中国大学mooc机器学习第二天-第一周导学
1.无监督学习

(1)
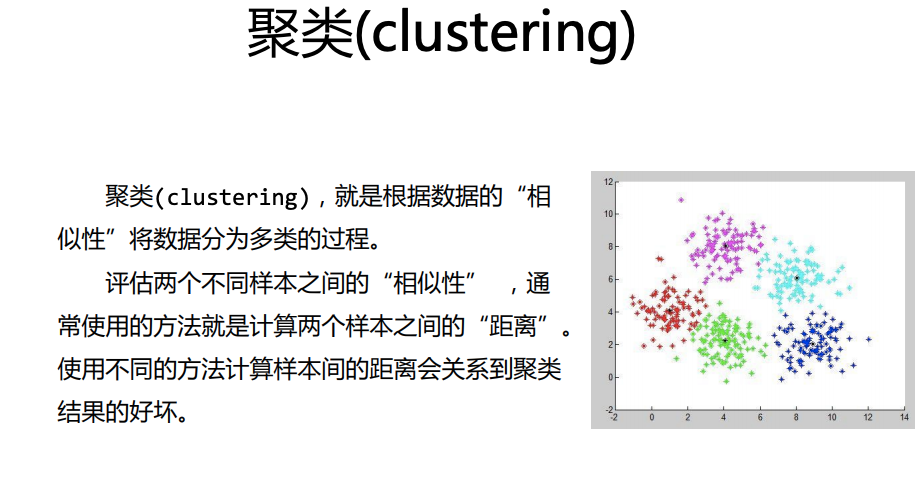
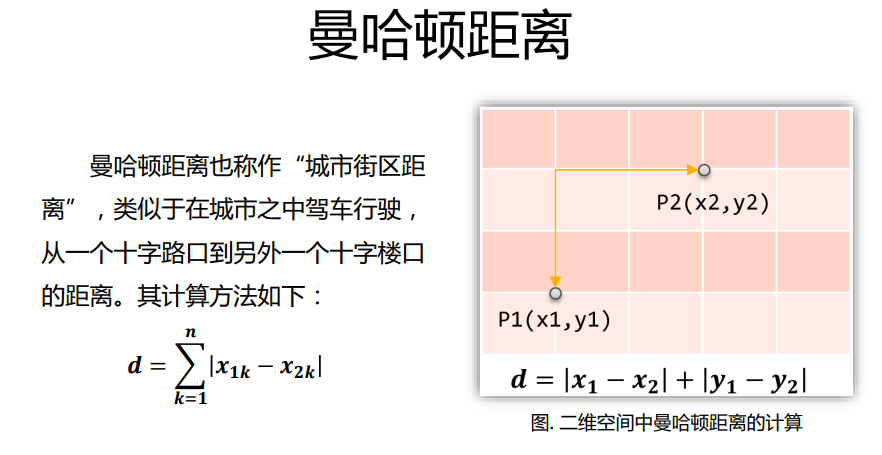
(2)距离介绍



