自然语言处理:EncoderDecoder模型 从Encoder-Decoder到AttentionModel再到Transformer
Encoder-Decoder模型
所谓encoder-decoder模型,又叫做编码-解码模型。这是一种应用于seq2seq问题的模型。
那么seq2seq又是什么呢?简单的说,就是根据一个输入序列x,来生成另一个输出序列y。seq2seq有很多的应用,例如翻译,文档摘取,问答系统等等。在翻译中,输入序列是待翻译的文本,输出序列是翻译后的文本;在问答系统中,输入序列是提出的问题,而输出序列是答案。
为了解决seq2seq问题,有人提出了encoder-decoder模型,也就是编码-解码模型。所谓编码,就是将输入序列转化成一个固定长度的向量;解码,就是将之前生成的固定向量再转化成输出序列。
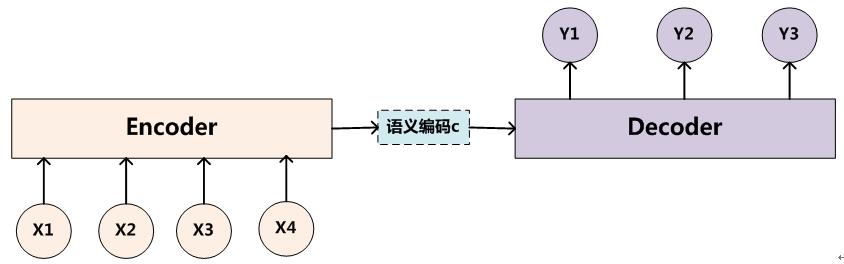
Encoder-Decoder框架可以这么直观地去理解:可以把它看作适合处理由一个句子(或篇章)生成另外一个句子(或篇章)的通用处理模型。对于句子对<X,Y>,我们的目标是给定输入句子X,期待通过Encoder-Decoder框架来生成目标句子Y。X和Y可以是同一种语言,也可以是两种不同的语言。而X和Y分别由各自的单词序列构成:
Encoder顾名思义就是对输入句子X进行编码,将输入句子通过非线性变换转化为中间语义表示C:
对于解码器Decoder来说,其任务是根据句子X的中间语义表示C和之前已经生成的历史信息y1,y2….yi-1来生成i时刻要生成的单词yi
每个yi都依次这么产生,那么看起来就是整个系统根据输入句子X生成了目标句子Y。
Encoder-Decoder是个非常通用的计算框架,至于Encoder和Decoder具体使用什么模型都是由研究者自己定的,常见的比如CNN/RNN/BiRNN/GRU/LSTM/Deep LSTM等,这里的变化组合非常多。
encoder-decoder模型虽然非常经典,但是局限性也非常大。最大的局限性就在于编码和解码之间的唯一联系就是一个固定长度的语义向量C。也就是说,编码器要将整个序列的信息压缩进一个固定长度的向量中去。但是这样做有两个弊端,一是语义向量无法完全表示整个序列的信息,还有就是先输入的内容携带的信息会被后输入的信息稀释掉,或者说,被覆盖了。输入序列越长,这个现象就越严重。这就使得在解码的时候一开始就没有获得输入序列足够的信息, 那么解码的准确度自然也就要打个折扣了.
