
Python 多进程
python中的多进程最大的好处就是充分利用多核cpu的资源,不像python中的多线程,受制于GIL的限制,从而只能进行cpu分配,
在python的多进程中,适合于所有的场合,基本上能用多线程的,那么基本上就能用多进程。
一,multiprocessing
multiprocessing模块就是跨平台版本的多进程模块,multiprocessing模块提供了一个Process类来代表一个进程对象
实例一:
import multiprocessing,threading
import time,os
def run2():
print('这是多线程启动的')
def run():
print('thread %s is running...'%threading.current_thread().name)
time.sleep(2)
for i in range(5):
print('thread %s >>> %s' % (threading.current_thread().name, i))
t = threading.Thread(target=run2)
t.start()
print('thread %s ended.' % threading.current_thread().name)
if __name__ == '__main__':
print('Parent process %s' % os.getpid())
for i in range(5):
p = multiprocessing.Process(target=run)
print('Child process will start.')
p.start()
p.join()
print('Child process end.')
输出结果:

二,进程间通信
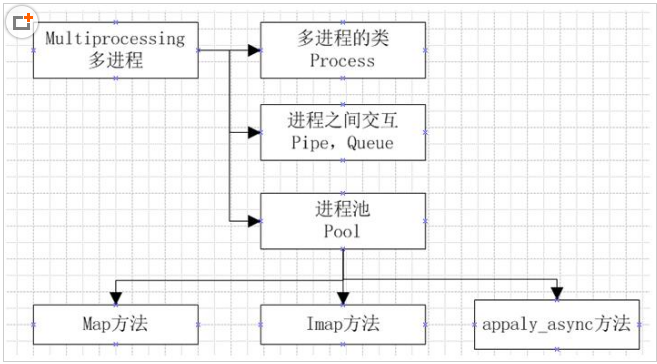
在多进程中,内存数据是不能共享的,从而需要用单独的数据结构来处理共享的数据
Python的multiprocessing模块包装了底层的机制,提供了Queue、Pipes等多种方式来交换数据
multiprocessing.Pipe([duplex])
返回2个连接对象(conn1, conn2),代表管道的两端,默认是双向通信.如果duplex=False,conn1只能用来接收消息,conn2只能用来发送消息.
实例一:queue用来在进程间传递消息,get () /put() 方法
#以Queue为例,在父进程中创建两个子进程,一个往Queue里写数据,一个从Queue里读数据:
from multiprocessing import Process, Queue
import os, time, random
# 写数据进程执行的代码:
def write(q):
print('Process to write: %s' % os.getpid())
for value in ['A', 'B', 'C']:
print('Put %s to queue...' % value)
q.put(value)
time.sleep(random.random())
# 读数据进程执行的代码:
def read(q):
print('Process to read: %s' % os.getpid())
while True:
value = q.get(True)
print('Get %s from queue.' % value)
if __name__=='__main__':
print('Parent process %s' % os.getpid())
# 父进程创建Queue,并传给各个子进程:
q = Queue()
pw = Process(target=write, args=(q,))
pr = Process(target=read, args=(q,))
# 启动子进程pw,写入:
pw.start()
# 启动子进程pr,读取:
pr.start()
# 等待pw结束:
pw.join()
# pr进程里是死循环,无法等待其结束,只能强行终止:
pr.terminate()
输出结果:
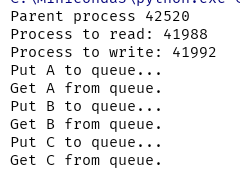
在其中,并没有使用什么其他的代码,主要就是使用Queue来保存数据,从而可以达到进程间交换数据的目的。
实例二:pipe()返回一对连接对象,代表了pipe的两端,每个对象都有send()和recv()方法。
from multiprocessing import Process, Pipe
import os, time, random
# 写数据进程执行的代码:
def write_1(q):
print('Process to write: %s' % os.getpid())
q.send(['A', 'B', 'C'])
time.sleep(random.random())
if __name__=='__main__':
print('Parent process %s' % os.getpid())
parent_conn, child_conn = Pipe()
pw = Process(target=write_1, args=(child_conn,))
pw.start()
pw.join()
print(parent_conn.recv())
输出结果:
Parent process 43784
Process to write: 38380
['A', 'B', 'C']
主要是使用Pipe中返回的两个socket来进行传输和接收数据,在父进程中,使用的是parent_conn,
在子进程中使用的是child_conn,从而子进程发送数据的方法send,而在父进程中进行接收方法recv
三,计算密集型 vs. IO密集型
是否采用多任务的第二个考虑是任务的类型。我们可以把任务分为计算密集型和IO密集型。
计算密集型任务的特点是要进行大量的计算,消耗CPU资源,比如计算圆周率、对视频进行高清解码等等,全靠CPU的运算能力。
这种计算密集型任务虽然也可以用多任务完成,但是任务越多,花在任务切换的时间就越多,CPU执行任务的效率就越低,所以,要最高效地利用CPU,计算密集型任务同时进行的数量应当等于CPU的核心数。
计算密集型任务由于主要消耗CPU资源,因此,代码运行效率至关重要。Python这样的脚本语言运行效率很低,完全不适合计算密集型任务。对于计算密集型任务,最好用C语言编写。
第二种任务的类型是IO密集型,涉及到网络、磁盘IO的任务都是IO密集型任务,这类任务的特点是CPU消耗很少,任务的大部分时间都在等待IO操作完成(因为IO的速度远远低于CPU和内存的速度)。
对于IO密集型任务,任务越多,CPU效率越高,但也有一个限度。常见的大部分任务都是IO密集型任务,比如Web应用。
IO密集型任务执行期间,99%的时间都花在IO上,花在CPU上的时间很少,因此,用运行速度极快的C语言替换用Python这样运行速度极低的脚本语言,完全无法提升运行效率。
对于IO密集型任务,最合适的语言就是开发效率最高(代码量最少)的语言,脚本语言是首选,C语言最差。
四,异步IO
例子:去排队买票,你在这给他说一下你要买票,等到你的时候 他会自动把票给你,节省你排队的时间
知识拓展:
python的多线程只能利用cpu的一个核心,一个核心同时只能运行一个任务那么为什么你使用多线程的时候,它的确是比单线程快
答:如果是一个计算为主的程序(专业一点称为CPU密集型程序),这一点确实是比较吃亏的,每个线程运行一遍,就相当于单线程再跑,甚至比单线程还要慢——CPU切换线程的上下文也是要有开销的。
但是,如果是一个磁盘或网络为主的程序(IO密集型)就不同了。一个线程处在IO等待的时候,另一个线程还可以在CPU里面跑,有时候CPU闲着没事干,所有的线程都在等着IO,这时候他们就是同时的了,
而单线程的话此时还是在一个一个等待的。我们都知道IO的速度比起CPU来是慢到令人发指的,python的多线程就在这时候发挥作用了。比方说多线程网络传输,多线程往不同的目录写文件,等等。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号