GraphQL实战-第一篇-GraphQL介绍
GraphQL实战-第一篇-GraphQL介绍
https://blog.csdn.net/xplan5/article/details/108716321
GraphQL的前世今生
Facebook的业务线有移动端,PC端和其它端,不同的场景下对一个资源所需要的信息是不同的。如移动端需要User的a、b、c三个字段,PC端需要b、c、d三个字段;对于此场景,要么开多个定制化API接口,会造成代码冗余,要么一个全信息API接口,有接口信息冗余。
造成了不止以下三个痛点
- 移动端需要高效的数据加载,被接口冗余字段拖累
- 多端产品下,API维护困难
- 前端新产品快速开发困难,需要大量的后端配合写业务定制化API
解决以上问题,2012年Facebook在开发中形成了一套规范,就诞生了GraphQL,并于2016年将此规范开源。
API开发方式的发展,从SOAP到REST,经历了很多年,GraphQL也许是下一代的API方式,发展的共同特点是,API越来越自由,越来越灵活。
GraphQL-API查询语言
GraphQL是什么?
官方的解释是 GraphQL是一种用于API的查询语言。
怎么理解API查询语言,我们知道SQL是结构化查询语言,是查数据的,当然也能操作数据。同为Query Language 当然是有相同点的。
GraphQL和SQL
- SQL 是对数据库(服务端)的操作语言
- GraphQL 是对API接口(服务端)的操作语言
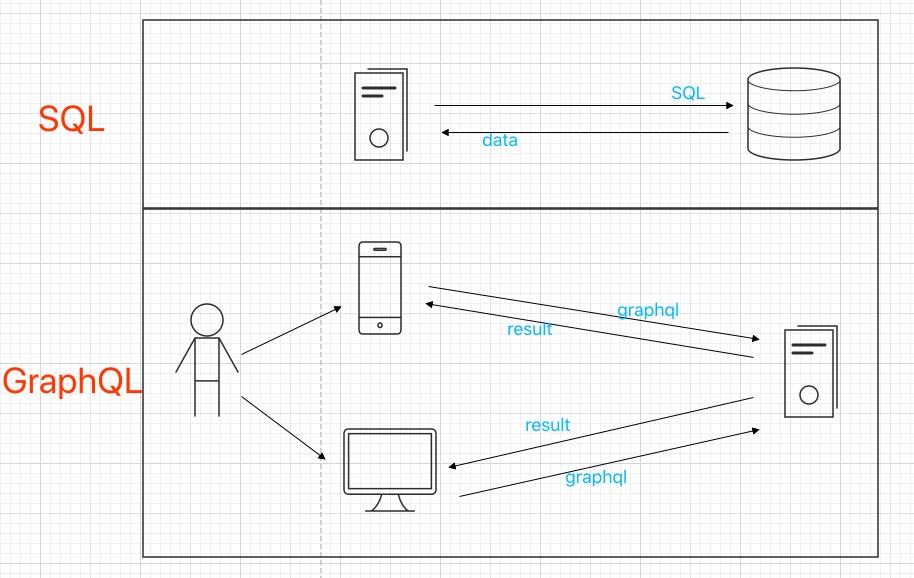
数据库分为服务端和客户端,我们最为客户端写SQL来操作数据库;
GraphQL也分服务端和客户端,这里讲的是服务端为主。客户端就是接口调用方,暂且理解为前端;服务端就是提供接口的后端服务。
GraphQL可以简单理解为,客户端 操作 API, 后端业务系统作为数据库为客户端提供服务。
GraphQL的优点
现在来看看GraphQL做到了什么。
一 接收的数据不多不少
向你的API发送一个GraphQL请求 就能准确获得你想要的数据,不 多不少。没有任何数据冗余。这是graphql最大的优点,客户端在GraphQL的请求脚本中指定查询的字段,API就不会返回任何多余的字段。
对应于SQL就相当于:
SELECT age,name
FROM USER
WHERE id = 1532;
对应的GraphQL语句就是
{
queryUser(id:1532) {
age
name
}
}
下图是使用效果:
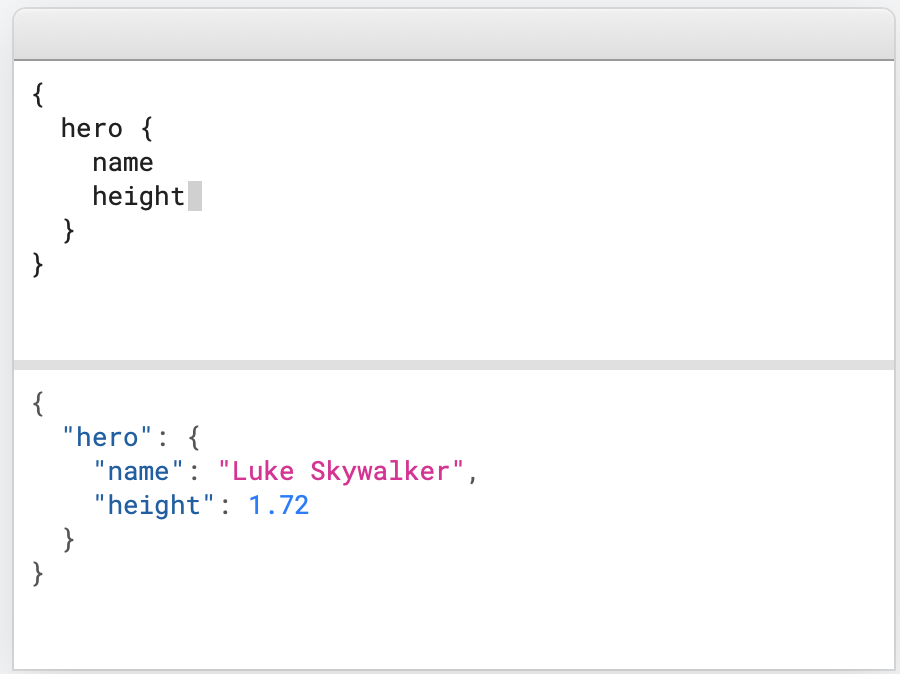