Attention模型
Soft Attention
Encoder-Decoder模型是没有体现出“注意力模型”的,所以可以把它看作是注意力不集中的分心模型。为什么说它注意力不集中呢?请观察下目标句子Y中每个单词的生成过程如下:
其中f是decoder的非线性变换函数。从这里可以看出,在生成目标句子的单词时,不论生成哪个单词,是y1,y2也好,还是y3也好,他们使用的句子X的语义编码C都是一样的,没有任何区别。而语义编码C是由句子X的每个单词经过Encoder 编码产生的,这意味着不论是生成哪个单词,y1,y2还是y3,其实句子X中任意单词对生成某个目标单词yi来说影响力都是相同的,没有任何区别(其实如果Encoder是RNN的话,理论上越是后输入的单词影响越大,并非等权的,估计这也是为何Google提出Sequence to Sequence模型时发现把输入句子逆序输入做翻译效果会更好的小Trick的原因)。这就是为何说这个模型没有体现出注意力的缘由。这类似于你看到眼前的画面,但是没有注意焦点一样。如果拿机器翻译来解释这个分心模型的Encoder-Decoder框架更好理解,比如输入的是英文句子:Tom chase Jerry,Encoder-Decoder框架逐步生成中文单词:“汤姆”,“追逐”,“杰瑞”。在翻译“杰瑞”这个中文单词的时候,分心模型里面的每个英文单词对于翻译目标单词“杰瑞”贡献是相同的,很明显这里不太合理,显然“Jerry”对于翻译成“杰瑞”更重要,但是分心模型是无法体现这一点的,这就是为何说它没有引入注意力的原因。没有引入注意力的模型在输入句子比较短的时候估计问题不大,但是如果输入句子比较长,此时所有语义完全通过一个中间语义向量来表示,单词自身的信息已经消失,可想而知会丢失很多细节信息,这也是为何要引入注意力模型的重要原因。
上面的例子中,如果引入AM模型的话,应该在翻译“杰瑞”的时候,体现出英文单词对于翻译当前中文单词不同的影响程度,比如给出类似下面一个概率分布值:
(Tom,0.3)(Chase,0.2)(Jerry,0.5)
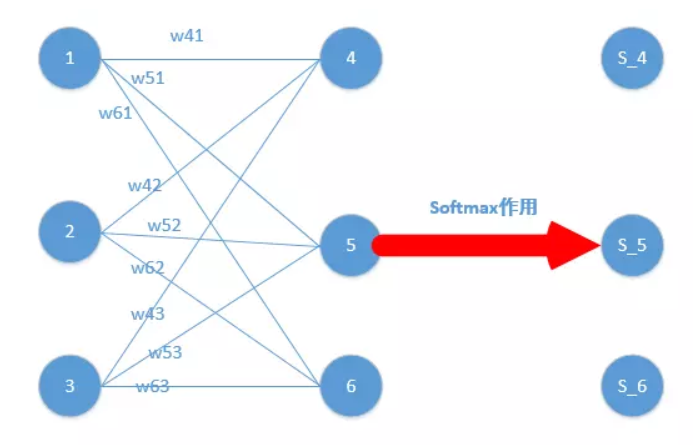
每个英文单词的概率代表了翻译当前单词“杰瑞”时,注意力分配模型分配给不同英文单词的注意力大小。这对于正确翻译目标语单词肯定是有帮助的,因为引入了新的信息。同理,目标句子中的每个单词都应该学会其对应的源语句子中单词的注意力分配概率信息。这意味着在生成每个单词Yi的时候,原先都是相同的中间语义表示C会替换成根据当前生成单词而不断变化的Ci。理解AM模型的关键就是这里,即由固定的中间语义表示C换成了根据当前输出单词来调整成加入注意力模型的变化的Ci。增加了AM模型的Encoder-Decoder框架理解起来如下图所示。
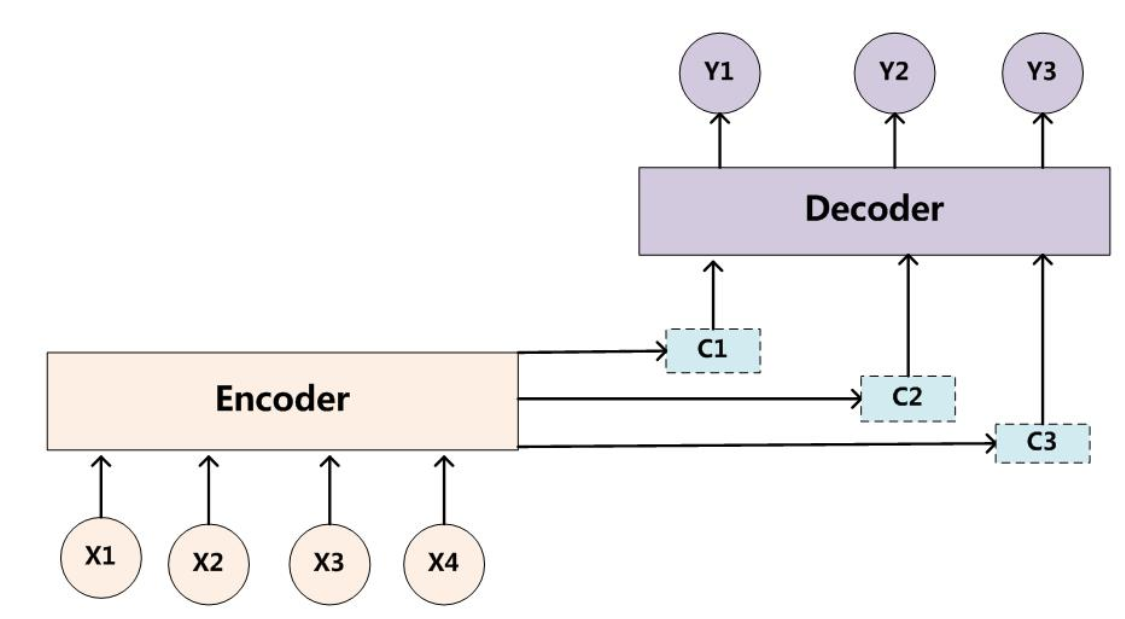
即生成目标句子单词的过程成了下面的形式:
而每个Ci可能对应着不同的源语句子单词的注意力分配概率分布。
其中,\(C_i=\sum\limits_{j=1}^{T_x} \alpha_{ij}h_j\)。
