
0 Intro
Apache Spark is an open source, general-purpose distributed computing engine used for processing and analyzing a large amount of data. Just like Hadoop MapReduce, it also works with the system to distribute data across the cluster and process the data in parallel. Spark uses master/slave architecture. one central coordinator and many distributed workers. Here, the central coordinator is called the driver.
The driver runs in its own Java process. These drivers communicate with a potentially large number of distributed workers called executors. Each executor is a separate java process. A Spark Application is a combination of driver and its own executors. With the help of cluster manager, a Spark Application is launched on a set of machines. Standalone Cluster Manager is the default built in cluster manager of Spark. Apart from its built-in cluster manager, Spark also works with some open source cluster manager like Hadoop Yarn, Apache Mesos etc.
1 Concept
1.1 Cluster Manager
Mesos
YARN
Spark Standalone
1.1.1 Nodes
Master: The machine on which the Driver program runs
Slave: The machine on which the Executor program runs
1.2 Driver
The Driver is one of the nodes in the Cluster.
It plays the role of a master node in the Spark cluster.
separate process to execute user applications
creates SparkContext to schedule jobs execution and negotiate with cluster manager
The driver does not run computations (filter,map, reduce, etc).
When you call collect() on an RDD or Dataset, the whole data is sent to the Driver. This is why you should be careful when calling collect().
1.3 Executor
Executors are JVMs that run on Worker nodes. These are the JVMs that actually run Tasks on data Partitions.
1.4 Job
A job is a sequence of stages, triggered by an action such as .count(), foreachRdd(), collect(), read() or write().
1.5 Stage
Jobs are divided into stages, a Stage is a sequence of Tasks that can all be run together, without a shuffle which devided by wide dependence
For example: using .read to read a file from disk, then runnning .map and .filter can all be done without a shuffle, so it can fit in a single stage.
1.6 Task
A Task is a single operation (.map or .filter) happening on a specific RDD partition.
Each Task is executed as a single thread in an Executor!
If your dataset has 2 Partitions, an operation such as a filter() will trigger 2 Tasks, one for each Partition.
1.7 Shuffle
A Shuffle refers to an operation where data is re-partitioned across a Cluster.
join and any operation that ends with ByKey will trigger a Shuffle.
It is a costly operation because a lot of data can be sent via the network.
1.8 Partition
A Partition is a logical chunk of your RDD/Dataset.
Data is split into Partitions so that each Executor can operate on a single part, enabling parallelization.
It can be processed by a single Executor core.
For example: If you have 4 data partitions and you have 4 executor cores, you can process everything in parallel, in a single pass.
1.9 DAG
DAG stands for Directed Acyclic Graph, in the present context its a DAG of operators.
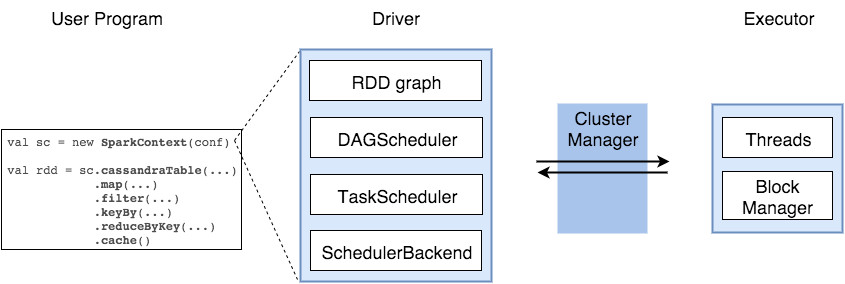
1.10 SparkContext
represents the connection to a Spark cluster, and can be used to create RDDs, accumulators and broadcast variables on that cluster
1.11 DAGScheduler
computes a DAG of stages for each job and submits them to TaskScheduler determines preferred locations for tasks (based on cache status or shuffle files locations) and finds minimum schedule to run the jobs
1.12 TaskScheduler
responsible for sending tasks to the cluster, running them, retrying if there are failures, and mitigating stragglers
1.13 SchedulerBackend
backend interface for scheduling systems that allows plugging in different implementations(Mesos, YARN, Standalone, local)
1.14 BlockManager
provides interfaces for putting and retrieving blocks both locally and remotely into various stores (memory, disk, and off-heap)
2 overview
The first layer is the interpreter, Spark uses a Scala interpreter, with some modifications. As you enter your code in spark console (creating RDD’s and applying operators), Spark creates a operator graph. When the user runs an action (like collect), the Graph is submitted to a DAG Scheduler. The DAG scheduler divides operator graph into (map and reduce) stages. A stage is comprised of tasks based on partitions of the input data. The DAG scheduler pipelines operators together to optimize the graph. For e.g. Many map operators can be scheduled in a single stage. This optimization is key to Sparks performance. The final result of a DAG scheduler is a set of stages. The stages are passed on to the Task Scheduler. The task scheduler launches tasks via cluster manager. (Spark Standalone/Yarn/Mesos). The task scheduler doesn’t know about dependencies among stages.
