【Randomly Wired NN】2019-ICCV-Exploring Randomly Wired Neural Networks for Image Recognition-论文阅读
Randomly Wired NN
2019-ICCV-Exploring Randomly Wired Neural Networks for Image Recognition
来源:ChenBong 博客园
- Institute:FAIR
- Author:Saining Xie,Alexander Kirillov,Ross Girshick,Kaiming He
- GitHub:
- Citation:150+
Motivation
- 卷积网络结构可以抽象为图的结构,节点是操作符(op),连线是数据流动;如VGG是和ResNet基本结构都是一个顺序图(1=>2=>3...),改变的仅仅是布线的方式(加了跳跃的连线)性能就提高很多,因此网络(图)的布线是对性能有很大影响的因素。
- NAS 方法已经对网络的布线和op类型的联合搜索做了很多研究,但网络的布线依然极大程度的依赖手工设计,与ResNet/DenseNet一样,NAS方法的布线方式被局限在一个很小的空间内。
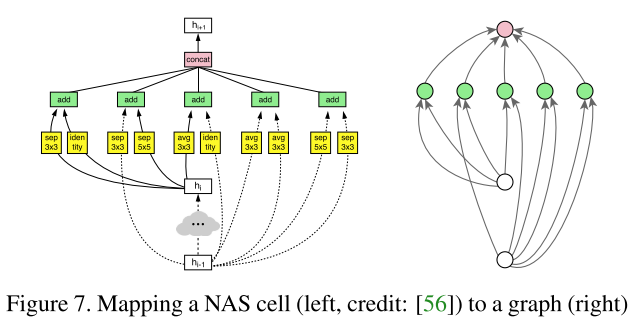
- 因此如果我们放松对布线方式的约束,对网络的性能有什么样的影响?
- 即 对一个给定的图,给定节点,不同的布线(随机的布线)对网络的性能有什么样的影响?
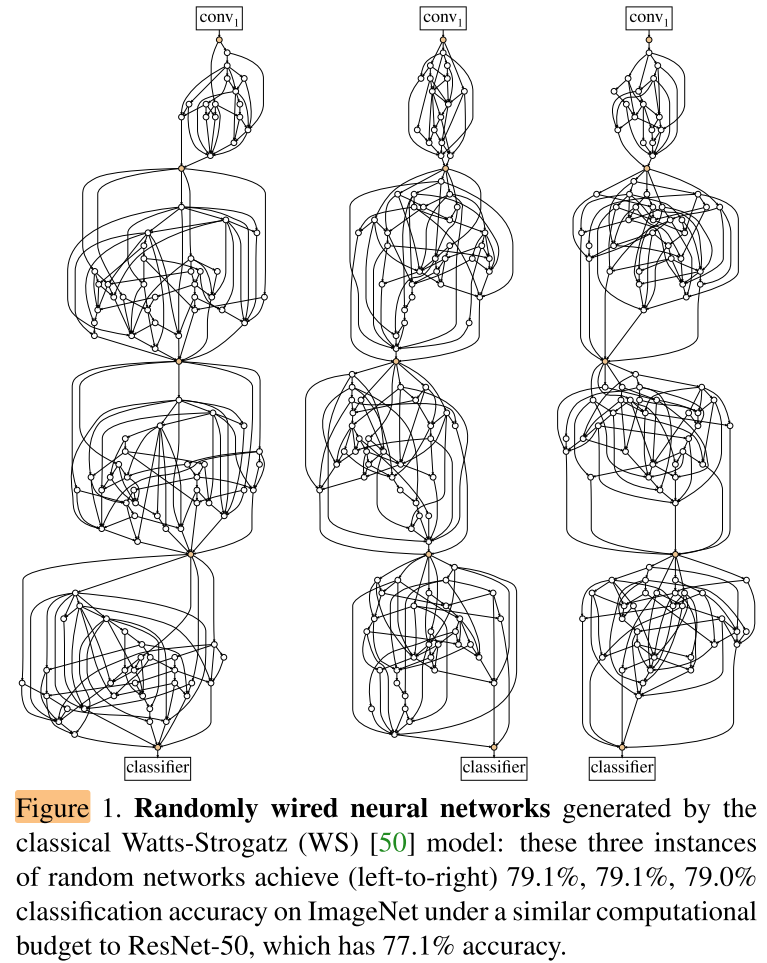
Contribution
- 流程:随机图生成器 => 生成随机无向图 => 转化为有向图DAG => 将DAG映射为卷积网络,得到随机布线卷积网络
- 布线对网络的影响
Method
Edge 边
数据流动,没有参数
节点Node
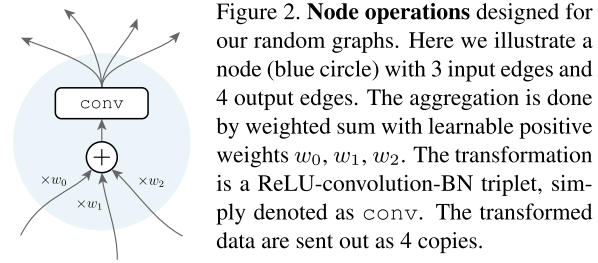
一个节点Node的内部结构:
- Aggregation 聚合:接收1个或多个 input ,进行加权求和,每个input有一个对应的权重参数 \(w_i\)
- Transformation 计算:卷积/池化等操作,这里使用 ReLU-conv-BN,其中conv为3×3可分离卷积
- Distribution 分发:将 output 复制多份,分发给下一个节点
这些结构有以下特性:
- Aggregation 中的 点加操作 保持了输入/输出通道的一致,保持了前后节点计算量相同,防止越靠后的节点计算量越大(ResNet 也是点加,而 DenseNet 的 concat 操作就会导致后续节点计算量增大)
- Transformation 中的计算操作,必须保持输入/输出通道的一致(除了不同stage),以确保(同一个stage)的不同节点的output都可以 Aggregation