如果把Attention机制从上文讲述例子中的Encoder-Decoder框架中剥离,并进一步做抽象,可以更容易看懂Attention机制的本质思想。
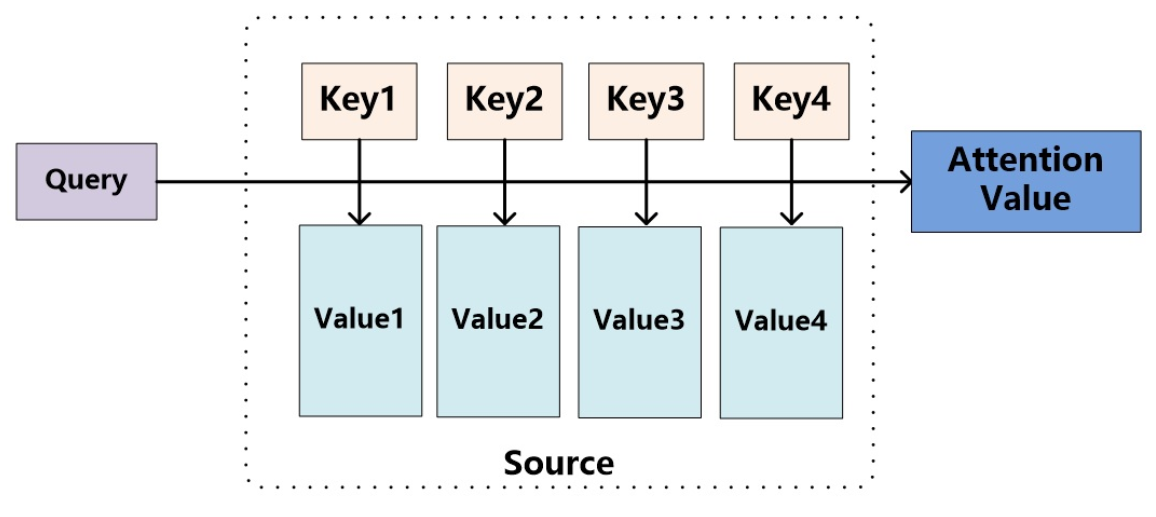
我们可以这样来看待Attention机制:将Source中的构成元素想象成是由一系列的<Key,Value>数据对构成,此时给定Target中的某个元素Query,通过计算Query和各个Key的相似性或者相关性,得到每个Key对应Value的权重系数,然后对Value进行加权求和,即得到了最终的Attention数值。所以本质上Attention机制是对Source中元素的Value值进行加权求和,而Query和Key用来计算对应Value的权重系数。即可以将其本质思想改写为如下公式:
其中对相似度的考量可以通过点积、Cosine相似度以及MLP网络实现。
Hard Attention
其实从上面我们就可以看出,我们通常接触到的Attention都是soft attention。
在 soft attention 机制中,权重\(\alpha_t\)所扮演的角色是Source在时刻 t 输入decoder的信息中的所占的比例。
而在 hard attention 机制中,权重\(\alpha_t\)所扮演的角色是Source在时刻 t 被选中作为输入decoder的信息的概率,有且仅有一个区域会被选中。为此,引入变量\(s_{ti}\) ,当区域 i 被选中时取值为1,否则为0。
更多细节可以看参考文献,或论文NEURAL MACHINE TRANSLATIONBY JOINTLY LEARNING TO ALIGN AND TRANSLATE。
Self-Attention:Transformer
Self Attention也经常被称为intra Attention(内部Attention),属于SoftAttention。在一般任务的Encoder-Decoder框架中,输入Source和输出Target内容是不一样的,比如对于英-中机器翻译来说,Source是英文句子,Target是对应的翻译出的中文句子,Attention机制发生在Target的元素Query和Source中的所有元素之间。而Self Attention顾名思义,指的不是Target和Source之间的Attention机制,而是Source内部元素之间或者Target内部元素之间发生的Attention机制,也可以理解为Target=Source这种特殊情况下的注意力计算机制。其计算过程和上面soft attention的计算方式相同,也是计算Q和K的相似度,进而加权求和得到Q对应的Value值,不过这里的Q是等于K的。
SelfAttention的思想,至此我们也有一个了解了。现在我们来聊聊最近大火的Transformer。
