JavaScript under the hood
js引擎
JavaScript引擎可以简单理解为一种执行JavaScript代码的计算机程序。
每个浏览器都有自己的js引擎,最广为人知的可能是谷歌Chrome的V8引擎(它同样是JavaScriptRuntime Node.js的解析引擎)。其他浏览器都拥有自己的js引擎。
call stack & heap
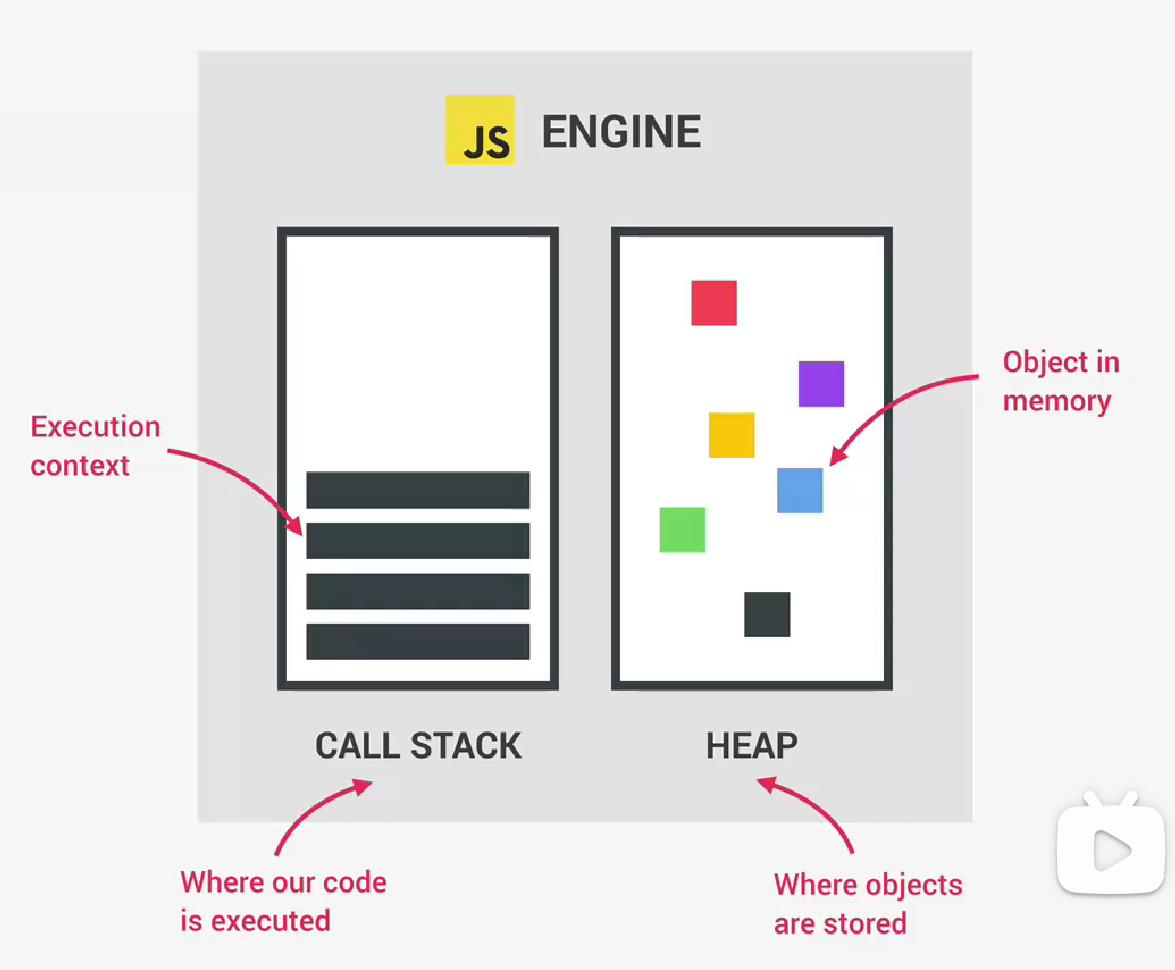
任何js引擎总是包含一个call stack和一个heap。
- call stack是实际执行代码的地方,也就是说,js代码实际上是在js引擎的call stack中执行的(准确来说是在call stack的execution context中执行)。
- heap是一个非结构化内存池,它存储了应用程序需要的所有对象。
现代JavaScript即时编译
计算机的处理器只懂得0和1,因此每个程序最终都需要转换为机器代码来执行,这个转换的过程可以通过compilation或interpretation来实现。
- compilation:整个源代码立即编译为机器代码,这个机器代码可被转换为能在任何计算机上执行的可移植文件。(先编译,后执行)

- interpretation:有一个贯穿源代码的解释器并逐行执行。代码是同时读取和执行的。源代码转换为机器代码的过程在执行之前(right before),而不是提前转换(ahead of time)。

JavaScript曾经是一种纯粹的interpreted language,但解释型语言执行速度慢,这是在构建大型项目时无法忍受的。
因此,现代JavaScript现在混合使用compilation和interpretation。这被称为just-in-time compilation(JIT)。这种方法将整个源代码编译成机器代码(但没有可移植文件可执行),然后立即执行。