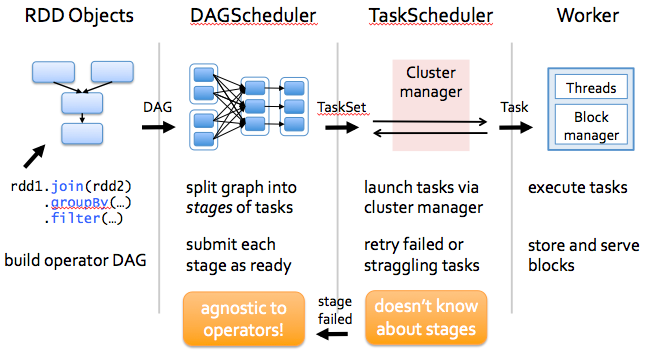
Job execution class which invoked in standalone diagram as follows
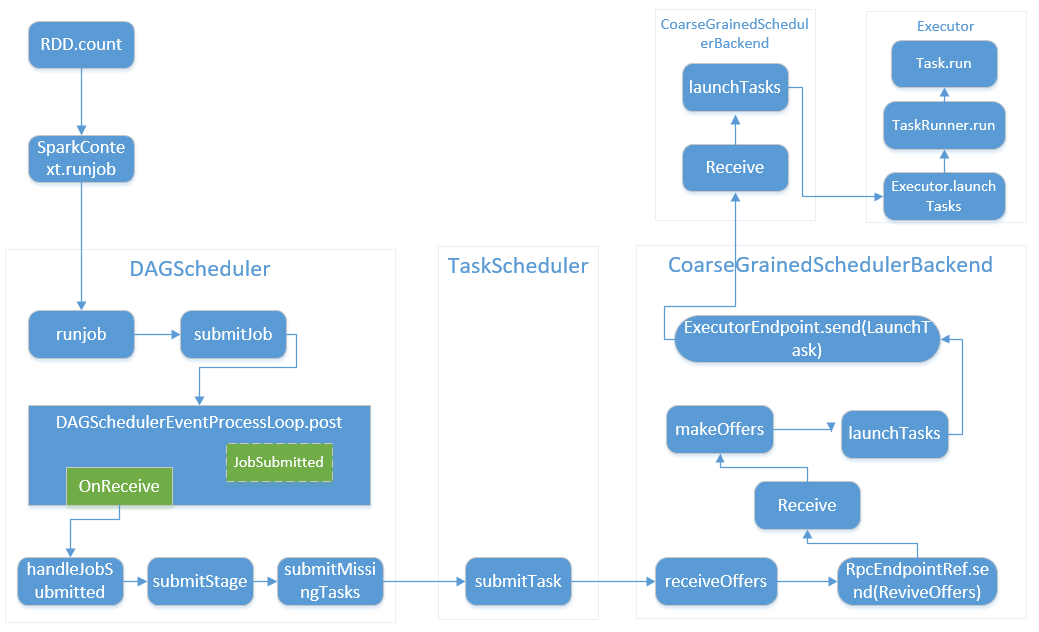
3 submit
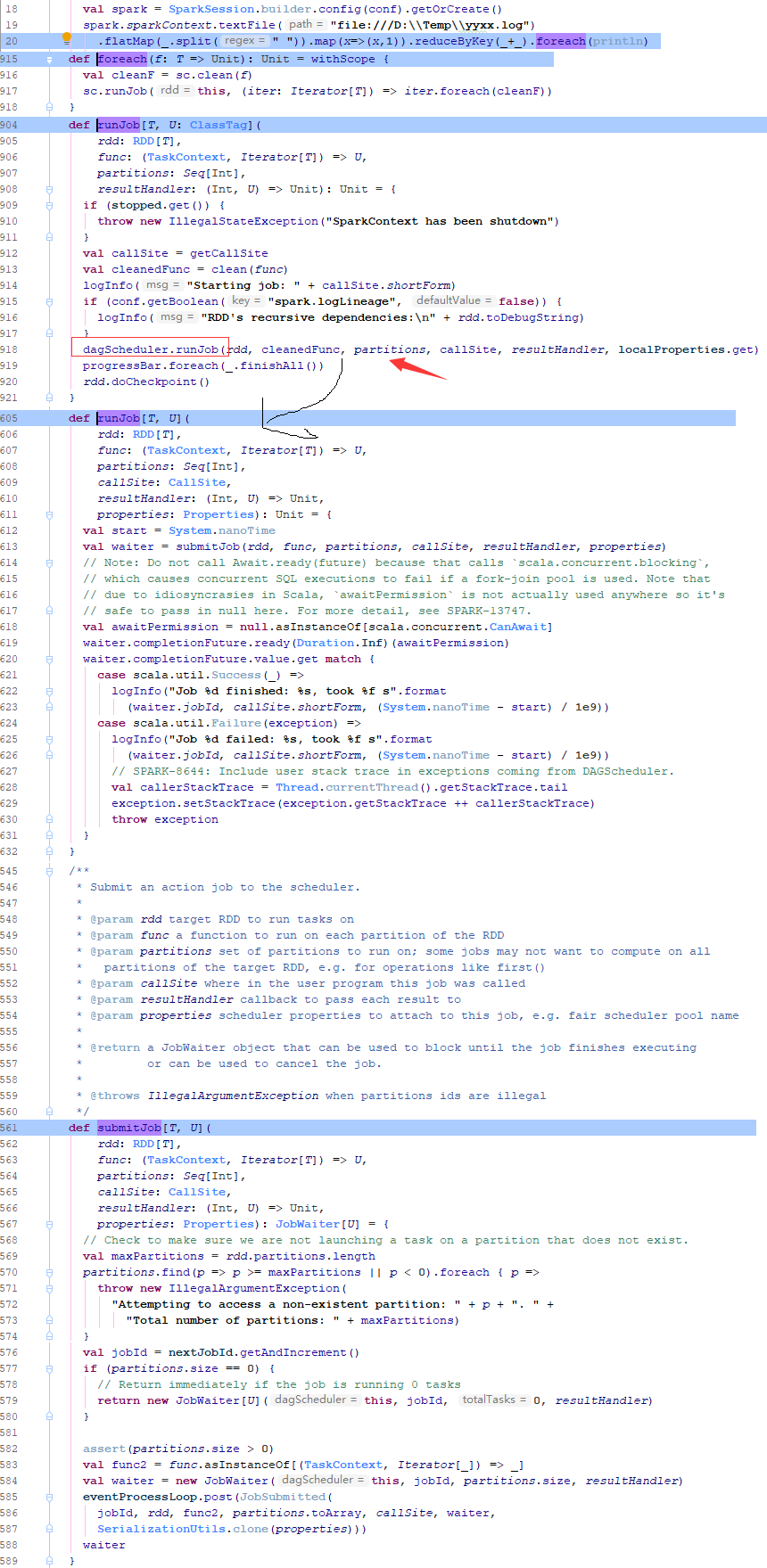
4 Scheduling stage
user code containing RDD transformations forms Direct Acyclic Graph which is then split into stages of tasks by DAGScheduler. Stages combine tasks which don’t require shuffling/repartitioning if the data. Tasks run on workers and results then return to client.
DAG

Here's a DAG for the code sample above. So basically any data processing workflow could be defined as reading the data source, applying set of transformations and materializing the result in different ways. Transformations create dependencies between RDDs and here we can see different types of them.
