机器学习实战笔记-6-支持向量机
支持向量机
- 优缺点:优点:泛化错误率低,计算开销不大,结果易解释;缺点:对参数调节和核函数的选择敏感,原始分类器不加修改仅适用于处理二类问题。
适用于:数值型和标称型数据。 - 最流行的SVM是序列最小优化(SMO)算法。支持向量是离分隔超平面最近的点。支持向量机本质就是求解数据集的最佳分隔直线(支持向量离分割超平面尽可能远)。
原理
分隔超平面的形式:\(w^{T}x + b =0\),支持向量的点A到分隔面的距离为\(d = \frac{|w^{T}A + b |}{| | w | |}\),为了方便最大化此d,固定支持向量处的\(|{w}^{ {T} }{A} + b |{= 1}\),得到\(d = \frac{1}{| | {\omega} | |}\),故\(\max(d ) = \frac{1}{\min( | | {\omega} || )}\),问题变成:
第一步:将有约束的原始目标函数转换为无约束的新构造的拉格朗日目标函数(为了建立一个在可行解区域内与原目标函数相同,在可行解区域外函数值趋近于无穷大的新函数),令
其中\(\alpha_{i} \geq 0\)叫拉格朗日乘子。首先令\(\alpha_{i}\)为正无穷,
- 当\(y_{i}( {\omega}^{T}x_{i} + b ) \geq1\)(可行解区域内),显然在支持向量处\(\mathcal{L}\)取到最大值,\(\theta(\omega ){=}\frac{1}{2}| | \omega | |^{2}\);
- 当\(y_{i}( {\omega}^{T}x_{i} + b ) <1\)(可行解区域外),可得到\(\theta( \omega){=}{+}{\infty}\)。
现在求解\({\text{min} }_{ {\omega,b} }{\theta}({\omega} ) = \text{min}_{ {\omega,b} }{\text{max} }_{ {\alpha}_{ {i} }{\geq 0} }\mathcal{L}( {\omega},b,\alpha){=}{p}^{ {*} }\)。
也就是求解\({\text{max} }_{\alpha_{ {i} }{\geq 0} }{\text{mi} }{n}_{ {\omega,b} }\mathcal{L}({\omega},b,\alpha ){=}{d}^{ {*} }{\text{} }{,}{d}^{ {*} }{\leq}{p}^{ {*} }\)。
\(d^{*} = p^{*}\)的条件:求取最小值的目标函数为凸函数(已满足),满足KKT条件。
KKT条件:拉格朗日函数处理之后的新目标函数L(w,b,α)对x求导为零;\(\alpha*g_{k}({x})= 0\),其中\(g_{k}( x ) = 1 - y_{i}({\omega}^{T}{x}_{i} + b ) = 1 - y_{i}y_{i}^{'}\)。
首先固定\(\alpha\),要让L(w,b,α)关于w和b最小化,分别对w和b偏导数,令其为0,即\(\frac{\partial\mathcal{L} }{\partial\omega}= 0,\frac{\partial\mathcal{L} }{\partial b} = 0\),得到\({\omega =}\sum_{i= 1}^{m}{\alpha_{i}y_{i}{x}_{i} }\ ,\ \sum_{i = 1}^{m}{\alpha_{i}y_{i} =0}\)。代回L(w,b,α),得到
,则再求外层的最大值\(\operatorname{}( \sum_{i = 1}^{m}\alpha_{i} - \frac{1}{2}\sum_{i,j =1}^{m}{\alpha_{i}\alpha_{j}y_{i}y_{j}{x}_{i}^{T}{x}_{j} } )\) s.t. \(\ \alpha_{i} \geq 0,\sum_{i = 1}^{m}{\alpha_{i}y_{i} } = 0\)。
事实上,这里的假设:数据是100%线性可分的。但应允许有些数据点在错误的超平面一侧。
| - | 考察支持向量$$y_{i}y'{i} = y({\omega}^{T}x_{i} + b)=1$$ | 考察错误分类的点$${y_{i}y_{i}^{'} = y}{i}( {\omega}^{T}x + b ) < 1$$ |
|---|---|---|
| 目标函数 | $$min(\frac{1}{2}|\omega|^{2})$$ | $$\min( \frac{1}{2}| \omega |^{2} + C\sum_{i = 1}^{m}\xi_{i} )$$,$$\xi_{i} = \max( 0,1 - y_{i}y_{i}^{'} )$$ |
| 约束条件 | $$g({x}{i}) = 1 - yy'_{i}\leq 0$$ | $$g({x}{i}) = 1 - yy'{i}- \xi \leq 0,\xi_{i} \geq 0$$ |
