spark集群安装并集成到hadoop集群
前言
最近在搞hadoop+spark+python,所以就搭建了一个本地的hadoop环境,基础环境搭建地址hadoop2.7.7 分布式集群安装与配置
本篇博客主要说明,如果搭建spark集群并集成到hadoop
安装流程
安装spark需要先安装scala 注意在安装过程中需要对应spark与scala版本, spark 也要跟hadoop对应版本,具体的可以在spark官网下载页面查看
下载sacla并安装
https://www.scala-lang.org/files/archive/scala-2.11.12.tgz tar zxf scala-2.11.12.tgz
移动并修改权限
chown hduser:hduser -R scala-2.11.11
mv /root/scala-2.11.11 /usr/local/scala
配置环境变量
vim .bashrc
#scala var
export SCALA_HOME=/usr/local/scala
export PATH=$PATH:$SCALA_HOME/bin
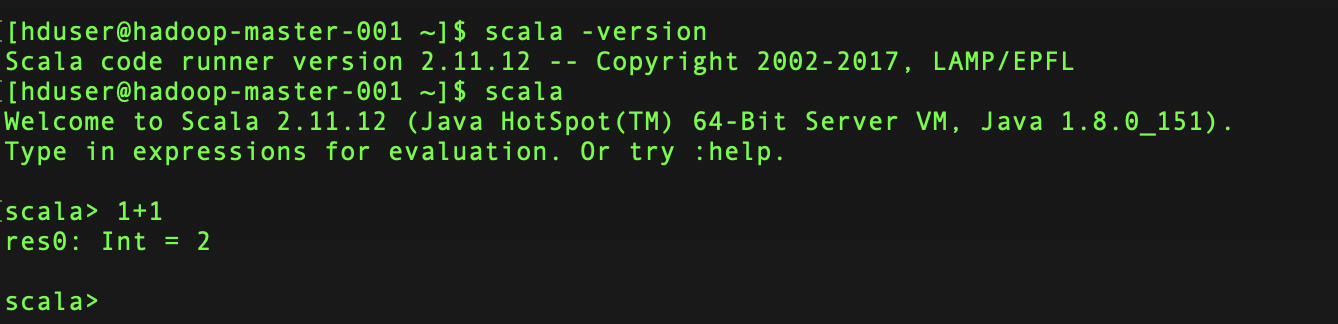
安装完成可以通过scala进如交互页面
注意事项
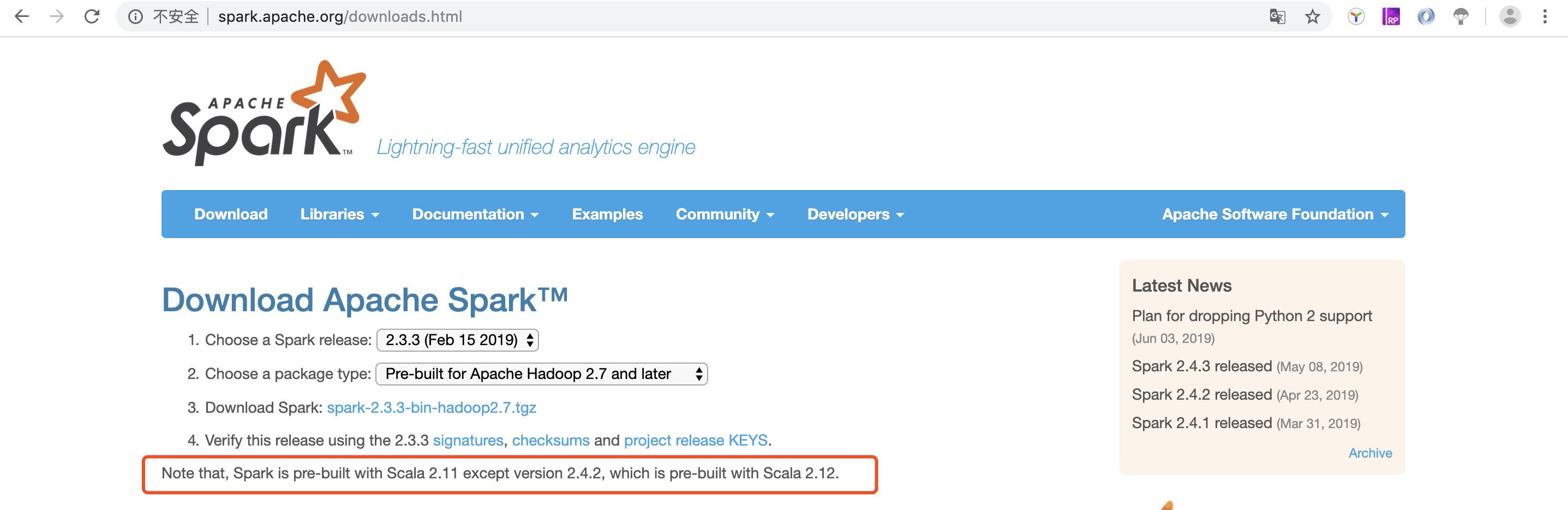
注意:Spark与hadoop版本必须互相匹配,因为Spark会读取Hadoop HDFS 并且必须能在Hadoop YARN执行程序,所以必须要按照我们目前安装的Hadoop版本来选择
笔者这里用的是hadoop2.7.7 所以我选择的是Pre-built for Apache Hadoop 2.7 and later
