

1.注册中国大学MOOC
2.选择北京理工大学嵩天老师的《Python网络爬虫与信息提取》MOOC课程
3.学习完成第0周至第4周的课程内容,并完成各周作业
4.提供图片或网站显示的学习进度,证明学习的过程。
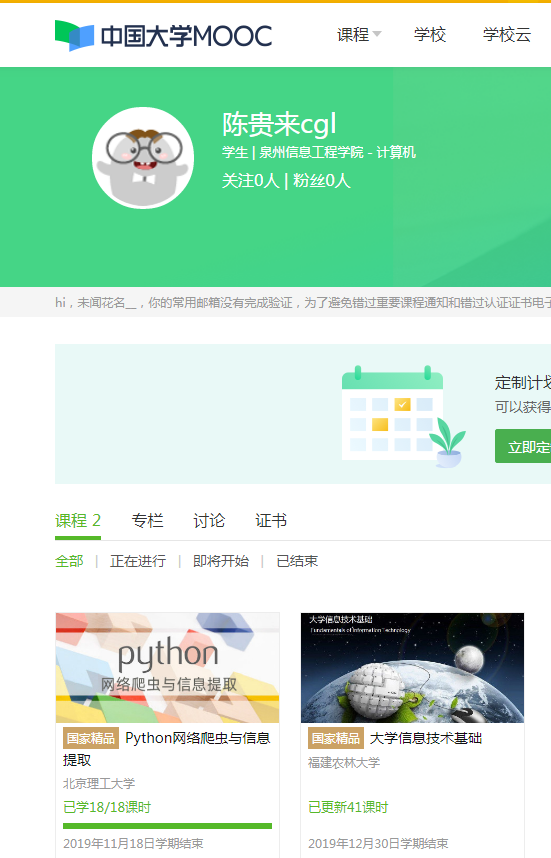
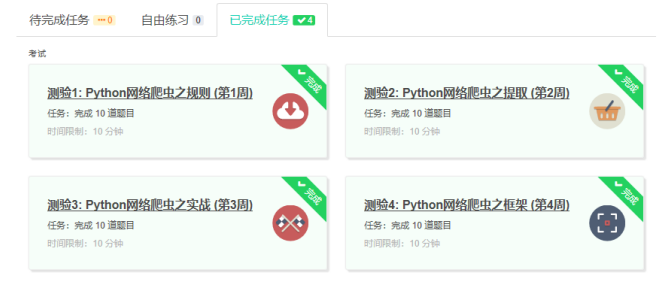
5.写一篇不少于1000字的学习笔记,谈一下学习的体会和收获。
《Python网络爬虫与信息提取》读书笔记与总结
在这一周的时间里,我学习了北京理工大学嵩天老师的《Python网络爬虫与信息提取》,本课程主要讲了五个部分:
第一部分:requests库中自动爬取HTML页面和自动网络请求提交
☆requests库7个主要方法:
a、requests.request() 构造一个请求,支撑以下各方法的基础方法
b、requests.get() 获取HTML网页的主要方法,对应于HTTP的GET
c、requests.head() 获取HTML网页头信息的方法,对应于HTTP的HEAD
d、requests.post() 向HTML网页提交POST请求的方法,对应于HTTP的POST
e、requests.put() 向HTML网页提交PUT请求的方法,对应于HTTP的PUT
f、requests.patch() 向HTML网页提交局部修改请求,对应于HTTP的PATCH
g、requests.delete() 向HTML页面提交删除请求,对应于HTTP的DELETE
☆requests库异常
a、requests.ConnectionError 网络连接错误异常,如DNS查询失败、拒绝连接等
b、requests.HTTPError HTTP错误异常
c、requests.URLRequired URL缺失异常
d、requests.TooManyRedirects 超过最大重定向次数,产生重定向异常
e、requests.ConnectTimeout 连接远程服务器超时异常
f、requests.Timeout 请求URL超时,产生超时异常
☆http协议对资源的6中操作:
GET 请求获取URL位置的资源
HEAD 请求获取URL位置资源的响应消息报告,即获得该资源的头部信息
POST 请求向URL位置的资源后附加新的数据
PUT 请求向URL位置存储一个资源,覆盖原URL位置的资源
PATCH 请求局部更新URL位置的资源,即改变该处资源的部分内容
DELETE 请求删除URL位置存储的资源
第二部分:robots.txt协议中的网络爬虫排除标准
1、小规模,数据量小,爬取速度不敏感,Requests库,90%以上 ,爬取网页、玩转网页
2、中规模,数据规模较大,爬取速度敏感,Scrapy库,爬取网站、爬取系列网站
3、大规模,搜索引擎爬取,速度关键 ,定制开发,爬取全网
第三部分:beautiful soup库中的解析HTML页面
☆beautiful soup库是解析、遍历、维护“标签树”的功能库
☆4种解析器:
soup = BeautifulSoup(‘<html>data</html>’,’html.parser’)
bs4的HTML解析器 BeautifulSoup(mk,’html.parser’) 安装bs4库
