第三次作业
作业①:
要求:指定一个网站,爬取这个网站中的所有的所有图片,例如:中国气象网(http://www.weather.com.cn)。实现单线程和多线程的方式爬取。
–务必控制总页数(学号尾数2位)、总下载的图片数量(尾数后3位)等限制爬取的措施。
输出信息: 将下载的Url信息在控制台输出,并将下载的图片存储在images子文件中,并给出截图。
作业代码
单线程方式爬取
import requests
from bs4 import BeautifulSoup
import os
import time
def single_thread_crawler():
# 创建保存图片的文件夹
if not os.path.exists('images'):
os.makedirs('images')
# 爬取32页,总共132张图片
total_pages = 32
total_images = 132
images_per_page = total_images // total_pages
downloaded_count = 0
print("开始单线程爬取图片...")
print(f"计划爬取 {total_pages} 页,总共 {total_images} 张图片")
print("=" * 50)
for page in range(1, total_pages + 1):
print(f"正在爬取第 {page} 页...")
# 构建URL
if page == 1:
url = "http://www.weather.com.cn/weather/101010100.shtml"
else:
url = "http://www.weather.com.cn/weather/101020100.shtml"
try:
# 发送请求
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36'
}
response = requests.get(url, headers=headers, timeout=10)
response.encoding = 'utf-8'
# 解析HTML
soup = BeautifulSoup(response.text, 'html.parser')
images = soup.find_all('img')
page_downloaded = 0
for img in images:
if downloaded_count >= total_images:
break
img_url = img.get('src')
if img_url:
# 处理相对URL
if img_url.startswith('//'):
img_url = 'http:' + img_url
elif img_url.startswith('/'):
img_url = 'http://www.weather.com.cn' + img_url
# 下载常见的图片格式
if any(img_url.lower().endswith(ext) for ext in ['.jpg', '.jpeg', '.png', '.gif']):
try:
# 下载图片
img_response = requests.get(img_url, headers=headers, timeout=10)
# 生成文件名
filename = f"image_{downloaded_count + 1:03d}.jpg"
filepath = os.path.join('images', filename)
# 保存图片
with open(filepath, 'wb') as f:
f.write(img_response.content)
downloaded_count += 1
page_downloaded += 1
print(f"下载成功: {img_url}")
print(f"保存为: {filepath}")
# 控制下载速度,避免请求过快
time.sleep(0.5)
except Exception as e:
print(f"下载图片失败: {img_url}, 错误: {e}")
print(f"第 {page} 页下载完成,本页下载了 {page_downloaded} 张图片")
except Exception as e:
print(f"爬取第 {page} 页失败: {e}")
print("-" * 30)
print("=" * 50)
print(f"爬取完成!总共下载了 {downloaded_count} 张图片")
print(f"图片保存在: {os.path.abspath('images')} 文件夹中")
if __name__ == "__main__":
single_thread_crawler()
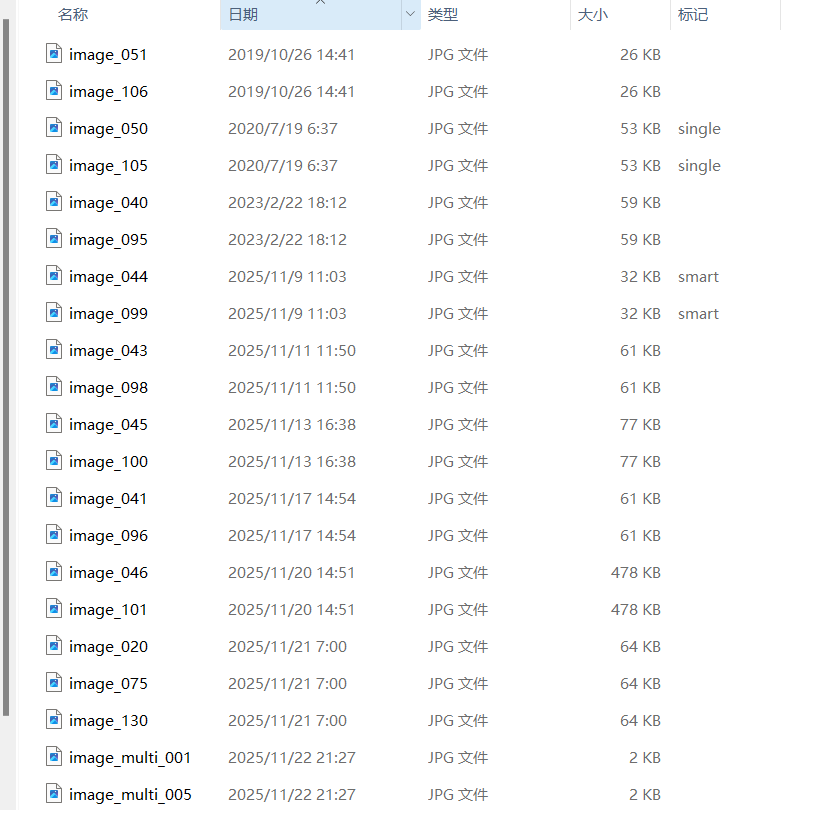
查看结果
