运用python爬取手机品牌评分热榜
运用python爬取手机品牌评分热榜
一.选题背景:
信息技术的不断发展,极大地改变了人们的生活,并且这种改变正在以越来越快的速度蔓延。这一点,从手机服务的发展中就能体现出来。手机从最开始的提供的通话服务,到后来的短信服务,再到如今的多样化服务,手机服务功能的多样化不仅仅给人们提供了便利,同时,它也深刻的影响了整个社会、经济的发展。同时,人们对于电子设备的需求越来越大,对于电子设备功能的需求也越来越大。所以,对手机热销评分榜单进行分析,有助于了解现在手机行业的发展,同时还能体现出手机的功能在社会是否被真正的需要,以及能更好的了解到,现在人对于手机功能具有怎样的需求。
二、主题式网络爬虫设计方案:
1、主题式网络爬虫名称:爬取手机品牌评分热榜。
3、网络爬虫设计方案概述:访问网页,分析网页源代码,找出所需要的的标签,逐个提取标签保存到相同路径的文件中,读取改文件,进行数据清洗,数据模型分析,数据可视化处理,绘制图形、保存数据。
4、技术难点:设置爬虫障碍;许多数据是图片格式以及爬取到的数据含有不需要的宇符串,需要通过其他手段进行处理。
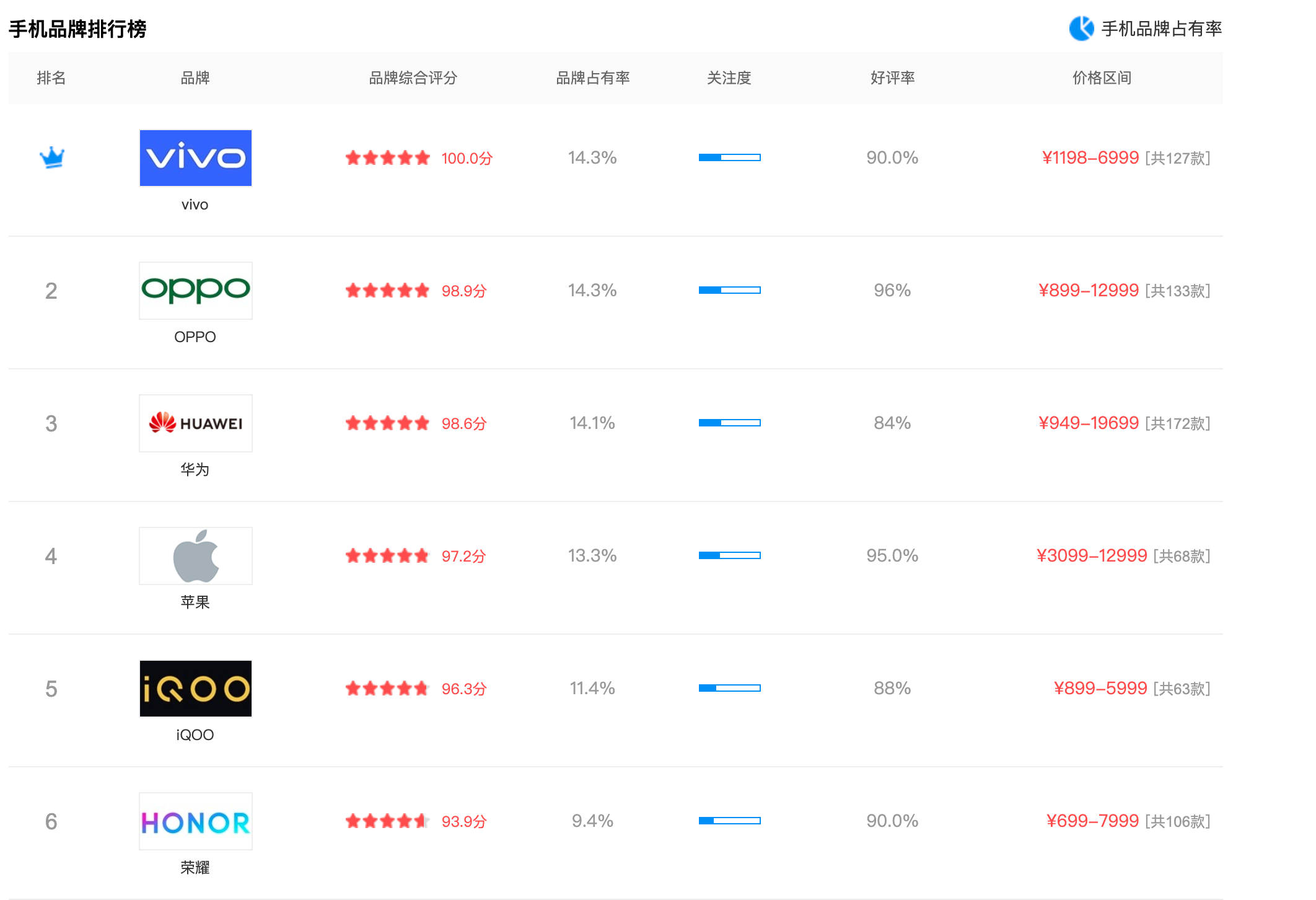
Htmls页面解析:
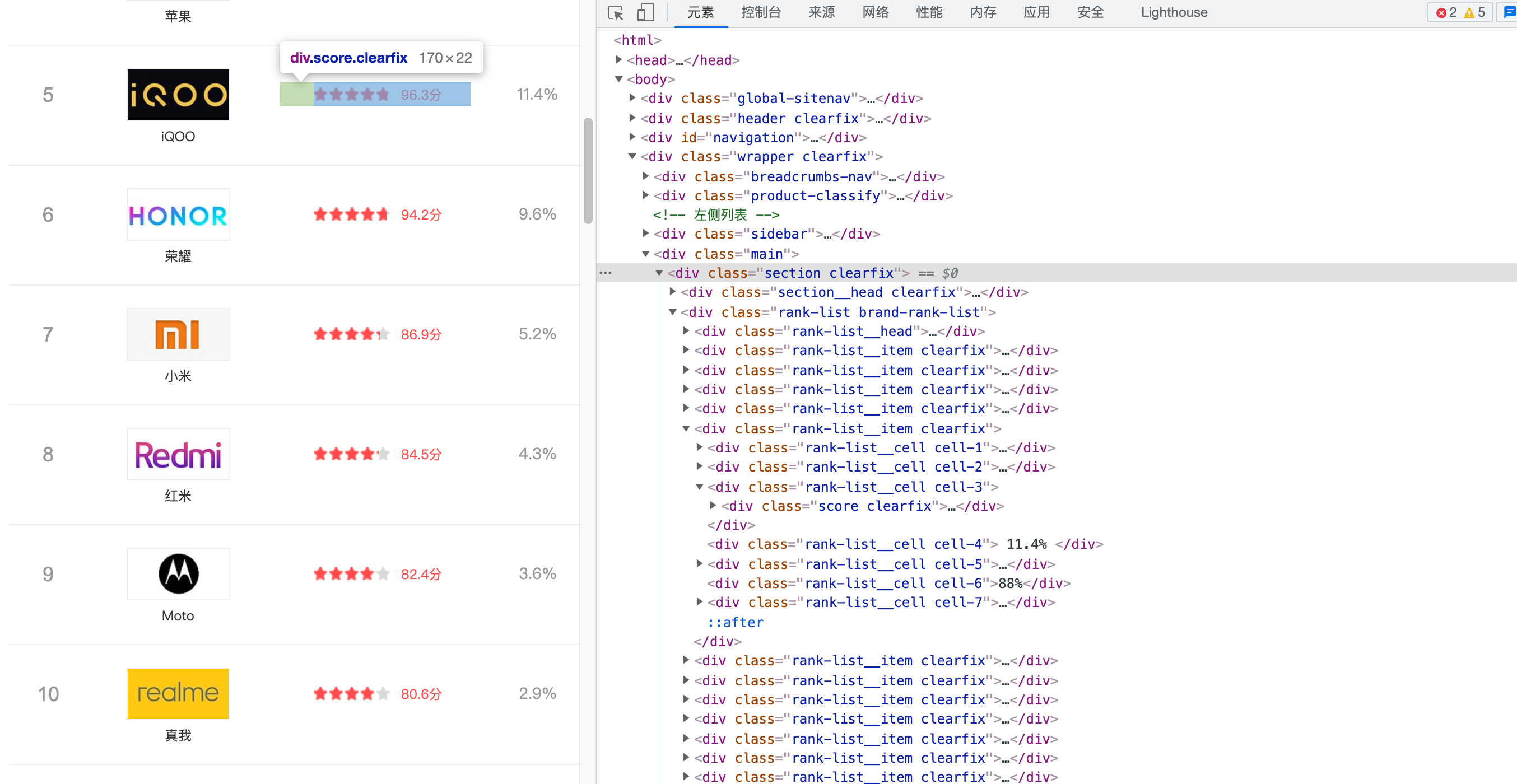
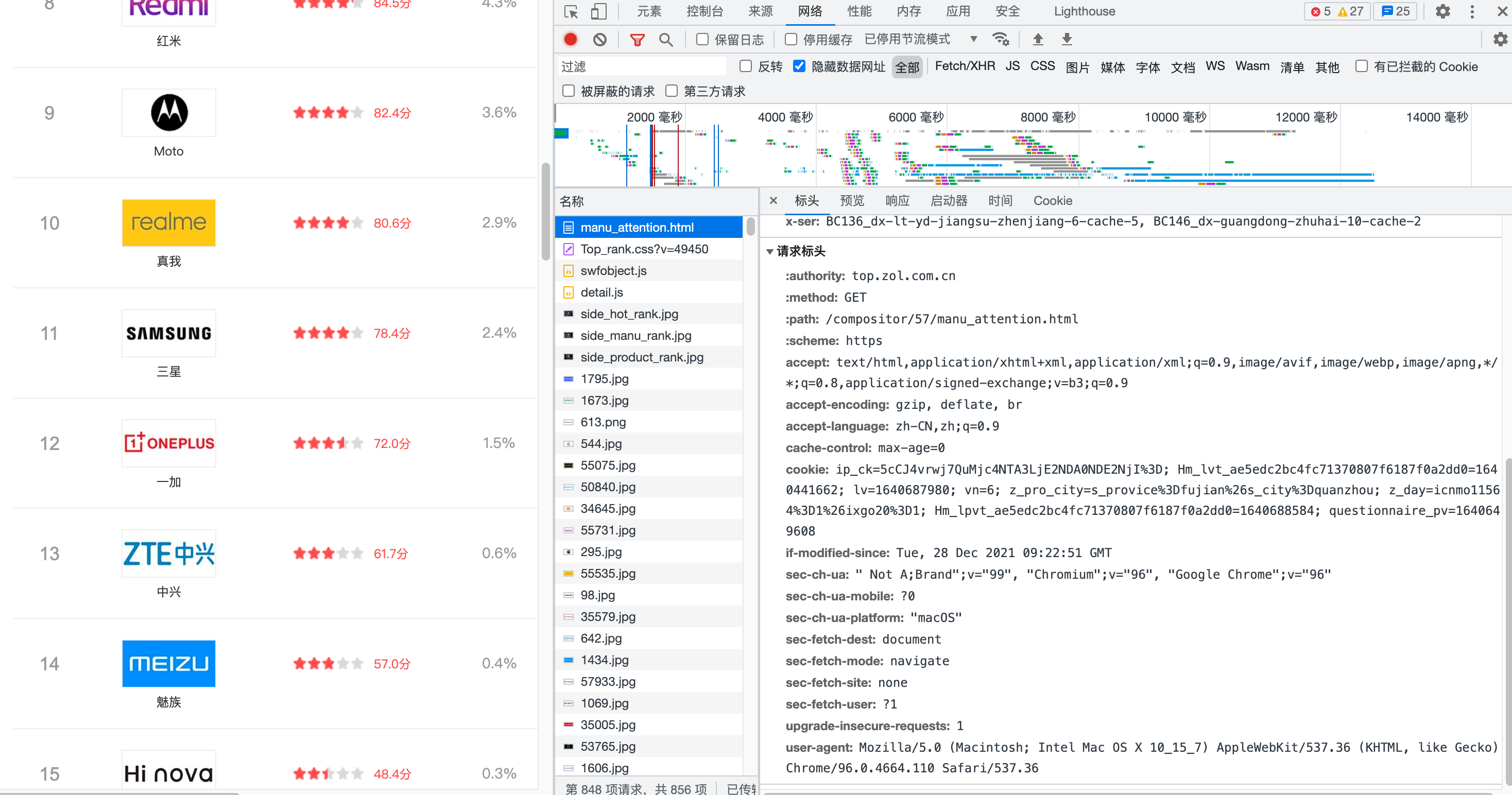
四、网络爬虫程序设计
1.数据爬取与采集:
1 #导入相应的库 2 3 import requests 4 from bs4 import BeautifulSoup 5 import bs4 6 import pandas as pd 7 import matplotlib.pyplot as plt 8 import numpy as np 9 import re 10 import scipy as sp 11 from scipy.optimize import leastsq 12 import matplotlib as mpl 13 from numpy import genfromtxt 14 import seaborn as sns 15 16 #准备工作---爬取数据 17 18 print("-------开始爬取数据--------\n") 19 20 def getHTMLText(): 21 #爬取的网址 22 url = 'https://top.zol.com.cn/compositor/57/manu_attention.html' 23 try: 24 #爬虫伪装 25 headers = {'user-agent: Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/96.0.4664.110 Safari/537.36'} 26 #用requests爬取网页信息 27 r=requests.get(url,timeout=30,headers=headers) 28 #产生异常信息 29 r.raise_for_status() 30 #设置编码标准 31 r.encoding=r.apparent_encoding 32 soup=BeautifulSoup(r.text,'lxml') 33 #返回爬取的网页内容 34 return soup 35 #若发生报错,则返回空字符串 36 except: 37 return "" 38 39 print("-------数据爬取完成--------\n")
显示结果如下:

2.对数据进行清洗和处理:用for循环遍历数据,但由于一些数据用for循环不好获取,这里我选择用正则表达式进行获取和数据处理
对于一些数据含有字符串、符号、0等数据替换成缺失值
1 #数据清洗和处理及保存 2 def data_analysis(soup): 3 #建立需要的空列表 4 name=[] 5 grade=[] 6 occupancy=[] 7 attention=[] 8 praise=[] 9 price=[] 10 minimum_price=[] 11 highest_price=[] 12 style=[] 13 link=[] 14 brand=[] 15 #用for循环爬取需要的数据 16 #先遍历大的class类型 17 for data in soup.find_all("div",class_="rank-list__item