论文阅读:Forwarding Metamorphosis: Fast Programmable Match-Action Processing in Hardware for SDN
摘要:
在软件定义网络中,控制平面在物理上与转发平面分离,控制软件使用开放接口(例如OpenFlow)对转发平面(例如,交换机和路由器)进行编程。
本文旨在克服当前交换芯片和OpenFlow协议的两个局限性:
-
当前的硬件交换机非常严格,仅允许在一组固定的字段上进行“匹配操作”处理
-
OpenFlow规范仅定义了有限的数据包处理动作
我们提出了RMT(可重配置匹配表)模型,这是一种受RISC启发的,用于交换芯片的新流水线体系结构。我们确定了一些基本的动作原语集,以指定在硬件中如何处理标头。 RMT允许在不更改硬件的情况下在现场更改转发平面,像在OpenFlow中一样,程序员可以指定多个宽度和深度任意的匹配表,并且只受整体资源限制,并且每个表都可以配置为在任意字段上进行匹配。但是,与OpenFlow相比,RMT允许程序员更全面地修改所有标头字段。
我们的论文描述了实现RMT模型的64端口10 Gb / s交换芯片的设计,具体设计表明,灵活的OpenFlow硬件交换机实施几乎不需要额外的成本或功能即可实现。
背景/问题:
良好的抽象在计算机系统中至关重要,因为它们可以使系统处理变化并简化下一个更高层的编程。关键的抽象,网络已经取得了进步——TCP提供了端点之间连接队列的抽象,IP提供了从端点到网络边缘的简单数据报抽象, 但是网络内的路由和转发仍然是路由协议和转发行为的混乱综合体,控制和转发平面在封闭的垂直集成内部始终交织在一起。
SDN转发平面的编程控制允许网络所有者在复制现有协议行为的同时向网络添加新功能,OpenFlow作为控制平面和转发平面之间的接口,已经成为众所周知的基于Match+Action的方法。
在通用CPU上的软件中实现Match+Action并不难,但是对于当今大家希望达到的速度,大约1TB/s,我们需要专用硬件的并行性。由于交换芯片的交换速度比CPU快两个数量级,比网络处理器快一个数量级,且这种趋势不太可能改变。 因此,我们需要考虑如何在硬件中实施Match-Action,以利用流水线和并行性,同时综合考虑片上表存储器的限制。
在可编程性和速度之间存在自然的折衷,如今,支持新功能经常需要更换硬件。 如果Match-Action硬件允许只在字段中进行足够的重新配置,以便可以在运行时支持新型的数据包处理,那么它将改变我们对网络编程的看法。 这里真正的问题是,是否可以在不牺牲速度的情况下以合理的成本完成这项工作。
这时有两种可选择的方式:
-
单个匹配表:最简单的方法是在我们称为SMT(单个匹配表)模型中抽象匹配语义。在SMT中,控制器告诉交换机将数据包头字段的任何集合与单个匹配表中的条目进行匹配,SMT假定解析器定位并提取正确的头字段以与表匹配。然而,仔细研究表明,对于经典问题SMT模型的使用成本很高,该表需要存储头的每种组合,在很多情况下会造成浪费。
-
多个匹配表:MMT(多个匹配表)是SMT模型的自然改进。 MMT在一项重要的意义上超越了SMT,它允许多个较小的匹配表通过一个分组字段的子集进行匹配,对照表排列成阶段的流水线。通过修改分组报头或传递给阶段j的其他信息,阶段i可以使阶段j的处理依赖于阶段i <j的处理。但现有的交换芯片实现的表数量很少,在制造芯片时会设置宽度,深度和执行顺序,这严重限制了灵活性。另外,交换芯片仅提供了与常见处理行为相对应的有限动作列表,例如,转发,丢弃,递减TTL,推送VLAN或MPLS标头以及GRE封装。到目前为止,OpenFlow仅指定其中的一个子集,这个动作集不容易扩展,也不是很抽象。
解决办法:
可重配置匹配表:我们探索了一种称为RMT(可重配置匹配表)的MMT模型的改进。像MMT一样,理想的RMT将允许一组管线阶段,每个阶段具有任意深度和宽度的匹配表。
RMT超越了MMT,它允许通过以下四种方式重新配置数据平面:
-
可以更改字段定义并添加新字段
-
可以指定匹配表的数量,拓扑结构,宽度和深度,而仅受匹配位数的总体资源限制
-
可以定义新的动作,例如编写新的拥塞字段
-
可以将任意修改的数据包放置在指定的队列中,以在任何端口子集输出,并为每个队列指定排队规则。
我们描述了一种RMT交换器体系结构,该体系结构允许定义任意标头和标头序列,通过任意数量的表进行字段的任意匹配,任意写入包头字段(而不是包主体)的大小,以及每个包的状态更新。
实现细节:
我们将RMT称为“允许一系列流水线阶段”,每个都具有一个与字段匹配的任意深度和宽度的匹配表”,RMT交换机由解析器组成,以启用字段匹配,然后是任意数量的匹配阶段。
解析器的输出是一个包头向量,它是一组头字段,向量流经一系列逻辑匹配阶段,每个阶段都抽象了图1a中数据包处理(例如,以太网或IP处理)的逻辑单元,每个逻辑匹配阶段都允许配置匹配表大小。
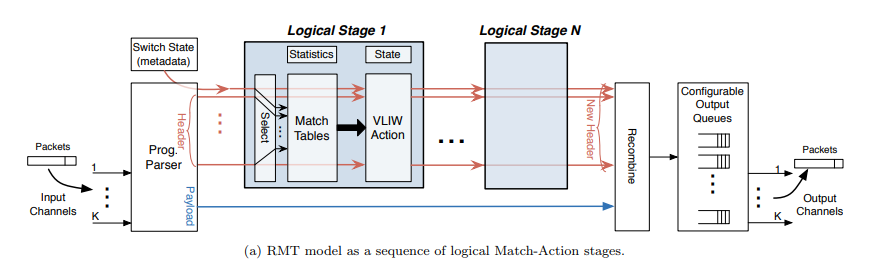
理想RMT允许通过修改解析器来添加新字段,通过修改匹配存储器来匹配新字段,通过修改阶段指令来进行新操作,以及通过修改每个队列的队列规则来进行新排队。最重要的是,它允许将来修改数据平面无需修改硬件。

我们提倡一种如图所示的实现架构,该架构由大量物理流水线阶段组成,根据每个逻辑阶段的资源需求,可以将较少数量的逻辑RMT阶段映射到该阶段。优势在于它使用具有短线的平铺架构,可以以最小的浪费重新配置资源。
物理流水线阶段架构需要限制以允许实现千兆位速度:
-
匹配限制:设计必须包含固定数量的物理匹配阶段以及一组固定的资源
-
数据包标头限制:必须限制包含用于匹配和操作的字段的数据包标头向量
-
内存限制:每个物理匹配阶段都包含大小相同的表内存
-
动作限制:为了实现,必须限制每个阶段中指令的数量和复杂性

 浙公网安备 33010602011771号
浙公网安备 33010602011771号