

结对第二次—文献摘要热词统计
作业描述
| 课程 | 软件工程1916|W(福州大学) |
|---|---|
| 作业要求 | 结对第二次—文献摘要热词统计及进阶需求 |
| 结队博客 | 221600328 221600106 |
| Github地址 | 基础需求 |
| 作业目标 | 实现一个能够对文本文件中的单词的词频进行统计的控制台程序。 |
| 具体分工 | 221600328:主要代码及工作 221600106:部分代码,编写文档 |
签入记录
作业正文
PSP表格
| PSP2.1 | Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | 60 | 50 |
| Estimate | 估计这个任务需要多少时间 | 1700 | 2050 |
| Development | 开发 | 300 | 350 |
| Analysis | 需求分析 (包括学习新技术) | 180 | 220 |
| Design Spec | 生成设计文档 | 60 | 70 |
| Design Review | 设计复审 | 60 | 80 |
| Coding Standard | 代码规范 (为目前的开发制定合适的规范) | 30 | 20 |
| Design | 具体设计 | 180 | 220 |
| Coding | 具体编码 | 770 | 850 |
| Code Review | 代码复审 | 120 | 100 |
| Test | 测试(自我测试,修改代码,提交修改) | 80 | 70 |
| Reporting | 报告 | 160 | 180 |
| Test Repor | 测试报告 | 30 | 35 |
| Size Measurement | 计算工作量 | 30 | 25 |
| Postmortem & Process Improvement Plan | 事后总结, 并提出过程改进计划 | 120 | 55 |
| 合计 | 2180 | 2325 |
需求分析
WordCount基本需求
实现一个命令行程序,不妨称之为wordCount。
第一步、实现基本功能
输入文件名以命令行参数传入。例如我们在命令行窗口(cmd)中输入:
//C语言类
wordCount.exe input.txt
//Java语言
java wordCount input.txt
则会统计input.txt中的以下几个指标
1.统计文件的字符数:
- 只需要统计Ascii码,汉字不需考虑
- 空格,水平制表符,换行符,均算字符
2.统计文件的单词总数,单词:至少以4个英文字母开头,跟上字母数字符号,单词以分隔符分割,不区分大小写。
- 英文字母: A-Z,a-z
- 字母数字符号:A-Z, a-z,0-9
- 分割符:空格,非字母数字符号
- 例:file123是一个单词,123file不是一个单词。file,File和FILE是同一个单词
3.统计文件的有效行数:任何包含非空白字符的行,都需要统计。
4.统计文件中各单词的出现次数,最终只输出频率最高的10个。频率相同的单词,优先输出字典序靠前的单词。
5.按照字典序输出到文件result.txt:例如,windows95,windows98和windows2000同时出现时,则先输出windows2000
- 输出的单词统一为小写格式
6.输出的格式为
characters: number
words: number
lines: number
...
