
Redis 集群搭建
首先redis就是一个服务,在linux里面其实就是一个进程的存在。所以因为资源限制,也可以使用一台机器进行伪集群测试。
注意这玩意,至少6个实例,三对的master slave
redis集群解决问题
1)容量不够,进行扩容
2)并发读写操作, redis实例进行分摊
什么是集群
Redis 集群实现了对Redis的水平扩容,即启动N个redis节点,将整个数据库分布存储在这N个节点中,每个节点存储总数据的1/N。
Redis 集群通过分区(partition)来提供一定程度的可用性(availability): 即使集群中有一部分节点失效或者无法进行通讯, 集群也可以继续处理命令请求。
安装ruby的环境
yum install ruby(安装ruby)
yum install rubygems(ruby的包管理器)
gem install redis(安装ruby脚本运行使用的第三方包,点击下载)
我这边提个安装gem install redis可能出现的问题,提示ruby版本太低了:

网上说要装RVM,然后更新ruby版本,但是本人一直捣鼓不成功,于是放弃,直接下载,然后上传/opt后本地安装。

执行在opt目录下执行 gem install --local redis-3.3.5.gem
配置实例
因为一台机子模拟,注意点其实就下下面几个了:
拷贝多个redis.conf文件,需要include共有的redis.conf
可以把共有的redis.conf中bind ip注释掉
共有的redis.conf中开启daemonize yes
Pid文件名字
指定端口
Log文件名字
Dump.rdb名字
Appendonly 关掉或者换名字
制作6个实例,6379,6380,6381,6389,6390,6391.
处了上面几个,还要加上集群对应的配置
cluster-enabled yes,打开集群模式 cluster-config-file nodes-6379.conf, 设定节点配置文件名 cluster-node-timeout 15000, 设定节点失联时间,超过该时间(毫秒),集群自动进行主从切换。
最终的配置配置文件形成如下:
include /usr/local/src/bchen/redis-5.0.8/redis.conf pidfile "/usr/local/src/bchen/redis-5.0.8/cluster/redis_6379.pid" port 6379 logfile "/usr/local/src/bchen/redis-5.0.8/cluster/file_6379.log" dbfilename "dump_6379.rdb" dir "/usr/local/src/bchen/redis-5.0.8/cluster" cluster-enabled yes cluster-config-file nodes-6379.conf cluster-node-timeout 15000
6380,6381,6389,6390,6391对应的配置文件,无非就是所有的6379改成自己对应的端口号。notepad++编辑后替换。
接下来启动各个实例,然后由于这些节点现在还未全部关联起来,所以要用命令联结成一个集群:
启动成功后:
到src目录下:
./redis-trib.rb create --replicas 1 ip:6379 ip:6380 ip:6381 ip:6389 ip:6390 ip:6391
一个集群至少要有三个主节点, 这个--replicas 1表示需要为主机配置一个slave
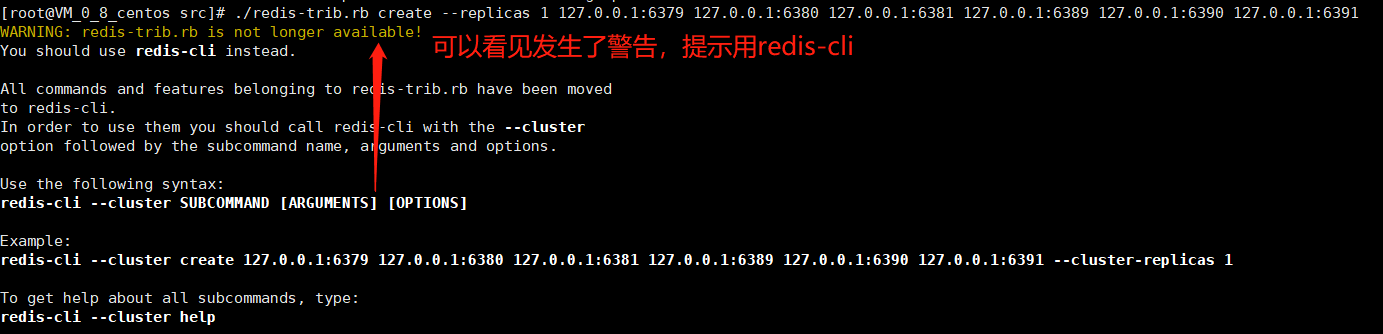
心累:现在高版本的redis-cli已经支持集群了,不再需要安装ruby了。前面捣鼓安装ruby环境也没啥用啊。改成redis-cli --cluster
这边其实还给了命令的提示,所以直接按照给出的例子跑:

到这样子,说明成功:
>>> Performing hash slots allocation on 6 nodes...
Master[0] -> Slots 0 - 5460
Master[1] -> Slots 5461 - 10922
Master[2] -> Slots 10923 - 16383
Adding replica 127.0.0.1:6390 to 127.0.0.1:6379
Adding replica 127.0.0.1:6391 to 127.0.0.1:6380
Adding replica 127.0.0.1:6389 to 127.0.0.1:6381
>>> Trying to optimize slaves allocation for anti-affinity
[WARNING] Some slaves are in the same host as their master
M: bb023446318db7b2c869ec3411d1cdae6db60c97 127.0.0.1:6379
slots:[0-5460] (5461 slots) master
M: e137a98ccd2b15fe281ef1c454af754bfc8f9a19 127.0.0.1:6380
slots:[5461-10922] (5462 slots) master
M: 6be42717add07f25b4f0e2338982c951b5c03396 127.0.0.1:6381
slots:[10923-16383] (5461 slots) master
S: 974f8b6ca26cdaf0e98b711d742a1b99a20fde3b 127.0.0.1:6389
replicates e137a98ccd2b15fe281ef1c454af754bfc8f9a19
S: 9f38617c219ea9a557c8612d9b59b638086dfae9 127.0.0.1:6390
replicates 6be42717add07f25b4f0e2338982c951b5c03396
S: 80476529d11c8c089c5d81f3edd0c016404842b1 127.0.0.1:6391
replicates bb023446318db7b2c869ec3411d1cdae6db60c97
Can I set the above configuration? (type 'yes' to accept): yes
>>> Nodes configuration updated
>>> Assign a different config epoch to each node
>>> Sending CLUSTER MEET messages to join the cluster
Waiting for the cluster to join
.....
>>> Performing Cluster Check (using node 127.0.0.1:6379)
M: bb023446318db7b2c869ec3411d1cdae6db60c97 127.0.0.1:6379
slots:[0-5460] (5461 slots) master
1 additional replica(s)
S: 974f8b6ca26cdaf0e98b711d742a1b99a20fde3b 127.0.0.1:6389
slots: (0 slots) slave
replicates e137a98ccd2b15fe281ef1c454af754bfc8f9a19
M: e137a98ccd2b15fe281ef1c454af754bfc8f9a19 127.0.0.1:6380
slots:[5461-10922] (5462 slots) master
1 additional replica(s)
S: 80476529d11c8c089c5d81f3edd0c016404842b1 127.0.0.1:6391
slots: (0 slots) slave
replicates bb023446318db7b2c869ec3411d1cdae6db60c97
S: 9f38617c219ea9a557c8612d9b59b638086dfae9 127.0.0.1:6390
slots: (0 slots) slave
replicates 6be42717add07f25b4f0e2338982c951b5c03396
M: 6be42717add07f25b4f0e2338982c951b5c03396 127.0.0.1:6381
slots:[10923-16383] (5461 slots) master
1 additional replica(s)
[OK] All nodes agree about slots configuration.
>>> Check for open slots...
>>> Check slots coverage...
[OK] All 16384 slots covered.
这一块就是最终集群最终的信息:
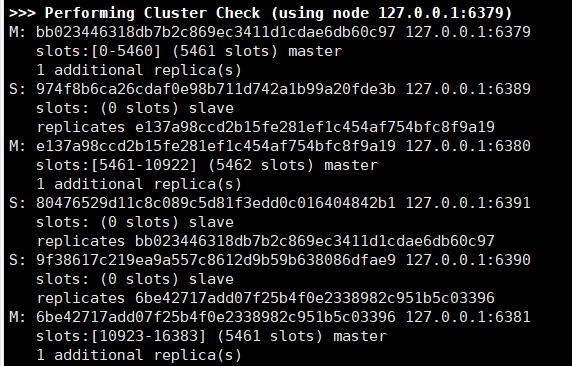
注意,怎么看从机是属于哪个master呢?有个replicates的字段进行标识了,后面会跟着一个40位的master的runid。
在具体的实例上也可以查看集群关系:
cluster nodes