这个特点,避免了网络传输的数据冗余,对前端的性能有改善,对于后端的优化也提供了新的方向,如根据GraphQL的需求,动态生成对应的sql,避免每次查全数据库字段带来的性能损耗。
二 获取多个资源,只用一个请求
简单来说就是,多个接口的调用,可以放到一个http请求中来做,并且自定义数据返回的格式,包括指定变量名。
传统的REST请求,是一次http请求,只操作一个API的内容,如一个场景下需要查询用户信息,商品信息和订单信息。要么前端调三次接口,要么后端封装一个定制的接口。
示例:
graphql多次调用服务获取资源:
获取用户信息
query queryUserInfo {
getUserInfoByID(userId:1890) {
userName
userAge
mailbox
}
}
获取商品信息
query queryProducts {
getProducts(device:web) {
productName
productid
sppu
price
}
}
获取订单信息
query queryOrders {
getOrdersByUserId(userId:1890) {
orderId
orderNo
}
}
以上内容,一次请求接口与搞定
query {
user: getUserInfoByID(userId:1890) {
userName
userAge
mailbox
}
products: getProducts(device:web) {
productName
productid
sppu
price
}
orders: getOrdersByUserId(userId:1890) {
orderId
orderNo
}
}
这个特点在移动端弱网环境下,也能高效的加载数据;而对于后端,也会相应减少Servlet线程是使用次数,可以有更高的系统吞吐量;另一个方向,一次请求多个接口,也可以采用异步执行,提升服务端的响应效率...
三 描述所有可能的类型系统
graphql的schema真正做到了代码及文档,服务端定义好graph后,客户端可以方便的查看到结构模型,客户端写脚本的时候graph也会起到很好的辅助作用。
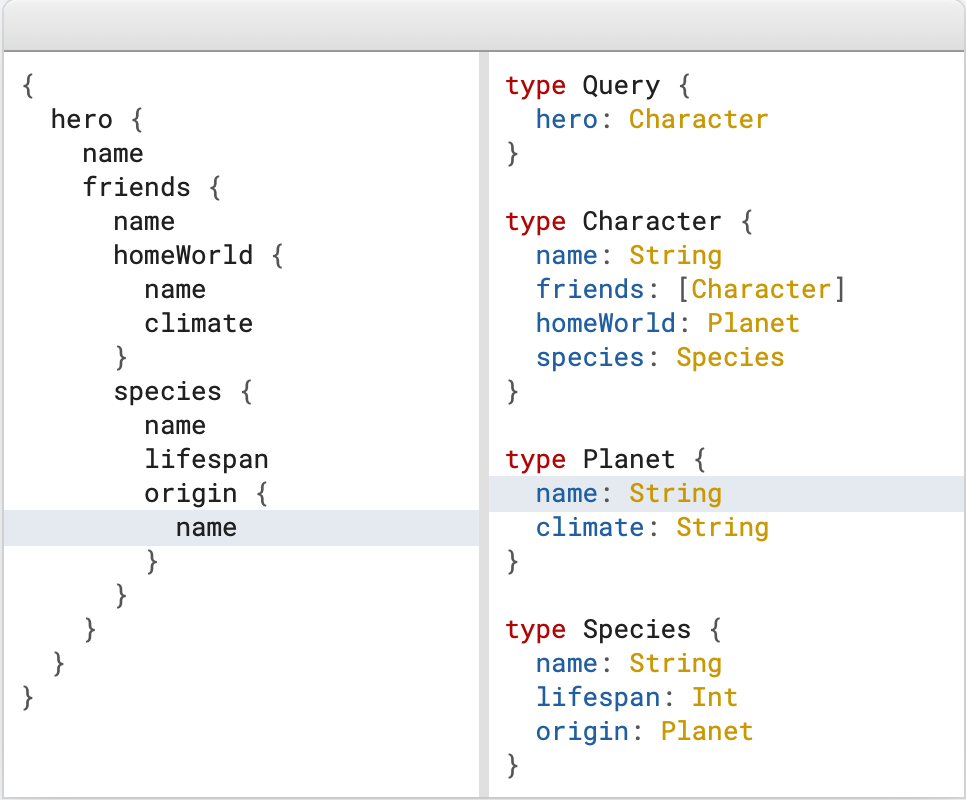
这一特点对于接口文档有了重新定义,后端定义好graph,前后端就可以同时开发业务,之后前端在需要组合类的API业务,只需要在这些原子性的API中组合数据即可。
以上三点就是GraphQL的明显优势
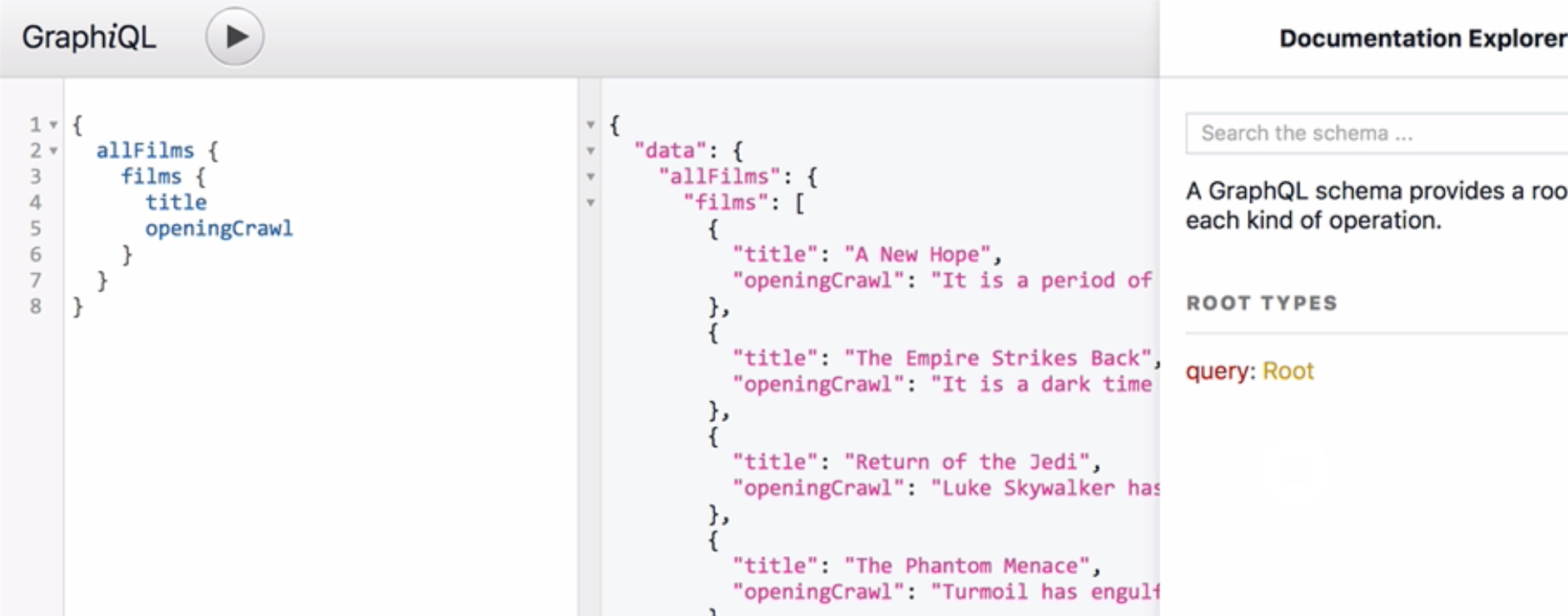
四 方便的调试工具GraphiQL
GraphqiQL是一个用于调试graphql的开发工具,包括调试接口和文档查询,他有代码提示和校验的功能。在代码集成插件后,可以在浏览器直接使用。