解题思路
这次题目主要是两个部分:字词计数和文件读写,本来想用c++来进行编码,后来发现使用Java更为简便,有许多类库函数可以直接调用来解决问题,于是就使用了Java。
思路主要是写一个Count类,类里包含各个小问题解决的方法,如CountCharacter,CountLine和CountWord。
使用BufferedReader读文件,读出来的数据用String存储,对该字符串进行修改,获取单词及行数,最后重写compare对单词进行排序。
有了整体思路后,对每个方法逐个击破,便迎刃而解了。
代码规范
一开始写这个代码十分不规范。。用的变量名简直随心所欲,后面按照Java规范修改了一下,整体还行。
设计说明
类图
(https://img2018.cnblogs.com/blog/1593605/201903/1593605-20190315170442501-135307741.png)
流程图

模块设计
模块说明
传入文件名,统计非空行数,统计字符数,统计单词数,统计最多的10个单词及其词频
方法说明
传入文件名
CountCharacter:计算字符数
CountWord:计算单词
CountLine:计算行数
关键代码
统计单词及计算词频部分,使用split正则表达式分词,存入HashMap,重写compare,存入List进行排序。
public int CountWord() {
int wordNum=0;
String regex="[^A-Za-z0-9]";
String textLowerCase= text.toLowerCase();