| 拉格朗日函数 | $$L = \frac{1}{2}| {\omega} |^{2} + {\alpha}g( {x}{i} ) = \frac{1}{2}|\omega|{2}+\sum_{i=1}\alpha(1-y_{i}y'_{i})$$ | $$L = \frac{1}{2}|{\omega}|^{2} + C\sum_{i=1}^{m}\xi_{i}+{\alpha}g({x}{i}) + {\mu}( {-}{\xi})\frac{1}{2}|\omega|{2}+C\sum_{i=1}\xi_{i}+\sum_{i=1}{m}\alpha_{i}(1-\xi_{i}-y_{i}y'_{i})-\sum_{i=1}\mu_{i}\xi_{i}$$ |
| KKT条件 | $$\left{ \begin{matrix}g(x_{i})\leq 0\\alpha_{i} \geq 0 \\alpha_{i}\cdot g(x_{i})=0\end{matrix} \right.$$ | $$\left{ \begin{matrix}g(x_{i}) \leq 0,\xi_{i} \geq 0 \ \alpha_{i} \geq 0, \mu_{i} \geq 0 \\alpha_{i}\cdot g(x_{i})=0, \mu_{i}\xi_{i}=0 \end{matrix}\right.$$ |
| 求$$\frac{\partial L}{\partial}$$ | $$\left{ \begin{matrix} \frac{\partial L}{\partial{\omega} } = 0 \rightarrow {\omega} = \sum_{i = 1}^{m}{\alpha_{i}y_{i}{x}{i} } \ \frac{\partial L}{\partial b} = 0 \rightarrow \sum^{m}{\alpha_{i}y_{i} } = 0 \end{matrix}\right.$$ | $$\left{ \begin{matrix} \frac{\partial L}{\partial{\omega} } = 0 \rightarrow {\omega} = \sum_{i = 1}^{m}{\alpha_{i}y_{i}{x}{i} }\ \frac{\partial L}{\partial b} = 0 \rightarrow \sum^{m}{\alpha_{i}y_{i} } = 0 \ \frac{\partial L}{\partial\xi_{i} } = 0 \rightarrow C = \alpha_{i} + \mu_{i} \end{matrix} \right.$$ |
| 对偶问题 | $$\max_{\alpha}\left{ \sum_{i = 1}^{m}{\alpha_{i} - \frac{1}{2}\sum_{i,j = 1}{m}{\alpha_{i}\alpha_{j}y_{i}y_{j}{x}_{i} }{x}{j} }} \right}$$ s.t. $$\sum^{m} \alpha_{i} y_{i} =0,\alpha_{i}≥0$$ | $$\max_{\alpha}\left{ \sum_{i = 1}^{m}{\alpha_{i} - \frac{1}{2}\sum_{i,j = 1}{m}{\alpha_{i}\alpha_{j}y_{i}y_{j}{x}_{i} }{x}{j} }} \right}$$ s.t. $$\sum^{m} \alpha_{i} y_{i} =0,\alpha_{i}≥0$$ |
| $$\alpha_{i}$$的意义 | $$\alpha_{i} = 0 \Rightarrow y_{i}y'{i} \geq 1$$ 边界内部; $$\alpha > 0 \Rightarrow y_{i}y'_{i}= 1$$ 支持向量,边界上; | $$\alpha_{i} = 0 \Rightarrow \mu_{i} > 0 \Rightarrow \xi_{i} = 0 \Rightarrow y_{i}y'{i}\geq 1$$边界内部; $$0 < \alpha < C \Rightarrow \mu_{i} > 0 \Rightarrow \xi_{i} = 0 \Rightarrow y_{i}y'{i}= 1$$ 支持向量; $$\alpha = C \Rightarrow \mu_{i} = 0 \Rightarrow \xi_{i} \geq 0 \Rightarrow y_{i}y'{i} = 1 - \xi$$ 过界点。 |
即仅把约束条件变为:\(C \geq \alpha_{i} \geq 0,\sum_{i = 1}^{m}{\alpha_{i}y_{i} }=0\),这里C用于控制“最大化间隔”和“保证大部分数据的函数间隔小于1.0”这两个目标的权重。
SMO算法:
预测的结果为\(y'{=}{\omega}^{ {T} }{x} +b\),由于\({\omega =}\sum_{i =1}^{m}{\alpha_{i}y_{i}{x}_{i} }\),故\(y'{=}\sum_{i =1}^{m}{\alpha_{i}y_{i}{x}_{i}^{ {T} }{x} } + b\)


