2021-Constructing Bug Knowledge Graph as a Service for Bug Search
构建Bug知识图作为Bug搜索服务
摘要
当遇到bug问题时,开发人员倾向于搜索bug存储库和提交存储库以获取参考。然而,版本控制系统中错误报告和提交之间的联系经常被忽略,错误库和提交库所能提供的信息很简单。当开发人员搜索一个bug问题时,他们只能获得bug报告或提交的信息,这些信息是松散的,很难供开发人员参考。更有甚者,很多搜索结果并不准确。针对这些问题,本文提出了一种利用主题模型处理bug和提交信息的方法,并构建bug知识图作为辅助bug搜索的服务。此外,随着与bug相关的信息量不断增加,更新数据非常耗时。我们可以用LTM主题模型(终身主题模型)自动更新bug知识图。最后,对来自Bugzilla@Mozilla的错误报告和来自Github的相应提交进行了实验。实验结果表明,该方法通过构建bug知识服务来帮助开发者搜索相关bug以供参考是有效的。
文章贡献
- 主题模型用于处理bug报告和提交中的信息,我们将bug知识图构建为一个服务来捕获bug数据中更全面的信息和链接。
- 采用终身主题模型,随着bug知识库和提交知识库中数据的增加,自动更新bug知识图,不断提高bug搜索的效率。
- 用真实的bug数据对我们的方法进行了评估,结果表明了我们方法的有效性和高效性。
系统架构
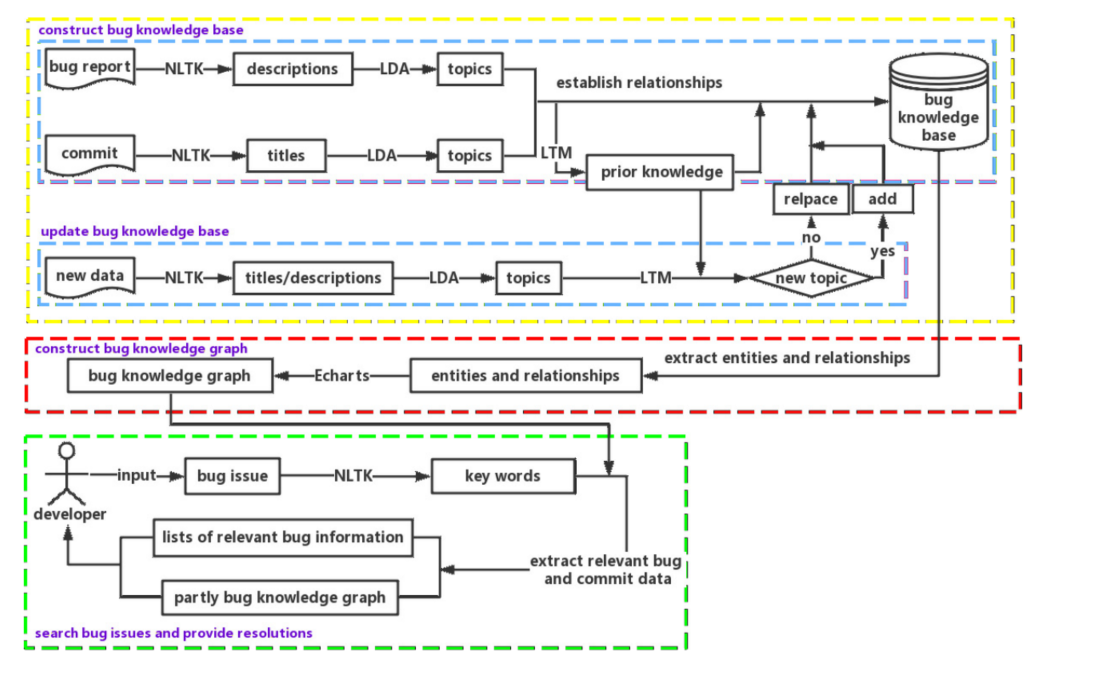
我们方法的整个过程,分为三个阶段。在第一阶段,挖掘bug报告和提交。借助LDA主题模型构建了缺陷知识库。然后,利用LTM主题模型提取缺陷知识。当有新数据添加到缺陷知识库时,运行LTM主题模型来判断新数据的主题是否是新主题。如果它是一个新主题,它将被添加到bug知识库中。如果不是新题目,bug知识库中的相同数据会被替换。在第二阶段,我们从bug知识库中提取bug实体、提交实体以及bug报告和提交之间的关系来构建bug知识图。之后,使用Echarts(一种可视化工具)构建bug知识图作为服务,方便开发者使用。第三阶段,当开发人员在bug知识图中搜索bug问题时,使用NLTK(Python中的一种自然语言处理工具)对输入进行预处理。之后,从bug知识图中提取相关的bug数据。最后,相关搜索结果以列表和部分bug知识图的形式返回。开发人员可以参考这些结果,形成解决bug问题的解决方案。下图展示了整个过程:
性能指标
为了评估我们的方法的性能,需要计算我们的方法和聚类方法的精度。该指标广泛用于测量搜索和推荐结果中相关信息的百分比。精度值是基于两个统计数据计算的:真阳性(TP)和假阳性(FP)。真正的阳性代表我们搜索的相关信息。误报代表我们搜索的无关信息。
使用以下公式计算精度:
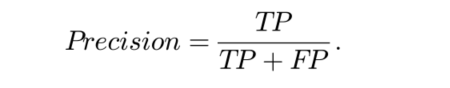
精确度可以反映我们方法的效率。根据上面的公式,精确度是搜索结果的相关信息的比率。
实验结果
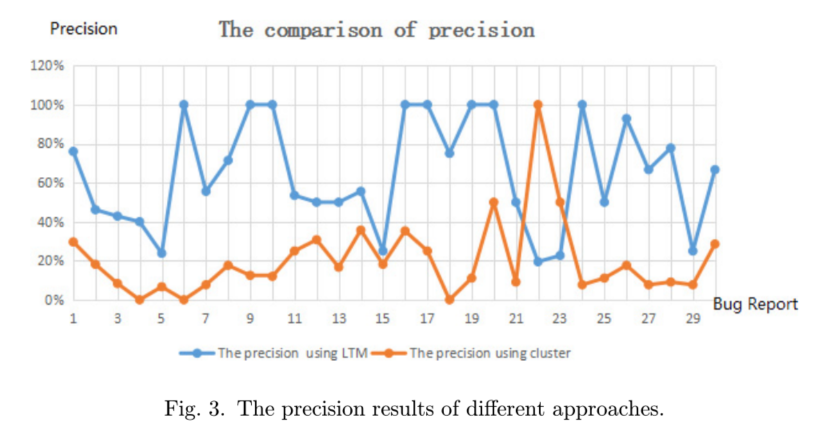
在下图中,蓝线表示使用LTM主题模型的精度,橙线表示使用聚类方法的精度。我们看到,我们的方法的大部分精度结果都比使用聚类方法的结果要高。该方法的平均准确率为64.53%,而聚类方法的平均准确率为20.30%。这表明使用LTM主题模型对缺陷报告进行分类更有效。也就是说,我们的方法可以提供更准确和相关的错误相关信息。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号