clearfix"): 18 for link1 in data("a",class_="name"): 19 name.append(link1.get_text()) 20 for link2 in data("div",class_="score clearfix"): 21 grade.append(link2.get_text().strip()) 22 for link3 in data("div",class_="rank-list__cell cell-4"): 23 occupancy.append(link3.get_text().strip()) 24 for link4 in data("div",class_="rank-list__cell cell-6"): 25 praise.append(link4.get_text().strip()) 26 for link5 in data("div",class_="rank__price"): 27 price.append(link5.get_text().strip()) 28 #用正则获取链接 29 link_=[] 30 link_=re.findall(r'(http:.+html)',str(data)) 31 #将连接存入列表 32 link.append(link_[0]) 33 brand_=[] 34 brand_=re.findall(r'(https:.+jpg)',str(data)) 35 brand.append(brand_[0]) 36 #获取关注度 37 attention=re.findall('<span style="width: (.*)"></span>',str(soup)) 38 #将价格区间分成最低价和最高价,并将暂无报价的以空字符保存 39 minimum_price=re.findall("¥(\d*)-|暂无报价",str(price)) 40 highest_price=re.findall("-(\d*)|暂无报价",str(price)) 41 #将种类单独存放 42 style=re.findall(r"共(\d*)款",str(price)) 43 #用正则将数据中的“分”字去除,便于后续的数据处理 44 grade=re.findall("(\d\d.\d|\d)",str(grade)) 45 #将occupancy,attention,praise列表中的“%”符号删去,便于后续的数据处理 46 occupancy=re.findall("(\d+.?\d)%|-",str(occupancy)) 47 attention=re.findall("(\d+)%",str(attention)) 48 praise=re.findall("(\d\d.\d|\d\d)%",str(praise)) 49 #将以下数据中的 “0” “” “0%” 的部分替换成缺失值 50 for j in range(len(occupancy)): 51 if occupancy[j]=="": 52 occupancy[j]=(np.nan) 53 if grade[j]=="0": 54 grade[j]=(np.nan) 55 if attention[j]=="0":
56 attention[j]=(np.nan) 57 if attention[j]=="0%": 58 attention[j]=(np.nan) 59 if minimum_price[j] and highest_price[j]==" ": 60 minimum_price[j]=(np.nan) 61 highest_price[j]=(np.nan)
显示结果如下:

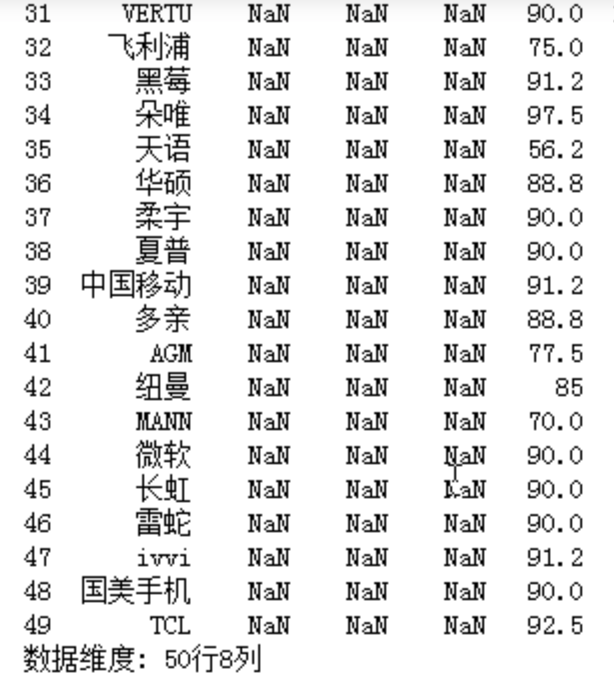
3.数据分析与可视化:对所有数据用DataFrame结构处理,
查看数据维度,查找缺失值、重复值,删除缺失值、重复值所对应的行