- Aggregation 和 Distribution 的 FLOPs 和 参数量 几乎可以忽略不计
- => 当一个节点 Node 的通道数 C 确定以后,该节点的FLOPs和参数量也随之确定,而与节点的输入输出度无关
- => 图的 FLOPs 和 参数量 大致和节点数成正比,而与布线无关
- => 当确定了一张图的所有边(图的布线)后,图的 FLOPs 和 参数量 也随之确定
- => 这些特定将 图的 FLOPs 和 参数量 与 图的布线 脱钩
- => 因此当 图的 FLOPs 和 参数量 相同时,最终网络的性能差异,完全取决于图的布线
Input/Output Node
到目前为止,一个确定了节点数和边(布线)的图 还不是一个有效的网络,因为图可能有多个输入节点(入度为0),和多个输出(出度为0)节点,而有效的网络通常只有1个输入和1个输出。
可以采用一个简单的办法:
- 增加1个额外的节点,连接到原始图的所有的输入节点,该额外的节点将输入分发(Distribution)给所有的输入节点
- 同理,增加1个额外的节点,连接到原始图的所有输出节点,将所有输出直接点加求平均(不是加权求和),作为网络的输出
- 这2个节点不包含卷积等运算,我们提到一个图包含N个节点时,不包含这2个额外的节点
Stage
有了单一的输入和输出节点后,这个图足以表示一个有效的卷积网络,但对于图像分类来说,一般不会全程保持原始的图片分辨率,因此我们将网络分为不同的stage,逐步下采样feature maps(即不同 stage 的 feature maps 分辨率不同)
一个随机生成的图表示一个stage的网络,不同stage之间通过额外的 input/output node 连接
每个stage图中,与 input node 直接连接的 node: stride=2,通道数 ×2
我们研究2种规模的网络:small regime(MobileNet),regular regime(ResNet-50/101),具体配置如下:

Random Graph
那么当给定了N个节点后,如何随机生成图的布线?使用图论中3种随机图生成算法:ER,BA,WS
Erd˝os-R´enyi (ER)
- 给定N个节点,任意2个节点之间的边,以P为概率进行连接,该过程独立于图中其他节点/边的状态
因此该算法只有1个参数P,表示为 ER(P)
Barab´asi-Albert (BA)
- 初始状态,图有M个节点(1<=M<N),该算法每次添加1个新节点和M条新的边(添加的边都与新节点相连)
- 对于新添加的节点,它会和已存在的节点 \(v\) 以概率 \(P_v\) 进行连接,其中 \(P_v\) 与 \(v\) 的度成正比
- 循环添加新节点,直到图有N个节点(一共添加 M-N 个新节点)
因此该算法只有1个参数M,表示为 BA(M),任意一个由 BA(M) 算法生成的图,都有且仅有 M(M-N) 条边。