lxml的HTML解析器 BeautifulSoup(mk,’lxml’) pip install lxml
lxml的XML解析器 BeautifulSoup(mk,’xml’) pip install lxml
html5lib的解析器 BeautifulSoup(mk,’html5lib’) pip install html5lib
☆BeautifulSoup类5种基本元素:
Tag 标签,最基本的信息组织单元,分别用<>和</>标明开头和结尾
Name 标签的名字,<p>…</p>的名字是’p’,格式:<tag>.name
Attributes 标签的属性,字典形式组织,格式:<tag>.attrs
NavigableString 标签内非属性字符串,<>…</>中字符串,格式:<tag>.string
Comment 标签内字符串的注释部分,一种特殊的Comment类型
☆三种遍历方式:下行遍历、下行遍历、平行遍历
☆信息标记的三种形式:xml、json、yaml
标记后的信息可形成信息组织结构,增加了信息维度
标记的结构与信息一样具有重要价值
标记后的信息可用于通信、存储或展示
标记后的信息更利于程序理解和运用
第四部分:Re正则表达式详解与提取页面关键信息
☆re库主要功能函数:
re.search() 在一个字符串中搜索匹配正则表达式的第一个位置,返回match对象
re.match() 从一个字符串的开始位置起匹配正则表达式,返回match对象
re.findall() 搜索字符串,以列表类型返回全部能匹配的子串
re.split() 将一个字符串按照正则表达式匹配结果进行分割,返回列表类型
re.finditer() 搜索字符串,返回一个匹配结果的迭代类型,每个迭代元素是match对象
re.sub() 在一个字符串中替换所有匹配正则表达式的子串,返回替换后的字符串
第五部分:scrapy库中的网络爬虫原理介绍和专业爬虫框架介绍
☆requests 库与Scrapy框架的区别
requests 库:页面级爬虫、功能库、并发性考虑不足,性能较差、重点在于页面下载、定制灵活、上手十分简单
Scrapy框架:网站级爬虫框架、并发性好,性能较高、重点在于爬虫结构、一般定制灵活,深度定制困难、入门稍难
☆Scrapy常用命令:
1、startproject 创建一个新工程scrapy startproject <name> [dir]
2、genspider 创建一个爬虫scrapy genspider [options] <name> <domain>
3、settings 获得爬虫配置信息scrapy settings [options]
4、crawl 运行一个爬虫scrapy crawl <spider>
5、list 列出工程中所有爬虫scrapy list
6、shell 启动URL调试命令行scrapy shell [url]
在这一周的学习中,让我们真正意义了解到python这一门语言的精炼之处,以及对爬虫这种方式所带来的的乐趣。使我们对这门语言接下来的学习过程中更加的有信心。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号