
在分布式系统中经常使用心跳(Heartbeat)来检测Server的健康状况,但从理论上来说,心跳无法真正检测对方是否crash,主要困难在于无法真正区别对方是宕机还是“慢”。传统的检测方法是设定一个超时时间T,只要在T之内没有接收到对方的心跳包便认为对方宕机,方法简单粗暴,但使用广泛。
1. 传统错误检测存在的缺陷
如上所述,在传统方式下,目标主机会每间隔t秒发起心跳,而接收方采用超时时间T(t<T)来判断目标是否宕机,接收方首先要非常清楚目标的心跳规律(周期为t的间隔)才能正确设定一个超时时间T,而T的选择依赖当前网络状况、目标主机的处理能力等很多不确定因素,因此在实际中往往会通过测试或估计的方式为T赋一个上限值。上限值设置过大,会导致判断“迟缓”,但会增大判断的正确性;过小,会提高判断效率,但会增加误判的可能性。但下面几种场景不能使用传统检测方法:
1. Gossip通信
但在实际应用中,比如基于Gossip通信应用中,因为随机通信,两个Server之间并不存在有规律的心跳,因此很难找到一个适合的超时时间T,除非把T设置的非常大,但这样检测过程就会“迟缓”的无法忍受。
2. 网络负载动态变化
还有一种情况是,随着网路负载的加大,Server心跳的接收时间可能会大于上限值T;但当网络压力减少时,心跳接收时间又会小于T,如果用一成不变的T来反映心跳状况,则会造成判断”迟缓“或误判。
3. 心跳检测与结果的分离
并不是每个应用都只需要知道一个目标主机宕机与否的结果(true/false),即有很多应用需要自己解释心跳结果从而采取不同的处理动作。比如,如果目标主机3s内没有心跳,应用A解读为宕机并重试;而应用B则解读为目标”不活跃“,需要把任务委派到其他Server。
也就是说,目标主机是否“宕机”应该由业务逻辑决定的,而不是简单的通过一个超时时间T决定,这就需要把心跳检测过程与对结果的解释相分离,从而为应用提供更好的灵活性。
2. 对传统错误检测的改造
很多人已经意识到了传统检测的缺点,因此提出了各种解决方案,这些方案的重点都放在如何改造超时时间T上,基本原理是在运行时根据前几次心跳时间动态估计下一次的心跳时间。而估计的方法大多通过采用随机抽样寻找心跳时间与网络波动的之间的关系曲线,这些方法有效地弥补了传统检测方法的缺陷,但解决的最贴近实际的还是φ失败检测算法,下面着重介绍这种算法。
3. φ失败检测算法
沿着对传统检测中T改造的思路,φ失败检测采用一个大小为N的滑动窗口(N可配置)来记录最近N次心跳时间间隔(本次心跳收到时间与上次之差),并把此作为随机样本。φ失败检测认为心跳时间间隔符合正态分布:
![]()
而对此函数进行积分,则认为其结果是时间间隔下的心跳接收概率,其积分如下:

所以,如果在[x,+∞)上积分则认为是时间间隔下心跳无法接收的概率:
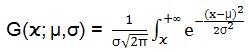
而φ采用下面公式计算:
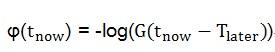
此时计算出的φ是一个数字,是从(tnow-Tlast)到+∞的积分,并取以10为底的对数并转换为正数,其含义是:假如在时间tnow判断目标宕机,则误判的可能性为P=G(tnow-Tlater),即心跳在tnow之后到达的概率。
则,P越大说明误判的概率越大,因为0<P<1,所以P是一个小数,实际结果会是一个很小的小数 ,为表达方便取其对数log(P),又因为0<P<1,故log(P)<0,因此定义φ=-log(P),为一正数。
现在从概率P推导不同φ之间的关系:
- P1、P2为不同时间点的概率,且P2 > P1
- φ1、φ2为对于的φ值(对数取反)
P2>P1 => log(P2) > log(P1) => -log(P2) < -log(P1) => φ2 < φ1
一般设定Φ为临界值,φ为根据当前时间计算出的值,如果φ>Φ,即误判的可能性小于设定的临界值,则认为目标主机已经宕机。
因为对数的关系,Φ=1,则认为误判的可能性不能超过10%,Φ=2,则为1%,Φ=3,则为0.1%...