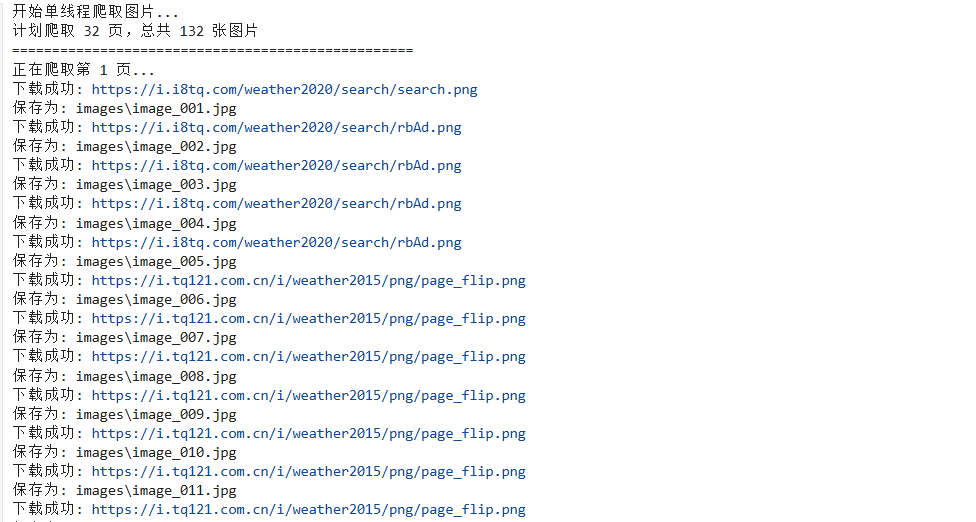

在文件夹中查看爬取的文件
多线程方式爬取
import requests
from bs4 import BeautifulSoup
import os
import threading
import time
from concurrent.futures import ThreadPoolExecutor
class MultiThreadCrawler:
def __init__(self):
self.downloaded_count = 0
self.lock = threading.Lock()
self.total_images = 132
self.total_pages = 32
def download_image(self, img_url, img_num):
try:
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36'
}
img_response = requests.get(img_url, headers=headers, timeout=10)
filename = f"image_multi_{img_num:03d}.jpg"
filepath = os.path.join('images', filename)
with open(filepath, 'wb') as f:
f.write(img_response.content)
with self.lock:
self.downloaded_count += 1
print(f"线程 {threading.current_thread().name} 下载成功: {img_url}")
print(f"保存为: {filepath}")
except Exception as e:
print(f"下载图片失败: {img_url}, 错误: {e}")
def crawl_page(self, page):
print(f"线程 {threading.current_thread().name} 正在爬取第 {page} 页...")
if page == 1:
url = "http://www.weather.com.cn/weather/101010100.shtml"
else:
url = "http://www.weather.com.cn/weather/101020100.shtml"
try:
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36'
}
response = requests.get(url, headers=headers, timeout=10)
response.encoding = 'utf-8'
soup = BeautifulSoup(response.text, 'html.parser')
images = soup.find_all('img')
img_urls = []
for img in images:
if len(img_urls) >= (self.total_images // self.total_pages):
break
img_url = img.get('src')
if img_url:
if img_url.startswith('//'):
img_url = 'http:' + img_url
elif img_url.startswith('/'):
img_url = 'http://www.weather.com.cn' + img_url
if any(img_url.lower().endswith(ext) for ext in ['.jpg', '.jpeg', '.png', '.gif']):
img_urls.append(img_url)
# 使用线程池下载图片
with ThreadPoolExecutor(max_workers=5) as executor:
start_num = (page - 1) * (self.total_images // self.total_pages) + 1
for i, img_url in enumerate(img_urls):
if self.downloaded_count < self.total_images:
executor.submit(self.download_image, img_url, start_num + i)
time.sleep(0.2) # 控制请求频率
print(f"第 {page} 页爬取完成")
except Exception as e:
print(f"爬取第 {page} 页失败: {e}")
def run(self):
# 创建保存图片的文件夹
if not os.path.exists('images'):
os.makedirs('images')
print("开始多线程爬取图片...")