String textcontents = textLowerCase.replaceAll(regex, " ");
String[] textarrays = textcontents.split("\\s+");
for(int i=0; i<textarrays.length;i++)
{
if(textarrays[i].length()>=4)
if(Character.isLetter(textarrays[i].charAt(0)) &&
Character.isLetter(textarrays[i].charAt(0)) &&
Character.isLetter(textarrays[i].charAt(0)) &&
Character.isLetter(textarrays[i].charAt(0)))
{
wordNum++;
if(!map.containsKey(textarrays[i]))
map.put(textarrays[i],1);
else
{
int num=map.get(textarrays[i]);
num++;
map.put(textarrays[i], num);
}
}
}
hotWords=Sort(map);
return wordNum;
}
public static List<HashMap.Entry<String, Integer>> Sort(Map m){
Map<String, Integer> map = new HashMap<String, Integer>();
// 通过ArrayList构造函数把map.entrySet()转换成list
List<Map.Entry<String, Integer>> list = new ArrayList<Map.Entry<String, Integer>>(m.entrySet());
// 通过比较器实现比较排序
Collections.sort(list, new Comparator<Map.Entry<String, Integer>>() {
@Override
public int compare(Map.Entry<String,Integer> mapping1, Map.Entry<String, Integer> mapping2) {
if(mapping1.getValue()==mapping2.getValue())
return mapping1.getKey().compareTo(mapping2.getKey());//字典排序
return mapping2.getValue()-mapping1.getValue();//从大到小
}
});
return list;
}
异常处理
对于各个异常情况都会打印异常信息,如下
catch (FileNotFoundException e)
{
// TODO Auto-generated catch block
e.printStackTrace();
}catch (IOException e)
{
// TODO Auto-generated catch block
e.printStackTrace();
}
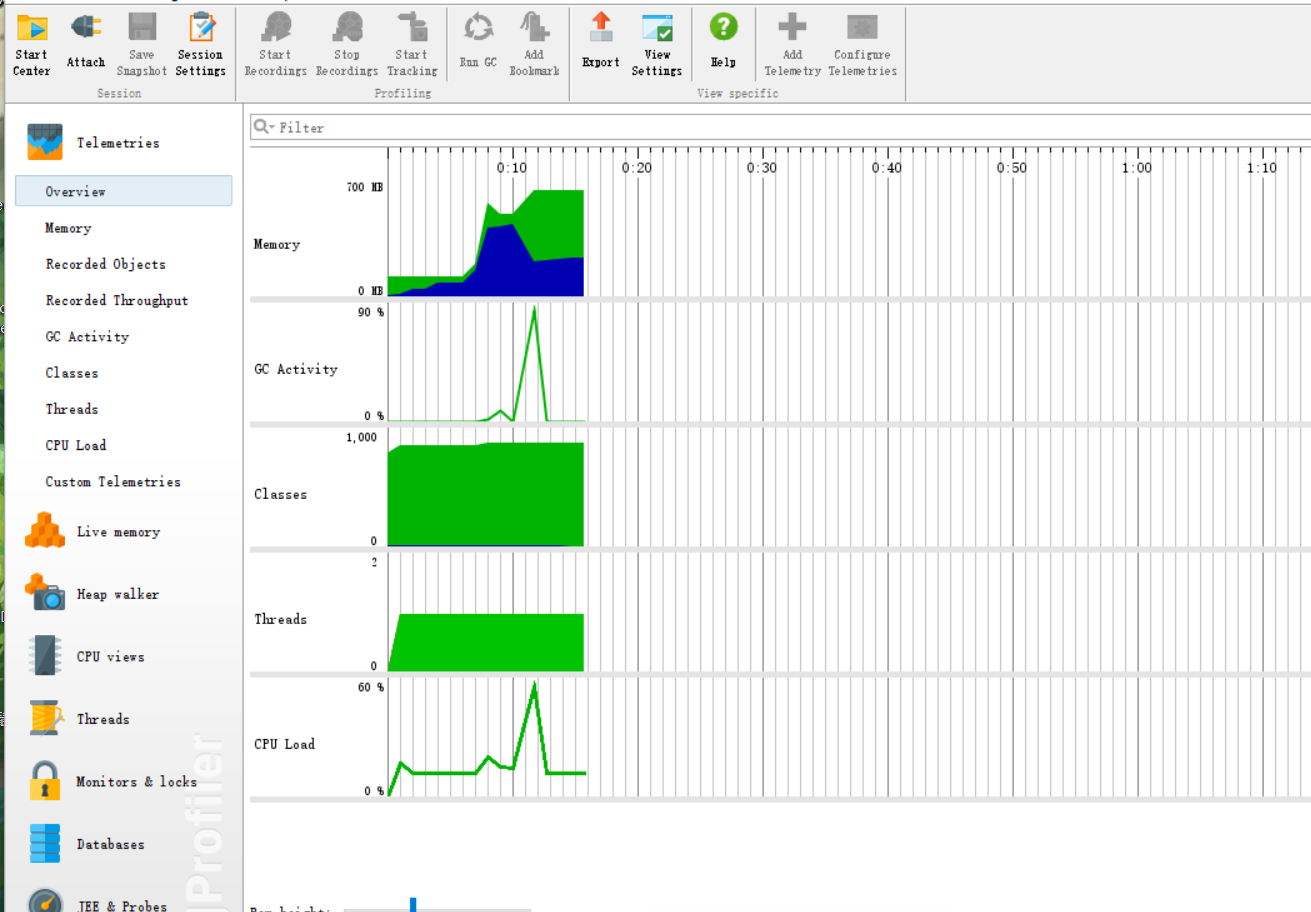