Transformer是一个STOA的机器翻译模型(BERT之前)。它使用了SelfAttention+EncoderDecoder的思想。不同于以往主流机器翻译使用基于RNN的seq2seq模型框架,该论文用attention机制代替了RNN搭建了整个模型框架。并提出了多头注意力(Multi-headed attention)机制方法,在编码器和解码器中大量的使用了多头自注意力机制(Multi-headed self-attention)。
放缩点积
之前我们说过,Attention中对相似度的计算可以通过点积、Cosine相似度以及MLP网络实现。Transformer使用的则是点积的进化版,放缩点积(Scaled dot-product attention)。
它相对点积Attention多除了一个\(\sqrt{d_k}\),\(d_k\)是Query和Key的维度,\(\frac{1}{\sqrt{d_k}}\)则是作为scaling factor,对Q乘K得到的score做归一化,这样保证这个分数不在特征维度很高的时候过大,进而保证梯度稳定。具体softmax求导可以参考简单易懂的softmax交叉熵损失函数求导
Multi-headed attention
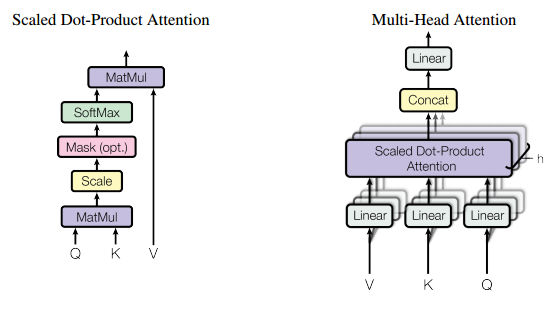
Multi-head attention,就是将input先分别经过3h个不同的线性映射,得到h份Q,K,V,再对每一份进行Scaled dot-product attention,之后将每部分结果合并起来,经过线性映射,得到最终的输出。
Transformer中h默认为8,输入维度默认512(每个单词embedding为512维),原始输入[batch_size,timestep,512],经过83个线性映射,得到8组Q,K,V,其中每个QKV都是[batch_size,timestep,64]。最终得到输出结果,在最后一位concat起来,重新得到[batch_size,timestep,512(64*8)],在经过512到512的线性映射,输出本个Multi-headed attention模块的结果,作为最终结果或者下个Multi-headed attention模块的结果。
以上的过程很多博客理解的是将512切分成8块再经过线性映射,这样是不符合原论文代码的。
附上Github上Star最多的Transformer仓库链接Transformer implemented by TF。
Multi-head Attention流程:
Input: Query\([T_q,d]\) Key\([T_k,d]\) Value\([T_v,d]\)
Linear: Query\([8,T_q,d/8]\) Key\([8,T_k,d/8]\) Value\([8,T_v,d/8]\)
放缩点积:softmax \([8,T_q,T_k]\) 乘V \([8,T_q,d/8]\) concat \([T_q,d]\)
FFN: \([T_q,d]\)
整体结构
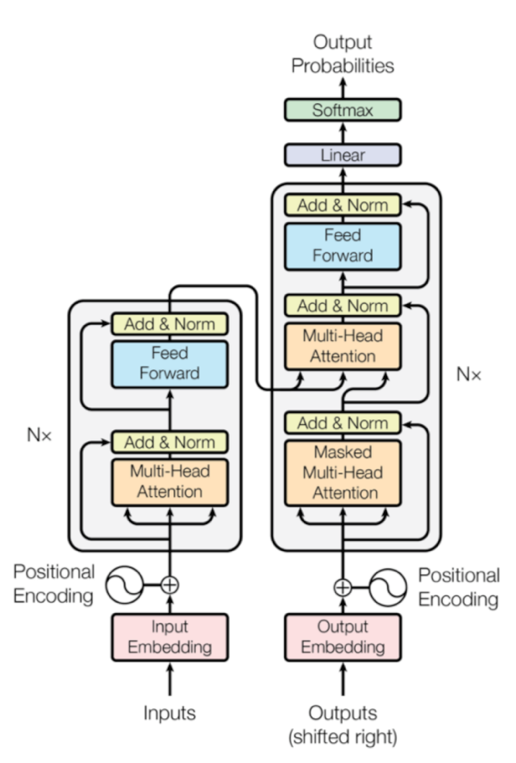