下载并安装spark
http://mirror.bit.edu.cn/apache/spark/spark-2.3.3/spark-2.3.3-bin-hadoop2.7.tgz
tar zxf spark-2.3.3-bin-hadoop2.7.tgz
移动并修改权限
chown hduser:hduser spark-2.3.3-bin-hadoop2.7
mv spark-2.3.3-bin-hadoop2.7 /usr/local/spark
配置环境变量
vim .bashrc
#spark var
export SPARK_HOME=/usr/local/spark
export PATH=$PATH:$SPARK_HOME/bin
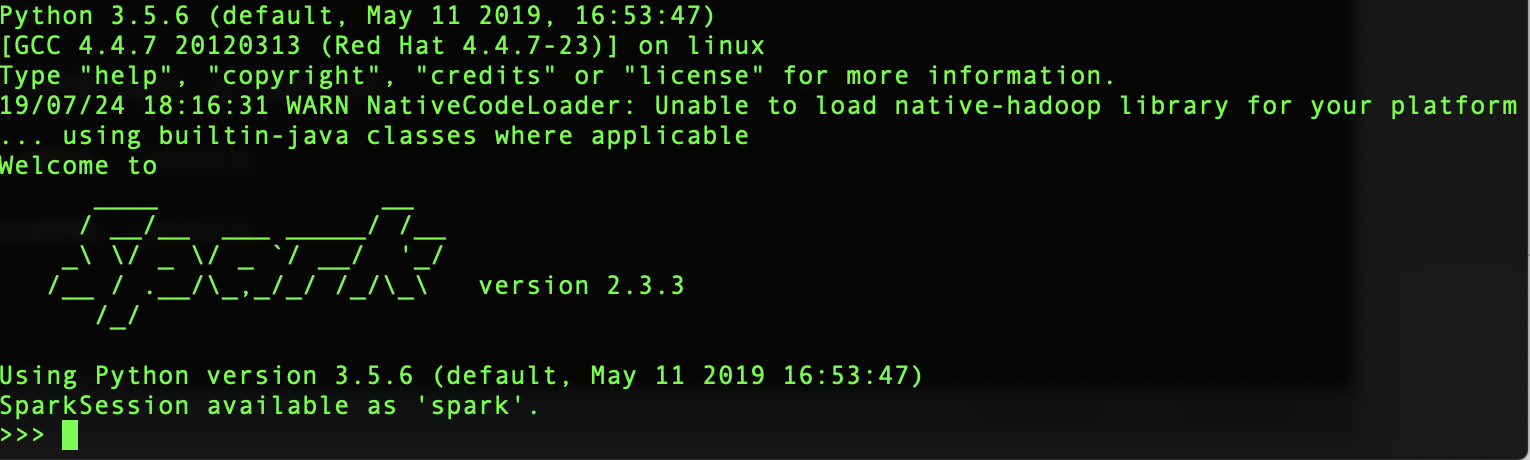
进入spark交互页面
默认是python2.7.x版本,对于当前来说版本比较老,可以修改pyspark来选择其他版本(前提是当前服务器已安装其他版本python)
修改master下的spark-env.sh #没有这个文件可以cp spark-env.sh.template spark-env.sh
在最后一行添加如下
export PYSPARK_PYTHON=/usr/bin/python3
修改master下的spark bin目录下pyspark
将文本中
PYSPARK_PYTHON=python
改为
PYSPARK_PYTHON=python3
#取消INFO信息打印
复制conf目录下的log4j模本文件到log4j.properties
将文本中
log4j.rootCategory=INFO, console
改为
log4j.rootCategory=WARN, console