1 #对所有数据用DataFrame结构处理 2 data1=pd.DataFrame([name,grade,occupancy,attention,praise,minimum_price,highest_price,style],\ 3 index=["品牌","评分","占有率","关注度","好评率","最低价","最高价","种类"]).T 4 #使数据输出时列名对齐 5 pd.set_option('display.unicode.ambiguous_as_wide', True) 6 pd.set_option('display.unicode.east_asian_width', True) 7 #查看数据维度 8 print("数据维度: {:}行{:}列\n".format(data1.shape[0],data1.shape[1]),"\n") 9 #使用describe查看统计信息 10 print(data1.describe(),"\n") 11 #查看数据是否有缺失值 12 print(data1.isnull(),"\n") 13 #只显示存在缺失值的行列,清楚的确定缺失值得位置 14 print(data1[data1.isnull().values==True],"\n") 15 #统计各列缺失值情况 16 print(data1.isnull().sum(),"\n") 17 #查找重复值 18 print(data1.duplicated(),"\n") 19 #删除重复值 20 data1=data1.drop_duplicates() 21 #删除缺失值对应的行 22 data=data1.dropna()
运行结果如下:


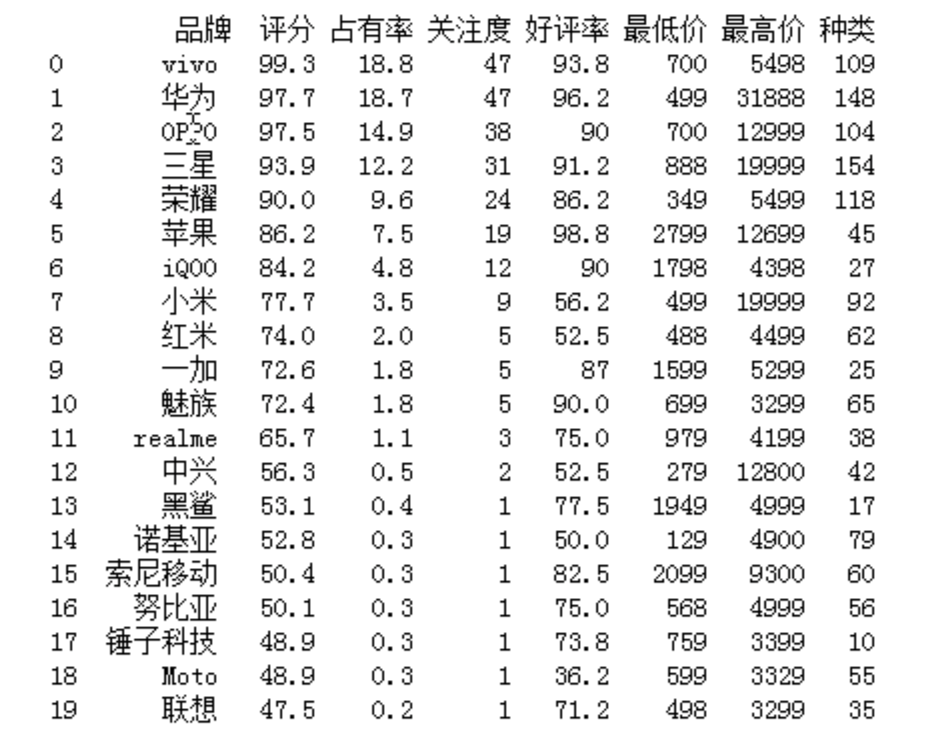
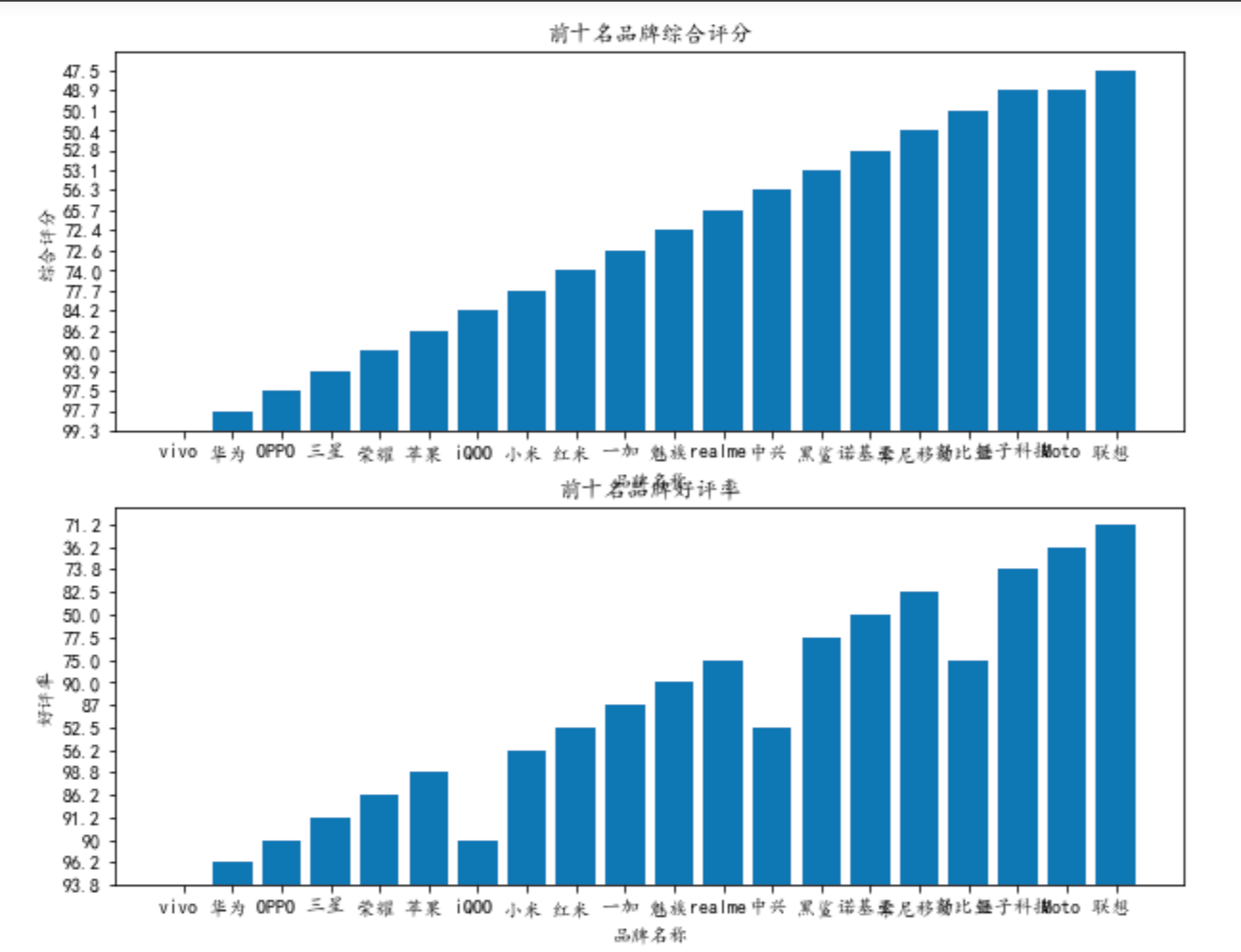
4.开始绘制各种图形:由于数据带有引号,绘制图形过程中存在报错,所以将数据转化为浮点型,在绘制过程中将每一个图形进行保存
1 #正常显示中文字体 2 mpl.rcParams['font.sans-serif'] = ['KaiTi'] 3 mpl.rcParams['font.serif'] = ['KaiTi'] 4 #解决保存图像是负号'-'显示为方块的问题,或者转换负号为字符 5 mpl.rcParams['axes.unicode_minus'] = False 6 #数据分析 7 #设置画布大小(横10竖8) 8 plt.figure(figsize=(10,8)) 9 #创建子图1 10 axes1=plt.subplot(2,1,1) 11 #绘制品牌与评分之间的柱状图 12 plt.bar(data['品牌'],data['评分']) 13 #创建子图1的标题 14 plt.title('前十名品牌综合评分') 15 #创建子图1的x轴名称 16 plt.xlabel('品牌名称') 17 #创建子图1的y轴名称 18 plt.ylabel("综合评分") 19 axes2=plt.subplot(2,1,2) 20 plt.bar(data['品牌'],data['好评率']) 21 plt.title('前十名品牌好评率') 22 plt.xlabel('品牌名称') 23 plt.ylabel("好评率") 24 #将图片进行保存 25 plt.savefig('E:/图片/1') 26 #显示图像 27 plt.show() 28 # 接下来只对前十名做数据分析 29 data_=data[0:10] 30 #绘制饼状图 31 plt.figure(figsize=(6,6)) 32 plt.pie(data_['占有率'],labels=data_['品牌']) 33 plt.title("品牌占有率") 34 plt.savefig('E:/图片/2') 35 plt.show() 36 #创建最低价与品牌之间的饼状图 37 plt.figure(figsize=(6,6)) 38 plt.pie(data_['最低价'],labels=data_['品牌']) 39 plt.title("品牌最低价") 40 plt.savefig('E:/图片/3') 41 plt.show() 42 #创建最高价与品牌之间的饼状图 43 plt.figure(figsize=(6,6)) 44 plt.pie(data_['最高价'],labels=data_['品牌']) 45 plt.title("品牌最高价") 46 plt.savefig('E:/图片/4') 47 plt.show() 48 #创建种类与品牌之间的饼状图 49 plt.figure(figsize=(6,6)) 50 plt.pie(data_['种类'],labels=data_['品牌']) 51 plt.title("品牌种类") 52 plt.savefig('E:/图片/5') 