
9/8
今日考题
1.详述你所知道的表查询关键字并针对每个关键字说出具体功能辅以相应sql语句
# where用于数据没分类前的筛选
select * from t1 where ...;
# like用于模糊查询配合% _使用,跟在在where后面
select * from t1 where name like '%e%';
# group by分组分完之后就个体就不在有意义了所以select后跟的也是分组的字段
select job from t1 group by job;
# 聚合函数max min avg count sum用来配合分类使用
select job,count(id) from t1 group by job;
# having用于分组后的过滤和where功能一样但是用于group by之后
select job,sum(salary) from t1
where age > 20 ,
group by job,
having sun(salary) > 1000000;
# distinct去重 用于去掉完全一样的数据 一般要指定字段也可以做到类似联合唯一的复合去重
select distinct name,age from t1;
# order by排序不加关键字默认升序加desc降序
select * from t1 order by salary desc,age;
# limit用来取指定条数数据给一个参数是取几条两个参数前一个是跳过多少条后面是取几条
select * from t1 limit 3,3;
# regexp正则 通过一串特殊符号指定对所要查找文本的限定
select * from t1 regexp ...
2.修改表的sql操作有哪些
alter table t1 modify 旧字段名 新字段名 新数据类型 约束条件;
alter table t1 change 旧字段名 新字段名 新数据类型 约束条件;
alter table t1 drop 字段名;
alter table 旧名 rename 新名字;
复习巩固
- select和from
# select
后面写需要查询的字段
# from
后面写需要查询的表名
'''面对复杂的查询时通常先写好 select * from 表名之后再慢慢加'''
- where
# 对整表做一个初步筛选
后面写一系列筛选条件
比较运算
逻辑运算
成员运算
...
# 模糊查询
关键字 like
符号