所有由 BA(M) 生成的图,其实是 N 个节点的图的一个子集,这是由图算法引入的一个潜在先验。
Watts-Strogatz (WS)
Watts-Strogatz 算法生成的图又称为 small-world graphs (小世界图/网络)
在数学、物理学和社会学中,小世界网络是一种数学图的类型,在这种图中大部分的结点不与彼此邻接,但大部分结点可以从任一其他点经少数几步就可到达。若将一个小世界网络中的点代表一个人,而连结线代表人与人认识,则这小世界网络可以反映陌生人由彼此共同认识的人而连结的小世界现象,实际的社会、生态等网络都是小世界网络。
- 初始时,图的节点放到一个环当中(N=7,K=2, 4)
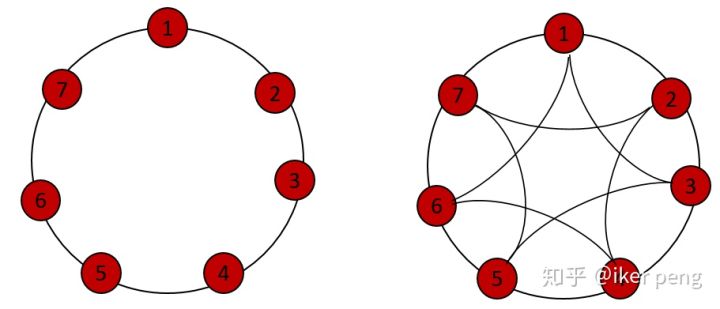
- 以此为基础,每一条边都以概率P断开,并与它之后(顺时针)的某个节点随机的连接,就得到WS随机图。以左图为例:
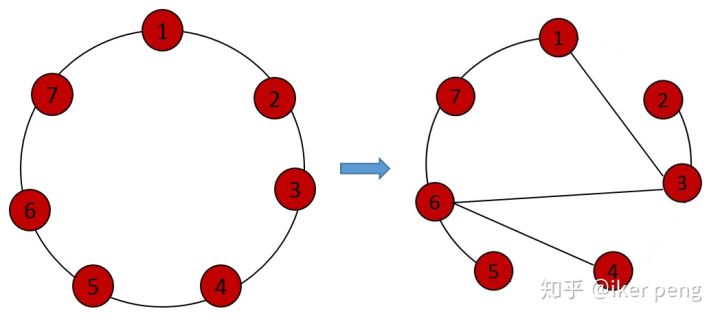
该算法有2个参数,K和P,表示为 WS(K, P),任意一个由 WS(K, P) 算法生成的图,都有且仅有 NK 条边。
由 WS(K, P) 生成的图也是 N个节点图 的一个子集,且该子集与 BA 算法生成的图子集不同,这是另一个由随机图生成算法引入的潜在先验
Design and Optimization
ER(P),BA(M),WS(K, P) 中的P,M,(K, P) 称为随机图算法的参数
每种算法的每种参数配置,称为一种随机网络生成器。
对于一个随机网络生成器我们随机生成多个网络,报告该生成器的平均准确率;对于同一个随机网络生成器,我们发现随机生成的网络 acc 方差很小。
注意,我们没有执行随机搜索,即不是随机生成多个网络取最好的结果,而是只随机生成几个网络。
Experiments
Setup
Architecture details
2种规模:small regime(MobileNet),regular regime(ResNet-50/101)
具体的N和C取决于网络的复杂度:
- 我们设置N=32:
- 对于small regime,C=79;
- 对于regular regime,C=109 or 154
Random seeds
对于每种随机网络生成器,我们随机生成5个网络(使用5个随机种子),train from scratch,评估 acc。
Implementation details
train:
- 100 epoch
- cos lr
- init_lr:0.1
- weight decate:5e-5
- momentum:0.9
- label smoothing:0.1
Analysis Experiments
Random graph generators
Figure 4 visualizes one example graph for each generator.