53 plt.show() 54 #绘制柱状图 55 plt.figure(figsize=(15,6)) 56 #创建10个数字,用于x轴的分组 57 x=np.arange(10) 58 #绘制最低价,最高价,种类的柱状图 59 y1=data_['最低价'] 60 y2=data_['最高价'] 61 y3=data_['种类'] 62 #设置间距 63 bar_width=0.3 64 #在偏移间距位置绘制柱状图 65 plt.bar(x,y1,bar_width,align="center",color="c",label="最低价",alpha=0.5) 66 plt.bar(x+bar_width,y2,bar_width,align="center",color="b",label="最高价",alpha=0.5) 67 plt.bar(x+2*bar_width,y3,bar_width,align="center",color="r",label="种类",alpha=0.5) 68 plt.xlabel("名称") 69 plt.ylabel("数目") 70 #设置x轴组别的位置,且以品牌名称作为组别名称 71 plt.xticks(x+bar_width,data_["品牌"]) 72 #显示图例,位置有系统选择最佳位置 73 plt.legend() 74 plt.savefig('E:/图片/6') 75 plt.show() 76 #绘制盒图 77 plt.boxplot((X,Y,data_['占有率'].astype('float64'),data_['好评率'].astype('float64'),y3.astype('float64')),\ 78 labels=("品牌","评分","占有率","好评率","种类")) 79 plt.title("各数据的盒图情况") 80 plt.savefig('E:/图片/8') 81 plt.show()
运行的结果如下:
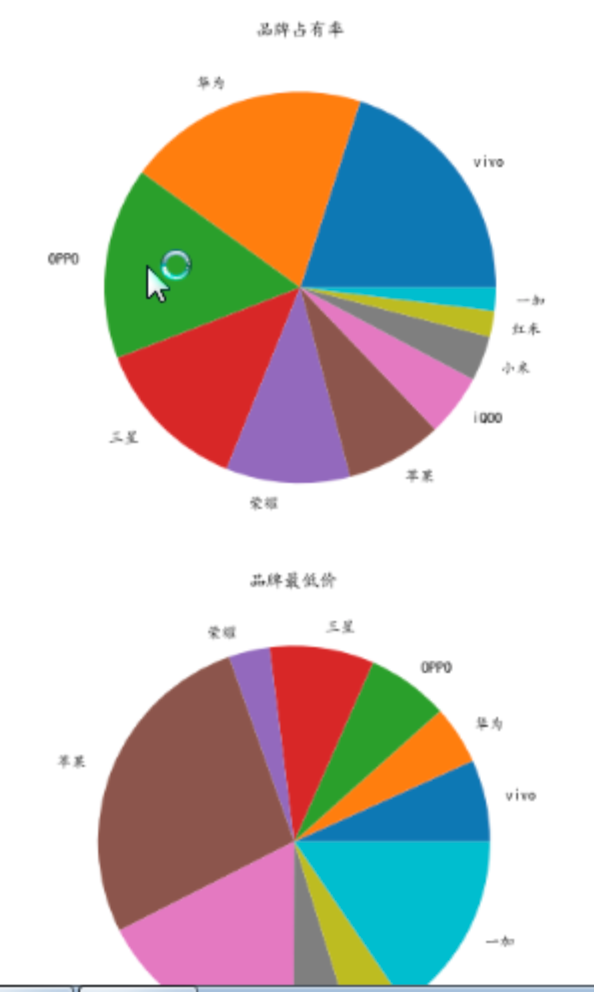
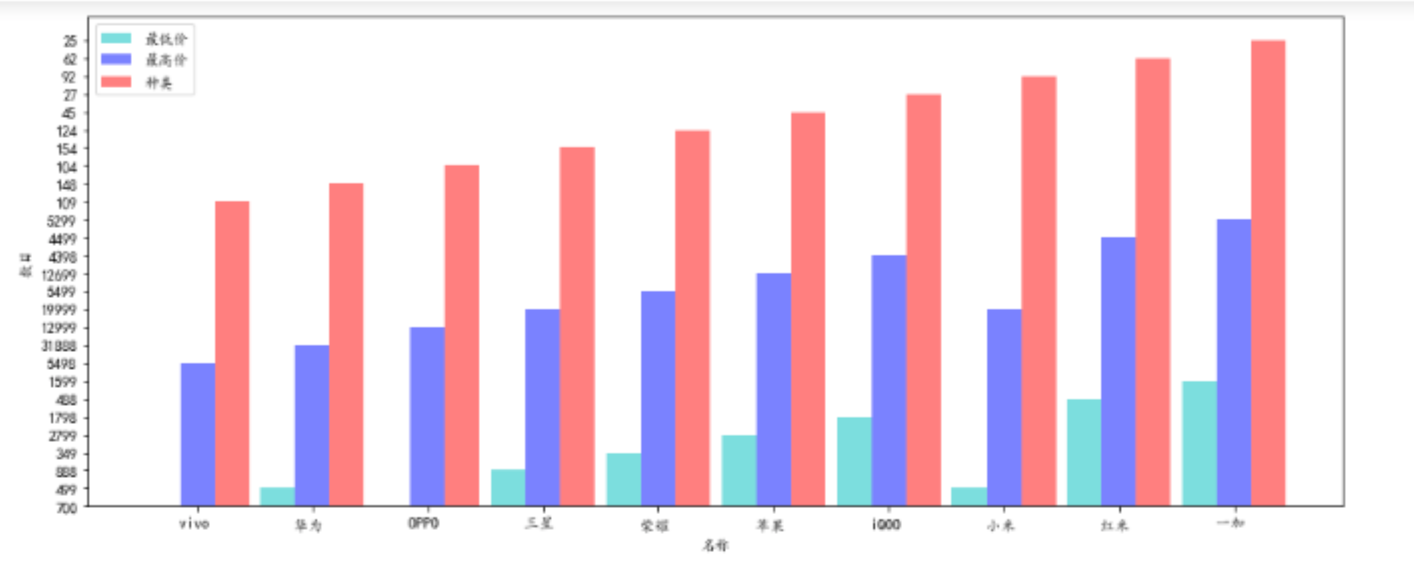
5.根据数据之间的关系,分析两个变量之间的相关系数,画出散点图,并建立变量之间的回归方程
1 #绘制拟合直线方程 2 X=(data['评分'])[::-1] 3 Y=(data['占有率'])[::-1] 4 #去除X,Y数据中的引号(转化为64位系数的浮点型) 5 X = X.astype('float64') 6 Y = Y.astype('float64') 7 #设置拟合函数 8 #二次函数标准形式 9 def func(p,x): 10 a,b,c=p 11 return a*x*x+b*x+c 12 #设置误差函数 13 def error_func(p,x,y): 14 return func(p,x)-y 15 #设置初始值,数值可随意指定 16 p0=[73.4,99.3,99.5] 17 #使用最小二乘法对数据进行拟合 18 Para=leastsq(error_func,p0,args=(X,Y)) 19 a,b,c=Para[0] 20 #打印参数 21 print("a=",a,"b=",b,"c=",c) 22 plt.figure(figsize=(10,6)) 23 #绘制散点图 24 plt.scatter(X,Y,color="green",label="样本数据",linewidth=2) 25 #绘制拟合直线 26 x=np.linspace(47.4,99.3,20) 27 y=a*x*x+b*x+c 28 plt.plot(x,y,color="red",label="拟合数据",linewidth=2) 29 plt.legend() 30 plt.title("品牌评分与占有率的关系") 31 plt.xlabel("评分") 32 plt.ylabel("占有率") 33 #设置网格线 34 plt.grid() 35 plt.savefig('D:/排行版图片/7') 36 plt.show()
运行结果如下:

6.数据持久化:
1 #数据保存 2 #将品牌链接增加到data1数据中 3 data1['品牌链接']=link 4 #将品牌商标链接增加到data1数据中 5 data1['品牌商标链接']=brand 6 #创建Excel表并写入数据 7 #创建文件名 8 wb ='E:\\手机品牌排行榜.xlsx' 9 #将数据保存 10 data1.to_excel(wb)