print(f"计划爬取 {self.total_pages} 页,总共 {self.total_images} 张图片")
print("=" * 50)
# 使用线程池爬取页面
with ThreadPoolExecutor(max_workers=2) as executor:
executor.map(self.crawl_page, range(1, self.total_pages + 1))
print("=" * 50)
print(f"爬取完成!总共下载了 {self.downloaded_count} 张图片")
print(f"图片保存在: {os.path.abspath('images')} 文件夹中")
def multi_thread_crawler():
crawler = MultiThreadCrawler()
crawler.run()
if __name__ == "__main__":
multi_thread_crawler()
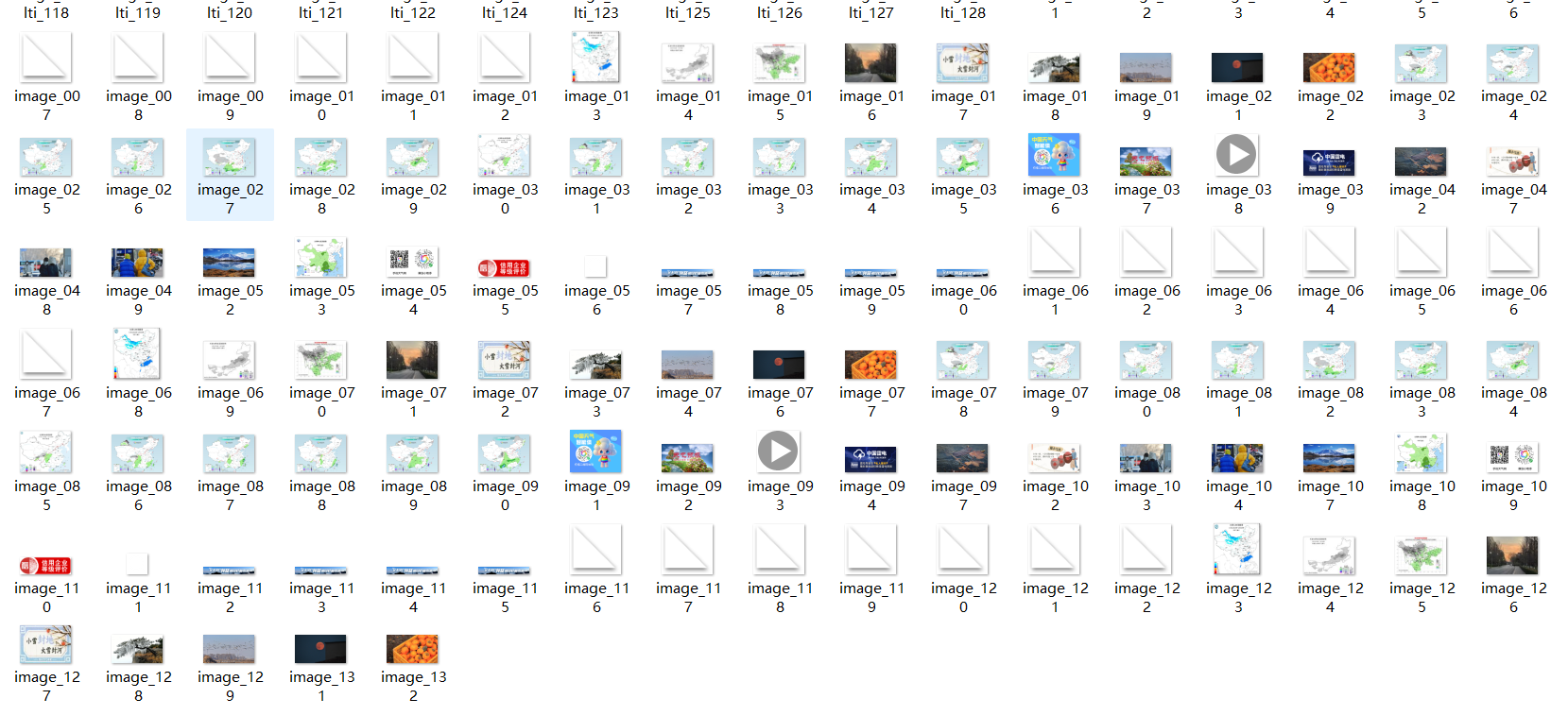
运行结果


在文件夹中查看下载的图片
心得体会
通过完成中国气象网图片爬取任务,我对网络爬虫有了更深入的认识。单线程爬虫虽然编写简单、稳定性高,但在处理大量数据时效率明显不足;而多线程爬虫通过并发执行显著提升了下载速度,但也带来了线程安全、资源竞争等复杂问题。在实践中,我学会了使用线程锁来确保数据一致性,通过线程池管理并发数量,并掌握了控制请求频率的重要性,避免对目标网站造成过大压力
Gitee文件夹链接
https://gitee.com/chenming333/chenmingproject/blob/master/作业3/1单线程.py
https://gitee.com/chenming333/chenmingproject/blob/master/作业3/1.多线程.py
作业②
要求:熟练掌握 scrapy 中 Item、Pipeline 数据的序列化输出方法;使用scrapy框架+Xpath+MySQL数据库存储技术路线爬取股票相关信息。
候选网站:东方财富网:https://www.eastmoney.com/
输出信息:MySQL数据库存储和输出格式如下:
表头英文命名例如:序号id,股票代码:bStockNo……,由同学们自行定义设计
| 序号 | 股票代码 | 股票名称 | 最新报价 | 涨跌幅 | 涨跌额 | 成交量 | 振幅 | 最高 | 最低 | 今开 | 昨收 |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | 688093 | N世华 | 28.47 | 10.92 | 26.13万 | 7.6亿 | 22.34 | 32.0 | 28.08 | 30.20 | 17.55 |
| 2…… |
作业代码
eastmoney.py
import scrapy
from stock_crawler.items import StockItem
import json
import re
class EastmoneySpider(scrapy.Spider):
name = 'eastmoney'
allowed_domains = ['push2.eastmoney.com', 'quote.eastmoney.com']
def start_requests(self):
api_url = "http://push2.eastmoney.com/api/qt/clist/get?fid=f3&fs=m:0+t:6,m:0+t:80,m:1+t:2,m:1+t:23&fields=f1,f2,f3,f4,f5,f6,f7,f8,f9,f10,f12,f13,f14,f15,f16,f17,f18,f20,f21,f23,f24,f25,f22,f11,f62,f128,f136,f115,f152&pn=1&pz=50"
yield scrapy.Request(url=api_url, callback=self.parse_api, headers={
'Referer': 'http://quote.eastmoney.com/',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36'
})
def parse_api(self, response):
print("通过API接口获取实时股票数据...")
print(f"响应状态: {response.status}")
try:
data = json.loads(response.text)
if 'data' not in data or 'diff' not in data['data']:
print("API返回数据格式异常,尝试备用方案...")
yield from self.parse_backup_page(response)
return
stocks = data['data']['diff']