% 有位置限制的无限张赖子
_ 有位置限制的一张赖子
- group by
# 按指定条件把单个的一大堆数据 分开重组 成一个个群体
group by 后面写分组的依据
'''分组完最小单位就以组为最小单位
所以默认只能直接获取到分组依据'''
mysql不同版本数据库表现不同
# 聚合函数
主要用于分组之后的数据处理
max min avg sun count
- having
# 对分组之后的数据进行二次筛选
后面写分组之后的过滤条件
select post,avg(salary) from t1
group by post having avg(salary)>100;
- distinct
# 对重复的数据去重操作
后面写需要去重的字段名
select distinct age from t1;
- order by
# 对指定字段排序
后面写需要排序的字段名
'order by 可以按照多个字段排序'
- limit
# 对数据进行分页处理 控制展示条数节省资源
后面写数字 可以一个也可以两个
- regexp
# 按照正则表达式筛选符合条件的数据
后面写正则表达式
内容概要
- 补充知识
- 多表查询理论
- 可视化软件navicat
- 多表查询练习题(难)
详细讲解
回顾训练
1. 查询岗位名以及岗位包含的所有员工名字
select post,group_concat(name) from emp group by post;
2. 查询岗位名以及各岗位内包含的员工个数
select post,count(id) from emp group by post;
3. 查询公司内男员工和女员工的个数
select gender,count(id) from emp group by gender;
4. 查询岗位名以及各岗位的平均薪资
select post,avg(salary) from emp group by post;
5. 查询岗位名以及各岗位的最高薪资
select post,max(salary) from emp group by post;
6. 查询岗位名以及各岗位的最低薪资
select post,min(salary) from emp group by post;
7. 查询男员工与男员工的平均薪资,女员工与女员工的平均薪资
select gender,avg(salary) from emp group by gender;
8. 统计各部门年龄在30岁以上的员工平均工资