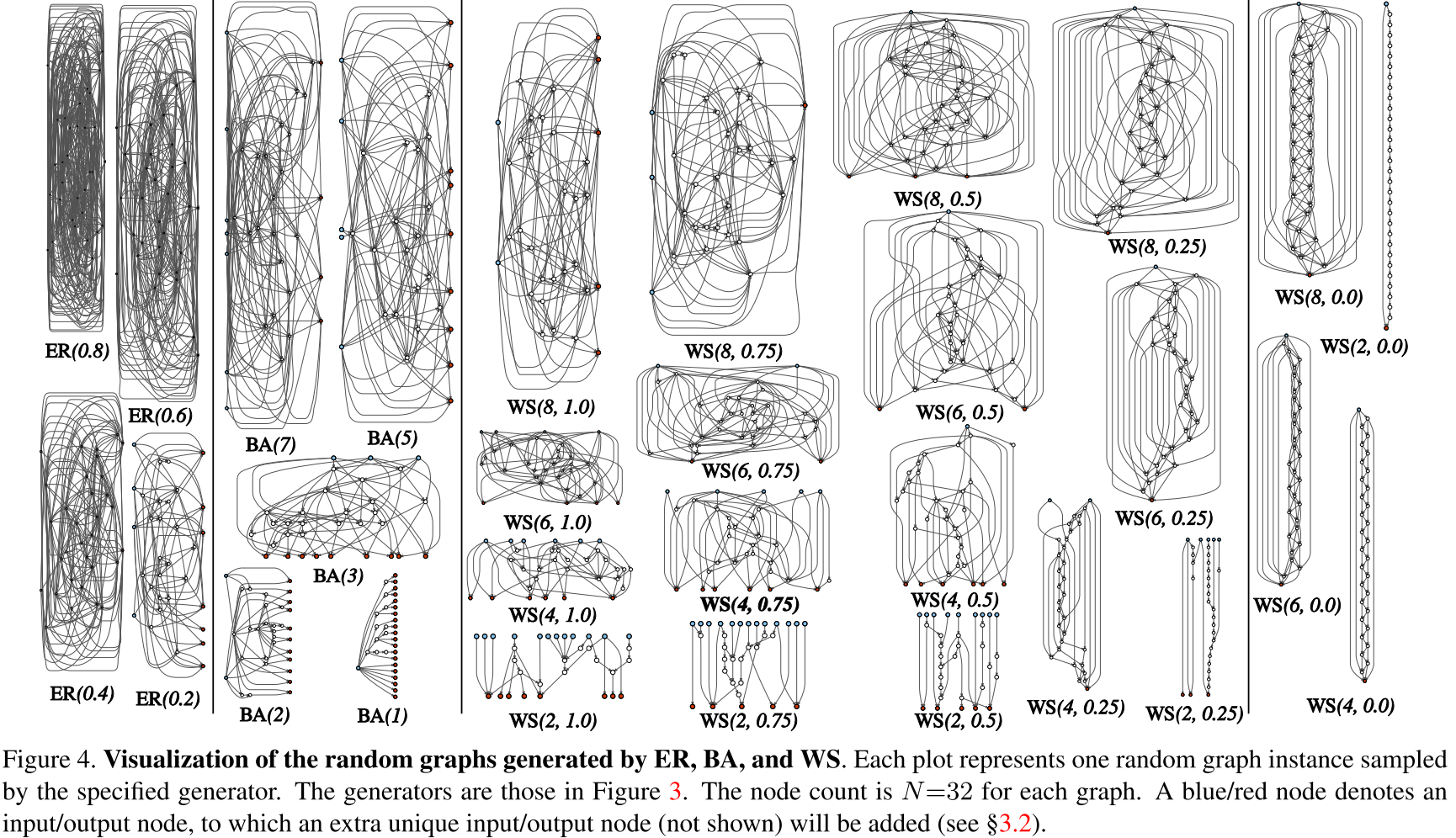
Figure 3 compares the results of different generators in the small computation regime: each RandWire net has ∼580M FLOPs.