现代JavaScript的JIT compilation过程
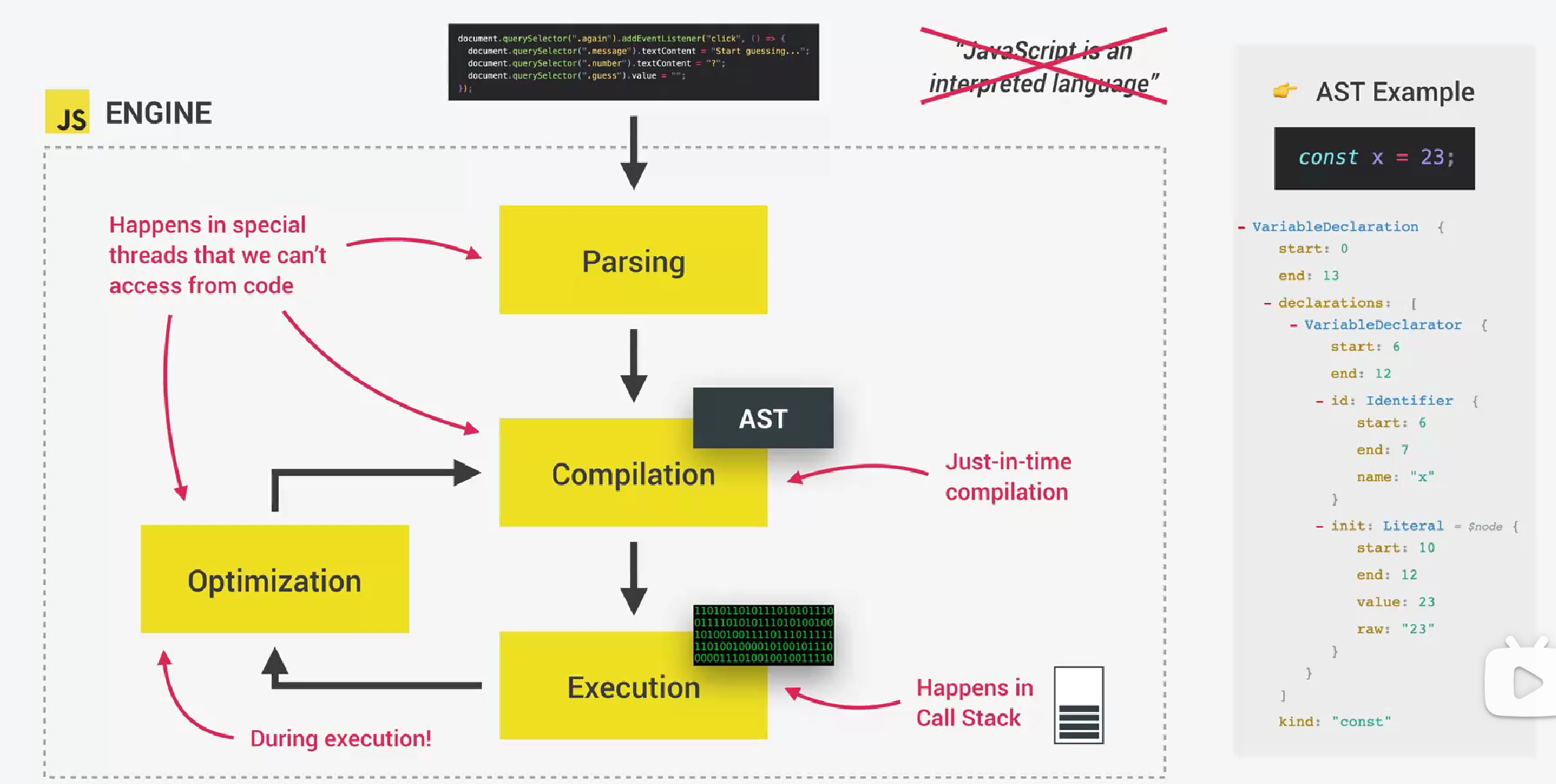
当一段JavaScript代码进入引擎时,会经历如下四个步骤(注意下面四个步骤都是发生在js引擎中):
- 解析代码(Parsing):在解析过程中,源代码被解析成名为抽象语法树(AST)的数据结构。这是通过首先将每一行代码拆分为有意义的片段,比如const、function关键字。然后将所有这些片段以结构化的方式保存到语法树中。这个步骤同样会检查是否存在语法错误。生成的AST之后会被用来生成机器代码
- 编译代码(Compilation):将上一步生成的AST编译成机器代码。这个机器代码会立即进入js引擎的call stack被运行
- 运行代码(Execution):具体执行的过程在下一节
- 优化代码(Optimization):代码运行之后整个过程并没有结束,现代js有一些非常聪明的优化策略:先创建一个未优化版本的机器代码,只是为了让它能尽快开始执行。然后在后台,这个代码正在被优化,并且在已运行的程序执行期间重新编译。在每次优化之后,原本未优化的代码将被转换为新的优化过的代码,这个过程不会中断执行过程。这个过程正是现代引擎如V8速度之快的关键。所有这些parsing、compilation和optimization发生在引擎内部的一些特殊thread中,我们无法通过代码访问,也就是说这个过程完全与main thread分离(即进入call stack,执行代码)。
不同的引擎会有轻微区别,但大体来说,这就是现代JIT compilation的样子。
JavaScript Runtime in the browser
