
9/17
今日考题
1.列举requests方法括号内可以携带的参数及作用
params # 放get请求后面携带的额外参数
headers # 请求头数据 比如浏览器K:V键值对
stream # stream = True 可以一行行读取节约内存
data # 放请求体数据
2.用自己的话详述cookie与session
cookie: 浏览器记下访问网页时候的K:V键值对数据下次访问的时候直接用
eg: 记录用户名密码下次登陆就不用再输入
session: 浏览器在收到用户名密码后返回一段随机字符 这样就防止密码泄露
同时由于字符串要通过K:V键值对记录所以还是要通过cookie工作
3.详细描述出针对华华手机登录的整体逻辑
1.先通过浏览器反复观察研究登录界面
2.找到向哪个网站提交登录数据
3.注册后找到登录中的请求体数据格式
4.用注册的用户名密码通过网站的请求体格式发送登录请求
5.获取返回的数据即cookie,做成字典格式保存
6.尝试直接通过提交cookie直接登录
4.目前你所知道的防爬措施及相应解决策略
1.请求是否是浏览器发出
在请求头中加入User-Agent参数
2.限定ip访问次数
通过白标各种ip做成IP代理池发送请求
3.限定cookie访问次数
和上面一样通过多注册获取cookie做成cookie代理池
复习巩固
- cookie与session
1.cookie与session由来
由于HTTP协议中的无状态的特点无法保存用户端信息的特点
