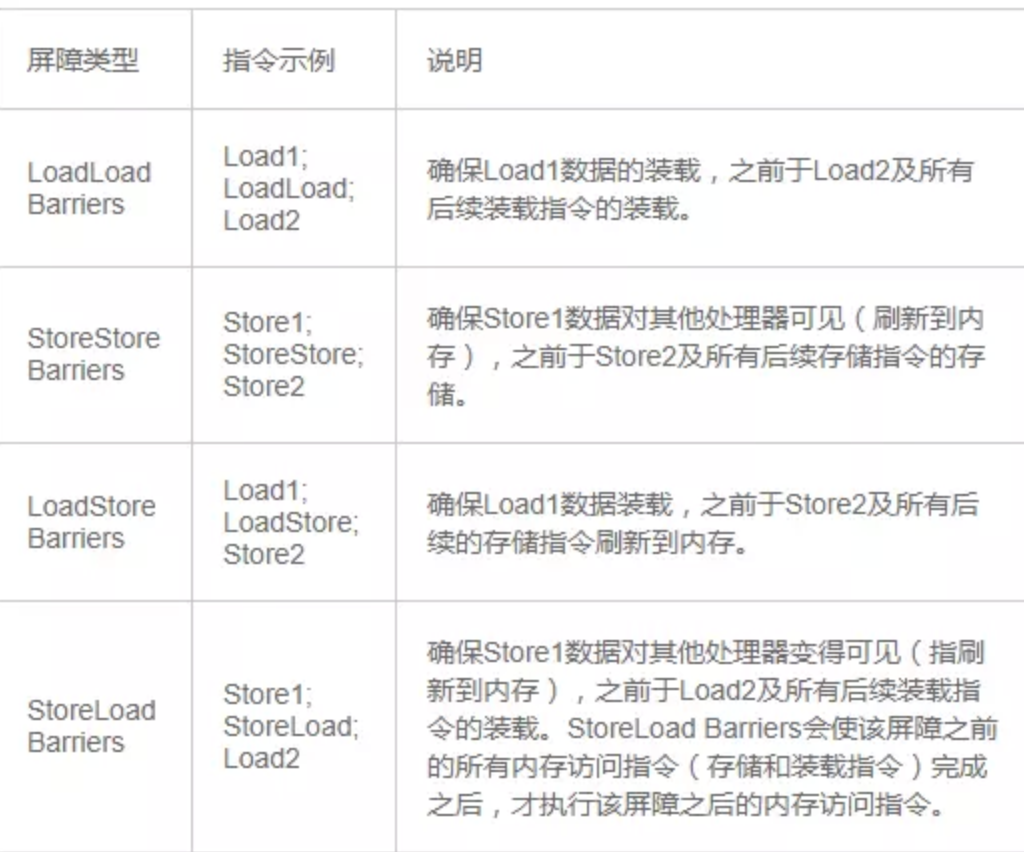
store和load的组合有4种:store-store,store-load,load-load和load-store。
内存模型
SC模型(sequential consistency,顺序一致性)
CPU会按照程序中顺序依次执行store和load指令。
TSO 模型(Total Store Order,完全存储定序)
在TSO模型中,我们说过store buffer会按照FIFO的顺序将数据写入L1 Cache。常见的PC处理器x86-64属于TSO模型。
TSO模型允许store-load乱序;
Linux内核中提供了smp_mb()宏对不同架构的指令进行封装,smp_mb()的作用是阻止它后面的读写操作不会乱序到宏前面的指令前执行。
如何fix以上的例子呢?我们只需要简单的将barrier()替换成smp_mb()操作即可
static void int thread_cpu0(void){
x = 1; /* 1) */
smp_mb();
r1 = y; /* 2) */
}
static void int thread_cpu1(void){
y = 1; /* 3) */
smp_mb();
r2 = x; /* 4) */
}
现在的代码我们可以这么理解,r1 = y不会比x = 1先执行。同样r2 = x不会在y = 1前执行。
PSO 模型(Part Store Order,部分存储定序)
对PSO模型此,store buffer不再以FIFO的次序写入Cache。
PSO模型允许store-load、store-store乱序;
inux内核中提供了smp_wmb()宏对不同架构的指令进行封装,smp_wmb()的作用是阻止它后面的写操作不会乱序到宏前面的写操作指令前执行。它就像是个屏障,写操作不容逾越。
回到之前的一个例子:
// global variables int flag, data; // thread1 void write_data_cpu0(int value) { data = value; flag = 1; } // thread2 void read_data_cpu1(void) { while (flag == 0); return data; }
由于现在store buffer不以FIFO的次序更新Cache,所以可能导致CPU1读取到data的旧值0,而flag新值true。
如果我们需要上述的示例代码在PSO模型的处理器上正确运行(按照我们期望的结果运行),就需要做出如下修改
void write_data_cpu0(int value) { data = value; smp_wmb(); flag = 1; }
smp_wmb()可以保证CPU1看到flag的值为1时,data的值一定是最新的值。
RMO 模型(Relaxed Memory Order)
RMO模型对4种操作都可以乱序。
inux内核中提供了smp_rmb()宏对不同架构的指令进行封装,smp_rmb()保证屏障后的读操作不会乱序到屏障前的读操作,只针对读操作,不影响写操作。
在RMO模型下,上述例子可以改成
// global variables int flag, data; // thread1 void write_data_cpu0(int value) { data = value; smp_wmb(); flag = 1; } // thread2 void read_data_cpu1(void) { while (flag == 0); smp_rmb(); return data; }
参考:
https://zhuanlan.zhihu.com/p/102370222
https://zhuanlan.zhihu.com/p/45808885

 浙公网安备 33010602011771号
浙公网安备 33010602011771号