面向知识库补全的合成向量空间模型
原文:Compositional Vector Space Models for Knowledge Base Completion
出版:arXiv:1504.06662 [cs.CL]
代码:未开源
数据集:http://iesl.cs.umass.edu/downloads//inferencerules/release.tar.gz
版权申明:版权归原文所有,如有侵权请联系管理员删除
摘要
知识库(KB)补全通过对现有事实进行推断来增加新的事实,例如从bornIn(X,Y)推断出containedIn(X,Y)的可能性很大。以前的大多数方法都是这样推断简单的一跳关系同义词,或者使用作为原子特征的多跳关系路径作为证据,比如bornIn(X,Z) → containedIn(Z,Y) 。
本文提出了一种非原子地推理多跳关系的连接的方法,用一个循环神经网络(RNN)组成路径的含义,该网络将路径中二元关系的向量嵌入作为输入。这不仅使我们能够推广到训练时未见过的路径,而且,通过一个高容量的RNN,还可以预测在组合模型训练时未见过的新关系类型(zero-shot learning)。我们收集了一个超过5200万个关系三元组的新数据集,并表明我们的方法比传统分类器提高了11%,比利用预训练嵌入的方法提高了7%。
模型方法
RNN
由于我们使用连接实体对的路径来预测缺失的关系类型, 所以本文提出了一个用于KB补全的RNN模型。如下图所示,KB图中的路径(任何长度)的向量表示是通过递归地应用组合函数计算出来的。为了计算树中较高节点的向量表示,组合函数消耗节点的两个子节点的向量表示,并输出一个相同维度的新向量。通过使用sigmoid函数比较路径的向量表示和的关系向量表示,对缺失的关系类型进行预测。
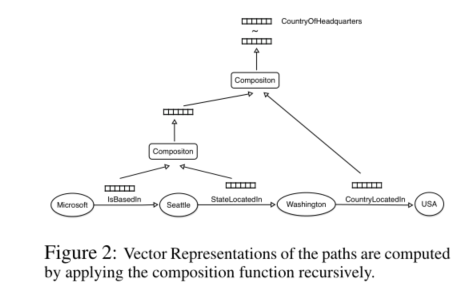
路径表征公式如下:
对于一条关系路径,如果只有两个关系,如:IsBasedIn -> StateLocatedIn, 其路径表征公式如下:
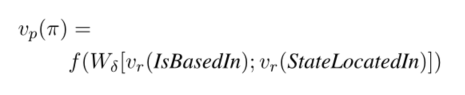
如对于上面的路径,接下来还存在第三个关系CountryLocatedIn, 即整条路径为:IsBasedIn -> StateLocatedIn -> CountryLocatedIn。其路径表征公式如下:
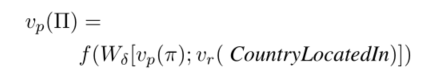
最后我们通过sigmod函数来比较上述路径表征与对应关系(如CountryOfHeadquarters)的向量表征,从而预测是否满足该关系。
训练技巧
在我们的任务中,对于连接实体对的路径集,我们将这些路径中向量表示与待预测关系的向量表示的最大点积的路径作为待选择的最终路径。
具体公式如下:
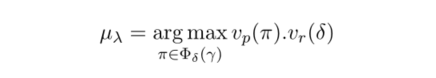
训练损失函数如下:
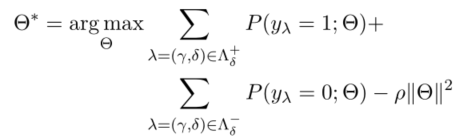
其中前一项是正样本的概率计算,中间一项是负样本的概率计算,最后一项是二次罚函数。
其中概率计算公式如下:
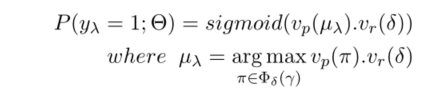
模型改进
在Zero-shot任务中,一些标签或类在训练模型期间是不可用的,只有在预测时给出这些类的描述。我们希望将模型推广到可以预测在训练集中不可见的待预测的关系,为此,对模型进行了两点修改:
- 学习一个复合的变换矩阵,而不是像之前一样与具体的待预测关系有关。
- 用预训练的向量固定关系向量,在训练过程中不发生改变。
对于前文提到的路径,其对应的组合函数修改后如下:
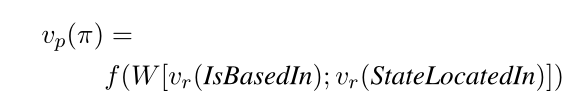
模型性能
实验参数
所有模型的超参数都是在相同的数据集上调优的。所有神经网络模型使用50维关系向量进行150次迭代训练,L2正则化器和学习率分别设为0.0001和0.1。在每60次迭代后,我们将学习率减半,并使用大小为20的小批量。使用AdaGrad优化神经网络和分类器。
数据集
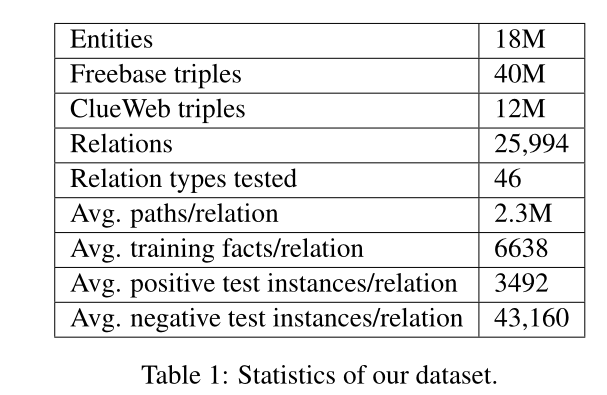
我们使用的数据集各项指标统计如下表:
结果
将我们的模型与常见的几类模型进行对比,得到具体结果如下表:
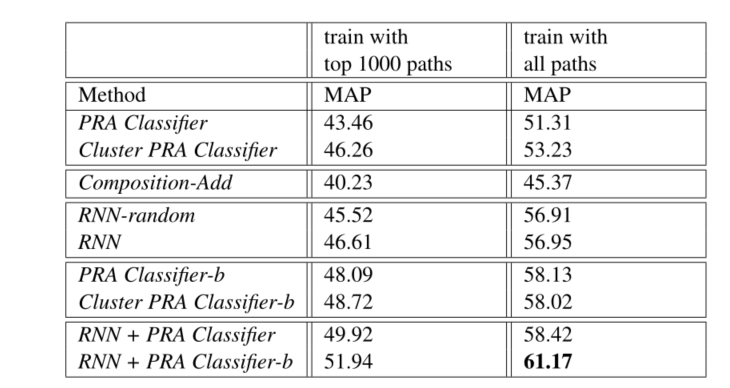
具体结论如下:
- 使用所有路径类型来训练模型的效果更好,而不是像以前的工作那样只使用前1000种路径类型
- RNN模型的性能不受初始化的影响,因为使用随机向量和预先训练的向量可以获得相似的性能。
- 对分类器进行扩展之后,取得了更好的性能。
在zero-shot上进行优化之后的模型性能比较如下:
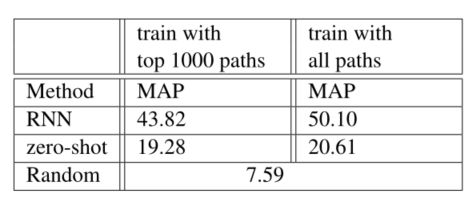
具体结果为:完全监督的RNN在很大程度上优于zero-shot模型,但不使用任何直接监督的zero-shot模型显然比随机基线要好得多。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号