The dependencies are usually classified as "narrow" and "wide":
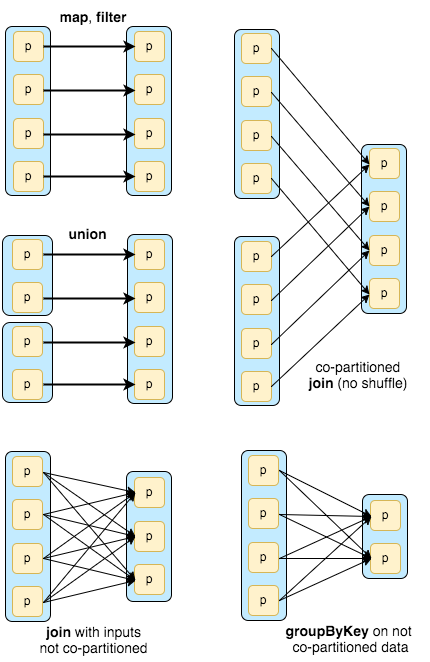
- Narrow (pipelineable)
- each partition of the parent RDD is used by at most one partition of the child RDD
- allow for pipelined execution on one cluster node
- failure recovery is more efficient as only lost parent partitions need to be recomputed
- Wide (shuffle)
- multiple child partitions may depend on one parent partition
- require data from all parent partitions to be available and to be shuffled across the nodes
- if some partition is lost from all the ancestors a complete recomputation is needed
Splitting DAG into Stages
Spark stages are created by breaking the RDD graph at shuffle boundaries
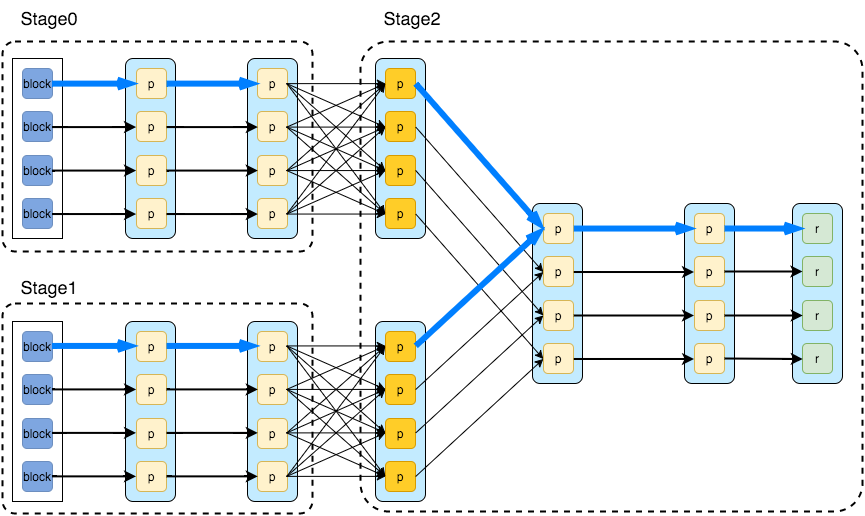
- RDD operations with "narrow" dependencies, like map() and filter(), are pipelined together into one set of tasks in each stage operations with shuffle dependencies require multiple stages (one to write a set of map output files, and another to read those files after a barrier).
- In the end, every stage will have only shuffle dependencies on other stages, and may compute multiple operations inside it. The actual pipelining of these operations happens in the
RDD.compute()functions of various RDDs
There are two types of tasks in Spark: ShuffleMapTask which partitions its input for shuffle and ResultTask which sends its output to the driver. The same applies to types of stages: ShuffleMapStage and ResultStage correspondingly.
Shuffle
During the shuffle ShuffleMapTask writes blocks to local drive, and then the task in the next stages fetches these blocks over the network.
- Shuffle Write
- redistributes data among partitions and writes files to disk
- each hash shuffle task creates one file per “reduce” task (total = MxR)
- sort shuffle task creates one file with regions assigned to reducer
- sort shuffle uses in-memory sorting with spillover to disk to get final result
- Shuffle Read
- fetches the files and applies reduce() logic
- if data ordering is needed then it is sorted on “reducer” side for any type of shuffle
In Spark Sort Shuffle is the default one since 1.2, but Hash Shuffle is available too.
Sort Shuffle
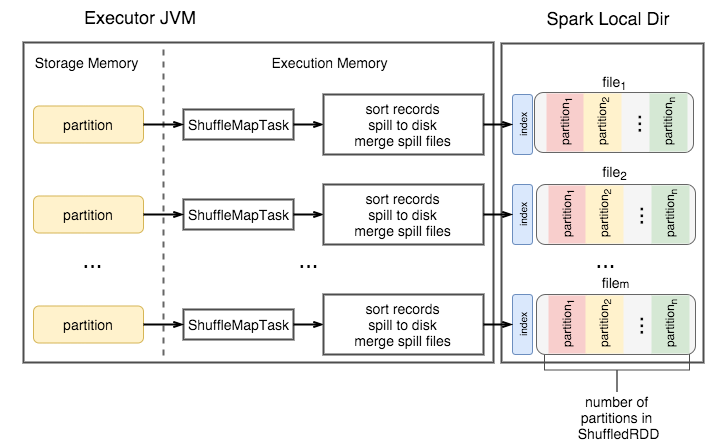
- Incoming records accumulated and sorted in memory according their target partition ids
- Sorted records are written to file or multiple files if spilled and then merged
- index file stores offsets of the data blocks in the data file
- Sorting without deserialization is possible under certain conditions (SPARK-7081)
Why is Spark DAG needful?