total = data['data']['total']
print(f"API返回 {total} 条股票数据,正在解析前20条...")
count = 0
for stock_id, stock_data in stocks.items():
if count >= 20:
break
try:
item = StockItem()
item['id'] = count + 1
# 解析股票数据
item['stock_code'] = stock_data.get('f12', '') # 股票代码
item['stock_name'] = stock_data.get('f14', '') # 股票名称
# 最新价
current_price = stock_data.get('f2', 0)
item['current_price'] = f"{current_price:.2f}" if current_price else '0.00'
# 涨跌幅
change_percent = stock_data.get('f3', 0)
item['change_percent'] = f"{change_percent:.2f}%" if change_percent else '0.00%'
# 涨跌额
change_amount = stock_data.get('f4', 0)
item['change_amount'] = f"{change_amount:.2f}" if change_amount else '0.00'
# 成交量(转换为万手)
volume = stock_data.get('f5', 0)
if volume > 0:
item['volume'] = f"{volume/10000:.2f}万手"
else:
item['volume'] = "0.00万手"
# 振幅
amplitude = stock_data.get('f7', 0)
item['amplitude'] = f"{amplitude:.2f}%" if amplitude else '0.00%'
# 最高价
high = stock_data.get('f15', 0)
item['high'] = f"{high:.2f}" if high else '0.00'
# 最低价
low = stock_data.get('f16', 0)
item['low'] = f"{low:.2f}" if low else '0.00'
# 今开
open_price = stock_data.get('f17', 0)
item['open_price'] = f"{open_price:.2f}" if open_price else '0.00'
# 昨收
close_price = stock_data.get('f18', 0)
item['close_price'] = f"{close_price:.2f}" if close_price else '0.00'
# 验证数据有效性
if item['stock_code'] and item['stock_name'] and item['stock_code'] != '0':
count += 1
yield item
print(f"解析成功: {item['stock_name']}({item['stock_code']}) - 价格: {item['current_price']}")
except Exception as e:
print(f"解析单条股票数据失败: {e}")
continue
print(f"成功解析 {count} 条实时股票数据")
except Exception as e:
print(f"解析API数据失败: {e}")
yield from self.parse_html_page()
def parse_backup_page(self, response):
"""备用解析方案:直接解析网页"""
print("尝试解析网页HTML...")
print("网页解析暂未实现,主要依赖API接口")
def parse_html_page(self):
"""直接请求网页并解析"""
print("尝试直接请求网页...")
url = "http://quote.eastmoney.com/center/gridlist.html"
yield scrapy.Request(url=url, callback=self.parse_real_html, headers={
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36',
'Referer': 'http://quote.eastmoney.com/'
})
def parse_real_html(self, response):
"""解析真实网页内容"""
print("开始解析网页内容...")