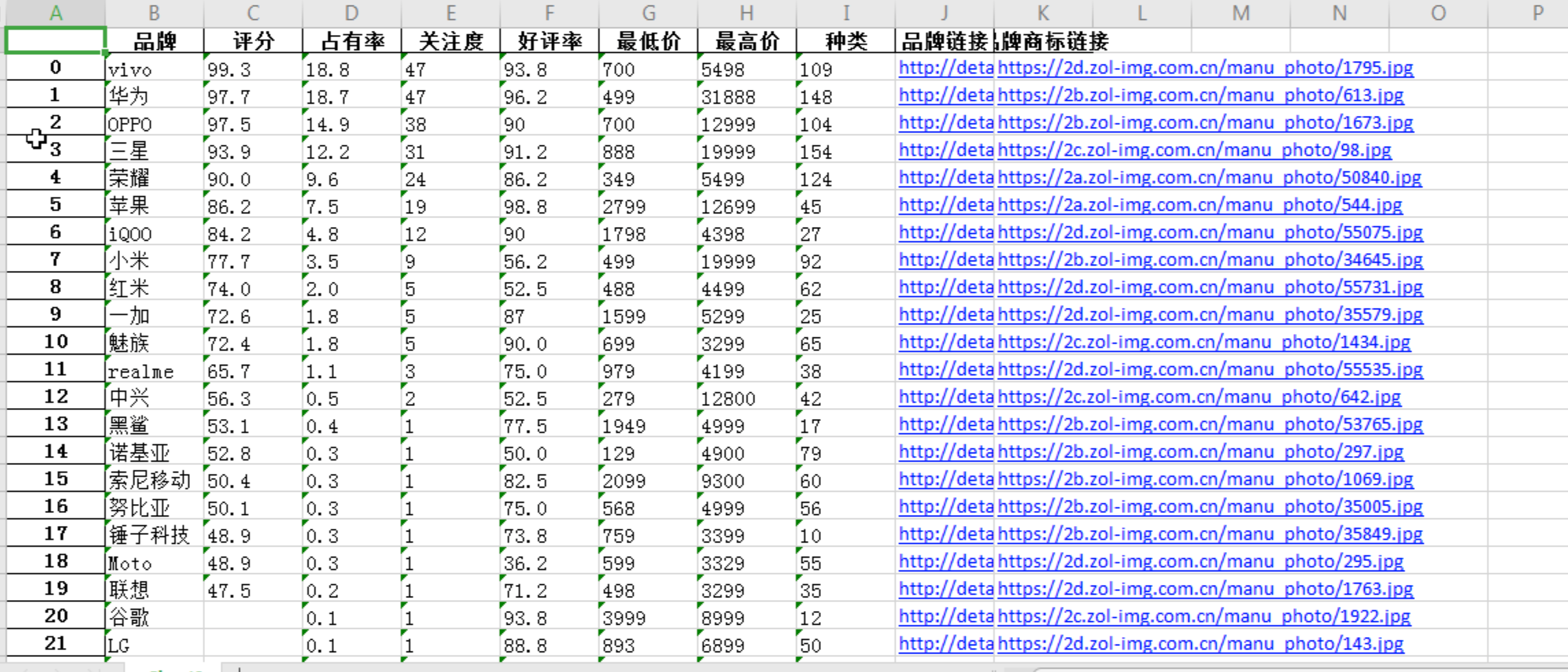
7. 完整代码
1 #导入相应的库 2 3 import requests 4 from bs4 import BeautifulSoup 5 import bs4 6 import pandas as pd 7 import matplotlib.pyplot as plt 8 import numpy as np 9 import re 10 import scipy as sp 11 from scipy.optimize import leastsq 12 import matplotlib as mpl 13 from numpy import genfromtxt 14 import seaborn as sns 15 16 #准备工作---爬取数据 17 18 print("-------开始爬取数据--------\n") 19 20 def getHTMLText(): 21 #爬取的网址 22 url = 'http://top.zol.com.cn/compositor/57/manu_attention.html' 23 try: 24 #爬虫伪装 25 headers = {'user-agent: Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/96.0.4664.110 Safari/537.36'} 26 #用requests爬取网页信息 27 r=requests.get(url,timeout=30,headers=headers) 28 #产生异常信息 29 r.raise_for_status() 30 #设置编码标准 31 r.encoding=r.apparent_encoding 32 soup=BeautifulSoup(r.text,'lxml') 33 #返回爬取的网页内容 34 return soup 35 #若发生报错,则返回空字符串 36 except: 37 return "" 38 39 print("-------数据爬取完成--------\n") 40 41 #数据清洗和处理及保存 42 43 def data_analysis(soup): 44 #建立需要的空列表 45 46 print("-------开始建立数据--------\n") 47 48 #存储品牌名称 49 name=[] 50 #存储品牌综合评分 51 grade=[] 52 #存储品牌占有率 53 occupancy=[] 54 #存储品牌关注度 55 attention=[] 56 #存储品牌好评率 57 praise=[] 58 #存储品牌价格区间及种类 59 price=[] 60 #存储最低价 61 minimum_price=[] 62 #存储最高价 63 highest_price=[] 64 #存储品牌种类 65 style=[] 66 #存储品牌链接 67 link=[] 68 #存储品牌商标链接 69 brand=[] 70 71 #用for循环爬取需要的数据 72 for data in soup.find_all("div",class_="rank-list__item clearfix"): 73 #获取品牌名称 74 for link1 in data("a",class_="name"): 75 name.append(link1.get_text()) 76 #获取品牌综合评分 77 for link2 in data("div",class_="score clearfix"): 78 grade.append(link2.get_text().strip()) 79 #获取品牌占有率 80 for link3 in data("div",class_="rank-list__cell cell-4"): 81 occupancy.append(link3.get_text().strip()) 82 #获取好评率 83 for link4 in data("div",class_="rank-list__cell cell-6"): 84 praise.append(link4.get_text().strip()) 85 #获取价格区间和种类 86 for link5 in data("div",class_="rank__price"): 87 price.append(link5.get_text().strip()) 88 link_=[] 89 link_=re.findall(r'(http:.