递归神经网络 RNN 原理(下)
基于对 RNN 的初步认识, 还是先回顾一下它核心的步骤:
(1) words / onehot vectors : \(x^{(t)} \in R^{|v|}\)
**(2) word embeddings: ** \(e^{(t)} = Ex^{(t)}\)
**(3) hidden states: ** \(\sigma(h^{(t)} = W_e e^{(t)} + W_h h^{(t-1)} + b_t)\) 注: \(h^{(0)}\) is the initial hidden state.
(4) output distribution: \(y^{(t)} = softmax(Uh^{(t)} + b_t) \in R^v\)
最后得到的 \(y^{(t)}\) 就是一个概率分布嘛. 值得注意的一点是, 这个 \(W_e\) 是复用的, 同样, 上面的 \(W_h\) 也是复用的, 这样做的特点是, RNN 对于输入向量的尺寸是没有限制的. 即可以用前面比如 5个单词来预测, 或者 10个单词来预测, 效果都是一样的.
然后训练的过程, 也是采用 误差向后传递 BP 的方式, 损失函数用交叉熵.
\(J^{(t)}(\theta) = CE (y^{(t)}, \hat y^{(t}) = -\sum \limits _{w \in V} y_w^{(t)} log \ \hat y_w^{(t)} = -log \ y^{(t)}_{x(t+1)}\)
RNN 如何做预测
至于该神经网络的误差的反向传递, 以及权值如何更新, 就不想再谈了, 思路一样的, 可以翻翻我前面对 BP 算法的推导 2.0 版本的. 核心: 多元函数求偏导, 注意求导的链式法则 (chain rule), 降梯度值作为"error" 这块很关键的, 只有深刻理解了 BP , 后面这些都是差不多的套路而已.
BP推导:
是差别, 但核心思想没变, 改吧改吧, 就基本能推导了, 我现在在 RNN 这里确实不想推了, 就像搞搞怎么去应用先
Just like a n-gram Language Model, you can use a RNN Model to generate text by repeated sampling. Sampled output is next step's input.
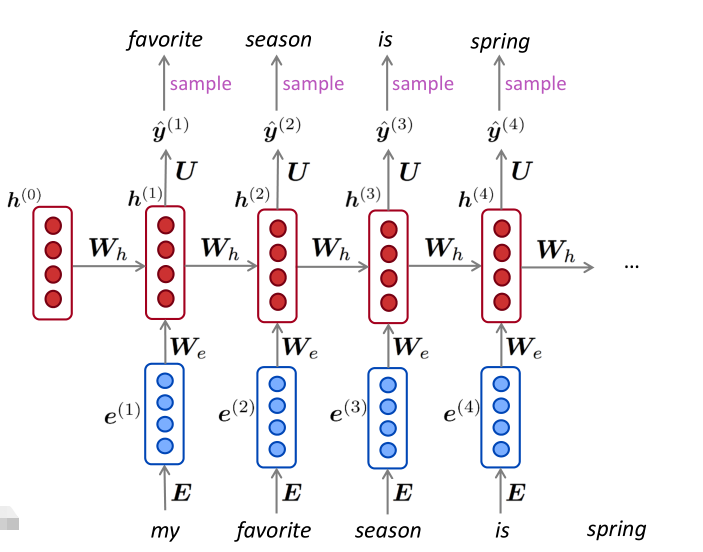
就先对 "my" 这个单词, 进行 onehot, 在 encoding 或者 embedding 词向量化, 再变为稠密向量, 与 E 相乘; 初始化 h0 ( 可假设h0向量里面都是0, 你随意) 与 W 相乘, 然后再:
\(\sigma(We + Wh + b_1) * U => y^{(1)}\) 的概率分布, 然后进行采样 sample ( from Vocabulary) 得到 "favorite".
于是就将 "favorite" 作为下一个状态的 "input" 跟上面一样的操作, 假如说取到的是 "season" .
然后再作为下一个状态的 "input", 这种 递归 的方式去不断重复这个过程... 这样就能生成一个完整的句子了. (前提是已通过 BP 训练好了 权值矩阵 We, Wh 和 bais 哦)
RNN 模型衡量
The standard evluation mertric (度量标准) for Language Models is perplexity (困惑 或误解程度)
\(perplexity = \prod \limits_{t=1}^T (\frac{1} {P_{lm} (x^{(t_1)} | x^t, ....x^1)})^{(1/t)}\)
真实的是知道的嘛, 再用这个模型 来衡量 perplexity 的程度. This is eque to the exponential of the **cross-entropy loss ** \(J(\theta)\) 的期望即 \(exp (J(\theta))\)
\(= \prod \limits_{t=1}^T (\frac{1} {y^t_{x+1}})^{1/t} = exp(\frac{1}{T} \sum\limits_{t=1}^T -log\ \hat y^{(t)}x_{x+1}) = exp(J(\theta))\)
Lower perplexity is better.
从一些前人的试验来看 从2013 -> 2016 从 n-gram 到 RNN -> LSTM 等方式在不断地降低这个 perplexity.
LM 的应用
Language Modeling is a benchmark task (标准任务) that help us measure our progress on understanding language.
同样呢,
Language Modeling is a subcomponent (子任务) for many NLP tasks, especially those involving generating text or estimating the probability of text. 在一些生成文本, 和文本预测的场景.
比如说, 输入法提示; 语音识别; 手写字符识别; 字词矫正; 文章作者猜测; 机器翻译; 自动写文章的简述 (summarization); 对话系统; 等, 应用还是蛮多的, 我很挺感兴趣的, 就目前还不太会, 也不知道靠不靠谱, 后面来试看, 我比较感兴趣的, 对话系统 和 自动文章;
RNN : 中文翻译为 "递归神经网络" 我感觉, 只是在不断复用W , 和前一个输出作为后一个输入, 感觉也没有咱编程中 递归的意思, 感觉上还是差了那么一点, 但, 总听上去却觉得非常高大上.
RNN 应用
小结
-
Language Model: A system that predicts the next word
-
Recurrent Neural Network: A family of neural networks that:
- Take sequential input of any length (RNN 对于输入的长度没有限制)
- Apply the same weights on each step (权值矩阵 W 是复用的哦)
- Can optionally produce output on each step (在每一步都可以产生输出)
-
RNN != LM (不完全等于 语言模型, RNN 还能有很多很多的应用场景, 如上面提到的什么机器翻译, 对话系统... 或者这 时序类预测 ... 理解核心是关键词: "神经网络, 权值复用, 上一状态输出作为下一状态输入" 这很强大的.
-
应用真的可以蛮多的...
更多应用
-
RNN can be used for tagging (给判断一段话的单词的词性) 也叫 part of speech tagging (词性标注)
-
RNN can be used for sentence calssification (给一段文本, 进行自动情感分析, 是 positive 还是 negative) 或者 0-5 李克特评分表来自动完成, (不由得又突然回到营销这块了)
-
RNN can be used as an encoder moduel (自动问答系统, 机器翻译)
-
RNN can be used to generate text (语音转文本, 自动生成文本)
递归神经网络 RNN 就认识到这了, 本来是想就简单了解一波, 公式也不想推导的, 看了有很多很多应用之后, 突然感觉, 有点想去动手试一波的冲动... 然后, 再看看一下, 比较更厉害点的这种, NLP 懂东西, 了解一下.

 浙公网安备 33010602011771号
浙公网安备 33010602011771号