# 尝试多种选择器
selectors = [
'//table[contains(@class, "table")]//tr',
'//div[contains(@class, "list")]//tr',
'//tbody//tr'
]
for selector in selectors:
rows = response.xpath(selector)
if rows:
print(f"使用选择器 '{selector}' 找到 {len(rows)} 行数据")
break
else:
print("未找到股票数据行")
return
count = 0
for i, row in enumerate(rows[:20]):
try:
# 提取各列数据
cells = row.xpath('./td//text()').getall()
if len(cells) >= 10:
item = StockItem()
item['id'] = count + 1
item['stock_code'] = cells[0].strip() if len(cells) > 0 else ''
item['stock_name'] = cells[1].strip() if len(cells) > 1 else ''
item['current_price'] = cells[2].strip() if len(cells) > 2 else ''
item['change_percent'] = cells[3].strip() if len(cells) > 3 else ''
item['change_amount'] = cells[4].strip() if len(cells) > 4 else ''
item['volume'] = cells[5].strip() if len(cells) > 5 else ''
item['amplitude'] = cells[6].strip() if len(cells) > 6 else ''
item['high'] = cells[7].strip() if len(cells) > 7 else ''
item['low'] = cells[8].strip() if len(cells) > 8 else ''
item['open_price'] = cells[9].strip() if len(cells) > 9 else ''
item['close_price'] = cells[10].strip() if len(cells) > 10 else ''
if item['stock_code'] and item['stock_name']:
count += 1
yield item
print(f"网页解析成功: {item['stock_name']}({item['stock_code']})")
except Exception as e:
print(f"解析网页行数据失败: {e}")
continue
print(f"网页解析完成,共 {count} 条数据")
items.py
import scrapy
class StockItem(scrapy.Item):
id = scrapy.Field() # 序号
stock_code = scrapy.Field() # 股票代码
stock_name = scrapy.Field() # 股票名称
current_price = scrapy.Field() # 最新报价
change_percent = scrapy.Field() # 涨跌幅
change_amount = scrapy.Field() # 涨跌额
volume = scrapy.Field() # 成交量
amplitude = scrapy.Field() # 振幅
high = scrapy.Field() # 最高
low = scrapy.Field() # 最低
open_price = scrapy.Field() # 今开
close_price = scrapy.Field() # 昨收
pipeline.py
import sqlite3
class StockCrawlerPipeline:
def __init__(self):
self.con = None
self.cursor = None
def open_spider(self, spider):
# 爬虫启动时打开数据库
self.openDB()
def close_spider(self, spider):
# 爬虫结束时关闭数据库并显示数据
self.show()
self.closeDB()
def openDB(self):
# 连接SQLite数据库
self.con = sqlite3.connect("stocks.db")
self.cursor = self.con.cursor()
try:
# 创建股票数据表,设置股票代码为主键
self.cursor.execute("""
