Categorizing and Predicting Invalid Vulnerabilities on Common Vulnerabilities and Exposures
在CVE上分类和预测无效漏洞
摘要
为了在不同的数据库、工具和服务之间共享漏洞信息,新发现的漏洞会定期报告给Common vulnerability and exposure (CVE)数据库。不幸的是,并不是所有的漏洞报告都将被接受。其中一些可能会被拒绝或通过争论被接受。在本工作中,我们将那些被拒绝或有争议的cve称为无效的漏洞报告。无效的漏洞报告不仅会导致不必要的确认漏洞的工作,而且还会影响软件供应商的声誉。
在本文中,我们的目标是了解无效漏洞报告的根本原因,并建立一个预测模型来自动识别它们。为此,我们首先利用卡片分类来对无效的漏洞报告进行分类,从这些报告中可以观察到被拒绝和有争议的cve的六个主要原因。然后,我们提出了一种文本挖掘方法来预测无效漏洞报告。实验结果表明,本文提出的文本挖掘方法预测失效漏洞的AUC得分为0.87。我们还讨论了我们的研究的含义:我们的分类可以用来指导新的提交者避免这些陷阱;通过使用自动化技术或优化评审机制,可以避免一些导致cve失效的根本原因;不应忽视无效的漏洞报告数据。
主要贡献
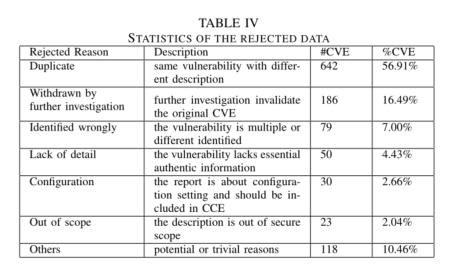
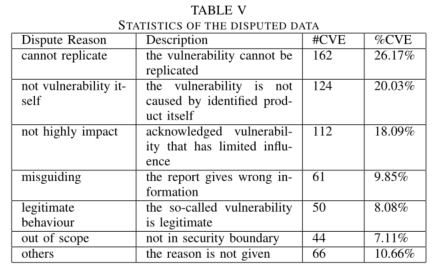
- 我们对从已知cve获取的无效漏洞报告进行了探索性研究。通过利用卡片排序方法,我们手动分类导致CVE候选被拒绝或争议的主要原因。
- 我们建立机器学习模型来自动预测新提交的CVE的有效性。实验结果表明,该方法能够自动预测CVE是否失效。我们也给出了能够帮助区分有效和无效cve的最重要的判别特征。
无效漏洞定义
在我们的研究中,一个无效的CVE条目是指一个不合格的漏洞报告,它所对应的漏洞不能被验证、复制,或者不能像报告所声称的那样真正影响安全性。在本文中,无效的CVE包括拒绝CVE和有争议的CVE。被拒绝的CVE会造成不必要的麻烦,例如浪费时间检查和修复。有争议的CVE将干扰曝光,因为这些漏洞不能被真正视为威胁,而且还会引起无关紧要的恐慌和对供应商的诽谤。
卡片分类
卡片分类被广泛用于生成类别。在卡片分类中,参与者创建类别名称并将条目分类到其中。在卡片排序过程中有两个阶段:在准备阶段,我们为每个CVE条目创建一张卡片。在执行阶段,卡片被分成具有描述性标题的有意义的组。第一和第二作者分别为卡片贴上标签。对于每张卡片,我们突出显示了与根本原因相关的关键短语,并将具有类似关键短语的卡片归类到同一组中。然后,这两个注释者一起工作以达成最终协议,并为所标识的每个类别分配一个有意义的名称。
对于被拒绝的CVE条目和有争议的CVE条目,我们得到了六个主要类别,如下图所示
实验结果
预测无效CVE
考虑到CVE在36436种产品中的多样性,为了给出一个整体的见解,我们使用分层的10倍交叉验证来评估模型的有效性。在实验中,我们应用过采样技术来处理不平衡数据问题。此外,我们使用相同的纵向数据设置来模拟我们的方法在实践中的使用,这意味着我们保持CVE提交给数据库的时间顺序。
根据时间顺序和5年的间隔,我们将我们的数据分为三个阶段(2002-2007年、2008-2012年、2013-2017年)。我们依次使用前一个阶段作为训练数据来预测下一个阶段。2002-2007年、2008-2012年和2013-2017年无效和有效报告的分布分别为509比28309、155比26138和122比39706。
在10倍交叉验证实验中,SVM表现最好,而随机森林排名第二。在时间序列实验中,随机森林的性能最好,因为它的AUC都比其他预测模型大得多。此外,随机森林在时间序列验证方面的性能最好,模拟了我们的方法在实际中的应用。
区分CVE无效和有效的指标
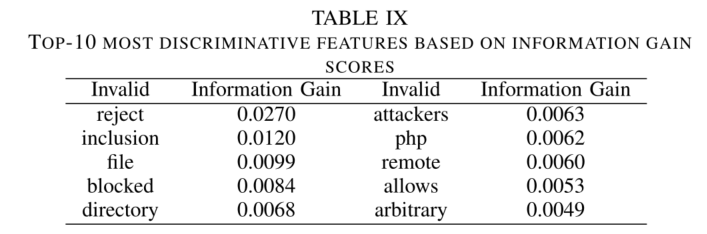
上表是根据信息增益分数排序的前10个特征。我们注意到信息增益分数很低(可能的最大值为1),这说明在如此庞大的语料库中,仅一个特征不足以将有效的CVE与无效的CVE进行分类。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号