
20211302陈琳福 实验4 Python综合实践
#20211302陈琳福 实验4 Python综合实践
##1实验内容
Python综合应用:爬虫、数据处理、可视化、机器学习、神经网络、游戏、网络安全等。
## 2. 实验过程及结果
(1)实验设计
1 功能
获取新闻页面的信息,提取其中的时间、标题、网址信息打印输出信息。
2 目标网站的 robots协议
在网站的根目录下查看网站的 robots协议,该网站对网络爬虫没有限制。
3 目标网站分析

网址:https://www.phei.com.cn/xwxx/index.shtml
查看网页源代码:查看网页源代码,可以看到相关信息都保存在html页面中。
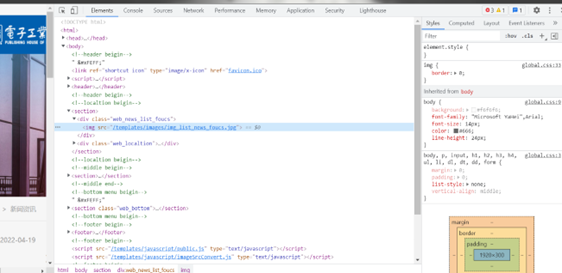
目标信息均保存的HTML页面中
4 结构设计
技术路线:Requests-BeautifulSoup
- Requests 自动网络url请求提交,循环获得html页面
- BeautifulSoup解析每个HTML页面,提取目标信息
- 打印输出信息到屏幕
(2)实现过程
1 Requests获得html页面
使用Requests通用框架,提交url请求,获取网页内容。
获取网页源代码
def getHTMLText(url):
try:
headers = {'User-Agent':"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.114 Safari/537.36"}
r = requests.get(url, timeout=30, headers=headers,allow_redirects=False)
print(r.status_code)
r.raise_for_status() # 如果状态不是200,引发HTTPError异常
r.encoding = r.apparent_encoding
#print(r.text[1000:2000])
return r.text
except:
print("网页访问异常!")
2 构造所有页面的url地址
https://www.phei.com.cn/xwxx/index.shtml #首页地址
https://www.phei.com.cn/xwxx/index_54.shtml #第1页地址
https://www.phei.com.cn/xwxx/index_53.shtml #第2页地址
……
https://www.phei.com.cn/xwxx/index_1.shtml #最后1页地址
定义get_urls()函数,构造所有分页url地址:
def get_urls(pages):
urls = ['https://www.phei.com.cn/xwxx/index.shtml']
for i in range(1,pages):
page = 55-i
url = "https://www.phei.com.cn/xwxx/index_{}.shtml".format(page)
urls.append(url)
#print(urls)
return urls
3 BeautifulSoup解析html页面提取信息
使用bs4的".find_all()"方法可以定位到信息位置:
def parsePage(html):
soup = BeautifulSoup(html, 'html.parser')
#for tag in soup.find_all(True):
#print(tag.name)
p = soup.find_all('li','li_b60')
#print(p)
print(len(p))
for i in range(len(p)):
print(i)
text = p[i]
#print(text.prettify())
利用find_all()对定位到的信息进一步准确地提取:
#bs4提取信息
def parsePage(html):
soup = BeautifulSoup(html, 'html.parser')
#for tag in soup.find_all(True):
#print(tag.name)
p = soup.find_all('li','li_b60')
#print(p)
print(len(p))
for i in range(len(p)):
print(i)
text = p[i]
#print(text.prettify()) #美观地打印标签树
#获得新闻时间
time = text.find_all('span')
print(time)
#获得新闻标题
title = text.find_all('p','li_news_title')
print(title)
#获得新闻网址
for link in text.find_all('a'):
link_part = link.get('href')
print(link_part)
4 构造循环获取html及处理主程序
pages = 2 #输入页面数量 urls = get_urls(pages) #调用get_urls()函数构造url地址 for url in urls: #循环获得页面并进行处理 print(url) html = getHTMLText(url) #获得网页源代码 parsePage(html) #解析提取网页信息
总代码:
import requests
from bs4 import BeautifulSoup
#获取网面源代码
def getHTMLText(url):
try:
headers = {'User-Agent':"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.114 Safari/537.36"}
r = requests.get(url, timeout=30, headers=headers,allow_redirects=False)
print(r.status_code)
r.raise_for_status() # 如果状态不是200,引发HTTPError异常
r.encoding = r.apparent_encoding
#print(r.text[1000:2000])
return r.text
except:
print("网页访问异常!")
#bs4提取信息
def parsePage(html):
soup = BeautifulSoup(html, 'html.parser')
#for tag in soup.find_all(True):
#print(tag.name)
p = soup.find_all('li','li_b60')
#print(p)
print(len(p))
for i in range(len(p)):
print(i)
text = p[i]
#print(text.prettify()) #美观地打印标签树
#获得新闻时间
time = text.find_all('span')
time_bs = BeautifulSoup(str(time), 'html.parser')
time_text = time_bs.get_text()
print(time_text)
#获得新闻标题
title = text.find_all('p','li_news_title')
title_bs = BeautifulSoup(str(title), 'html.parser')
title_text = title_bs.get_text()
print(title_text)
#获得新闻网址
for link in text.find_all('a'):
link_part = link.get('href')
html_url = 'https://www.phei.com.cn'+str(link_part)
print(html_url)
def get_urls(pages):
urls = ['https://www.phei.com.cn/xwxx/index.shtml']
for i in range(1,pages):
page = 55-i
url = "https://www.phei.com.cn/xwxx/index_{}.shtml".format(page)
urls.append(url)
#print(urls)
return urls
pages = 3
urls = get_urls(pages)
for url in urls:
print(url)
html = getHTMLText(url) #获得网页源代码
parsePage(html) #解析提取网页信息
##3课程总结及感想
(1)课程总结
第1课 初识Python
Python 是一种简单易学并且结合了解释性、编译性、互动性和面向对象的脚本语言。Python提供了高级数据结构,它的语法和动态类型以及解释性使它成为广大开发者的首选编程语言。
-
Python 是解释型语言: 开发过程中没有了编译这个环节。类似于PHP和Perl语言。
-
Python 是交互式语言: 可以在一个 Python 提示符 >>> 后直接执行代码。
-
Python 是面向对象语言: Python支持面向对象的风格或代码封装在对象的编程技术。
Python是一种面向对象oop的脚本语言。
面向对象是采用基于对象(实体)的概念建立模型,模拟客观世界分析、设计、实现软件的办法。面向对象的方法把数据和方法组合成一个整体,然后对其进行
系统建模。python编程思想的核心就是理解功能逻辑。
第2课 Pyhton语言基础
运算符:

缩进:
缩进是针对逻辑行的,因此首先要区分代码中的物理行和逻辑行。
- 物理行:代码编辑器中显示的代码,每一行是一个物理行。
- 逻辑行:Python解释器对代码进行解释,一个语句是一个逻辑行。
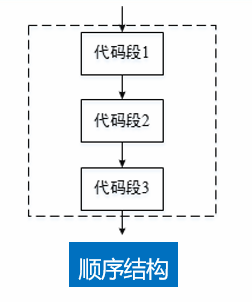
第3课 流程控制语句
- 顺序结构
- 条件和分支
单分支:

双分支:

多分支:

- 循环
while循环:

for循环:

第4课 序列的应用
列表、字典、集合。
第5课 字符串与正则表达式
Python 字符串是 Python 内置的一种数据类型,在 Python 中,用引号来表示字符串,例如 双引号 ",单引号 '。
字符串输出例子:
tang_hu_lu = "都说冰糖葫芦儿酸" # 声明字符串 print(tang_hu_lu) # 打印输出字符串 print(tang_hu_lu[2:4]) # 输出冰糖 print(tang_hu_lu[3:5]) # 输出糖葫
第6课 函数
在程序设计中,函数的使用可以提升代码的复用率和可维护性。
提升复用率: 程序设计中,一些代码的功能是相同的,操作是一样的,只不过针对的数据不一样。此种情况下,可以将这种功能写成一个函数模块,要使用此功能时只需调用这个函数模块就可以了。
提升可维护性: 使用函数后,实现了代码的复用,某个功能需要核查或修改时,只需要核查或修改此功能相对应的函数就可以了。对功能的修改可以使调用该函数的所有模块同时生效,极大提升了代码的可维护性。
一般格式如下:
def 函数名(参数列表):
函数体
-
形参(parameter),全称为"形式参数",不是实际存在的变量,又称虚拟变量。形参是在定义函数名和函数体的时候使用的参数,目的是用来接收调用该函数时传入的参数。 -
实参(argument),全称为"实际参数",是在调用时传递给函数的参数。实参可以是常量、变量、表达式、函数等。无论实参是何种类型的量,在进行函数调用时,它们都必须具有确定的值,以便把这些值传送给形参。
第7课 面向对象程序设计
面向对象:是把一组数据结构和处理他们的方法组成对象,把具有相同行为的对象归纳成类,通过封装隐藏类的内部细节,通过继承使类得到泛化,通过多态实现基于对象类型的动态分类。
类:表示一组(或一类)对象,每个对象都属于特定的类,并被称为该类的实例。在面向对象编程中,你编写表示现实世界中的事物和情景的类,并基于这些类来创建对象。编写类时,你定义一大类对象都有的通用行为。基于类创建 对象时,每个对象都自动具备这种通用行为,然后可根据需要赋予每个对象独特的个性。根据类来创建对象被称为 实例化,这让你能够使用类的实例。在面向对象编程中,术语对象大致意味着一系列数据(属性)以及一套访问和操作这些数据的方法;对象由属性和方法组成。属性不过是属于对象的变量,而方法是存储在属性中的函数。
类的成员主要包括:字段 方法 属性
面向对象三要素
- 封装:通常认为封装是把数据和操作数据的方法绑定起来,对数据的访问只能通过已定义的接口。
- 继承:继承是从已有类得到继承信息创建新类的过程。提供继承信息的类被称为父类(超类、基类);得到继承信息的类被称为子类(派生类)。
- 多态:多态性是指允许不同子类型的对象对同一消息作出不同的响应。简单的说就是用同样的对象引用调用同样的方法但是做了不同的事情。
第8课 文件操作及异常处理
python读取文件:
Python 在读写文件的时候首先要做的是打开文件,然后可以一次性读取文件或者一行行的读取,打开文件使用 open 函数。
读取文件所有内容使用 open 函数打开文件之后,可以通过 read 读取文件内容,该方法相当于将文件的内容一次性的读取到了程序的一个字符串中,非常强大。
# 文件地址,注意提前在当前目录新建一个 test.txt 文件 file = "test.txt" # 打开文件 f = open(file, encoding="utf-8") # 读取文件全部内容 read_str = f.read() # 关闭文件 f.close() print(read_str)
写入文件:泛指写入到本地硬盘上。