测试与效果图
本地运行spark
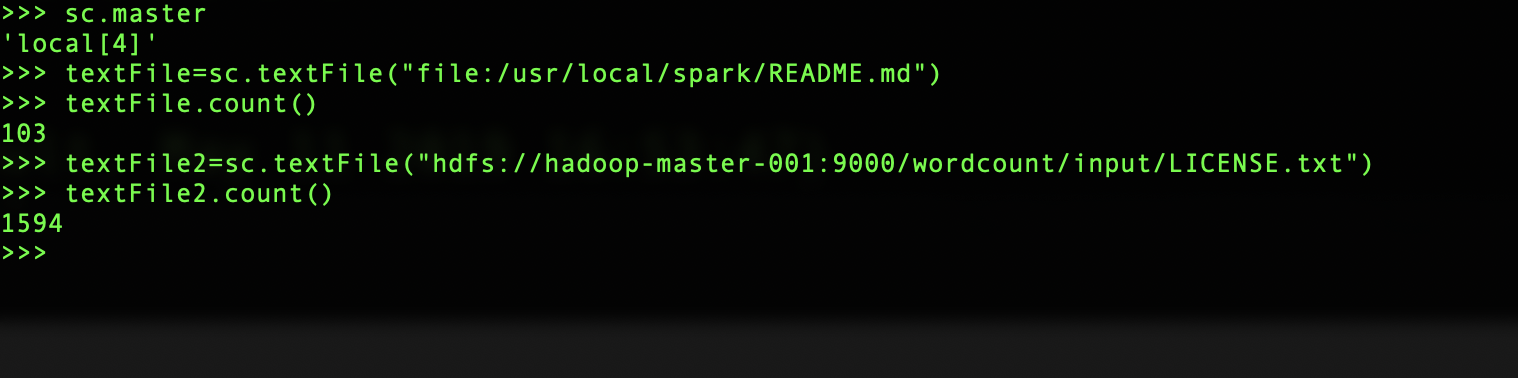
pyspark --master local[4]
spark 读取本地文件,所有节点都必须存在该文件
textFile=sc.textFile("file:/usr/local/spark/README.md")
spark 读取hdfs文件
textFile2=sc.textFile("hdfs://hadoop-master-001:9000/wordcount/input/LICENSE.txt")
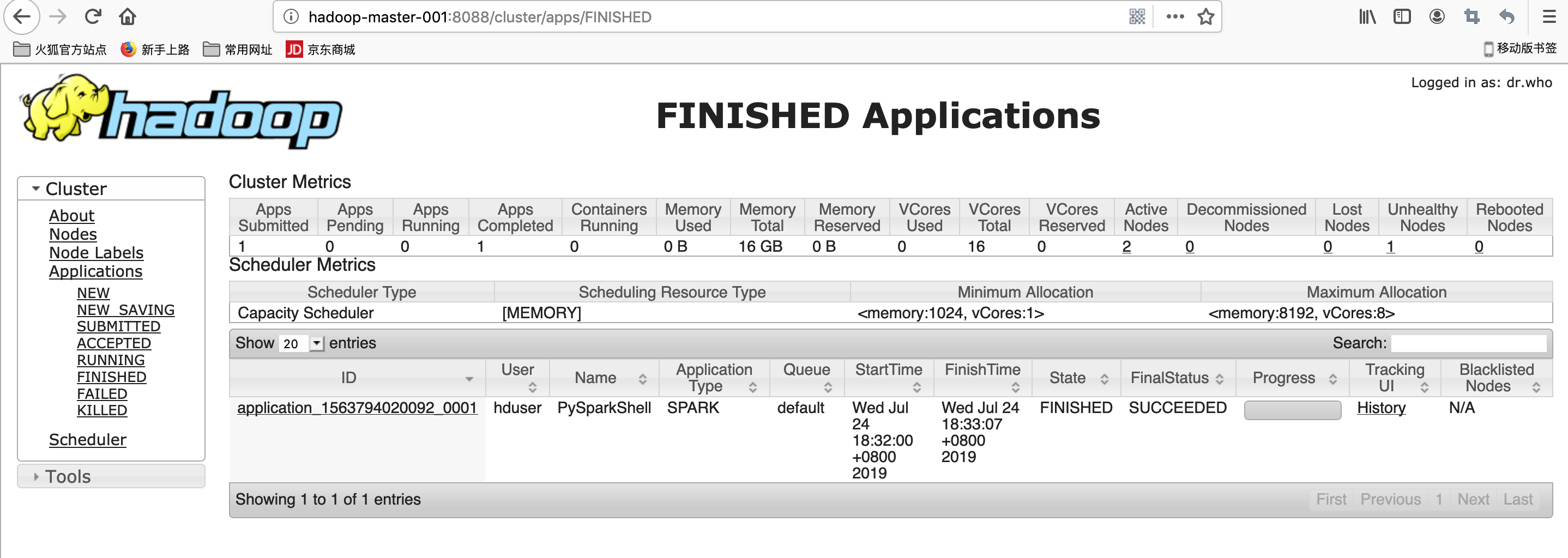
Hadoop YARN运行spark
HADOOP_CONF_DIR=/usr/local/hadoop/etc/hadoop pyspark --master yarn --deploy-mode client
textFile = sc.textFile("hdfs://hadoop-master-001:9000/wordcount/input/LICENSE.txt")
textFile.count()

spark Standalone Cluster运行
编辑spark-env.sh #spark_home/conf
export SPARK_MASTER=hadoop-master-001 //设置master的ip或域名
export SPARK_WORKER_CORES=1 //设置每个worker使用的CPU核心
export SPARK_WORKER_MEMORY=512m //设置每个worker使用的内存
export SPARK_WORKER_INSTANCES=4 //设置实例数