2.cookie与session主要特征
cookie指代的是服务端让客服端浏览器保存的键值对数据
session指代的是服务端保存的键值对数据
# session需要依赖于cookie工作
- 代码模拟登陆
'''浏览器功能介绍
Elements 查看页面被浏览器渲染后的html代码
console 相当于一个JS编程环境
sources 以目录形式存放各种资源
Netwok 监控网络请求
Fetch/XHR 偷偷发送的请求
Application 数据存储相关
cookies 就在这里
'''
1.先用浏览器发送正常登录请求
2.检查内部网络请求状态 获取登录的url地址
3.查看post请求体携带的数据特征
4.用requests模块发送登录请求
5.获取登录成功后服务器返回的cookie数据
6.携带cookie发送get请求
- requests参数总结
1.url # 请求地址
2.params # get请求携带的参数
3.headers # 请求头数据
4.data # post请求携带的数据
- requests其他知识补充
1.json格式 requests.get().json就能直接变成python中对应的数据
2.大文件
requests.get(stream=True) # 省内存
- 防爬措施及解决策略
1.User-Agent
requests.get(url,headers={})
2.IP代理池
requests.get(url,proxies={})
3.Cookie代理池
requests.get(url,cookies={})
内容概要
- 数据的加载方式
- 爬取天气数据
- 爬百度翻译
- 爬药品许可证
- 爬蔬菜价格
- 爬豆瓣电源分类
详细讲解
数据的加载方式
1.常见的加载方式
向服务器发请求 页面数据直接全部返回并加载
'''
如何验证数据是直接加载还是其他方式
浏览器空白处鼠标右键 点击查看网页源码 源码界面搜索相应数据
如果能收到就表示数据是直接加载的(你可以直接发送相应请求)
'''
2.内部js代码请求
先加载一个页面框架 然后再朝各项数据网址发送请求获取数据
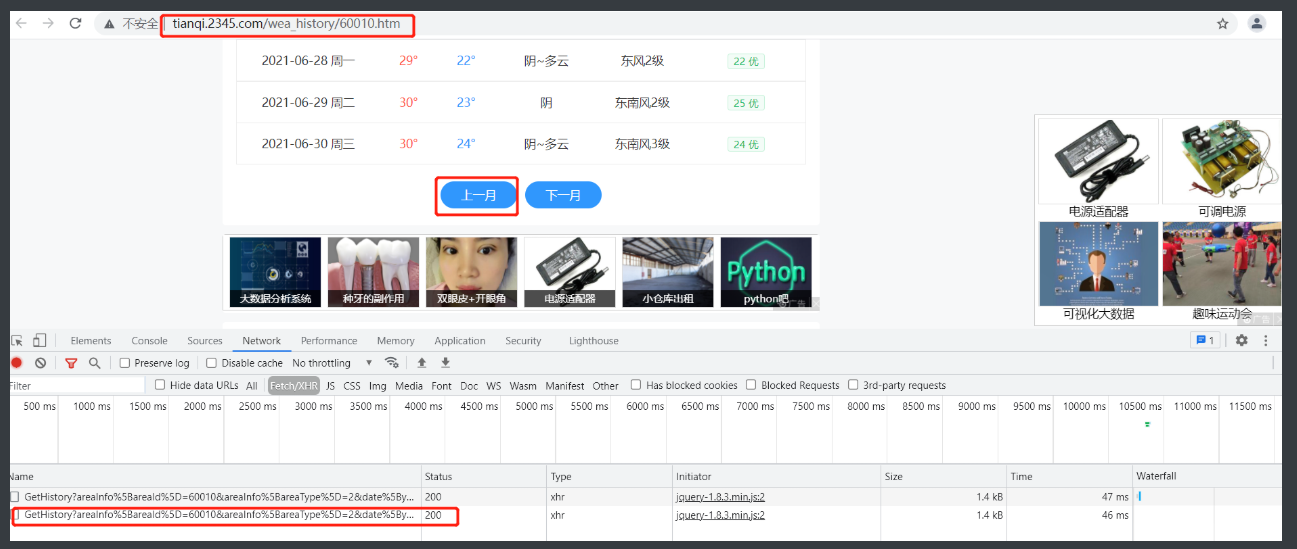
爬取天气数据
1.拿到这个页面先看上面的数据是否是直接写在网页上的
通过检查网页源码并搜索网页上内容
2.搜索是能有的 但是进一步观察发现点翻页后网址没有变化
3.思考翻页后数据是否还是直接写在这个网页上
那翻页就是通过网页内部实现的动态加载
4.这时候就需要network配合fetch去找到实现这个动态加载的部分
5.找到之后看里面url找到是去哪个网站请求数据的
6.找到可以复制出来验证一下想法
http://tianqi.2345.com/Pc/GetHistory?areaInfo%5BareaId%5D=60010&areaInfo%5BareaType%5D=2&date%5Byear%5D=2021&date%5Bmonth%5D=9