接下来尝试往redis写数据:
redis集群slots
一个 Redis 集群包含 16384(1024*16) 个插槽(hash slot), 数据库中的每个键都属于这 16384 个插槽的其中一个, 集群使用公式 CRC16(key) & 16384 来计算键 key 属于哪个槽, 其中 CRC16(key) 语句用于计算键 key 的 CRC16 校验和 。说白了就是一种算法而已,映射过去。
集群中的每个节点负责处理一部分插槽。 上面的截图其实有指示各个master节点所负责的插槽的范围。
我现在尝试登入后,写数据,失败:
127.0.0.1:6391> set k1 v1
(error) MOVED 12706 127.0.0.1:6381
其实就是k1对应的插槽在6381上,所以我过去应该到6381上执行。在redis-cli每次录入、查询键值,redis都会计算出该key应该送往的插槽,如果不是该客户端对应服务器的插槽,redis会报错,并告知应前往的redis实例地址和端口。
但是集群应该是整体?所以这种的其实不能用常规的方式登入,需要用集群的方式登入:
redis-cli客户端提供了 –c 参数实现自动重定向。 如 redis-cli -c –p 6379 登入后,再录入、查询键值对可以自动重定向。
127.0.0.1:6379> set k1 v1 -> Redirected to slot [12706] located at 127.0.0.1:6381 OK
可以看到也是redirected到6381上的12706插槽。其实数据是分master存储的。只不过以集群的形式登入后,可以自动重定向。但是6379里面还是没有这个key。如

注意:不在一个slot下的键值,是不能使用mget,mset等多键操作。
示例,异常显示,hash值不在同一个slot上:

但是非要进行批操作的话,就需要为k2,k3,k4指定hash运算的别名。可以通过{}来定义组的概念,从而使key中{}内相同内容的键值对放到一个slot中去。
如下,即可成功,即计算的时候会用c进行计算:

接下来是关于插槽的几个命令, 其实不是很重要:
CLUSTER KEYSLOT <key> 计算键 key 应该被放置在哪个槽上。
CLUSTER COUNTKEYSINSLOT <slot> 返回槽 slot 目前包含的键值对数量。
CLUSTER GETKEYSINSLOT <slot> <count> 返回 count 个 slot 槽中的键。
集群相关问题思考
1、如果主节点下线?从节点能否自动升为主节点?
如下测试, 当前6379是6391的master, 现在shutdown后查看集群情况:

可以看到6379挂了后,6391自动上位变成master, 注意,这个跟我们的主从复制是不一样的,主从复制里面,得要配置哨兵,否则,不会自动上位。
2、主节点恢复后,主从关系会如何?
那如果6379回来呢了?我们启动6379试试:

发现回来之后,直接变成slave.
3、如果所有某一段插槽的主从节点都宕掉,redis服务是否还能继续?
这个redis.conf中的参数cluster-require-full-coverage可以进行配置,正常数据比较重要,主从全没的话,就是服务会停止。
Jedis集群连接
public class JedisClusterTest { public static void main(String[] args) { Set<HostAndPort> set =new HashSet<HostAndPort>(); set.add(new HostAndPort("ip",6379)); JedisCluster jedisCluster=new JedisCluster(set); jedisCluster.set("k1", "v1"); System.out.println(jedisCluster.get("k1")); } }
JedisCluster的api其实跟我们的Jedis是差不多的。
Redis 集群的不足
1、多键操作是不被支持的 (需要归组指定)。多键的Redis事务是不被支持的。
2、lua脚本不被支持。这个lua其实就是个脚本。
3、由于集群方案出现较晚,后面的版本才有,所以有些公司想全部迁移到集群,还是要下很多功夫。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号