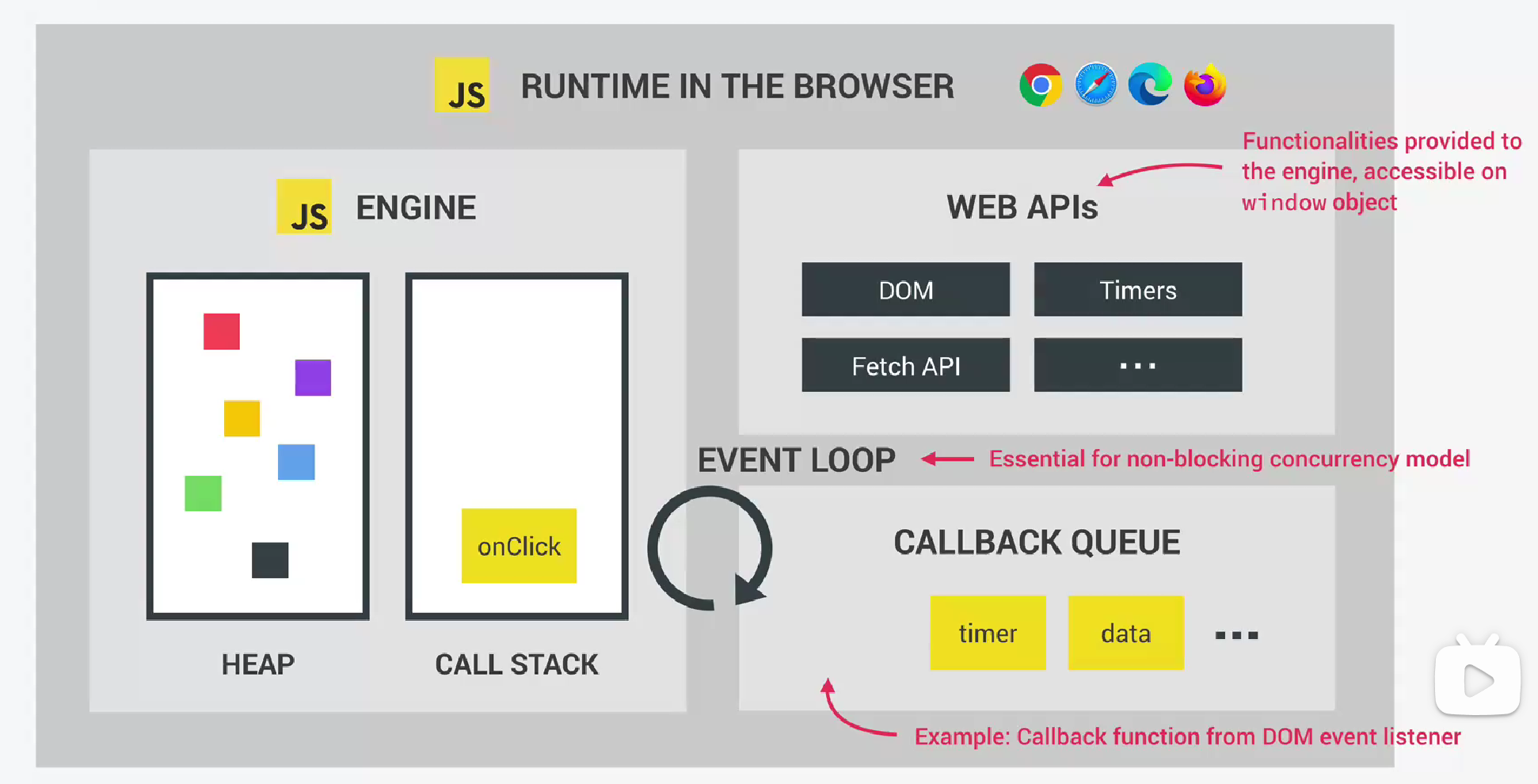
我们可以把js runtime想象成一个大容器,里面包含使用JavaScript需要的所有东西(可以类比js代码是披萨,那么js runtime就是披萨盒,里面除了有披萨还有吃披萨需要的东西,如手套、叉子等等)。最常见的JavaScript runtime是浏览器。浏览器作为JavaScript runtime包含以下三个部分:
- js引擎:任何js runtime的核心都是js引擎。没有引擎就没有runtime。
- web APIs:除了js引擎之外,我们同样需要访问web apis,从本质上来说,web API是提供给js引擎的功能,但实际上并不是js语言本身。JavaScript通过全局窗口对象(global window object)访问这些api。
- 回调序列:一个典型的JavasCript Runtime,还包含一个callback queue。这是一个包含所有准备执行的回调函数的数据结构。例如我们为DOM元素添加一个事件处理函数,这些事件处理函数也叫做callback function。当事件发生,首先callback函数会被放入callback queue,然后当call stack为空时,回调函数被传递到call stack,从而可以执行。这是通过一种叫做事件循环(event loop)的方式发生的。事件循环将回调函数从callback queue取出,然后将它们放入call stack,从而可以执行它们。事件循环是JavaScript非阻塞并发模型的核心。
JavaScript Runtime in Node.js
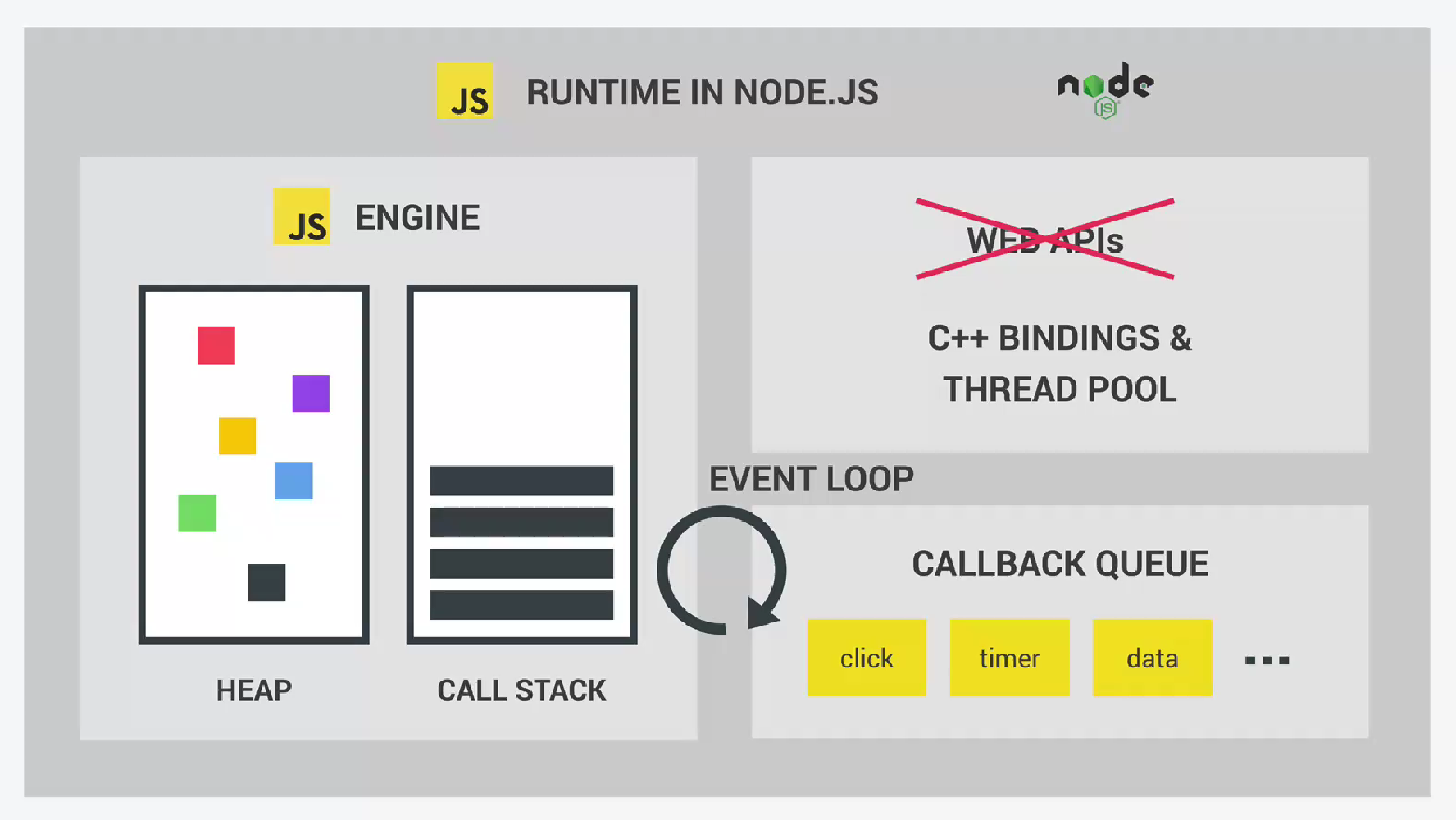