7.看到雀食是一堆json格式数据再放到bejson里面看看
8.验证说明这个就是这个月网页的数据
9.通过代码爬取
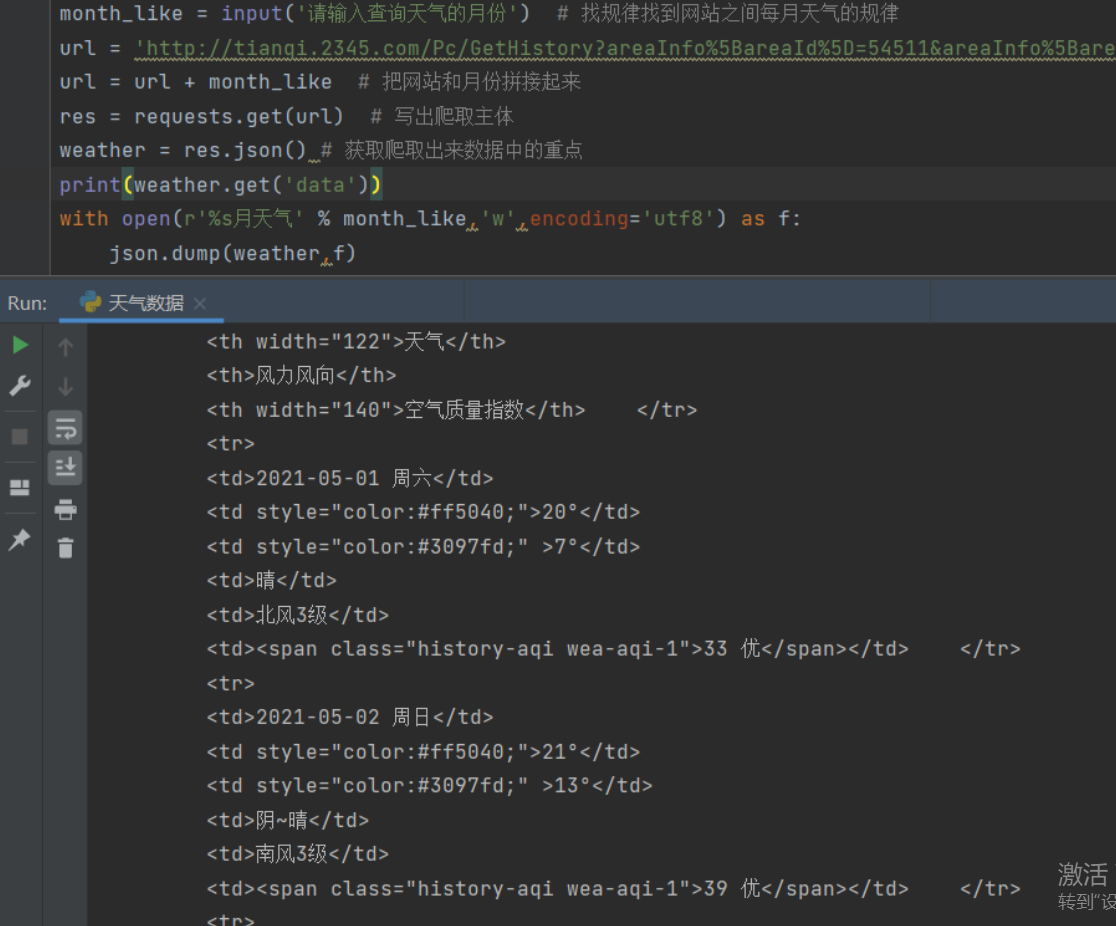
import requests # 1.导入模块
import json
month_like = input('请输入查询天气的月份') # 找规律找到网站之间每月天气的规律
url = 'http://tianqi.2345.com/Pc/GetHistory?areaInfo%5BareaId%5D=54511&areaInfo%5BareaType%5D=2&date%5Byear%5D=2021&date%5Bmonth%5D='
url = url + month_like # 把网站和月份拼接起来
res = requests.get(url) # 写出爬取主体
weather = res.json() # 获取爬取出来数据中的重点
with open(r'%s月天气' % month_like,'w',encoding='utf8') as f:
json.dump(weather,f)
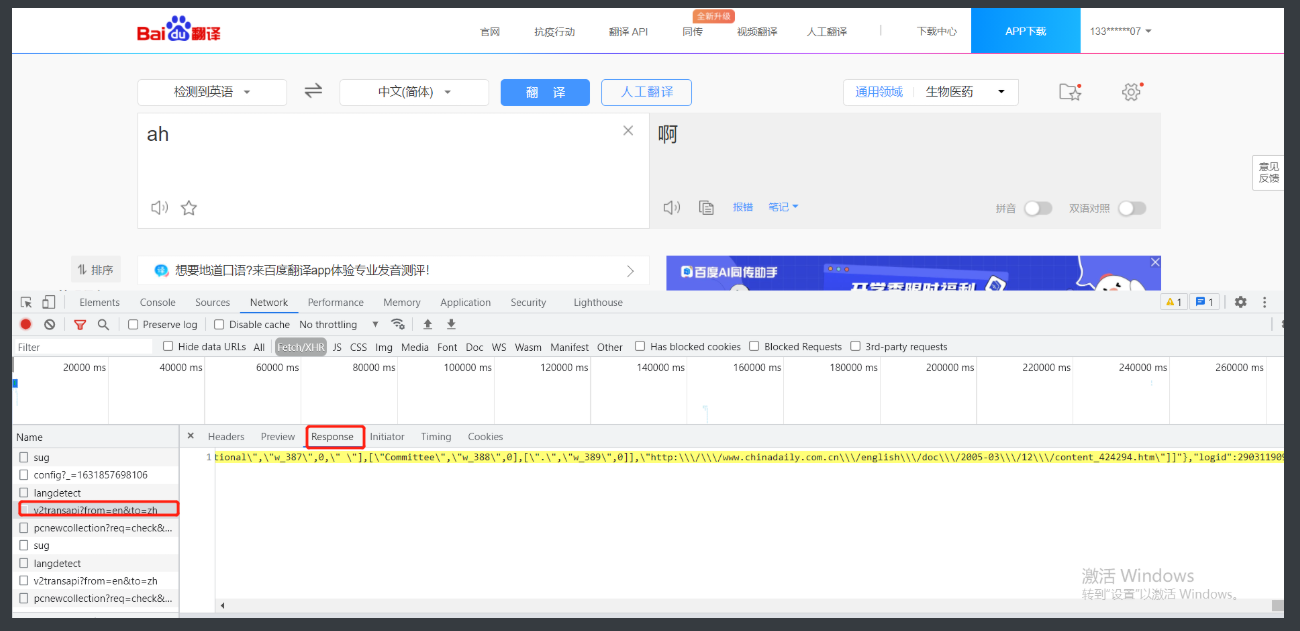
爬百度翻译
1.首先还是一样研究一下网页
2.网页地址没有变化但是每输入一个字母就有相应的翻译
3.那基本确定network里面有什么小东西蠢蠢欲动的