In hadoop mapreduce, computations take place in three steps:
1. Initially, we use HDFS (Hadoop Distributed File System) to read data every time we need.
2. After that, two transformation operations map and reduce are applied.
3. And in the third step computed result is written back to HDFS. Due to each operation is independent of each other there is no linkage in between. Sometimes it became an issue to handle two map-reduce jobs at same time. Due to this most memory gets wasted. That results in long computation with less data volume.
Therefore in spark, it automatically forms DAG logical flow of operations. That helps in minimize the data shuffling all around. This reduces the duration of computations with less data volume. It also increases the efficiency of the process with time.
How Spark Builds a DAG?
There are following steps of the process defining how spark creates a DAG:
- Very first, the user submits an apache spark application to spark.
- Than driver module takes the application from spark side.
- The driver performs several tasks on the application. That helps to identify whether transformations and actions are present in the application.
- All the operations are arranged further in a logical flow of operations, that arrangement is DAG.
- Than DAG graph converted into the physical execution plan which contains stages.
- As we discussed earlier driver identifies transformations. It also sets stage boundaries according to the nature of transformation. There are two types of transformation process applied on RDD: 1. Narrow transformations 2. Wide transformations. As wide Transformation requires data shuffling that shows it results in stage boundaries.
- After all, DAG scheduler makes a physical execution plan, which contains tasks. Later on, those tasks are joint to make bundles to send them over the cluster.
How is Fault Tolerance achieved through Spark DAG?
As we know DAG keeps the record of operations applied on RDD. It holds every detail of tasks executed on different partitions of spark RDD. So at the time of failure or if losing any RDD, we can fetch it easily with the help of DAG graph. For example, If any operation is going on and all of sudden any RDD crashes. With the help of cluster manager, we will identify the partition in which loss occurs. After that through DAG, we will assign the RDD at the same time to recover the data loss. That new node will operate on the particular partition of spark RDD. It will also execute in the series of operation, where it needed to be executed.
Working with DAG optimizer in Spark
Optimizing a DAG is possible by rearranging and combining operators wherever possible. The DAG optimizer rearranges the order of operators to maintain the number of records of further operations. For example, if we take two operations like map () and filter () in a spark job. The optimizer will rearrange the order of both the operators. Since filtering may reduce the number of records to experience map operations.
Advantages of DAG in Spark
DAG has turned as very beneficial in several terms to us. Some of them are list-up below:
- It is possible to execute many at same time queries through DAG. Due to only two queries (Map and Reduce) are available in mapreduce. We are not able to entertain SQL query, which is also possible on DAG. It turns out more flexible than mapreduce.
- As it is possible to achieve fault tolerance through DAG. We can recover lost RDDs using this graph.
- In comparison to hadoop mapreduce, DAG provides better global optimization.
Spark DAG – Conclusion
Coming to the end, we found that DAG in spark overcomes the limitations of hadoop mapreduce. It enhances sparks functioning in any way. DAG is a beneficial programming style used in distributed systems. Through DAG there are several level functions are available to work on. As in mapreduce, there are only two functions (map and reduce) available.
Comparatively, DAG is faster than mapreduce. That improves the efficiency of the system.