如论文中所设置的,编码器由6个编码block组成,同样解码器是6个解码block组成,不过这些block都不共享参数。与所有的生成模型相同的是,编码器的输出会作为解码器的输入:
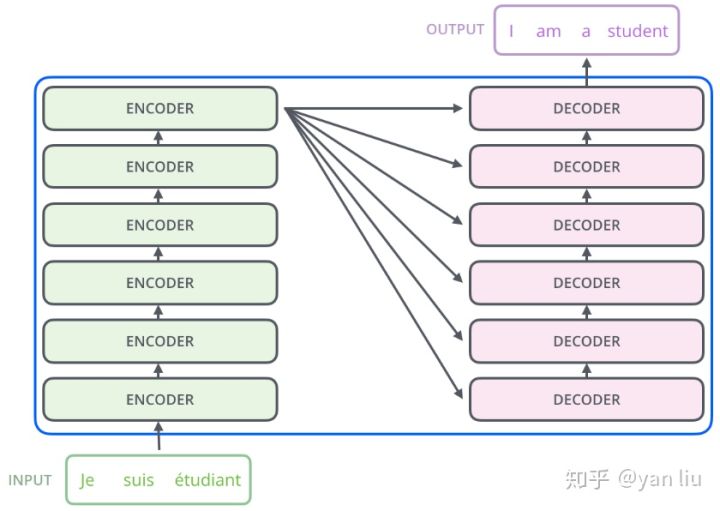
Encoder结构
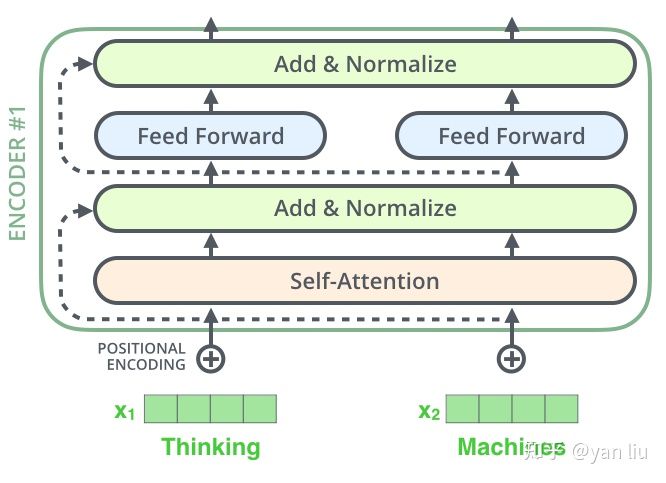
Encoder结构如图,由一个self attention+一个每个timestep共享的前馈神经网络+两次残差连接和LayerNormalization构成。
其中,encoder的这个selfattention是不加causality mask的。(为什么?)应该是为了更好的捕捉单词之间的联系吧,某个单词可能和前后的单词都有关系,就想biLSTM捕捉的序列关系一样。
encoder依次接受input句子中的所有单词,如英译汉:I am a student.->我是学生。经过6个encoder block,输出decoder部分的K和V。
Decoder结构
Decoder中,一个Masked Multi-head attention,加一个Encoder-Decoder Multi-head attention,最终经过一个feed forward网络,每层都加上了残差连接和LayerNormalization,构成一个decoder block。
论文中,解码器由6个block组成。每个block接收上一层decoder block的输出作为Masked Multi-head attention的输入;之后接收encoder最后一层输出的中间语义C作为Encoder-Decoder Multi-head attention的KV,使用Masked Multi-head attention的输出作为Encoder-Decoder Multi-head attention的Query。
考虑只有一个batch,省略batch维度,由于encoder部分为selfattention,故中间语义C:\([T_e,d]\)。
Decoder流程
encoder output as KV: \([T_e,d]\)
decoder input:\([T_d,d]\)
decoder multihead selfattention output as Q:\([T_d,d]\)
decoder encoder_decoder attention output:\([T_d,d]\)
decoder FFN:\([T_d,d]\)
Layer Normalization
BN实际使用时需要计算并且保存某一层神经网络batch的均值和方差等统计信息,对于对一个固定深度的前向神经网络(DNN,CNN)使用BN,很方便;但对于RNN来说,sequence的长度是不一致的,换句话说RNN的深度不是固定的,不同的time-step需要保存不同的statics特征,可能存在一个特殊sequence比其他sequence长很多,这样training时,计算很麻烦。