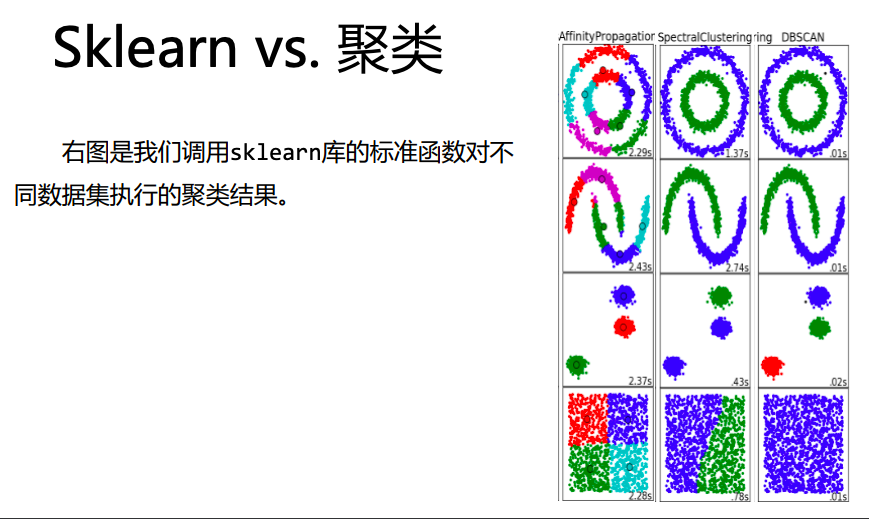
(3)聚类方法对比效果

sklearn.cluster
sklearn.cluster模块提供的各聚类算法函数可以使用不同的数据形式作为 输入:
标准数据输入格式:[样本个数,特征个数]定义的矩阵形式。
相似性矩阵输入格式:即由[样本数目,样本数目]定义的矩阵形式,矩阵中 的每一个元素为两个样本的相似度,如DBSCAN, AffinityPropagation(近邻传 播算法)接受这种输入。如果以余弦相似度为例,则对角线元素全为1. 矩阵中每 个元素的取值范围为[0,1]。
sklearn.cluster
|
算法名称 |
参数 |
可扩展性 |
相似性度量 |
|
K-means |
聚类个数 |
大规模数据 |
点间距离 |
|
DBSCAN |
邻域大小 |
大规模数据 |
点间距离 |
|
Gaussian Mixtures |
聚类个数及其他 超参 |
复杂度高,不适 合处理大规模数 据 |
马氏距离 |
|
Birch |
分支因子,阈值 等其他超参 |
大规模数据 |
两点间的欧式距 离 |
2。降维
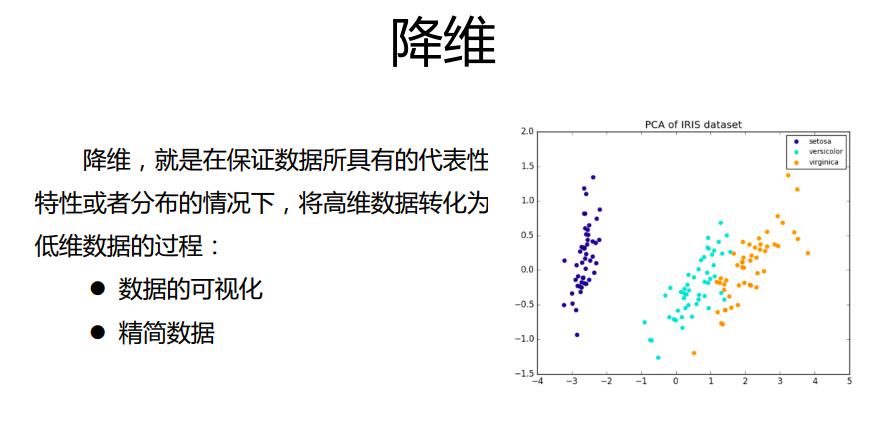
聚类 vs.降维
聚类和降维都是无监督学习的典型任务,任务之间存在关联,比如某些 高维数据的聚类可以通过降维处理更好的获得,另外学界研究也表明代表性 的聚类算法如k-means与降维算法如NMF之间存在等价性,在此我们就不展 开讨论了,有兴趣的同学可以参考我们推荐的阅读内容。
sklearn vs.降维
降维是机器学习领域的一个重要研究内容,有很多被工业界和学术界接受 的典型算法,截止到目前sklearn库提供7种降维算法。
降维过程也可以被理解为对数据集的组成成份进行分解(decomposition) 的过程,因此sklearn为降维模块命名为decomposition, 在对降维算法 调用需要使用sklearn.decomposition模块
sklearn.decomposition
|
算法名称 |
参数 |
可扩展性 |
适用任务 |
|
PCA |
所降维度及其他 超参 |
大规模数据 |
信号处理等 |
|
FastICA |
所降维度及其他 超参 |
超大规模数据 |
图形图像特征提 取 |
|
NMF |
所降维度及其他 超参 |
大规模数据 |
图形图像特征提 取 |
|
LDA |
所降维度及其他 超参 |
大规模数据 |
文本数据,主题 挖掘 |

 浙公网安备 33010602011771号
浙公网安备 33010602011771号