CODE Analysis
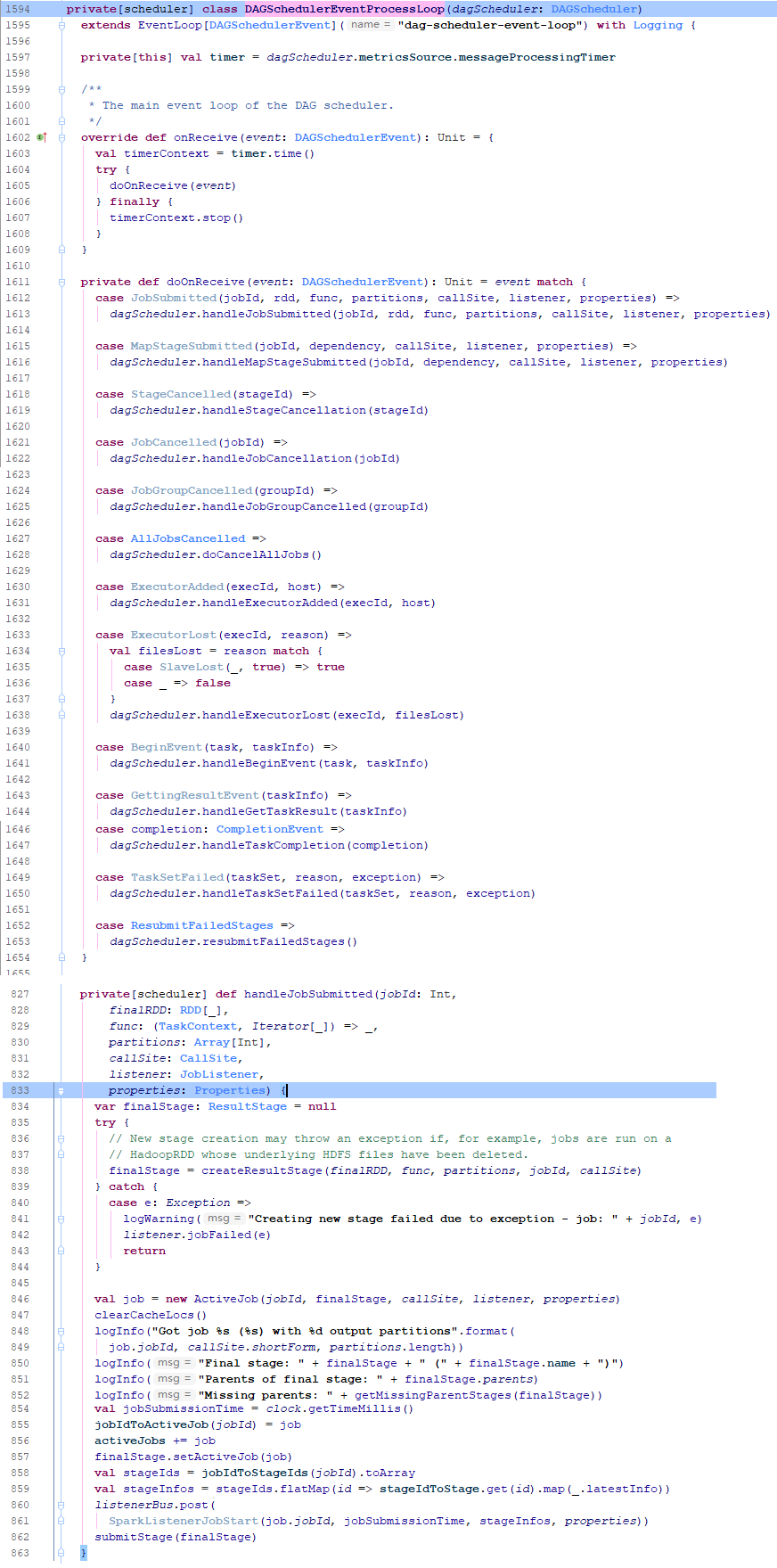
In the previous step, DAGScheduler begin from the method of handleJobSubmitted.

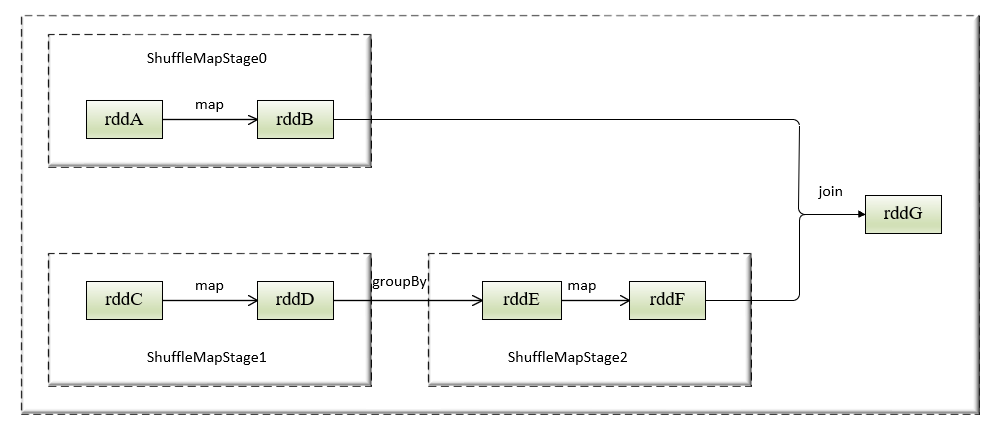
As the follow pictuce let me to introduce how to divide the schedule stage, there have seven rdd which are rddA to rddG and five operator steps. the detail divide infomation are as follows.

 浙公网安备 33010602011771号
浙公网安备 33010602011771号