而且RNN的参数是各时间步共用的,那么当sequencelength不一样,我们去padding0的话,就会影响BN层参数的学习。所以很麻烦。
另外BN对batchsize的大小比较敏感,由于每次计算均值和方差是在一个batch上,所以如果batchsize太小,则计算的均值、方差不足以代表整个数据分布。
与BN不同,LN是针对深度网络的某一层的所有神经元的输入进行normalize操作,即在RNN中,对每个cell的input+State_{t-1}进行normalize。
参考Layer Normalization以及其他的一些Normalization方法
Positional Encoding
self-attention机制建模序列的方式,既不是RNN的时序观点,也不是CNN的结构化观点,而是一种词袋(bag of words)的观点。进一步阐述的话,应该说该机制视一个序列为扁平的结构,因为不论看上去距离多远的词,在self-attention机制中都为1。这样的建模方式,实际上会丢失词之间的相对距离关系。举个例子就是,“牛 吃了 草”、“草 吃了 牛”,“吃了 牛 草”三个句子建模出来的每个词对应的表示,会是一致的。
为了缓解这个问题,Transformer中将词在句子中所处的位置映射成vector,补充到其embedding中去。该思路并不是第一次被提出,CNN模型其实也存在同样的难以建模相对位置(时序信息)的缺陷,Facebook提出了位置编码的方法。一种直接的方式是,直接对绝对位置信息建模到embedding里面,即将词Wi的i映射成一个向量,加到其embedding中去。这种方式的缺点是只能建模有限长度的序列。Transformer文章中提出了一种非常新颖的时序信息建模方式,就是利用三角函数的周期性,来建模词之间的相对位置关系。具体的方式是将绝对位置作为三角函数中的变量做计算,具体公式如下:
其中pos为timestep维度,第几个timestep。d_model为单词embedding的维度,2i表示d_model中第2i维。
该公式的设计非常先验,尤其是分母部分,不太好解释。从笔者个人的观点来看,一方面三角函数有很好的周期性,也就是隔一定的距离,因变量的值会重复出现,这种特性可以用来建模相对距离;另一方面,三角函数的值域是[-1,1],可以很好的提供embedding元素的值。
更多可以参考论文Convolutional Sequence to Sequence Learning
Residual Connection
Deep Residual Learning for Image Recognition 这篇论文认为,理论上,可以训练一个 shallower 网络,然后在这个训练好的 shallower 网络上堆几层 identity mapping(恒等映射) 的层,即输出等于输入的层,构建出一个 deeper 网络。这两个网络(shallower 和 deeper)得到的结果应该是一模一样的,因为堆上去的层都是 identity mapping。