将master环境中的spark目录打包并分别远程传输到所有slave节点中.
设置spark Standalone Cluster 服务器(master环境)
vim /usr/local/spark/conf/slaves 添加ip或域名
hadoop-data-001
hadoop-data-002
hadoop-data-003
启动与关闭
/usr/local/spark/sbin/start-all.sh
/usr/local/spark/sbin/stop-all.sh
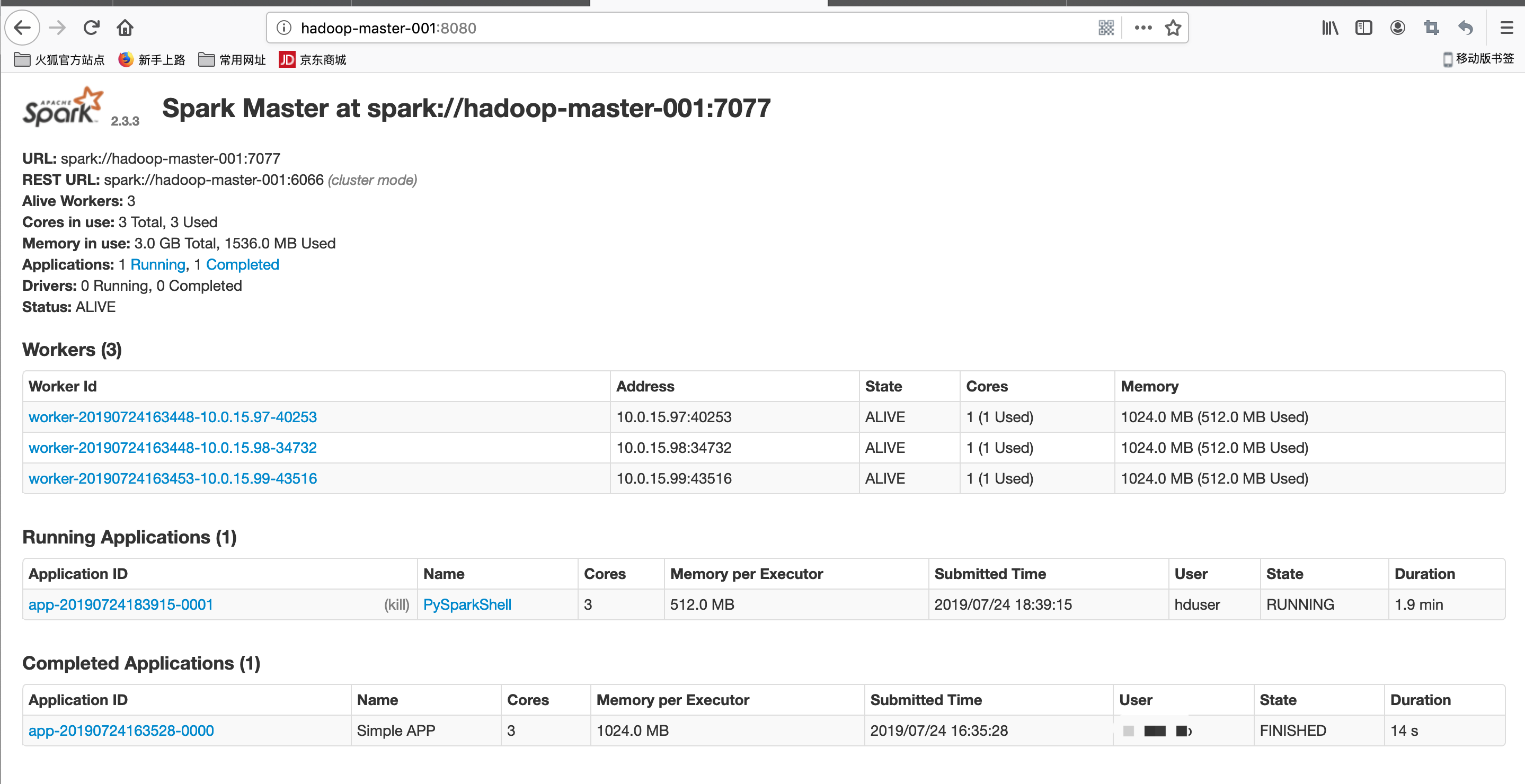
pyspark --master spark://hadoop-master-001:7077 --num-executors 1 --total-executor-cores 3 --executor-memory 512m
textFile = sc.textFile("file:/usr/local/spark/README.md")
textFile.count()
注意 当在cluster模式下,如yarn-client或spark standalone 读取本地文件时,因为程序是分不到不同的服务器,所以必须确认所有机器都有该文件,否则会发生错误.
建议 最好在cluster读取hdfs文件,这样不会出现文件
text2=sc.textFile("hdfs://hadoop-master-001:9000/wordcount/input/LICENSE.txt")
text2.count()

spark web ui
异常处理
hadoop yarn运行pyspark时异常信息:
ERROR SparkContext: Error initializing SparkContext. org.apache.spark.SparkException: Yarn application has already ended! It might have been killed or unable to launch application master
解决方式
查看http://hadoop-master-001:8088/cluster/app/ 最新任务点击history 查看信息
"Diagnostics: Container [pid=29708,containerID=container_1563435447194_0007_02_000001] is running beyond virtual memory limits. Current usage: 55.6 MB of 1 GB physical memory used; 2.2 GB of 2.1 GB virtual memory used. Killing container."
修改所有节点的yarn-site.xml,添加如下
<property>
<name>yarn.nodemanager.pmem-check-enabled</name>
<value>false</value>
</property>
<property>
<name>yarn.nodemanager.vmem-check-enabled</name>
<value>false</value>
</property>
主节点执行stop-yarn.sh, start-yarn.sh 重启所有节点yarn

 浙公网安备 33010602011771号
浙公网安备 33010602011771号