nodejs中的Js运行时和浏览器中的js运行时看起来很相似。但没有web api(因为它们是浏览器提供的),相反它有多个C++绑定和线程池(thread pool)。
JavaScript代码是怎样执行的
从上面可以知道,JavaScript代码在js引擎的call stack中执行。代码进入引擎,在经历了解析(parse)和编译(compile)之后立即进入call stack执行。那它具体是怎么执行呢?
- 创建全局执行上下文:假设一段代码刚刚完成编译,现在它可以被执行了,此时js引擎会创建一个全局执行上下文(global execution context)用于top-level代码,即不在任何函数内部的代码。也就是说,一开始只有函数之外的代码才会被执行。
执行上下文可以理解为一种环境(同样可以类比披萨和披萨盒),js代码可以在此环境中执行。它像一个储存所有必要信息的盒子,以便执行一些js代码。JavaScript代码总是在执行上下文中运行。
无论一个JavaScript项目多复杂,都只有一个全局执行上下文。它总是作为默认上下文存在,是执行top-level代码的地方。
- 执行top-level code:全局执行上下文创建后,顶层代码将在其中执行。执行本身只是计算机的CPU处理机器代码,没什么好说的。
- 执行函数:一旦顶层代码执行完成,当有函数调用时,调用的函数最终也开始执行:对于每个函数调用,都会创建一个新的执行上下文,包含运行函数所有必要的信息。当所有函数都被执行完成后,js引擎会一直等待回调函数到达并执行。
这些所有的执行上下文加在一起,组成了call stack。也就是说,call stack = global execution context + execution contexts(function1、function2...)