这样可以得出一个结论:理论上,在训练集上,Deeper 不应该比 shallower 差,即越深的网络不会比浅层的网络效果差。但为什么会出现图 1 这样的情况呢,随着层数的增多,训练集上的效果变差?这被称为退化问题(degradation problem),原因是随着网络越来越深,训练变得原来越难,网络的优化变得越来越难。理论上,越深的网络,效果应该更好;但实际上,由于训练难度,过深的网络会产生退化问题,效果反而不如相对较浅的网络。而残差网络就可以解决这个问题的,残差网络越深,训练集上的效果会越好。(测试集上的效果可能涉及过拟合问题。过拟合问题指的是测试集上的效果和训练集上的效果之间有差距。)
残差网络通过加入 shortcut connections(Residual Connection),变得更加容易被优化。
在加入了Residual Connection后,我们反向传播的时候,每次更新的梯度都会包含一项对本层网络输入(上层网络输出)的梯度,于是一定程度可以环节梯度消失的问题。
另外,从前向传播的角度去考虑,DNN中每层都可以认为是对input特征的提取,越深的层提取的特征越高阶。加入Residual Connection后,我们可以将更多低阶的信息直连到后面的层,进而保留更多低阶特征的信息。
一些问题:
1.放缩点积相对点积Attention多除了一个\(\sqrt{d_k}\),为什么?
答:\(d_k\)是Query和Key的维度,\(\frac{1}{\sqrt{d_k}}\)则是作为scaling factor,对Q乘K得到的score做归一化,这样保证这个分数不在特征维度很高的时候过大,进而保证梯度稳定。
那么为什么能保证梯度稳定呢?
softmax求导参考带你看懂softmax函数以及相关求导过程。
得到softmax导数:
ij时,$$\frac{\partial s_i}{\partial z_j} =s_i(1-s_i)$$
i!=j时,$$\frac{\partial s_i}{\partial z_j} = -s_is_j$$
其中s_i是softmax结果中第i维的元素,z_i是softmax前第i维的元素。
由此我们可以得到,在ij时,导数图像适合sigmoid函数导数类似的。不加放缩因子时,softmax输入值z_i过大则,对应导数应落在导数图像右边导数接近0处,进而导致梯度接近0,进而导致梯度消失,无法反向传播更新参数。
而i!=j时,由于\(e^{z_i},e^{z_j}\)的浮动范围都更大,所以很容易(有更大概率)导致\(s_i,s_j\)很小,进而导致梯度接近0,进而导致梯度消失。
所以加上放缩因子后能保证梯度的稳定。
那么为什么放缩因子要是\(\sqrt{d}\)呢?
假设q和k是独立随机变量,均值都为0,方差都为1,那么他们的点积和\(qk=\sum_{i=1}^{d_k}=q_ik_i\)的均值也是0,方差是d_k,故需要用\(\sqrt{d}\)来将softmax的输入放缩成一个符合标准正态分布的变量。具体推导见下图:

2.三次mask的顺序调整是否合理?