4.所以打开network + fetch 在输入单词观察一下
5.一看吓一跳啊 每输入一个字符要跳至少4个加载的数据还有3个在post请求体里面有我输入的字符
6.这时候无法区分那就点一下后面的response观察一下返回的到底是什么
7.放到bejson里面不难发现是按区域分开的翻译信息
8.那返回结果最实用sug翻译小区域的为例就可以开始书写代码了
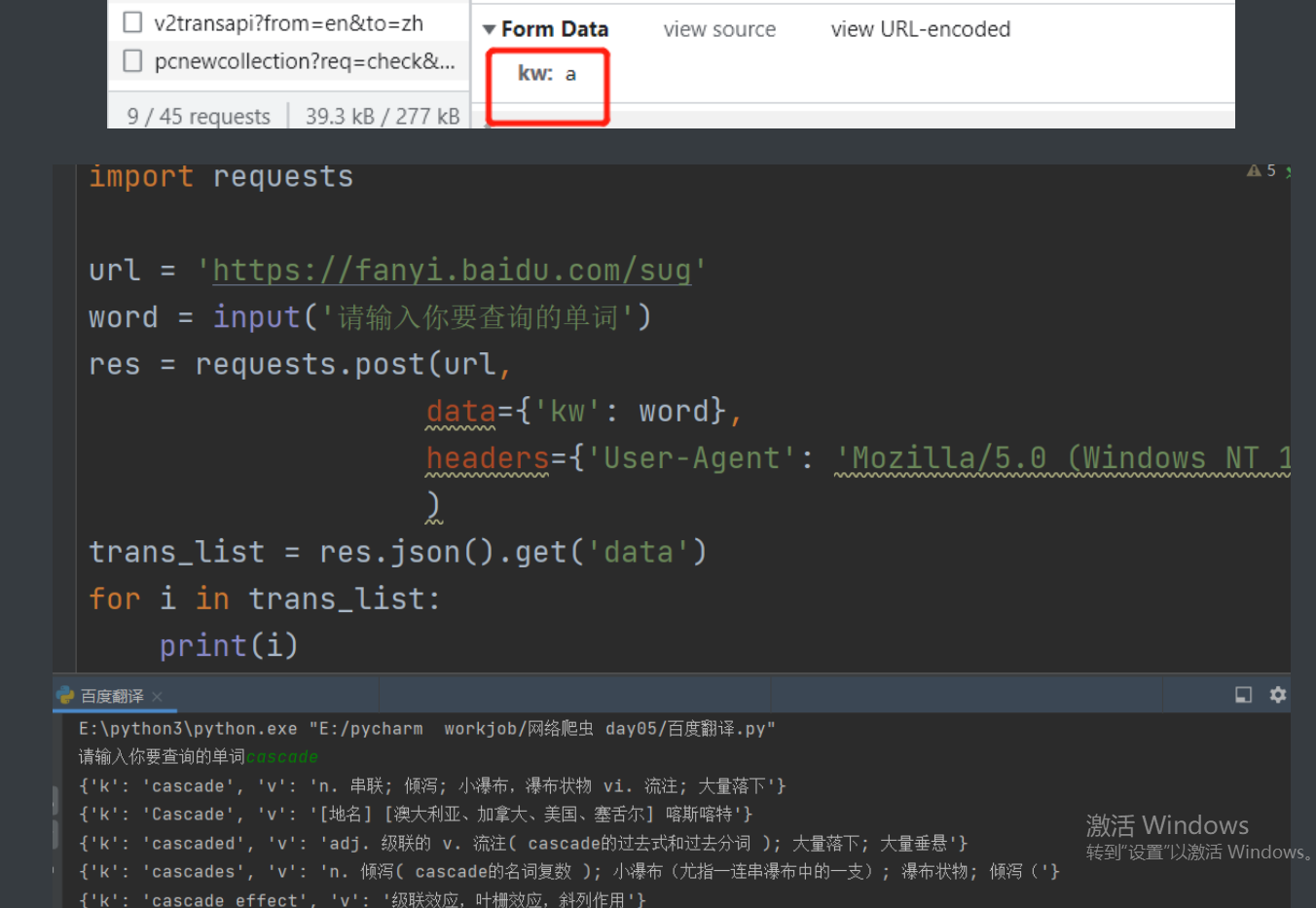
import requests
url = 'https://fanyi.baidu.com/sug'
word = input('请输入你要查询的单词')
res = requests.post(url,
data={'kw': word},
headers={'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/93.0.4577.82 Safari/537.36'}
)
trans_list = res.json().get('data')
for i in trans_list:
print(i)
爬药品许可证
1.首先查看网站的布局,先看一个个点进去的链接是不是是什么成分
2.没有找到那就是说明这个东西是动态加载的
3.由于需要爬取的数据是通过这个链接进入的但是数量也不允许手动一个个去添加
4.那就要在加载的时候就打开network好好观察一下