+html)',str(data)) 90 #将连接存入列表 91 link.append(link_[0]) 92 brand_=[] 93 brand_=re.findall(r'(https:.+jpg)',str(data)) 94 #将商标连接存入列表 95 brand.append(brand_[0]) 96 97 #获取关注度 98 attention=re.findall('<span style="width: (.*)"></span>',str(soup)) 99 minimum_price=re.findall("¥(\d*)-|暂无报价",str(price)) 100 highest_price=re.findall("-(\d*)|暂无报价",str(price)) 101 style=re.findall(r"共(\d*)款",str(price)) 102 grade=re.findall("(\d\d.\d|\d)",str(grade)) 103 occupancy=re.findall("(\d+.?\d)%|-",str(occupancy)) 104 attention=re.findall("(\d+)%",str(attention)) 105 praise=re.findall("(\d\d.\d|\d\d)%",str(praise)) 106 107 #打印品牌前三名 108 print("-----2021年手机品牌前三名如下-----") 109 print("第一名: {}".format(name[0]),"\n") 110 print("第二名: {}".format(name[1]),"\n") 111 print("第三名: {}".format(name[2]),"\n") 112 113 #以下是查看收集的数据 114 #将以下数据中的 “0” “” “0%” 的部分替换成缺失值 115 for j in range(len(occupancy)): 116 if occupancy[j]=="": 117 occupancy[j]=(np.nan) 118 if grade[j]=="0": 119 grade[j]=(np.nan) 120 if attention[j]=="0": 121 attention[j]=(np.nan) 122 if attention[j]=="0%": 123 attention[j]=(np.nan) 124 if minimum_price[j] and highest_price[j]==" ": 125 minimum_price[j]=(np.nan) 126 highest_price[j]=(np.nan) 127 128 print("--------数据建立已完成--------\n") 129 130 print("--------开始处理数据--------\n") 131 132 #对所有数据用DataFrame结构处理 133 data1=pd.DataFrame([name,grade,occupancy,attention,praise,minimum_price,highest_price,style],\ 134 index=["品牌","评分","占有率","关注度","好评率","最低价","最高价","种类"]).T 135 #使数据输出时列名对齐 136 pd.set_option('display.unicode.ambiguous_as_wide', True) 137 pd.set_option('display.unicode.east_asian_width', True) 138 print(data1) 139 140 #查看数据维度 141 print("数据维度: {:}行{:}列\n".format(data1.shape[0],data1.shape[1]),"\n") 142 print(data1.describe(),"\n") 143 print(data1.isnull(),"\n") 144 print(data1[data1.isnull().values==True],"\n") 145 