select post,avg(salary) from emp where age>30 group by post;
补充知识
# 1.group_concat()方法
用来获取除分组以外的其他字段数据
select post,group_concat(name,'|',salary)
from emp group by post;
# 2.concat()方法 没有分组也能用
select concat(name,'|',salary) from emp;
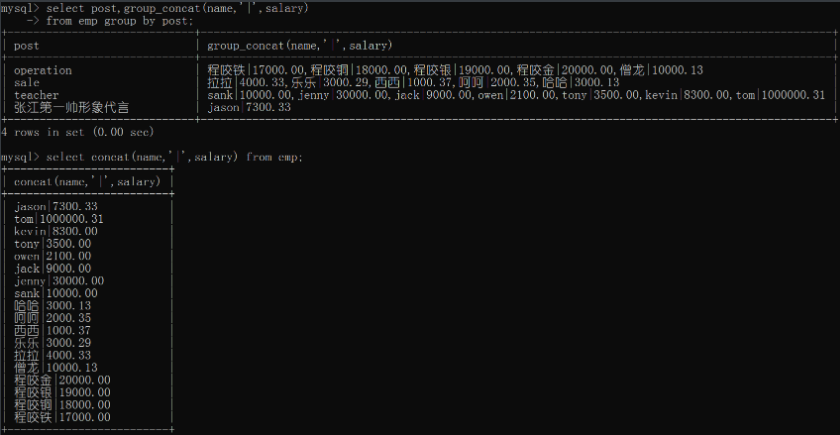
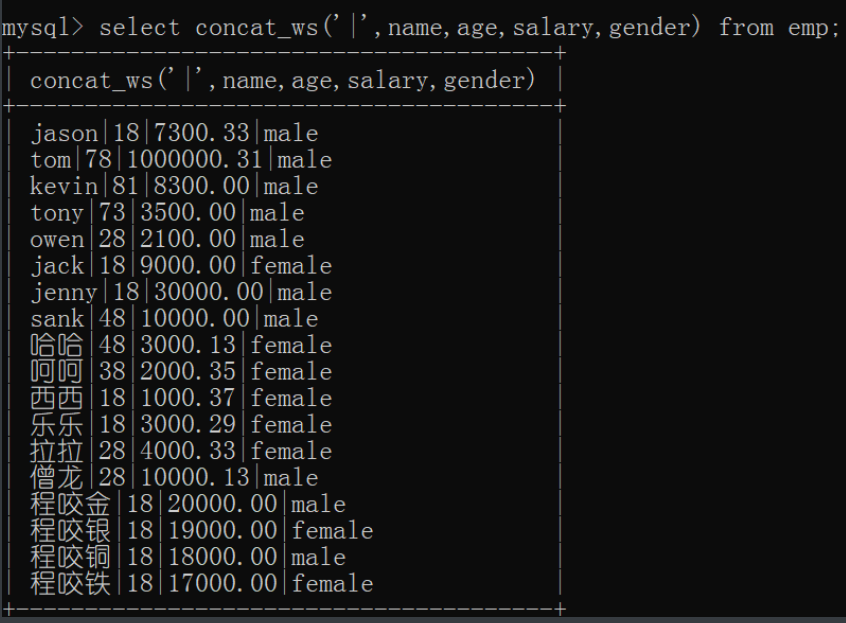
# 3.concat_ws() 用于多个字段之间分隔符相同
select concat_ws('|',name,age,salary,gender) from emp;
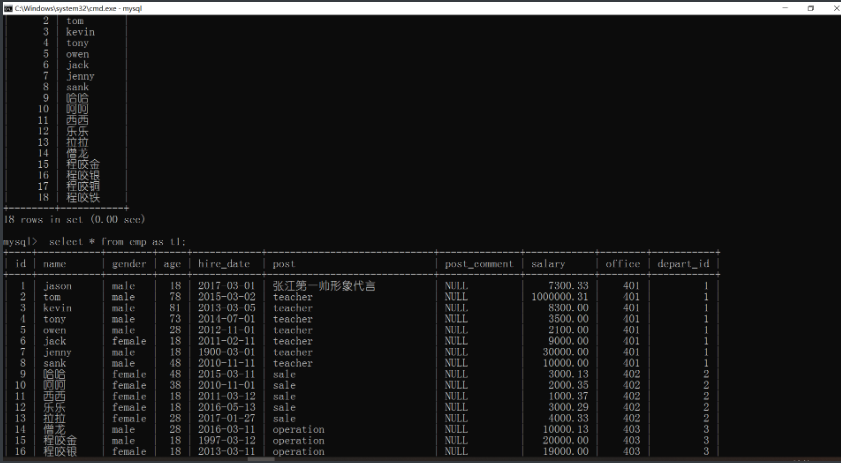
# 4.as语法
1.可以给字段名起别名(可以省略as但是不建议)
select id as '序号',name as '姓名' from emp;
2.同样可以给表名起别名
select * from emp as t1;
'''将emp表名起别名为t1 之后用t1指代emp'''
# as左边是字段as另一边就给字段名起别名 表同理
多表查询理论
多表查询:所需数据来自多张表数据的组合
#建表
create table dep(
id int primary key auto_increment,
name varchar(20)
);
create table emp(
id int primary key auto_increment,
name varchar(20),
gender enum('male','female') not null default 'male',
age int,
dep_id int
);
#插入数据
insert into dep values
(200,'技术'),
(201,'人力资源'),
(202,'销售'),
(203,'运营');
insert into emp(name,gender,age,dep_id) values
('jason','male',18,200),
('egon','female',48,201),
('kevin','male',18,201),