create table stocks (
id integer primary key,
stock_code varchar(16),
stock_name varchar(32),
current_price varchar(16),
change_percent varchar(16),
change_amount varchar(16),
volume varchar(16),
amplitude varchar(16),
high varchar(16),
low varchar(16),
open_price varchar(16),
close_price varchar(16)
)
""")
print("数据库表创建成功")
except:
# 如果表已存在,则清空表中的数据
self.cursor.execute("delete from stocks")
print("清空已有数据")
def closeDB(self):
# 关闭数据库连接
if self.con:
self.con.commit()
self.con.close()
print("数据库连接已关闭")
def process_item(self, item, spider):
# 向数据库插入股票数据
self.insert(
item['id'],
item['stock_code'],
item['stock_name'],
item['current_price'],
item['change_percent'],
item['change_amount'],
item['volume'],
item['amplitude'],
item['high'],
item['low'],
item['open_price'],
item['close_price']
)
return item
def insert(self, id, stock_code, stock_name, current_price, change_percent, change_amount, volume, amplitude, high, low, open_price, close_price):
# 向数据库插入股票数据
try:
self.cursor.execute(
"insert into stocks (id, stock_code, stock_name, current_price, change_percent, change_amount, volume, amplitude, high, low, open_price, close_price) values (?,?,?,?,?,?,?,?,?,?,?,?)",
(id, stock_code, stock_name, current_price, change_percent, change_amount, volume, amplitude, high, low, open_price, close_price)
)
print(f"插入成功: {stock_name}({stock_code})")
except Exception as err:
print(f"插入数据失败: {err}")
def show(self):
# 显示数据库中的所有股票数据
try:
self.cursor.execute("select * from stocks order by id")
results = self.cursor.fetchall()
print("\n" + "="*150)
print("SQLite数据库存储数据如下:")
print("="*150)
print("| 序号 | 股票代码 | 股票名称 | 最新报价 | 涨跌幅 | 涨跌额 | 成交量 | 振幅 | 最高 | 最低 | 今开 | 昨收 |")
print("|" + "-"*149 + "|")
for row in results:
print(f"| {row[0]:<4} | {row[1]:<10} | {row[2]:<8} | {row[3]:<8} | {row[4]:<8} | {row[5]:<10} | {row[6]:<8} | {row[7]:<8} | {row[8]:<8} | {row[9]:<8} | {row[10]:<8} | {row[11]:<8} |")
print("="*150)
print(f"总共存储了 {len(results)} 条股票数据")
print(f"数据库文件: stocks.db")
except Exception as err:
print(f"查询数据失败: {err}")
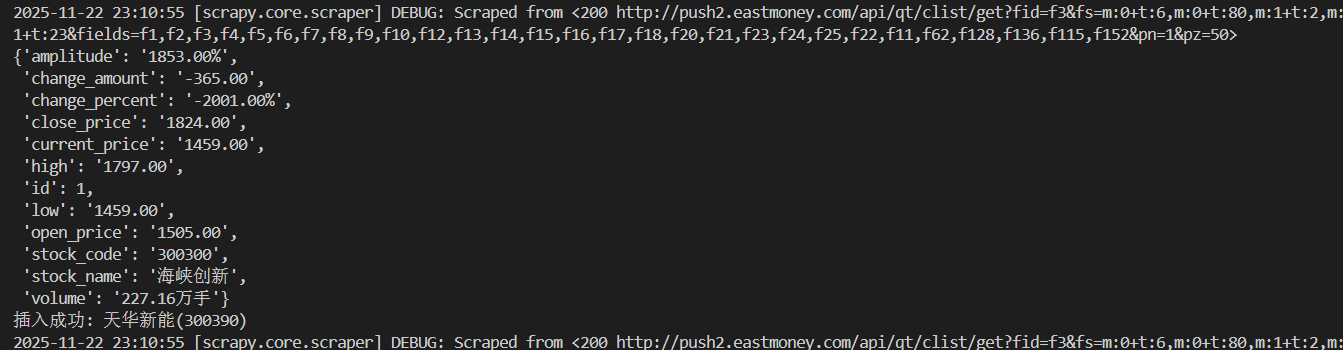
运行过程及结果
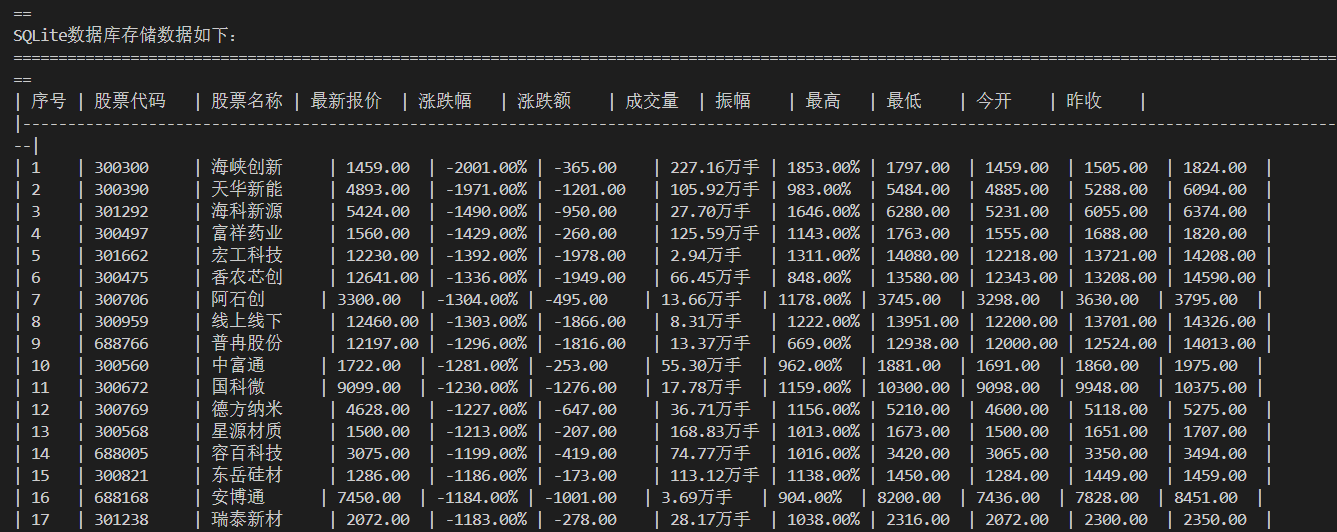
心得体会
在爬取东方财富网股票数据的过程中,我遇到了网站反爬机制、页面结构变化、数据解析困难等诸多挑战。通过分析网络请求、调整请求头、使用API接口等方式,我学会了如何应对这些实际问题。