可以看到要满足KKT条件\(\alpha*g_{k}({x}) = 0\):
- \(\alpha_{i} = 0\rightarrow y_{i}y_{i}^{'} \geq 1\) 则\(\alpha_{i}\)是正常分类,在边界内部;
- \(0 < \alpha_{i}<C\rightarrow y_{i}y_{i}^{'} = 1\) 则\(\alpha_{i}\)是支持向量,在边界上;
- \(\alpha_{i} = C\rightarrow y_{i}y_{i}^{'} \leq 1\) 则\(\alpha_{i}\)是在两条边界之间。
必须同时更新一对\(\alpha\),\(\alpha_{1}^{\text{new} }y_{1} +\alpha_{2}^{\text{new} }y_{2} = \alpha_{1}^{\text{old} }y_{1} +\alpha_{2}^{\text{old} }y_{2} = \zeta\)。先确定一个的范围,如\(L \leq \alpha_{2}^{\text{new} } \leq H\)。
当\(y_{1},y_{2}\)不相等(符号相反),则\(\alpha_{1}^{\text{old} } -\alpha_{2}^{\text{old} } = \zeta\),\(\left\{ \begin{matrix} {0 \leq \alpha}_{2}\leq C \\ 0 \leq \alpha_{2} + \zeta \leq C \\ \end{matrix} \right.\)继而\(L =\max( 0, - \zeta ),H = \min{(C,C - \zeta)}\)。
当\(y_{1},y_{2}\)相等(符号相同),则\(\alpha_{1}^{\text{old} } +\alpha_{2}^{\text{old} } = \zeta\),\(\left\{ \begin{matrix} {0 \leq \alpha}_{2}\leq C \\ 0 \leq {\zeta - \alpha}_{2} \leq C \\ \end{matrix} \right.\)继而\(L =\max( 0,\zeta - C ),H = \min{(C,\zeta)}\)。
故\(\left\{ \begin{matrix} L = \max{(0,\alpha_{2}^{\text{old} } -\alpha_{1}^{\text{old} })},H = \min{(C,C + \alpha_{2}^{\text{old} } - \alpha_{1}^{\text{old} })}\text{\ if\ }y_{1} \neq y_{2} \\ L = \max{(0,\alpha_{2}^{\text{old} } + \alpha_{1}^{\text{old} } - C)},H = \min{(C,\alpha_{2}^{\text{old} } + \alpha_{1}^{\text{old} })}\text{\ if\ }y_{1} = y_{2} \\ \end{matrix} \right.\),因为
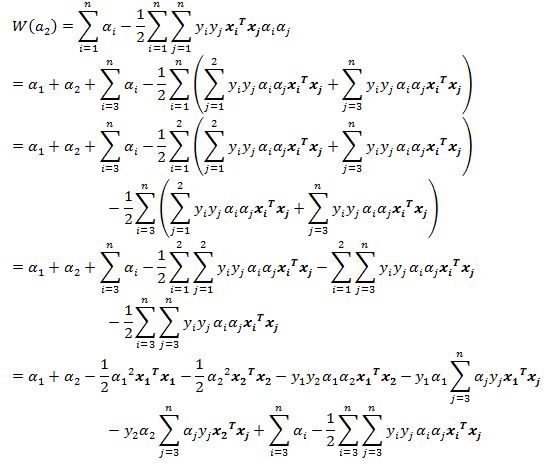
其中
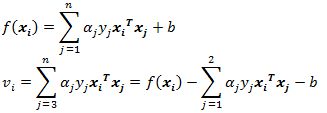
得到
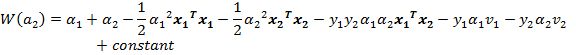
\(\alpha_{1}y_{1} + \alpha_{2}y_{2} = B\),两边同时乘以\(y_{1}\)(注意\(y_{1}y_{1} =1\)),得到\(\alpha_{1} = \gamma - s\alpha_{2}\),其中\(\gamma = By_{1},\ s =y_{1}y_{2}\),得到
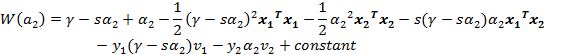
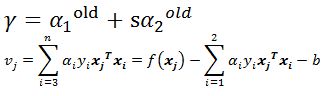