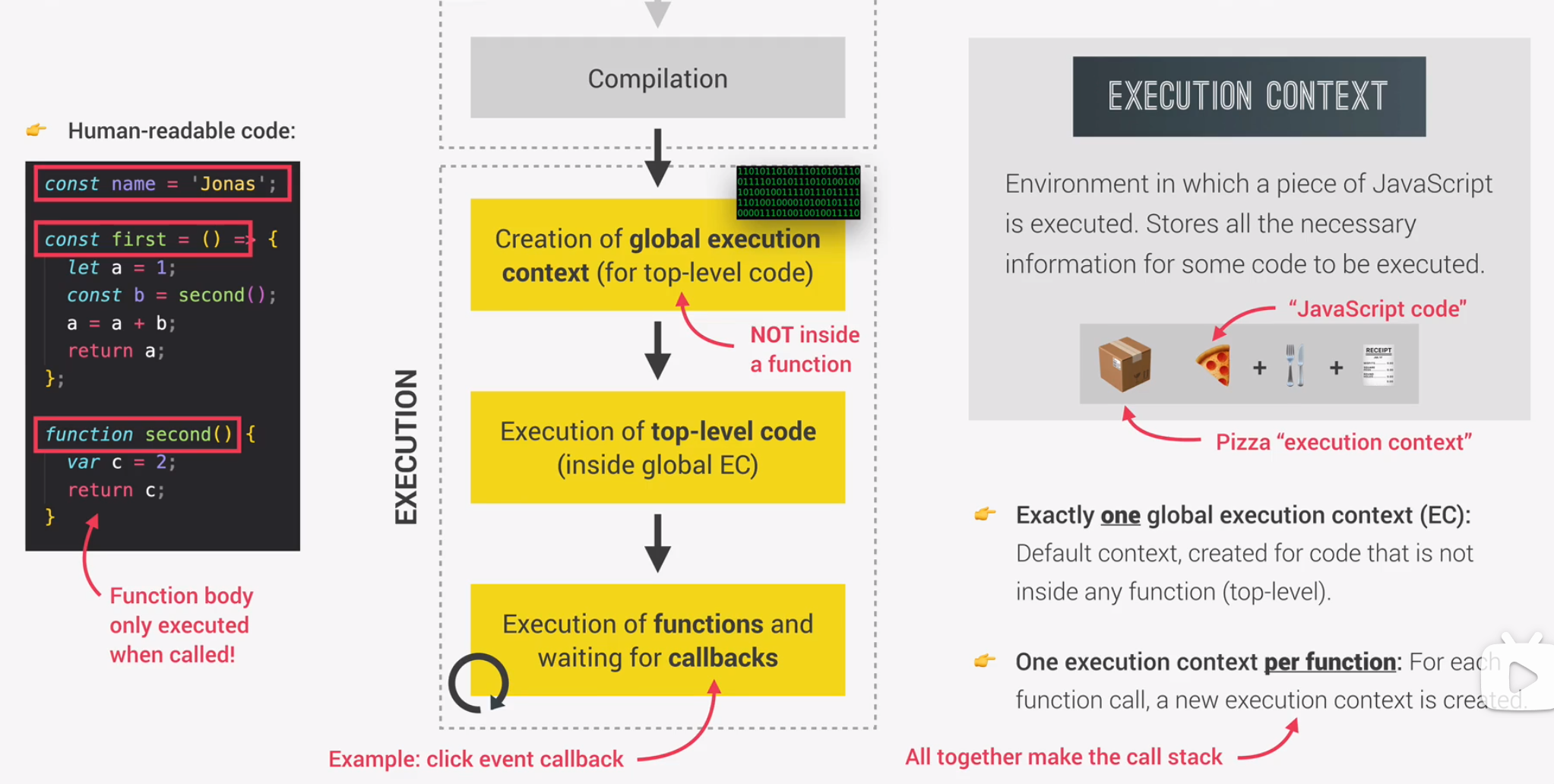
执行上下文由什么组成
- variable environment:变量环境中储存了所有的变量、函数声明,还有一个特殊的arguments对象,其中包括任何传递到当前函数的执行上下文的参数。
- scope chain:包含对当前函数之外定位变量的引用。
- this keyword:在创建阶段生成的,执行之前发生
注意:箭头函数的执行上下文不包含上面提到的argument对象和this关键字。相反,它们可以从最近的父函数(closest regular function parent)使用argument对象和this关键字。
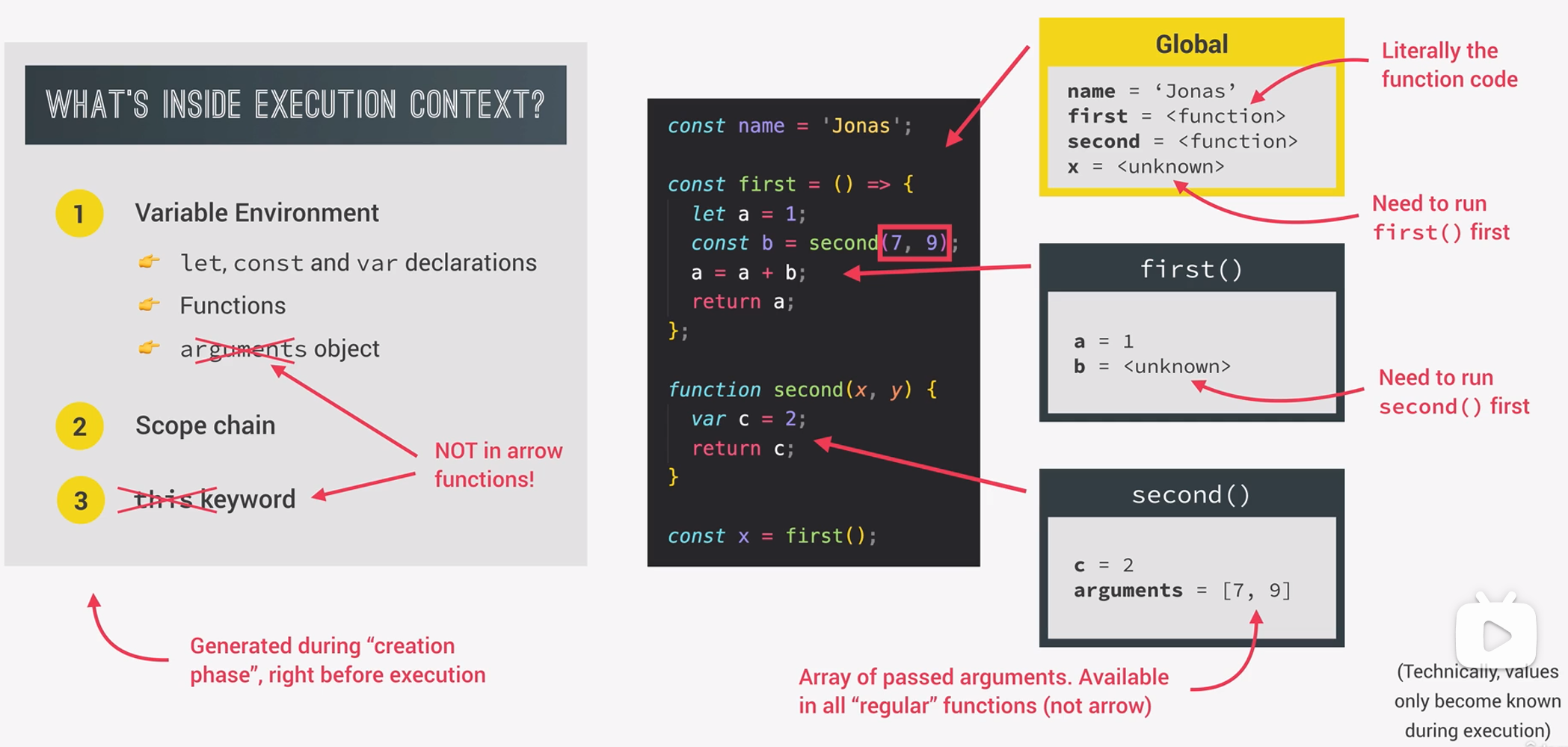
什么是call stack
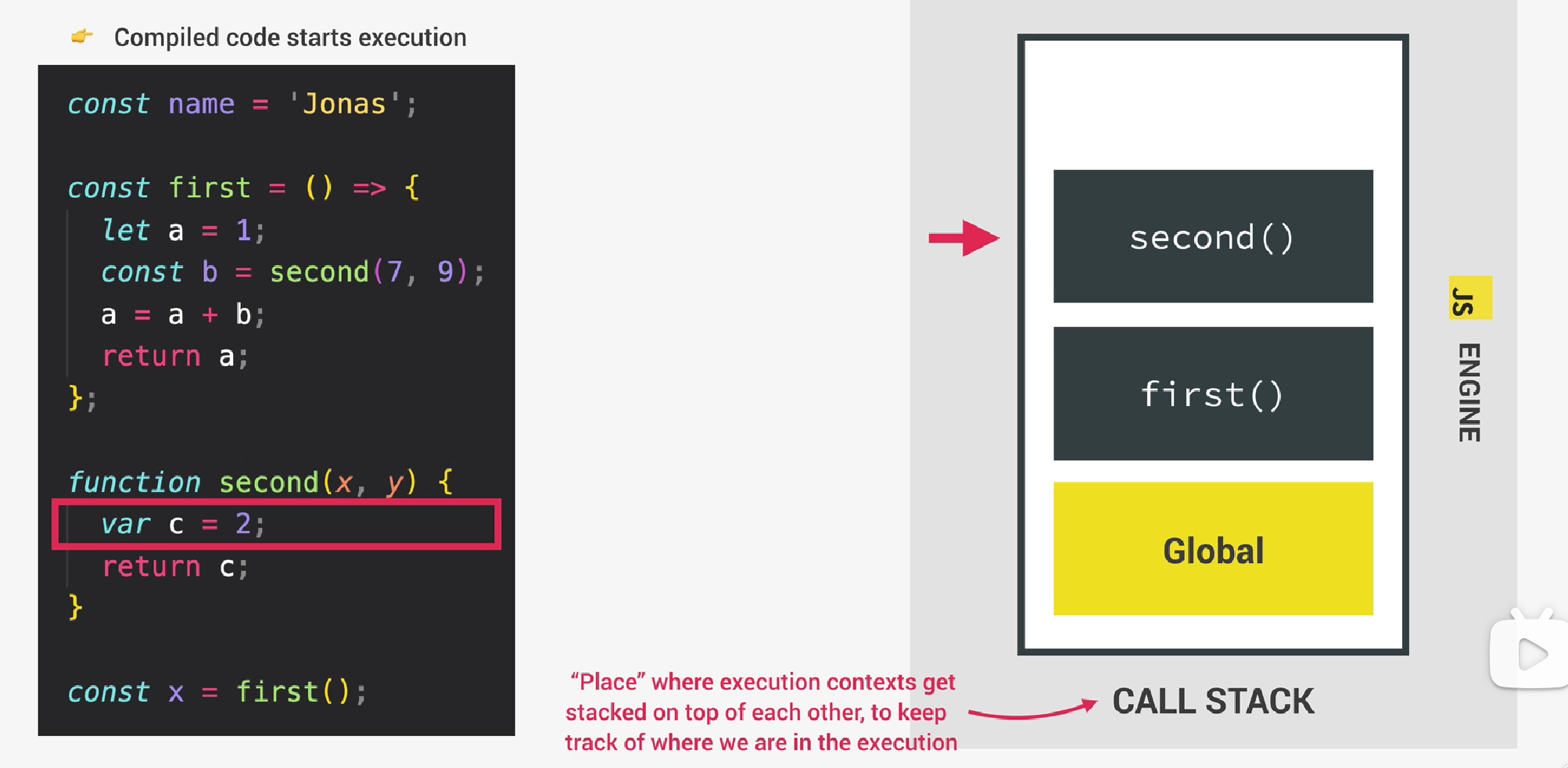
从上面可以知道,所有的execution context加在一起,组成了call stack。在上面的一段代码中,按照引擎执行js代码的顺序,call stack中执行上下文的排列自底向上应该是:先创建global execution context,然后创建first()函数的ec,最后创建second(x,y)函数的ec。