Gitee文件夹链接
https://gitee.com/chenming333/chenmingproject/blob/master/作业3/2.eastmoney.py
https://gitee.com/chenming333/chenmingproject/blob/master/作业3/2.items.py
https://gitee.com/chenming333/chenmingproject/blob/master/作业3/2.pipiline.py
作业③:
要求:熟练掌握 scrapy 中 Item、Pipeline 数据的序列化输出方法;使用scrapy框架+Xpath+MySQL数据库存储技术路线爬取外汇网站数据。
候选网站:中国银行网:https://www.boc.cn/sourcedb/whpj/
输出信息:
| Currency | TBP | CBP | TSP | CSP | Time |
|---|---|---|---|---|---|
| 阿联酋迪拉姆 | 198.58 | 192.31 | 199.98 | 206.59 | 11:27:14 |
作业代码
boc.py
import scrapy
from boc_forex.items import ForexItem
class BocSpider(scrapy.Spider):
name = 'boc'
allowed_domains = ['www.boc.cn']
start_urls = ['https://www.boc.cn/sourcedb/whpj/']
def parse(self, response):
print("开始解析中国银行外汇数据...")
# 查找外汇数据表格
table = response.xpath('//table')
if not table:
print("未找到数据表格")
return
# 获取表格中的所有行(跳过表头)
rows = table.xpath('.//tr')[1:] # 跳过第一行表头
count = 0
for row in rows:
try:
# 提取每列数据
columns = row.xpath('./td//text()').getall()
if len(columns) >= 7: # 确保有足够的数据列
item = ForexItem()
item['currency'] = columns[0].strip() if columns[0] else '' # 货币名称
item['tbp'] = columns[1].strip() if len(columns) > 1 else '' # 现汇买入价
item['cbp'] = columns[2].strip() if len(columns) > 2 else '' # 现钞买入价
item['tsp'] = columns[3].strip() if len(columns) > 3 else '' # 现汇卖出价
item['csp'] = columns[4].strip() if len(columns) > 4 else '' # 现钞卖出价
item['time'] = columns[6].strip() if len(columns) > 6 else '' # 发布时间
# 验证数据完整性
if (item['currency'] and item['tbp'] and item['tsp'] and
item['currency'] != '货币名称'):
count += 1
yield item
print(f"解析成功: {item['currency']} - 现汇买入: {item['tbp']}")
except Exception as e:
print(f"解析行数据失败: {e}")
continue
print(f"成功解析 {count} 条外汇数据")
def start_requests(self):
# 添加请求头,避免被反爬
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36',
'Referer': 'https://www.boc.cn/sourcedb/whpj/',
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,*/*;q=0.8'
}
for url in self.start_urls:
yield scrapy.Request(url, headers=headers, callback=self.parse)
items.py
import scrapy
class ForexItem(scrapy.Item):
currency = scrapy.Field() # 货币名称
tbp = scrapy.Field() # 现汇买入价
cbp = scrapy.Field() # 现钞买入价
tsp = scrapy.Field() # 现汇卖出价