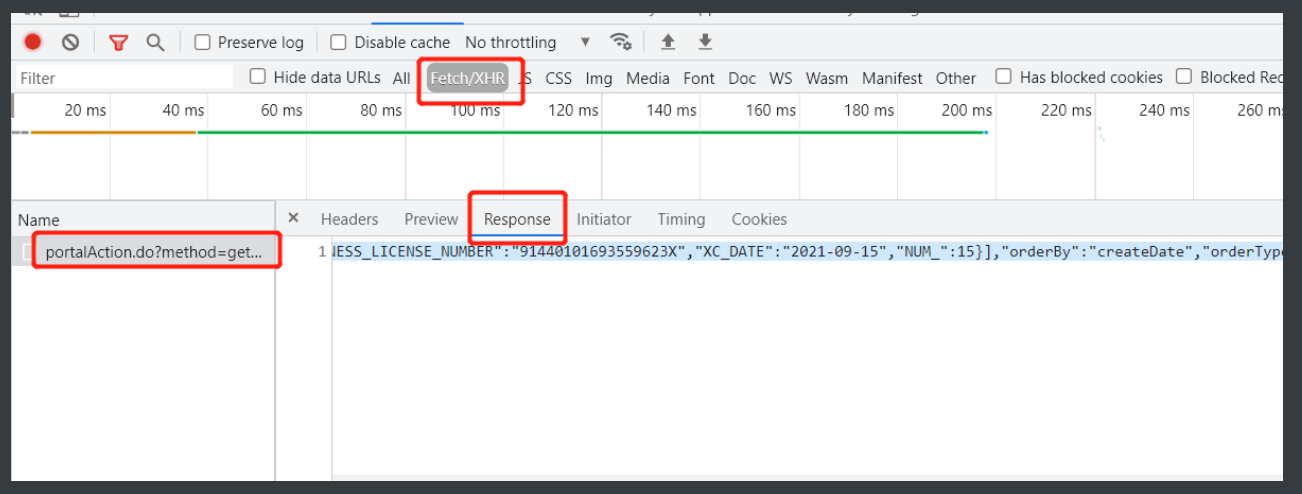
5.重新带着透视看这个网站载入发现了偷偷向外发送的请求就一个
6.那基本可以确定这页上的数据是通过这个请求得来的以防万一放到bejson看一下

7.发现没错那就可以先写一部分代码
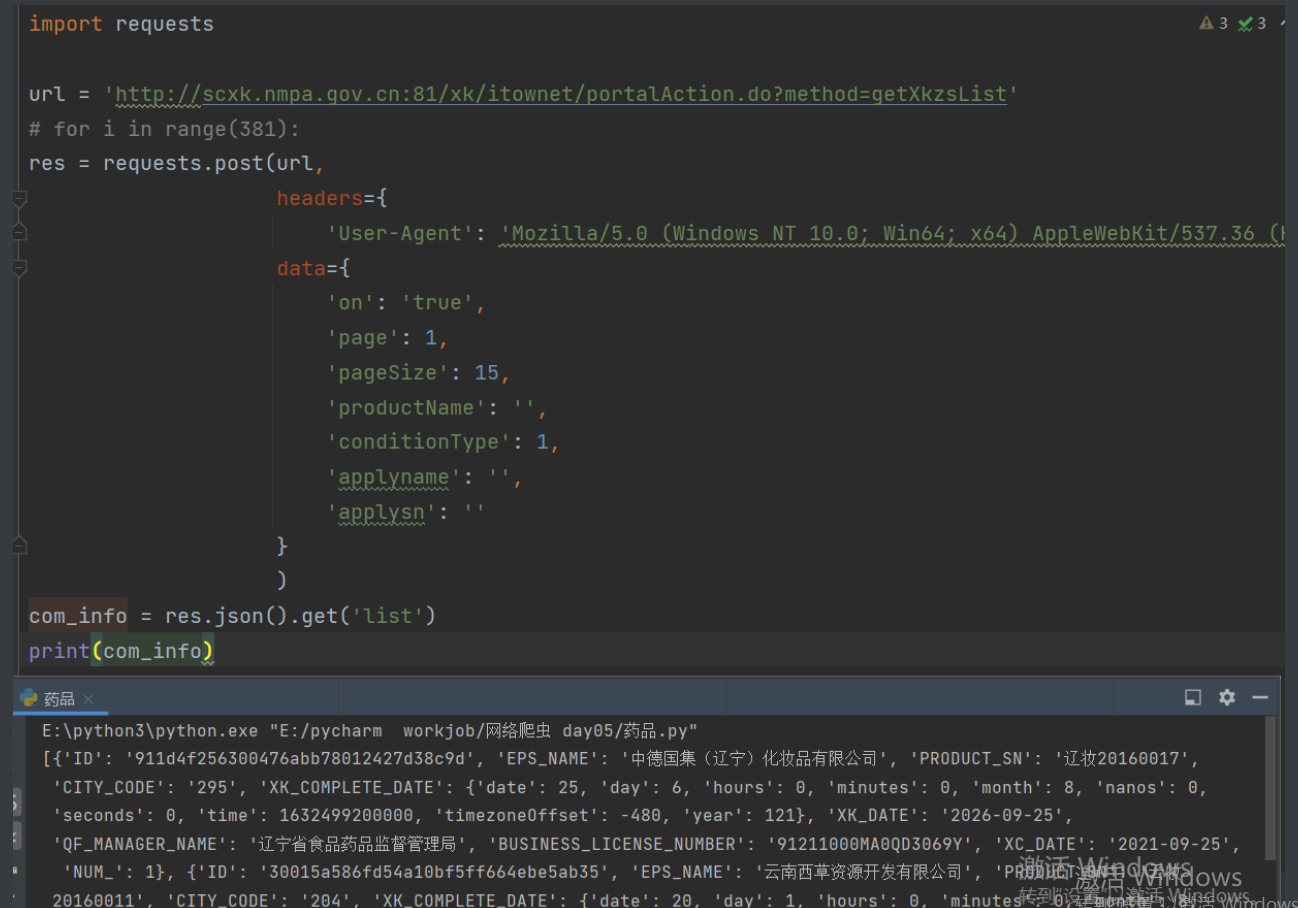
8.现在找到了一个个的公司名字了但是我们实际需要的数据是点进去里面的详情
9.这时候就要点进详情再重复一下1到6
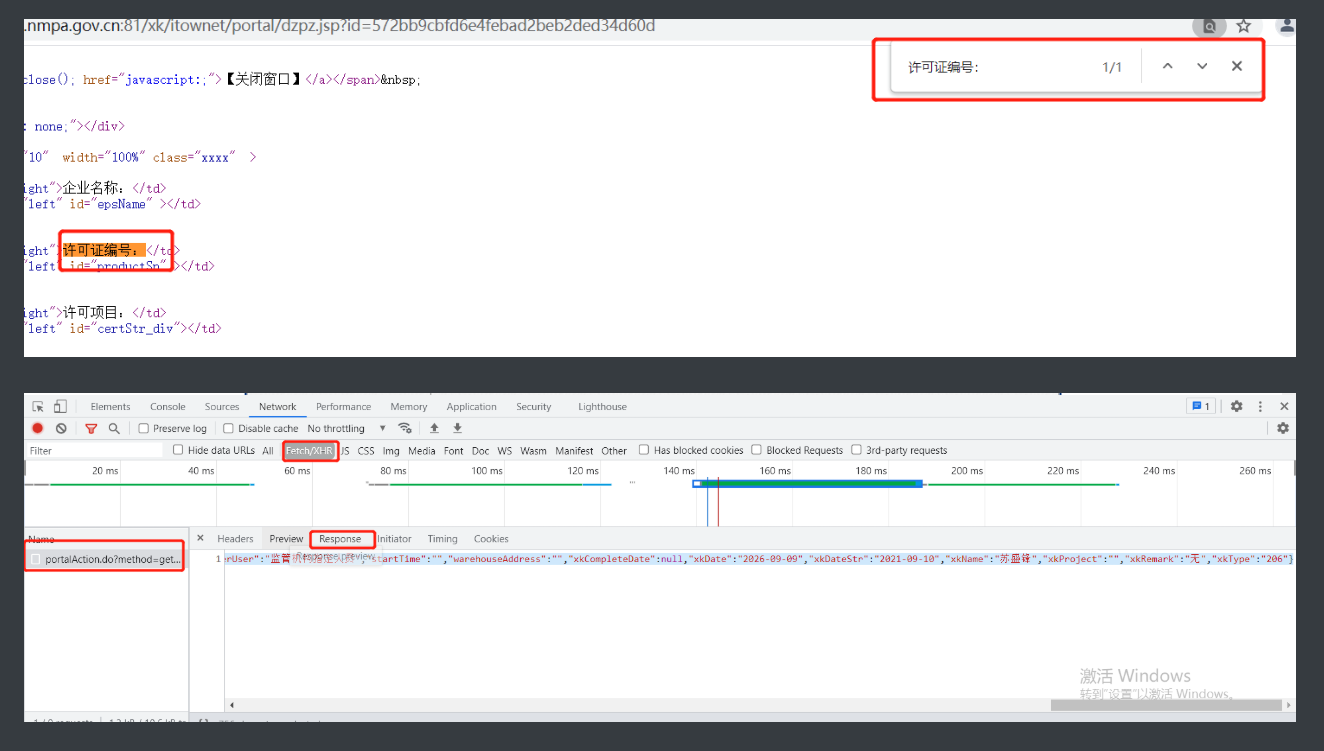
10.这次是直接写在网页上了但是network里也找到了好东西
11.这时候可以直接把整个网站爬下来再筛选数据也可以看一下response里面的内容先
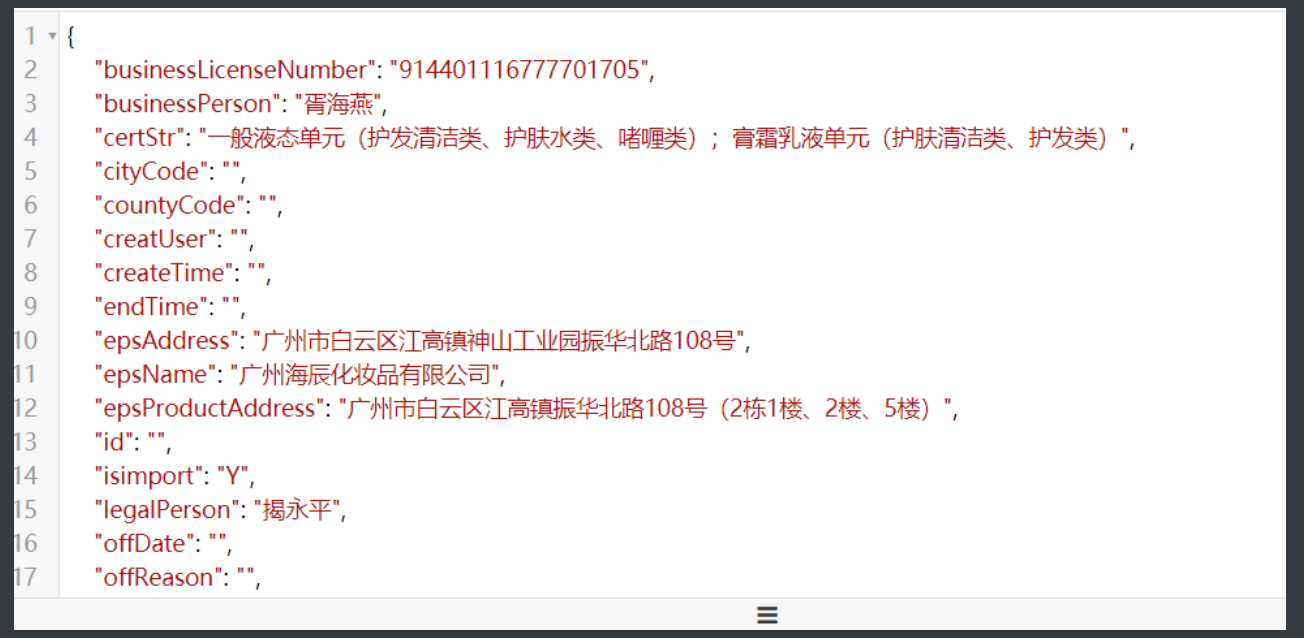
12.运气不错这个post请求回的数据也是表格内容,稍加比对就知道直接用response的内容更加好
13.那再看这个post是向哪里发送的请求的
http://scxk.nmpa.gov.cn:81/xk/itownet/portalAction.do?method=getXkzsById
请求体id: 911d4f256300476abb78012427d38c9d
14.这时候就要试着找找规律看看别的几个网站点开是什么样的
15.点开下面的链接接着看