('nick','male',28,202),
('owen','male',18,203),
('jerry','female',18,204);
'''
SQL语句查询出来的结果其实也可以看成是一张表
涉及到多表查询可能会出现字段名冲突所以需要在字段名前面加上表名作限制
'''
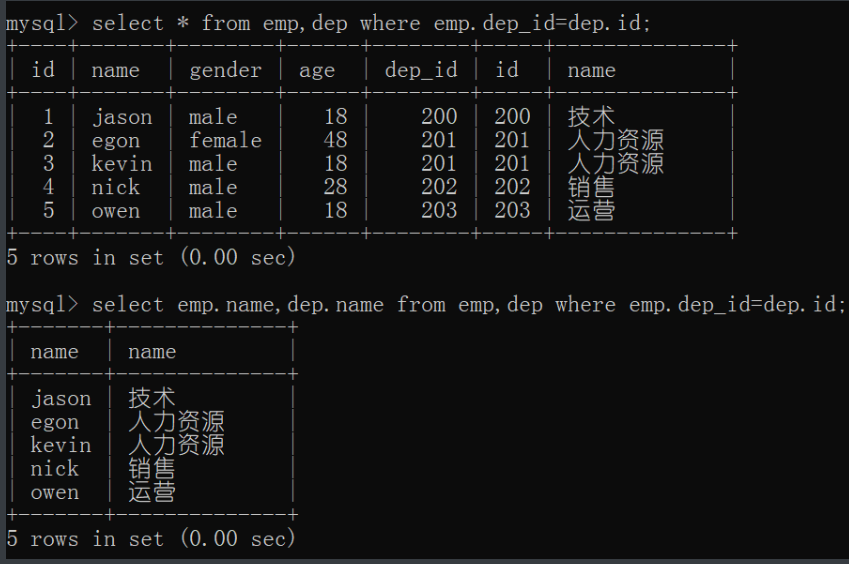
# 查询员工姓名以及对应的部门
# 推导思路
1.员工名在emp表 部门名在dep表
2.先把两个表放一起打开 得到笛卡尔积(所有数据都对应一遍)
select * from emp,dep;
3.再通过筛选选出外键和主键对应的数据留下
select * from emp,dep where emp.dep_id=dep.id;
# 注意此处id前加了表名和句点符来区分
4.最后把*替换取到我们想要部分的数据
select emp.name,dep.name from emp,dep where emp.dep_id=dep.id;

多表查询之联表
'''联表顾名思义 是先将多张表拼成大表 然后再用单表查询完成'''
mysql中拼接表的关键字
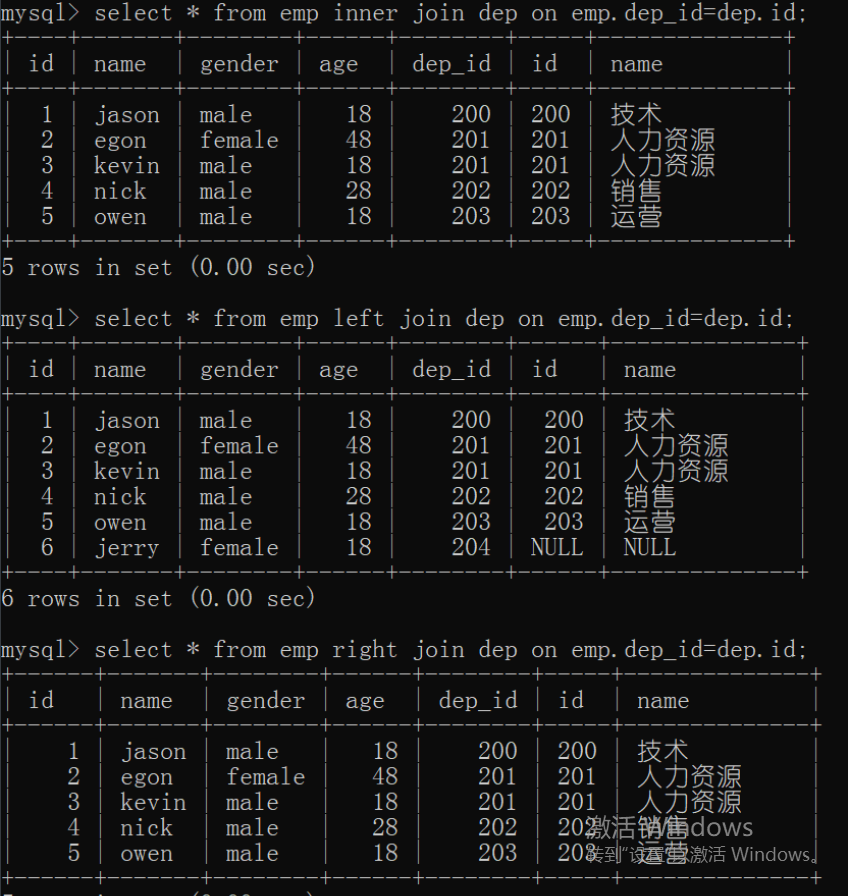
# inner jion 内链接
select * from emp inner join dep on emp.dep_id=dep.id;
把数据按照后面的要求链接起来,没有就不显示
# left join 左链接
select * from emp left join dep on emp.dep_id=dep.id;
把关键字左边表全展示之后按后面的要求链接右表 没有的数据用null填充
# right join 右链接
select * from emp right join dep on emp.dep_id=dep.id;
把关键字右边表全展示之后按后面的要求链接右表 没有的数据用null填充
# union
select * from emp left join dep on emp.dep_id=dep.id
union
select * from emp right join dep on emp.dep_id=dep.id;
多表查询之子查询
'''不同于联表查询 子查询通过将一张表的查询结果括号括起来当成是另一条SQL语句的条件'''
这样的步骤更符合生活中我们解决问题的思路>>>分步解决