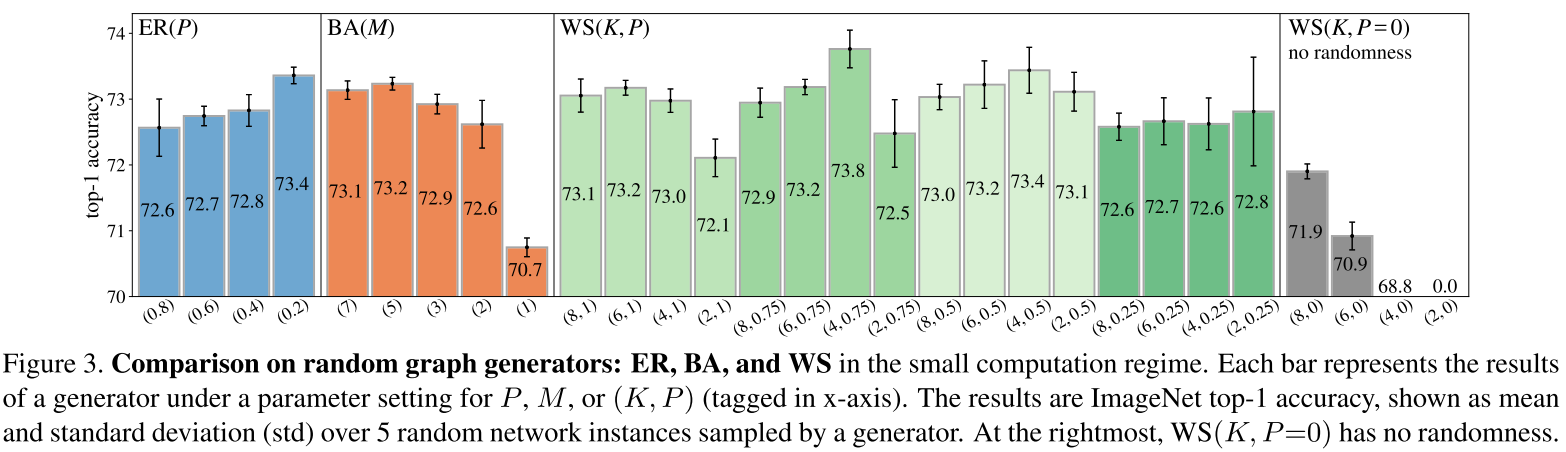
- 所有随机生成的网络都给出了相当不错的性能,没有任何一个网络无法收敛。
- 三种随机图生成算法都有性能超过73%的配置,与最佳配置 WS(4, 0.75) 的差距在1%以内。
- 此外,同一个生成器生成的网络的标准差很小,在0.2%~0.4%之间,作为对比,ResNet-50的标准差为0.1~0.2%
- 不同随机生成器之间性能有一定的差距,BA(1) 比 WS(4, 0.75) 低 3%,这说明布线对网络性能确实有重要作用
- 对于相同的K,WS(K,P=0)(非随机)的结果都比其 WS(K,P>0) (随机)对应的结果差
Graph damage
对已经训练好的网络移除1个节点或1条边后,直接验证性能(类似剪枝,网络的鲁棒性)

- 对于WS生成的网络,当删除节点的输出度较高时,平均精度下降较大。这意味着WS中向许多节点发送信息的 "枢纽 "节点具有影响力。
- 如果一条边的目标节点的输入度较小,去掉这条边对性能影响较大,因为移除该条边相当于移除目标节点的大部分输入。
Node operations
目前为止,我们网络节点的 Transformation 使用都是 3×3 可分离卷积,尝试将其替换为
- 3×3 标准卷积
- 3×3 max-pool => 1×1 卷积
- 3×3 avg-pool => 1×1 卷积
同时调整C,以保持所有替换op后的网络与原网络 FLOPs 相近