为了追踪我们在程序执行中所处的位置,位于call stack顶部的ec为当前正在运行的ec。由于函数second(x,y)的execution context在栈顶,当它返回c的值时,意味着该函数已经执行完毕,此时这个执行上下文将从栈顶弹出(pop),并从计算机内存中消失(实际上没完全消失),接着将执行新的栈顶执行上下文,即first()函数的执行上下文。
这就是call stack追踪execution context执行顺序的过程,它的美妙之处在于,当没有call stack时,引擎无法知道上一个被执行的函数是谁, 也就不知道该返回哪里。call stack对于js引擎来说就好比一张地图,它确保执行时永远不会迷路。
当执行结束时,call stack中仅存在global execution context,程序实际上会保持这种状态直到它最终真正完成。只有当我们关闭浏览器选项卡或窗口时,这时程序真正完成了,global execution context才会从call stack中弹出。
scoping & scope
我们前面提到过,一段js代码进入引擎,首先会经过解析(Parsing)和编译(Compilation)。我们首先来探讨解析部分。
在解析过程中,整个程序会被分解为不同的关键词,这些关键词被称为词法单元(token)。以let temp = 10这个声明为例,一旦被分词后,这个声明就会被转化为这些关键词:let, temp, =, 10。词法分析(lexing)和分词(tokenizing)这两个术语可以替换使用,两者间略微有些不同。词法分析是分词的过程,但是在这个过程中还会检查是否为独立的词法单元。词法分析是智能版的分词。
除此之外,在这个过程中,JavaScript引擎会查看整个程序,分配不同的变量到各自的作用域,然后检查是否有错误,一旦发现错误,执行就终止。
决定变量或者函数在执行的时候位于什么作用域的过程被称为lexical scoping。lexical这个词源于JS编译的分词/词法分析(lexing)阶段。这个过程发生在解析阶段。

变量的三种作用域
- global scope:在任何函数和代码块之外定义的变量;这些变量在程序的任何地方都可以访问。
- function scope:每个函数都会创建一个作用域,函数内部声明的变量只能在该函数内部访问;这也被成为局部作用域(local scope)。
- block scope:从ES6开始,代码块(花括号之间的一切,例如if语句或for循环的块)也会创建作用域,块内部声明的变量只能在块内部访问。注意:块作用域只适用于let或const声明的变量!(let and const are block scoped, while var is function scoped)

scope chain