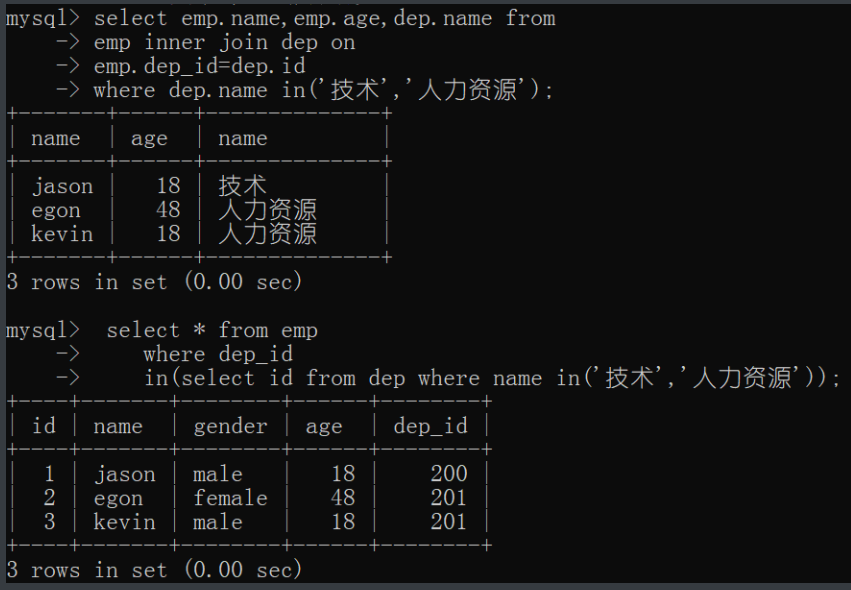
# 查询部门是技术或者人力资源的员工信息
1.通过联表操作做
select emp.name,emp.age,dep.name from
emp inner join dep on
emp.dep_id=dep.id
where dep.name in('技术','人力资源');
2.通过子查询
2.1先去查询技术和人力资源的id
select id from dep where name in('技术','人力资源');
2.2再通过这个拿到数据作为成员运算的条件
select * from emp
where dep_id
in(select id from dep where name in('技术','人力资源'));
多表查询总结
涉及到多表查询只有两种方法
1.联表查询
2.子查询
而且很多复杂情况需要两种方法结合使用
可视化软件之Navicat
可视化软件能大幅提升工作上一些基本操作的效率
Navicat就是其中之一
内部其实就是封装了相应SQL语句
# 白嫖大法https://defcon.cn/214.html
失效可以自行百度再找
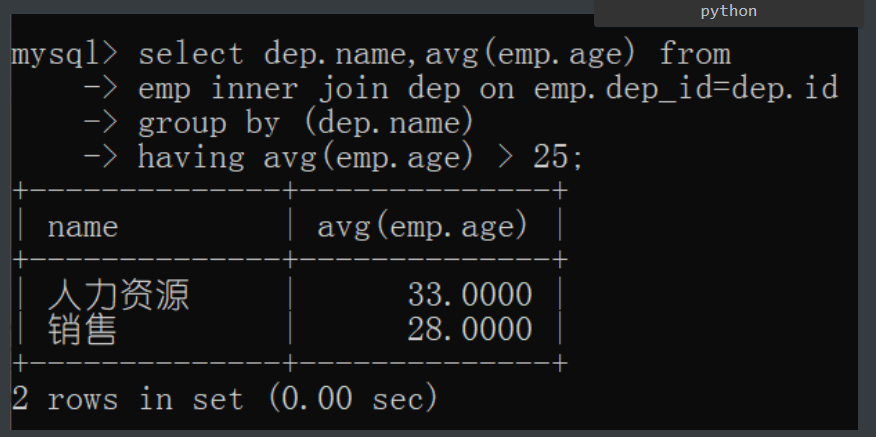
查询平均年轻在25岁以上的部门名(使用两种方式都完成一下)
# 联表操作
1.先把表用关键字联起来
select * from emp inner join dep on emp.dep_id=dep.id;
2.在通过部门分类筛平均年龄
select dep.name,avg(emp.age) from
emp inner join dep on emp.dep_id=dep.id
group by (dep.name)
having avg(emp.age) > 25;
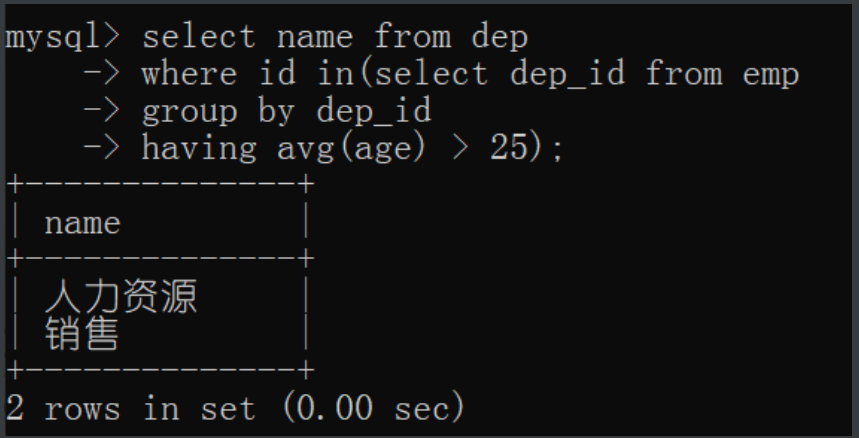
# 子查询
1.先找到平均年龄过25的部门id
select dep_id from emp
group by dep_id
having avg(age) > 25;
2.再通过筛选后的数据找到对应部门
select name from dep
where id in(select dep_id from emp
group by dep_id
having avg(age) > 25);

 浙公网安备 33010602011771号
浙公网安备 33010602011771号