print(data1.isnull().sum(),"\n") 146 print(data1.duplicated(),"\n") 147 data1=data1.drop_duplicates() 148 data=data1.dropna() 149 print(data) 150 151 print("--------数据处理已完成--------\n") 152 153 print("--------开始绘制图形--------\n") 154 155 #正常显示中文字体 156 mpl.rcParams['font.sans-serif'] = ['KaiTi'] 157 mpl.rcParams['font.serif'] = ['KaiTi'] 158 mpl.rcParams['axes.unicode_minus'] = False 159 160 #数据分析 161 plt.figure(figsize=(10,8)) 162 axes1=plt.subplot(2,1,1) 163 plt.bar(data['品牌'],data['评分']) 164 plt.title('前十名品牌综合评分') 165 plt.xlabel('品牌名称') 166 plt.ylabel("综合评分") 167 axes2=plt.subplot(2,1,2) 168 plt.bar(data['品牌'],data['好评率']) 169 plt.title('前十名品牌好评率') 170 plt.xlabel('品牌名称') 171 plt.ylabel("好评率") 172 plt.savefig('E:/图片/1') 173 plt.show() 174 data_=data[0:10] 175 print(data_) 176 177 #绘制饼状图 178 179 #创建占有率与品牌之间的饼状图 180 plt.figure(figsize=(6,6)) 181 plt.pie(data_['占有率'],labels=data_['品牌']) 182 plt.title("品牌占有率") 183 plt.savefig('E:/图片/2') 184 plt.show() 185 186 #创建最低价与品牌之间的饼状图 187 plt.figure(figsize=(6,6)) 188 plt.pie(data_['最低价'],labels=data_['品牌']) 189 plt.title("品牌最低价") 190 plt.savefig('E:/图片/3') 191 plt.show() 192 193 #创建最高价与品牌之间的饼状图 194 plt.figure(figsize=(6,6)) 195 plt.pie(data_['最高价'],labels=data_['品牌']) 196 plt.title("品牌最高价") 197 plt.savefig('E:/图片/4') 198 plt.show() 199 200 #创建种类与品牌之间的饼状图 201 plt.figure(figsize=(6,6)) 202 plt.pie(data_['种类'],labels=data_['品牌']) 203 plt.title("品牌种类") 204 plt.savefig('E:/图片/5') 205 plt.show() 206 207 #绘制柱状图 208 plt.figure(figsize=(15,6)) 209 x=np.arange(10) 210 y1=data_['最低价'] 211 y2=data_['最高价'] 212 y3=data_['种类'] 213 #设置间距 214 bar_width=0.3 215 #在偏移间距位置绘制柱状图 216 plt.bar(x,y1,bar_width,align="center",color="c",label="最低价",alpha=0.5) 217 plt.bar(x+bar_width,y2,bar_width,align="center",color="b",label="最高价",alpha=0.5) 218 plt.bar(x+2*bar_width,y3,bar_width,align="center",color="r",label="种类",alpha=0.5) 219 plt.xlabel("名称") 220 plt.ylabel("数目") 221 #设置x轴组别的位置,且以品牌名称作为组别名称 