# 文件地址,注意提前在当前目录新建一个 test.txt 文件
file = "test.txt"
# 打开文件
with open(file, mode="w", encoding="utf-8") as f:
# 写入文件内容
f.write("我是即将被写入的内容")
文件复制:使用该模块中 shutil 对象的 copy 方法可以对文件进行复制操作。
import shutil
shutil.copy("test.txt","aaa.txt")
shutil.copy("test.txt","../aaa.txt") # 不同目录拷贝
目录复制:copytree 方法语法格式与 copy 一致,只不过该方法是用来复制目录的,如果目录下面有子目录或文件一起复制。
import shutil
# 第一个参数是旧目录,第二个参数是新目录
shutil.copytree("../1","a4")
第9课 Python操作数据库
目前主流的数据库有两种:
- 一个是关系型数据库,如MySql
- 一个是非关系型数据库 如mongodb
第10课 Python网络编程及爬虫
urllib 模块是 Python 标准库,其价值在于抓取网络上的 URL 资源。
Python3 中 urllib 模块包括如下内容。
urllib.request:请求模块,用于打开和读取 URL;urllib.error:异常处理模块,捕获urllib.error抛出异常;urllib.parse:URL 解析,爬虫程序中用于处理 URL 地址;urllib.robotparser:解析 robots.txt 文件,判断目标站点哪些内容可爬,哪些不可以爬。
Beautiful Soup 是一款 Python 解析库,主要用于将 HTML 标签转换为 Python 对象树,然后让我们从对象树中提取数据。
lxml 库是一款 Python 数据解析库。
requests 库:
url:请求地址;params:要发送的查询字符串,可以为字典,列表,元组,字节;data:body 对象中要传递的参数,可以为字段,列表,元组,字节或者文件对象;json:JSON 序列化对象;headers:请求头,字典格式;cookies:传递 cookie,字段或CookieJar类型;files:最复杂的一个参数,一般出现在POST请求中,格式举例"name":文件对象或者{'name':文件对象},还可以在一个请求中发送多个文件,不过一般爬虫场景不会用到;auth:指定身份验证机制;timeout:服务器等待响应时间,在源码中检索到可以为元组类型,这个之前没有使用过,即(connect timeout, read timeout);allow_redirects:是否允许重定向;proxies:代理;verify:SSL 验证;stream:流式请求,主要对接流式 API;cert:证书。
(2)感想:
python是一门非常有潜力的高级语言,历经多年的发展,其在编程上发挥着越来越大的作用。
由于这学期还学习了C语言,所以我时不时会将python和C语言对比。python相对于c语言也是给程序员极大的便利。而python相较于C语言拥有更多的库,正因为它强大的库,让编程变得不再艰难。python在爬虫等方面的优势更是体现了它的功能强大。python虽然在许多方面相对于c语言比较方便,但也有其相对于弱一点的方面,比如说for循环等方面。虽然一学期下来,我对python的学习也仅仅只是它的基础方面,但python的强大对我仍然产生了强大的吸引力。
一个学期的python学习告一段落,通过选修python课,我对python的知识有了一定了解。由于练习时间有限,有的内容掌握并不牢固,但python的学习不仅仅是这一个阶段,日后还有更多的内容等待着我去学习,我也坚信我对编程的热爱会让我坚持下去。
##4参考