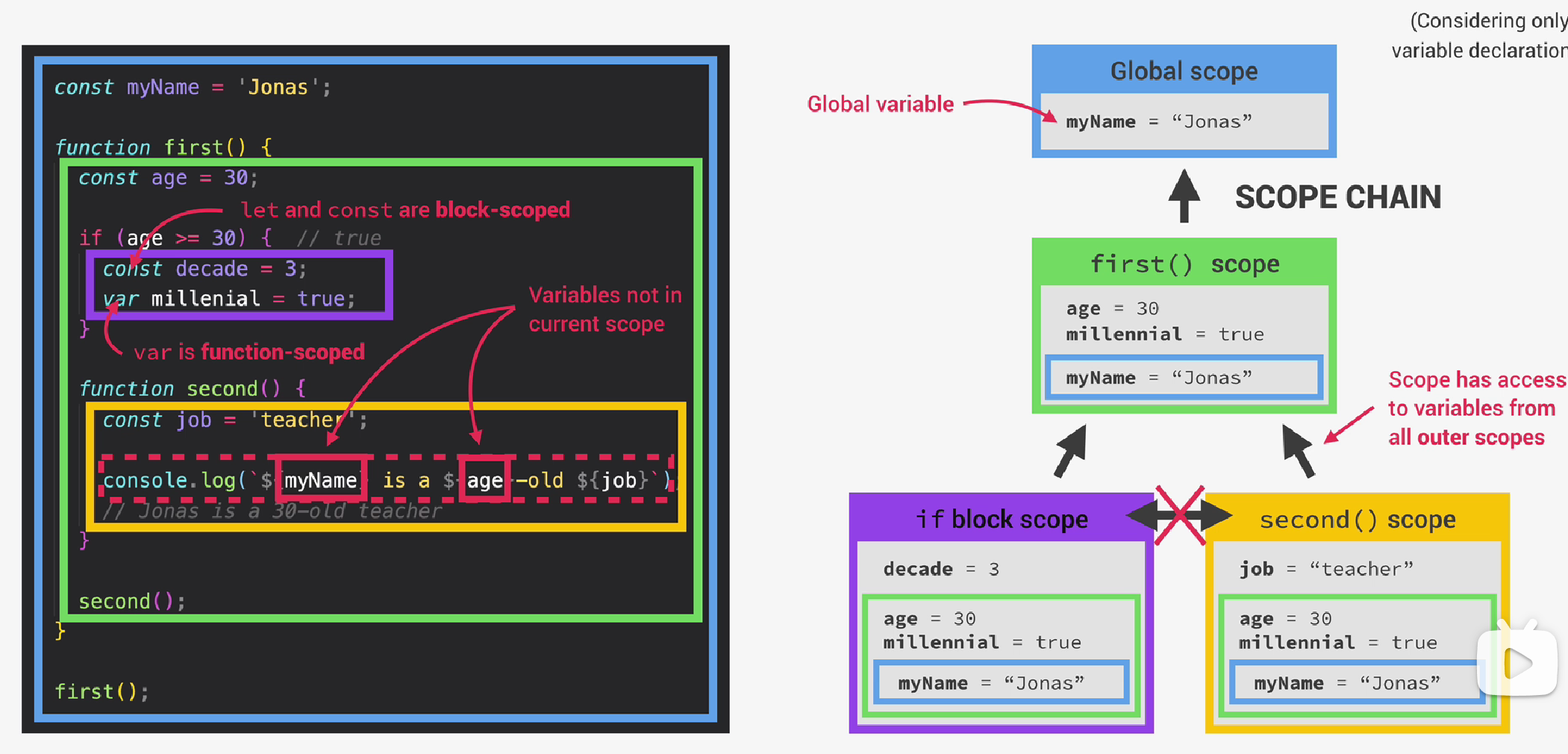
在下面的代码中,仅考虑变量声明,可知myName变量作用域为全局,first函数内部的变量age作用域为函数内部,且具有如下的嵌套关系。在second函数内部可以访问myName、age和job变量,这是因为每个作用域总是可以访问它的外部作用域(即父作用域)的所有变量。
这就是scope chain的工作原理。换句话说,如果一个作用域需要使用某个变量,但在当前作用域中找不到,那么它将会在作用域链中查找,看看它是否能在哪个父作用域中找到这个变量。如果找到,它将使用(而不是复制)这个变量,如果找不到,就会出现error。这个过程被称为变量查找(variable lookup)。
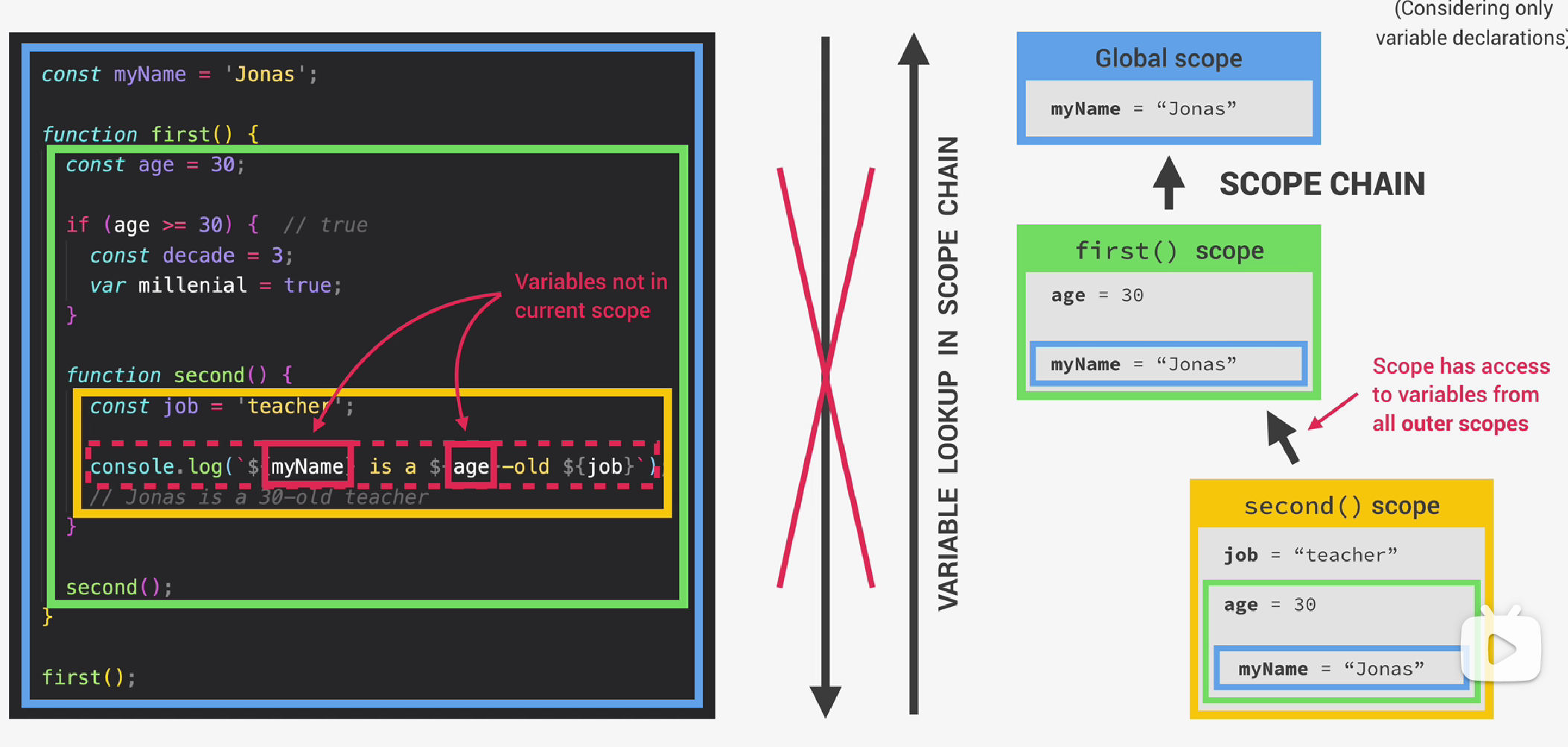
注意在if语句块中,decade变量使用const声明,所以它具有块作用域,而millenial变量使用var声明,因此具有函数作用域。
从嵌套关系可以看出,if块作用域和second函数作用域之间是兄弟关系,因此在second函数作用域中,无法访问decade变量,但是可以访问父作用域中的millennial变量。
scope chain VS. call stack

 浙公网安备 33010602011771号
浙公网安备 33010602011771号