http://scxk.nmpa.gov.cn:81/xk/itownet/portalAction.do?method=getXkzsById
请求头id: 35094851733f4bcd8f09704a2ac8156b
16.多次重复确认是向上述网站发送的请求并且请求体的id每次都不同
17.现在的问题就是要获取到请求体中的id就行了
18.巧了刚才爬的标签里有个id信息拿出对应的看一下
911d4f256300476abb78012427d38c9d
19.雀食是一样的嘛
20.那再代码里把这部分请求循环取值就好了
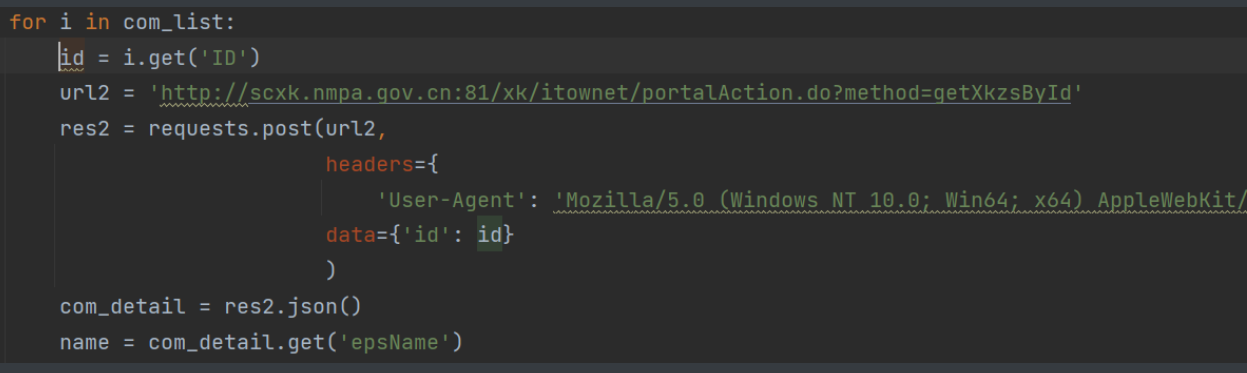
21.通过路径拼接和w模式写入数据最后的结果就是
import json
import os
import requests
if not os.path.exists(r'company_info'):
os.mkdir(r'company_info')
url1 = 'http://scxk.nmpa.gov.cn:81/xk/itownet/portalAction.do?method=getXkzsList'
for p in range(1,381):
res1 = requests.post(url1,
headers={
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/93.0.4577.82 Safari/537.36'},
data={
'on': 'true',
'page': p,
'pageSize': 15,
'productName': '',
'conditionType': 1,
'applyname': '',
'applysn': ''
}
)
com_list = res1.json().get('list')
for i in com_list:
id = i.get('ID')
url2 = 'http://scxk.nmpa.gov.cn:81/xk/itownet/portalAction.do?method=getXkzsById'
res2 = requests.post(url2,
headers={
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/93.0.4577.82 Safari/537.36'},
data={'id': id}
)
com_detail = res2.json()
name = com_detail.get('epsName')
info_add = os.path.join(r'company_info', name)
with open(info_add, 'w', encoding='utf8') as f:
json.dump(com_detail, f)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号