源代码中在softmax前先对key做了mask(填补的key对应的QK结果矩阵的列填负无穷,经过softmax后得到的结果即为0),然后softmax后选择性的进行causality mask,最后对query进行mask(对填补的query对应softmax结果矩阵的行填0)。
那么为什么不在softmax前,对key和query都做key-mask(填负无穷),或者在softmax后,对key和query都做query-mask(填0)呢?
从效果出发,结果是一样的。
如果都在softmax前进行key-mask,那么容易出现一行都是负无穷,进而梯度为0(上面问题1推到过)。不过,因为是填补的样本行,所以本来反向传播就应该截断了。所以也不会有梯度消失的问题。
综上两点,个人认为,调整顺序也是合理的。原有顺序也是合理的。
3.为什么要对input进行Linear操作(得到QKV)?
答:我们发现在selfAttention中是没有这个环节的,只有MultiheadAttention中有,所以这个操作就是为了将input映射到子空间,进而通过反向传播找到更适合做QKV的子表示空间。
4.为什么要进行FFN操作?
我们知道,Transformer中的FFN是一层512映射到2048的非线性变化(Relu)加一层2048到512的线性变化。那么为什么要这么做呢?
其实这个问题可以等价为,CNN中为什么最后都要加一层全连接层呢?
在CNN中,卷积块中的卷积的基本单元是局部视野,用它类比我们的眼睛的话、就是将外界信息翻译成神经信号的工具,它能将接收的输入中的各个特征提取出来;至于 NN(神经网络)块、则可以类比我们的神经网络(甚至说、类比我们的大脑),它能够利用卷积块得到的信号(特征)来做出相应的决策。概括地说、CNN 视卷积块为“眼”而视 NN 块为“脑”,眼脑结合则决策自成。
用机器学习的术语来说、则卷积块为“特征提取器”而 NN 块为“决策分类器”。
而他的作用就是:全连接层则起到将学到的“分布式特征表示”映射到样本标记空间的作用。
而事实上,CNN 的强大之处其实正在于其卷积块强大的特征提取能力上、NN 块甚至可以说只是用于分类的一个附属品而已。我们完全可以利用 CNN 将特征提取出来后、用之前介绍过的决策树、支持向量机等等来进行分类这一步而无须使用 NN 块。
所以Attention Block中的FFN是为了将Attention操作后得到的结果矩阵映射到更适合作为结果/下层输入的表示空间。
而最终decoder后的Linear模块也是为了将decoder的结果映射到一个和我们备选词库一样长度的向量中去,进而进行softmax。
5.哈夫曼树和负采样的方法对使用softmax激活的网络参数进行更新。
参见论文word2vec Parameter Learning Explained
参考资料
https://blog.csdn.net/u014595019/article/details/52826423 Encoder-Decoder模型和Attention模型
https://blog.csdn.net/malefactor/article/details/78767781 Encoder-Decoder模型和Attention模型2
https://blog.csdn.net/malefactor/article/details/50550211 自然语言处理中的Attention Model:是什么及为什么
https://blog.csdn.net/nbawj/article/details/80557237 Soft和Hard Attention
https://tobiaslee.top/2018/05/13/Attention-Notes/
https://baijiahao.baidu.com/s?id=1622064575970777188&wfr=spider&for=pc
https://blog.csdn.net/qq_41664845/article/details/84969266
https://www.jianshu.com/p/83de224873f1 这篇文章很好的讲解了为什么要在decoder部分输入(shifted right output)。
https://zhuanlan.zhihu.com/p/48508221 这篇文章则讲了很多到位的细节。
https://blog.csdn.net/QcloudCommunity/article/details/80972726 这篇文章则很好的介绍了从RNN到CNN到Attention的发展历程。
https://segmentfault.com/a/1190000015575985 Positional Encoding
https://www.cnblogs.com/wuliytTaotao/p/9560205.html 残差网络
https://daiwk.github.io/posts/platform-tensor-to-tensor.html#423-position-wise-feed-forward-networks
https://blog.csdn.net/weixin_39123145/article/details/82968189 CNN入门讲解-为什么要有最后一层全连接?

 浙公网安备 33010602011771号
浙公网安备 33010602011771号