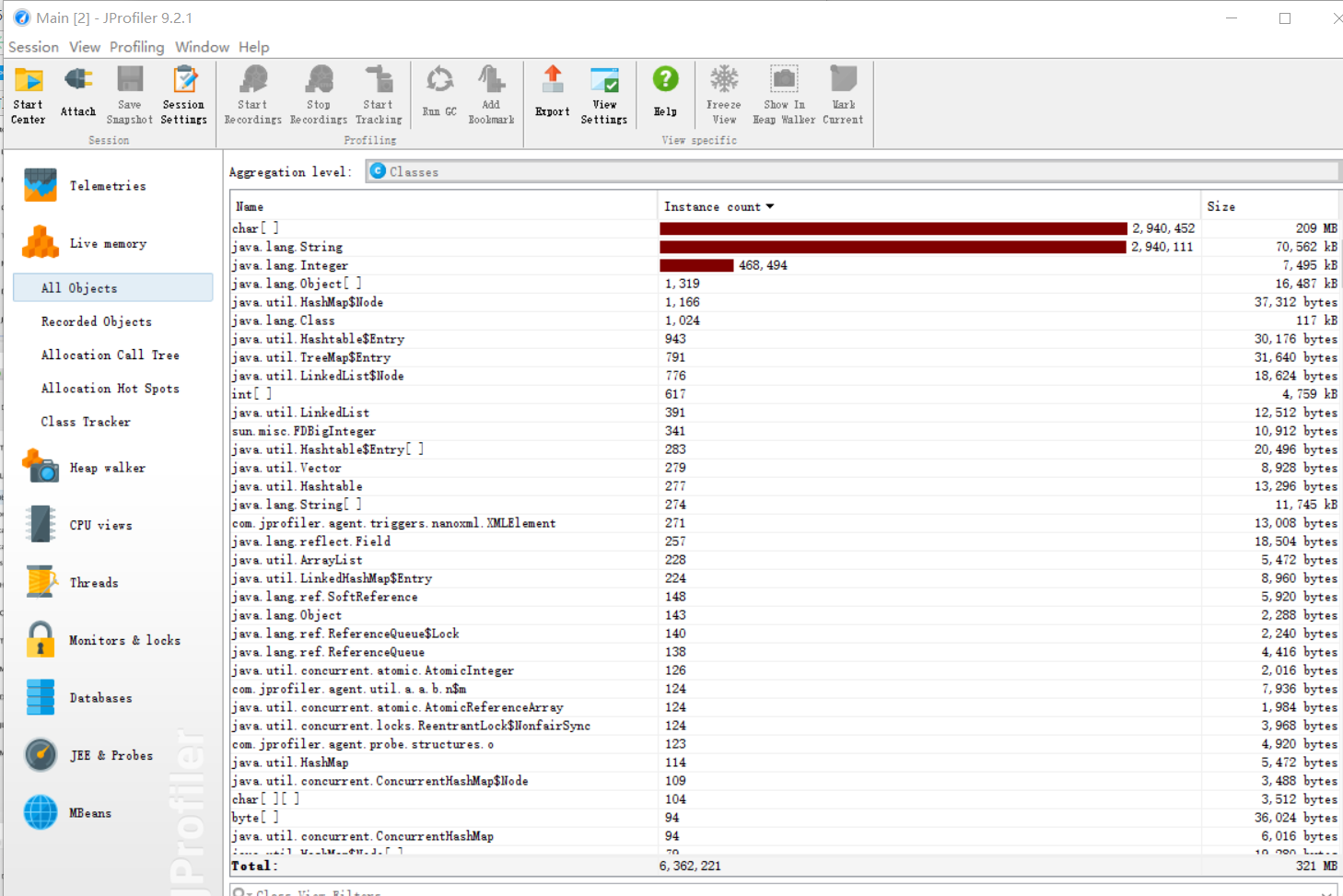
性能分析
如图,大部分开销来自于单词技术部分。
单元测试
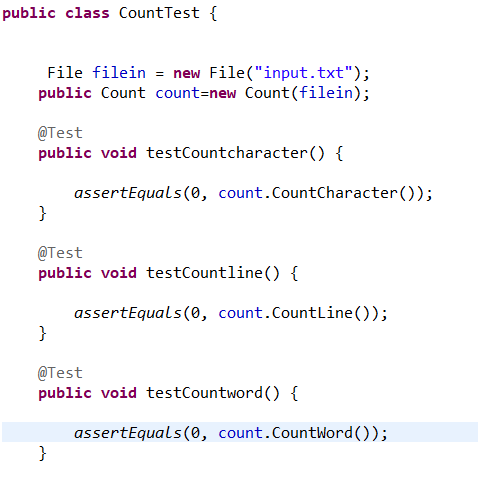
共设计了10组测试,分别有普通字符,换行符,空格,单词大小写,控制字符等。
以下是空白文件的测试,分别有统计单词,行数,字符的测试。
改进思路
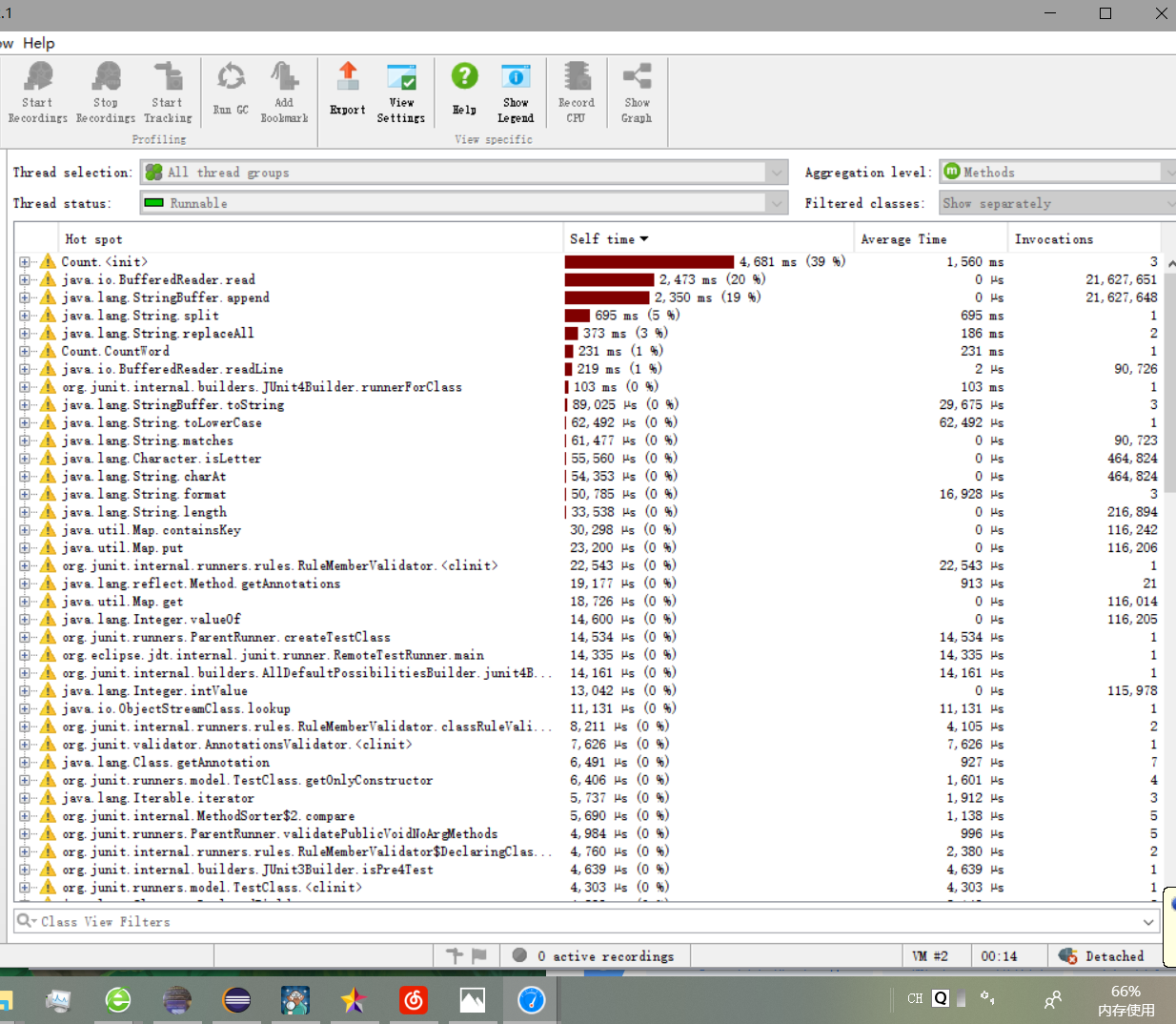
如图,在IO上有巨大的开销,主要在计算行数时又访问了一遍文件,导致过度的IO,性能下降,应先将文件数据暂存,后续对该文件进行访问,减少IO,提高性能。
另外分割字符的函数split开销也挺大,或许使用stringTokenizer进行切分能提高性能。
遇到的困难和解决方法:
- 需求的理解
- 解决方法:无可避免又在需求上产生疑问,果然对需求的清晰理解是首先,也是最重要的一步,通过与同学助教探讨解决问题。
- 使用性能分析,单元测试工具及git的使用
- 解决方法:首次使用这些工具,对工具的不熟悉,通过询问同学及上网查找资料解决。
- 编码能力不足
- 解决方法:个人编码能力不足,以至于编写代码花了很多的时间,定痛改前非,提高编程能力
评价队友
明辉是个很聪明勤奋的人,对这次作业做出了很大的贡献我也协助他完成了基础的工作。
posted on 2019-03-15 20:39 ChenHong1998 阅读(230) 评论(1) 收藏 举报


 浙公网安备 33010602011771号
浙公网安备 33010602011771号