横向为不同生成器的平均性能,顺序与图3相同
- 更换了op后,随机网络的性能依然相当好
- 尽管op更换,但网络生成器大致保持了它们的精度排序;事实上,图5中任意两个序列之间的Pearson 相关系数为0.91~0.98。
- 这说明op的选择与网络的布线对网络性能的影响是独立的(NAS做的op和布线的联合搜索,可能是没有必要的,可以分开搜索)
Comparisons
Small computation regime
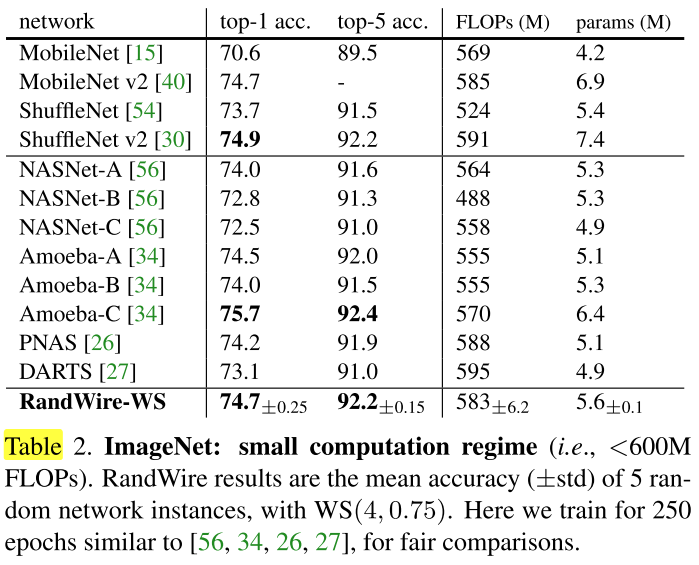
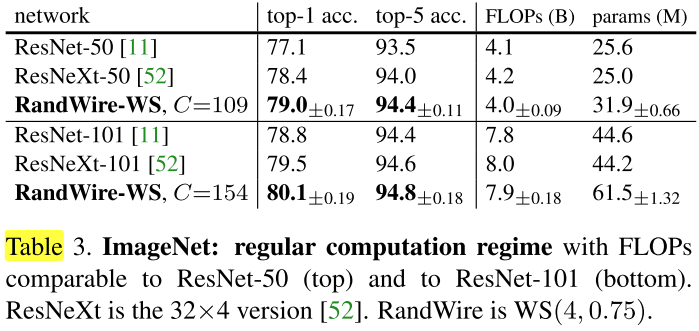
Regular computation regime
Larger computation
为了与NAS方法进一步对比,将表3中的网络,仅仅增大输入分辨率为 320×320,不重训直接验证性能:
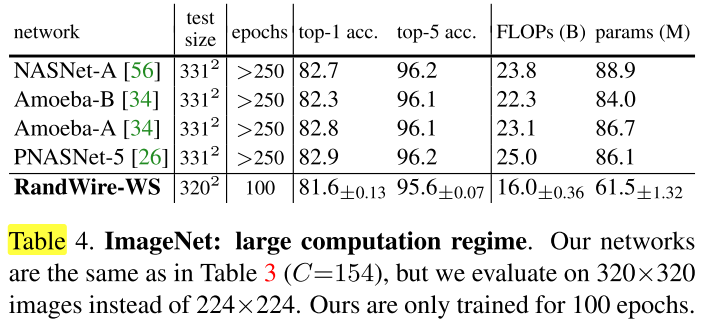
我们的网络比NAS低了 0.7%~1.3%,但我们仅用了 2/3 的FLOPs 和 3/4 的参数量,原始网络只训练了100个epochs,且增大输入分辨率后没有重训。
而NAS是使用250个epoch在331×331的分辨率上进行重训的结果。
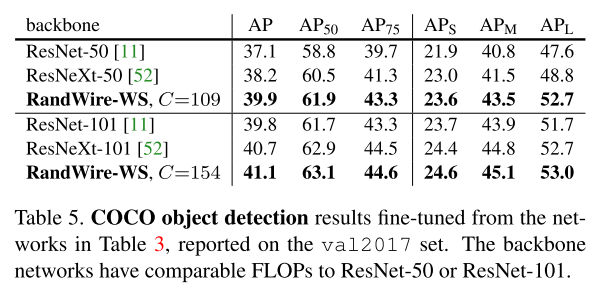
COCO object detection

 浙公网安备 33010602011771号
浙公网安备 33010602011771号