五 较低的迁移成本
很多人由于考虑到庞大的老系统,从REST迁移到GraphQL过程中有很高的迁移成本,导致放弃使用GrqphQL。
这一点是多虑了,第一,graphql和rest是可以两种形式并存的,并不是说使用graphql后必须放弃之前的REST方式,其实有一部分的场景还是REST实现更方便;第二,只要选择或者设计好graphql的实现方式,完全可以使用现有的业务代码,可以很快开发出一套graphql的版本。
六 系统可以无感升级
对于API的升级,只要不是删字段的情况,服务端的接口增加字段,增加API方法对于客户端的使用是没有任何影响的,既不会改变URI,也不会造成API升级带来字段冗余的情况。
GraphQL与REST
GraphQL可以认为是REST的改良版。
graphql需要借助REST来暴露一个url地址,通过REST的形式更方便的操作定义的API。
一套系统中GraphQL与REST可以共存,并且很多场景下都是这样的。通过设计也可以共用一套权限验证的逻辑,业务代码就更是能够共用了。
一般情况下,REST是一个API对应一个URI.而GraphQL是可以所有的API共用一个URL,甚至客户端可以根据业务自己组合一个业务上的API。
GraphQL的缺憾
GraphQL有很多优点,但GraphQL也不是完美的。也有一些缺憾的地方。
- GraphQL是Facebook发明的,并将GraphQL的规范开源。但Facebook的后端 设计并未开放,并且很难找到成功的示例。就连GraphQL的封装实现是第三方做的。
- 并不是所有的API都适合GraphQL来做
- 前期没有经过认真设计的GraphQL实现,容易造成一些性能问题
- 首次接触GraphQL的开发者,一定会遇到一些不好解决的问题,如N+1的问题:查询主信息附带子信息的场景,处理不好的话容易造成先根据id查询主表后获取到子表ids,然后循环根据子表id查询子表信息,这就造成了查询n+1次数据库,当然这个问题在REST中也是存在的,只不过GraphQL场景下解决起来似乎更加麻烦一点。权限验证:通常的权限验证是在网关层根据接口路径做的校验,如果是GraphQL的话只有一个URI资源,所以权限验证的方案就得重新设计了...
对GraphQL的期望
选择一个新的技术,一般是为了解决现有的痛点或者是使技术或方法体系能够得到进一步的升级。
这里谈一下笔者对GraphQL的一些期望
- 清晰的描述系统的功能:通过Graph的定义,使上游业务方可以清楚的了解我们开发的API结构,从而能够达到自助调用接口的目的。