222 plt.xticks(x+bar_width,data_["品牌"]) 223 #显示图例,位置有系统选择最佳位置 224 plt.legend() 225 plt.savefig('E:/图片/6') 226 plt.show() 227 228 #绘制拟合直线方程 229 X=(data['评分'])[::-1] 230 Y=(data['占有率'])[::-1] 231 #去除X,Y数据中的引号(转化为64位系数的浮点型) 232 X = X.astype('float64') 233 Y = Y.astype('float64') 234 #设置拟合函数 235 #二次函数标准形式 236 def func(p,x): 237 a,b,c=p 238 return a*x*x+b*x+c 239 #设置误差函数 240 def error_func(p,x,y): 241 return func(p,x)-y 242 #设置初始值,数值可随意指定 243 p0=[73.4,99.3,99.5] 244 #使用最小二乘法对数据进行拟合 245 Para=leastsq(error_func,p0,args=(X,Y)) 246 #将需要的参数保留下来 247 a,b,c=Para[0] 248 #打印参数 249 print("a=",a,"b=",b,"c=",c) 250 #设置画布大小(横10竖6) 251 plt.figure(figsize=(10,6)) 252 253 #绘制散点图 254 plt.scatter(X,Y,color="green",label="样本数据",linewidth=2) 255 256 #绘制拟合直线 257 x=np.linspace(47.4,99.3,20) 258 y=a*x*x+b*x+c 259 plt.plot(x,y,color="red",label="拟合数据",linewidth=2) 260 plt.legend() 261 plt.title("品牌评分与占有率的关系") 262 plt.xlabel("评分") 263 plt.ylabel("占有率") 264 plt.grid() 265 plt.savefig('E:/图片/7') 266 plt.show() 267 #用astype将数据转化为浮点型 268 plt.boxplot((X,Y,data_['占有率'].astype('float64'),data_['好评率'].astype('float64'),y3.astype('float64')),\ 269 labels=("品牌","评分","占有率","好评率","种类")) 270 plt.title("各数据的盒图情况") 271 plt.savefig('E:/图片/8') 272 plt.show() 273 274 print("--------所有图形已绘制完成--------\n") 275 276 print("--------所有图形已保存完成--------\n") 277 print("--------图形保存路径为: E:图片--------\n") 278 #数据保存 279 280 print("--------开始保存数据--------\n") 281 #将品牌链接增加到data1数据中 282 data1['品牌链接']=link 283 #将品牌商标链接增加到data1数据中 284 data1['品牌商标链接']=brand 285 #创建Excel表并写入数据 286 #创建文件名 287 wb ='E:\\2021年手机品牌排行榜.xlsx' 288 #将数据保存 289 data1.to_excel(wb) 290 291 print("--------数据保存已完成--------\n") 292 print("--------数据保存保存路径为: E:年手机品牌排行榜--------\n") 293 294 if __name__ == '__main__': 295 soup=getHTMLText() 296 data_analysis(soup)
五、总结
通过以上的分析,可以发现vivo手机的好评度是最高的;可以看出国产手机越来越受大家的喜爱;人们在注重手机品牌的同时,同时也会选择价格相对优惠的手机。通过以上的分析达到了预期的目标。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号