而正态分布中的σ、μ参数需要根据当前的随机样本动态计算,因为随机样本随网络状况的动态变化,正态分布函数也就随之变化,从而心跳时间也发生变化,但我们只要设定一个误判率(比如Φ=3)则能保证正确的结果。这是传统的基于超时时间T无法做到的。
注:关于根据随机样本计算σ、μ的方法请参考其他文档。
大家可能对上面把对对正态分布函数的积分作为概率的方法不太理解,下面介绍概率密度函数,从而说明为什么要这么做。严格说来这些内容不属于错误检测,只是数理统计的一些常识。
4. 概率密度函数
数理统计中的事件分随机事件和连续事件,随机事件是指事件的取值是可数的(可全部列出的),比如红、黑、黄三种颜色;而连续事件的取值则无法列出,比如心跳间隔时间,而只能属于某个区间。无论是离散还是连续事件,只要发生的足够多都会遵从一定的数理规律,也就是可以用一条曲线来表示其发生的趋势。
对离散事件而言,X轴代表事件的取值,Y轴代表该值发生的概率;而对连续事件,X轴依然代表事件取值,但Y轴代表该值附近的概率变化率,即单位宽度内的概率,而这条曲线称之为概率密度函数,对此曲线积分则得到概率,称之为累积函数,这也是累积失败检测名称的由来。为什么不能像离散事件那样根据随机样本直接绘制概率曲线?因为对连续事件而言,每个具体的取值对应的概率都为0,只有对某个一个区间才存在概率,因此只能绘制其密度函数曲线。很显然,概率密度函数是累积函数的一阶导数。
上面提到的正态分布是一个概率密度函数,当然也可以构造自己的密度函数,但要满足很多性质,具体请参考:概率密度函数。在实际中,连续时间随机分布的概率密度函数一般采用指数分布函数,而不会采用正态分布,当然正态分布函数因为不可积,其积分也很难计算。
指数分布的概率密度函数:
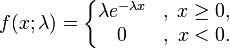 |
 |
对应的累积函数:
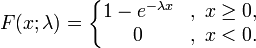 |
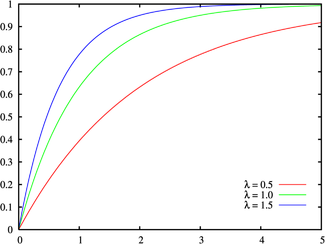 |
5. Cassandra中的应用
Cassandra是基于Gossip的通信,其错误检测方式便采用了累积失败检测,概率密度函数使用了指数分布函数,并没有采用原论文中的正态分布函数,默认情况,Cassandra把Φ设置为8,这个误判概率是相当低的。Cassandra是实现时,是为每个Server都为何一个滑动窗口用来记录其最近的随机样本,指数分布中的参数λ采用滑动窗口中间隔时间的平均值,从而随着网络状况的变化,概率曲线也会发生相应的变化,从而反映真实的网络状况。Cassandra的所有相关实现都封装在FailureDetector类中。
6. 总结
φ失败检测的核心思想是根据最近一段时间的样本估计目标宕机的可能性,从而能根据网络的真实情况正确判断目标是否宕机,当然也做到了检测与结果解释想分离,才能个人提高系统的可扩展性。当然实现的前提是选择一个恰当的概率密度函数,无论是正态分布还是只是分布都是一些经验函数,也可根据曲线拟合构造自己的概率密度函数。
7. 参考资料
【1】The ϕ Accrual Failure Detector
【2】A Gossip-Style Failure Detection Service
【3】Cassandra Failure detection

 浙公网安备 33010602011771号
浙公网安备 33010602011771号