- 构建强大的开发者工具:GraphQL是一套规范,基于这套规范开发出一款自动化的工具,如根据GraphQL自动生成SQL调用数据库,自动调用第三方系统,自动生成一些业务计算的逻辑,从而减少后端业务的开发量
GraphQL的执行
GrsaphQL并不是一套神秘的黑盒技术,这是它的优点,让每一个真正使用的它的人先了解它的原理;这也是它的缺点,很多需要实现的功能都需要自己开发。
前边说了GraphQL是一套规范,是一个查询语言,自然就有它的使用规范和操作语法需要学习了。这边简单提一下,Schema中需要定义操作类型,对应的graphql需要定义一系列业务相关的Type,Input...
type Query {
human(id: ID!): Human
}
type Human {
name: String
appearsIn: [Episode]
starships: [Starship]
}
enum Episode {
NEWHOPE
EMPIRE
JEDI
}
type Starship {
name: String
}
有关GraphQL的规范建议到官网上去学习了解:https://graphql.cn/learn/execution/
写在最后的话
GraphQL是2012年产生,与2015年开源的一套规范,相应的各个语言都有第三方实现的一套简单的框架。https://graphql.cn/code/
在国外的一些开发者者手中,陆续有一些自研的插件被开源,使用也很方便,在或许的分享中会有体现。当然,GraphQL在国内还没有大面积使用,包括相关的技术分享也极其保守,很少有人分享自己对GraphQL的设计及问题处理。
很多人觉得,GraphQL出现到现在已经好多年了,现在还是没有火起来,认为GraphQL已经没戏了,如果去了解一下SOAP到REST的演化,或许就不这么想了。也有人认为,GraphQL只适合一些个新业务的小项目去练手,或者老系统中在REST的基础上再维护一套GraphQL,认为GraphQL是上不了台面或扛不起任务的一个技术,笔者认为这个观念有点悲观,一个新技术的流行,是需要全方位的配合,一整套系统中,需要前端,后端,还需要各个产品线的配合,如果只是一个点的试验,确实推行的阻力会很大。还有一些人是主推GraphQL的缺点,以至于一些人了解缺点之后立即放弃并大肆传播,如一些文章标题就是《GraphQL从入门到放弃》《GraphQL使用它的五个理由和不使用的五个理由》...笔者认为,没有完美的技术,我们需要做的是理性的看待新事物,并积极的接受新事物,对应新技术我们应该放大其优点,解决其短板。就像我们接受微服务的时候,并没有因为微服务带来的分布式事物等难题而放弃使用它。
CLC

 浙公网安备 33010602011771号
浙公网安备 33010602011771号