直接得到

令:
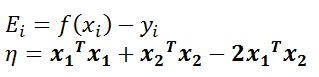
可以得到
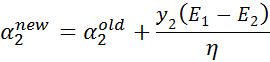

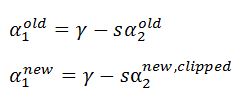
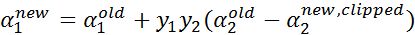
当\({0 < \alpha}_{1}^{\text{new} } < C\),是支持向量上的点,满足\(y_{1}({\omega}^{ {T} }{x}_{ {1} } + b ) = 1\),
两边同乘\(y_{1}\),得\(\sum_{i = 1}^{m}{\alpha_{i}y_{i}x_{i}x_{1} + b =y_{1} }\),得到
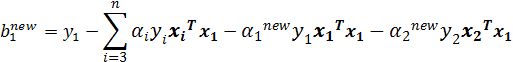
其中

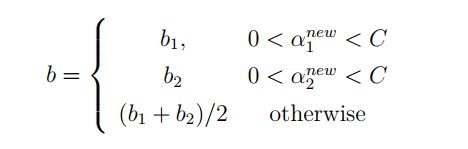
得到
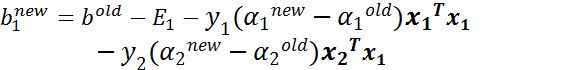

当\(b_{1}\)和\(b_{2}\)都有效,它们是相等的。即\(b^{\text{new} } =b_{1}^{\text{new} } = b_{2}^{\text{new} }\)。
SMO算法步骤:
步骤1:计算误差:

步骤2:计算上下界L和H:
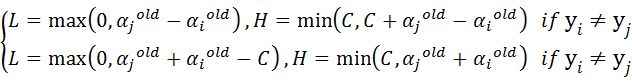
步骤3:计算η:

步骤4:更新αj:
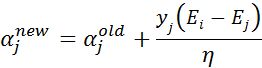
步骤5:根据取值范围修剪αj:
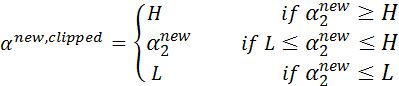
步骤6:更新αi:
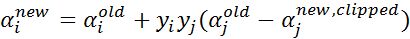
步骤7:更新b1和b2:
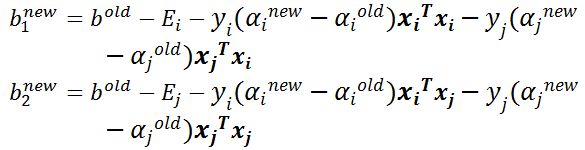
步骤8:根据b1和b2更新b:
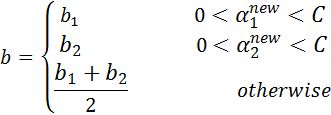
启发选择方式
下面这两个公式想必已经不再陌生:
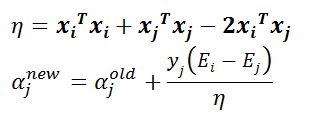
在实现SMO算法的时候,先计算\(\eta\),再更新\(\alpha\)。为了加快第二个\(\alpha\)乘子的迭代速度,需要让直线的斜率增大,对于\(\alpha\)的更新公式,其中\(\eta\)值没有什么文章可做,于是只能令:
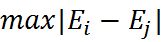
因此,我们可以明确自己的优化方法了:
最外层循环,首先在样本中选择违反KKT条件的一个乘子作为最外层循环,然后用启发式选择选择另外一个乘子并进行这两个乘子的优化;
在非边界乘子中寻找使得\(| E_{i} - E_{j} |\)最大的样本;
如果没有找到,则从整个样本中随机选择一个样本。
非线性SVM
- 核技巧
我们已经了解到,SVM如何处理线性可分的情况,而对于非线性的情况,SVM的处理方式就是选择一个核函数。简而言之:在线性不可分的情况下,SVM通过某种事先选择的非线性映射(核函数)将输入变量映到一个高维特征空间,将其变成在高维空间线性可分,在这个高维空间中构造最优分类超平面。
线性可分的情况下,超平面方程为:
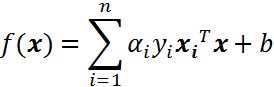
用内积来表示:
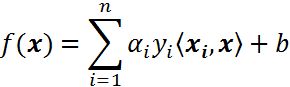
对于线性不可分,我们使用一个非线性映射,将数据映射到特征空间,在特征空间中使用线性学习器,分类函数变形如下:
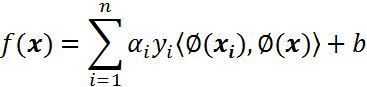
其中ϕ从输入空间(X)到某个特征空间(F)的映射,这意味着建立非线性学习器分为两步:
-
首先使用一个非线性映射将数据变换到一个特征空间F;
-
然后在特征空间使用线性学习器分类。
如果有一种方法可以在特征空间中直接计算内积$< \phi( x_{i} ),\phi(x) >
$,就像在原始输入点的函数中一样,就有可能将两个步骤融合到一起建立一个分线性的学习器,这样直接计算的方法称为核函数方法。
这里直接给出一个定义:核是一个函数 \(k\) ,对所有 \(x,z \in X\) ,满足 \(k(
x,z ) = < \phi( x_{i} ),\phi(x) >\),这里 \(\phi( )\)
是从原始输入空间X到内积空间F的映射。
简而言之:如果不是用核技术,就会先计算线性映 \(\phi(x_{1})\) 和 \(\phi(x_{2})\)
,然后计算这它们的内积,使用了核技术之后,先把 \(\phi(x_{1})\) 和
\(\phi(x_{2})\) 的一般表达式 \(< \phi(x_{1}),\phi(x_{2}) > = k( <
\phi(x_{1}),\phi(x_{2}) > )\) 计算出来,这里的 \(< , >\) 表示内积, \(k( , )\)
就是对应的核函数,这个表达式往往非常简单,所以计算非常方便。
这种将内积替换成核函数的方式被称为核技巧(kernel trick)。
2、非线性数据处理
已经知道了核技巧是什么,但是为什么要这样做呢?我们先举一个简单的例子,进行说明。假设二维平面x-y上存在若干点,其中点集A服从
\(\{ x,y|x^{2} + y^{2} = 1\}\) ,点集B服从 \(\{ x,y|x^{2} + y^{2} = 9\}\)
,那么这些点在二维平面上的分布是这样的:

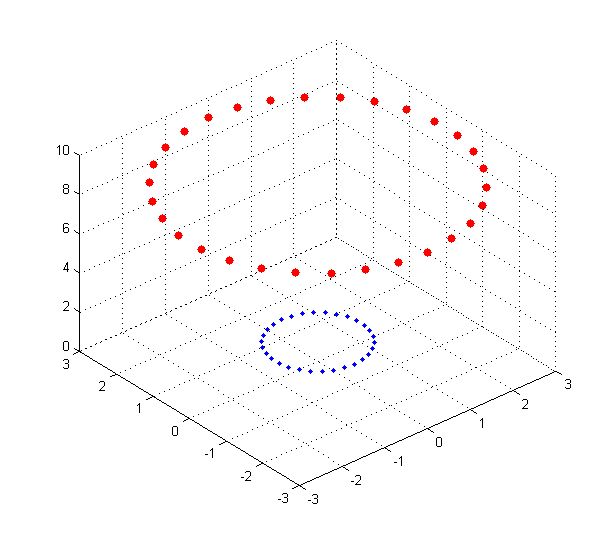

蓝色的是点集A,红色的是点集B,他们在xy平面上并不能线性可分,即用一条直线分割(
虽然肉眼是可以识别的) 。采用映射\(\ (x,y)\)->\((x,y,x^{2} + y^{2})\)
后,在三维空间的点的分布如上图中图。
可见红色和蓝色的点被映射到了不同的平面,在更高维空间中是线性可分的(用一个平面去分割)。
上述例子中的样本点的分布遵循圆的分布。继续推广到椭圆的一般样本形式:
上图右图的两类数据分布为两个椭圆的形状,这样的数据本身就是不可分的。不难发现,这两个半径不同的椭圆是加上了少量的噪音生成得到的。所以,一个理想的分界应该也是一个椭圆,而不是一个直线。如果用X1和X2来表示这个二维平面的两个坐标的话,我们知道这个分界椭圆可以写为:

这个方程就是高中学过的椭圆一般方程。注意上面的形式,如果我们构造另外一个五维的空间,其中五个坐标的值分别为:
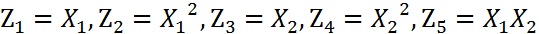
那么,显然我们可以将这个分界的椭圆方程写成如下形式:
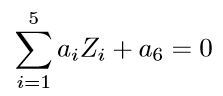
这个关于新的坐标 \(Z_{1},Z_{2},Z_{3},Z_{4},Z_{5}\)
的方程,就是一个超平面方程,它的维度是5。也就是说,如果我们做一个映射 \(\phi\ :\text{二维} \rightarrow \text{五维}\),将 \(X_{1},X_{2}\) 按照上面的规则映射为 \(Z_{1},Z_{2}, \cdots,Z_{5}\)
,那么在新的空间中原来的数据将变成线性可分的,从而使用之前我们推导的线性分类算法就可以进行处理了。
我们举个简单的计算例子,现在假设已知的映射函数为:
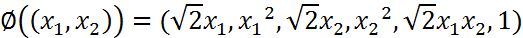
这个是一个从2维映射到5维的例子。如果没有使用核函数,根据上一小节的介绍,我们需要先结算映射后的结果,然后再进行内积运算。那么对于两个向量a1=(x1,x2)和a2=(y1,y2)有:
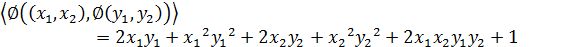
另外,如果我们不进行映射计算,直接运算下面的公式:
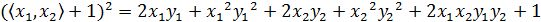
你会发现,这两个公式的计算结果是相同的。区别在于什么呢?
-
一个是根据映射函数,映射到高维空间中,然后再根据内积的公式进行计算,计算量大;
-
另一个则直接在原来的低维空间中进行计算,而不需要显式地写出映射后的结果,计算量小。
其实,在这个例子中,核函数就是:

我们通过 \(k(x_{1},x_{2})\)
的低维运算得到了先映射再内积的高维运算的结果,这就是核函数的神奇之处,它有效减少了我们的计算量。在这个例子中,我们对一个2维空间做映射,选择的新的空间是原始空间的所以一阶和二阶的组合,得到了5维的新空间;如果原始空间是3维的,那么我们会得到19维的新空间,这个数目是呈爆炸性增长的。如果我们使用
\(\phi( )\)
做映射计算,难度非常大,而且如果遇到无穷维的情况,就根本无从计算了。所以使用核函数进行计算是非常有必要的。
3、核技巧的实现
通过核技巧的转变,我们的分类函数变为:
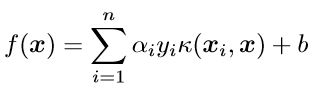
我们的对偶问题变成了:
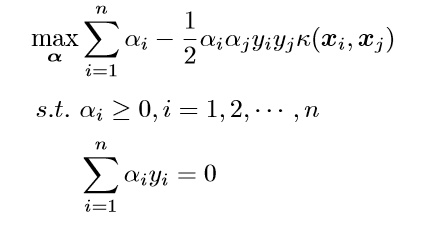
这样,我们就避开了高纬度空间中的计算。当然,我们刚刚的例子是非常简单的,我们可以手动构造出来对应映射的核函数出来,如果对于任意一个映射,要构造出对应的核函数就很困难了。因此,通常,人们会从一些常用的核函数中进行选择,根据问题和数据的不同,选择不同的参数,得到不同的核函数。接下来,要介绍的就是一个非常流行的核函数,那就是径向基核函数。
径向基核函数是SVM中常用的一个核函数。径向基核函数采用向量作为自变量的函数,能够基于向量举例运算输出一个标量。径向基核函数的高斯版本的公式如下:

其中,σ是用户自定义的用于确定到达率(reach)或者说函数值跌落到0的速度参数。上述高斯核函数将数据从原始空间映射到无穷维空间。关于无穷维空间,我们不必太担心。高斯核函数只是一个常用的核函数,使用者并不需要确切地理解数据到底是如何表现的,而且使用高斯核函数还会得到一个理想的结果。如果σ选得很大的话,高次特征上的权重实际上衰减得非常快,所以实际上(数值上近似一下)相当于一个低维的子空间;反过来,如果σ选得很小,则可以将任意的数据映射为线性可分——当然,这并不一定是好事,因为随之而来的可能是非常严重的过拟合问题。不过,总的来说,通过调控参数σ,高斯核实际上具有相当高的灵活性,也是使用最广泛的核函数之一。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号