csp = scrapy.Field() # 现钞卖出价
time = scrapy.Field() # 发布时间
pipeline.py
import sqlite3
class BocForexPipeline:
def __init__(self):
self.con = None
self.cursor = None
def open_spider(self, spider):
self.openDB()
def close_spider(self, spider):
self.show()
self.closeDB()
def openDB(self):
self.con = sqlite3.connect("forex.db")
self.cursor = self.con.cursor()
try:
self.cursor.execute("""
create table forex_rates (
id integer primary key autoincrement,
currency varchar(32),
tbp varchar(16),
cbp varchar(16),
tsp varchar(16),
csp varchar(16),
time varchar(16),
crawl_time timestamp default current_timestamp
)
""")
print("外汇数据表创建成功")
except:
self.cursor.execute("delete from forex_rates")
print("清空已有数据")
def closeDB(self):
if self.con:
self.con.commit()
self.con.close()
print("数据库连接已关闭")
def process_item(self, item, spider):
self.insert(
item['currency'],
item['tbp'],
item['cbp'],
item['tsp'],
item['csp'],
item['time']
)
return item
def insert(self, currency, tbp, cbp, tsp, csp, time):
try:
self.cursor.execute(
"insert into forex_rates (currency, tbp, cbp, tsp, csp, time) values (?,?,?,?,?,?)",
(currency, tbp, cbp, tsp, csp, time)
)
print(f"插入成功: {currency}")
except Exception as err:
print(f"插入数据失败: {err}")
def show(self):
try:
self.cursor.execute("select * from forex_rates order by id")
results = self.cursor.fetchall()
print("\n" + "="*100)
print("外汇数据存储结果:")
print("="*100)
print("| Currency | TBP | CBP | TSP | CSP | Time |")
print("|" + "-"*99 + "|")
for row in results:
print(f"| {row[1]:<14} | {row[2]:<6} | {row[3]:<6} | {row[4]:<6} | {row[5]:<6} | {row[6]:<9} |")
print("="*100)
print(f"总共存储了 {len(results)} 条外汇数据")
print(f"数据库文件: forex.db")
except Exception as err:
print(f"查询数据失败: {err}")
运行过程及结果
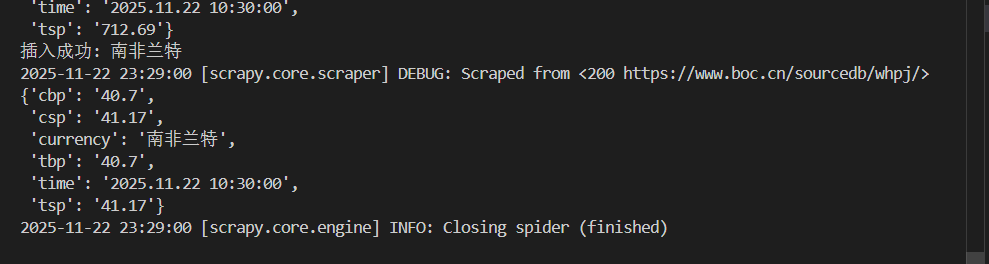
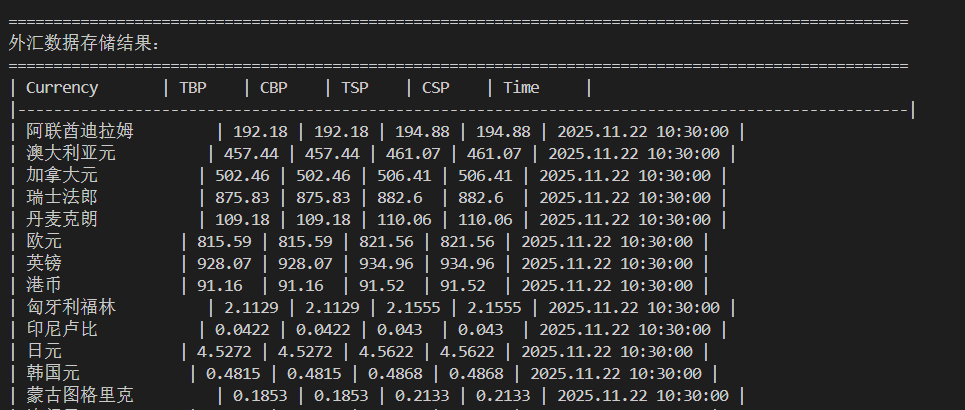
心得体会
通过这次外汇数据爬取实践,我熟练掌握了Scrapy框架中Item和Pipeline的配合使用,学会了用XPath精准提取网页表格数据,并实现了数据到SQLite数据库的自动化存储。整个过程加深了我对爬虫数据流和结构化数据处理的理解。
Gitee文件夹链接
https://gitee.com/chenming333/chenmingproject/blob/master/作业3/3.boc.py
https://gitee.com/chenming333/chenmingproject/blob/master/作业3/3.items.py
https://gitee.com/chenming333/chenmingproject/blob/master/作业3/3.pipeline.py

 浙公网安备 33010602011771号
浙公网安备 33010602011771号