Name Disambiguation in AMiner-Clustering, Maintenance, and Human in the Loop
Name Disambiguation in AMiner: Clustering, Maintenance, and Human in the Loop
本文通过结合全局和局部信息提出了一个全面的框架来解决名字消歧问题,并提出比传统基于 BIC 方法更好的端到端的簇大小估计方法。为提高准确性,加入反馈机制,与 GHOST 等目前集中最先进的方法相比,该方案有明显的性能提升。
1. 挑战
- 如何量化不同数据源中实体的相似性
- 可能没有重叠信息,需要设计一种量化规则
- 如何确定同名人数
- 现有方案通常预先指定
- 如何整合连续的数据
- 为确保作者经历,需要最小化作者职业生涯中的时间和文章间的间隔,保证其连续性
- 如何实现一个循环的系统
- 没有任何人为交互的消歧系统不够充实,利用人的反馈实现高的消歧准确性
2. 整体框架介绍

- 量化相似性
- 提出了一种结合全局度量和局部链接的学习算法,将每个实体投影到低维的公共空间,可直接计算其相似性
- 确定簇数
- 提出一种端到端的模型,使用递归神经网络直接估算簇数
- 结合人的参与
- 定义了来自用户/注释的6个潜在特征,将其结合到框架的不同组件中以改善消歧准确性
3. 相关研究
- 基于特征的方法
- 利用监督学习方法,基于文档特征向量学习每对文档间的距离函数
- Huang:首先使用块技术将具有相似名称的候选文档组合,然后通过 SVM 学习文档间距离,使用 DBSCAN 聚类文档
- Yoshida:提出两阶段聚类方法,在初次聚类后学习更好的特征
- Han:提出基于 SVM 和 Naive Bayes 的监督消歧方法
- Louppe:使用分类器学习每对的相似度并使用半监督层次聚类
- 基于链接的方法
- 利用来自邻居的拓扑和信息
- GHOST 仅通过共同作者构建文档图
- Tang 使用隐马尔科夫随机场模拟统一概率框架中的节点和边缘特征
- Zhang 通过基于文档相似度和共同作者关系从三个图中学习图嵌入
本文结合上述两种方法优点,结合监督学习全局嵌入和局部链接结构
- 估计簇大小
- 之前为预设值
- 使用 DBSCAN 之类方法避免指定k
- 使用 X-means 变体基于贝叶斯信息准测测量聚类质量迭代估计最优 K
本模型输入为一组文档嵌入,输出簇数量
4. 参数设置
设 a 为给定名字,关于 a 的文档集为
其中每篇文档的特征(包含 title,abstract,co-authors,venue.. )为
使用 I 表示 identity,如果
则两篇文章属于同一个人
姓名消歧问题
任务:寻早一个函数将一组文档 D 分到不同的集合
( 同一个集合仅包含同一人的文章 )
Ca 为 Da 名字a 的消歧结果
要解决消歧问题,需要更多的约束,此处主要考虑两种:
本身约束 Si 和成对约束 Sp
(y 表示是否数据集合 Ck)
成对约束
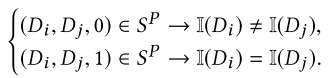
由个体约束推导成对约束
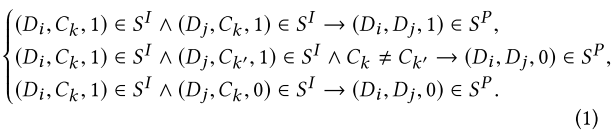
5. 框架
5.1. 表示学习
为有效量化不同文档间的相似性,将文档转换到同一嵌入空间,如果Di 与 Dj 相似,表示为:
5.1.1. 全局度量学习
每个文档 Di 被表示为一组不同长度的特征向量 Di = { x1,x2,...}---title,abstract,coauthors,venue..
每个特征为一个 one-hot 向量,首先将向量映射到一个连续的低维空间
每个文档的特征表示为
(每个特征嵌入的加权总和,an 是特征xn 的反转文档频率,xi 捕捉每个文档中共现统计量捕获特征之间的相关性)
但 xi 用于区分文档能力有限,需要其他协助
Contrastive Loss
给定一组约束
目的:强制正相关在嵌入空间内距离较近,反之,较远
设yi 为 Di 新的嵌入函数,目标为优化以下对比损失函数

(m 为margin)
由于将所有文档投影到同一空间的单个点上较困难(每个作者的不同文章可能为与不同社区协作的不同主题),因此采用排名学习,并优化三组损失函数
Triplet Loss
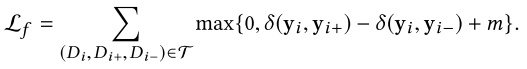
相对于投影到单个点,三元损失使得同一个体的文章可以在多个点,并同时获得与其他文档的距离
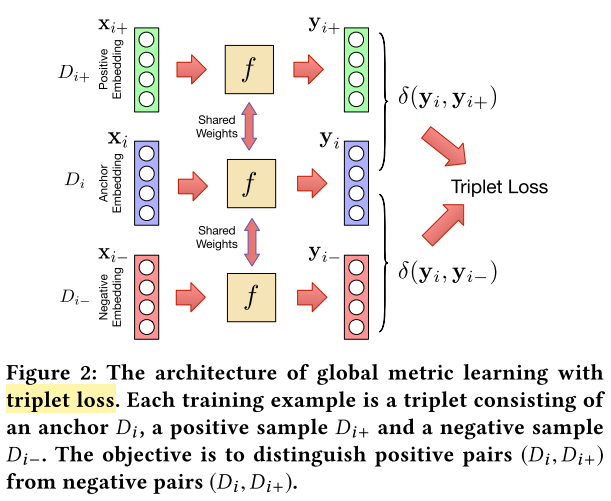
因为不同集合的文档被嵌入统一空间,因此称 {yi} 为全局嵌入
但是由于聚类是为每个名字单独进行的,还需要利用每个集合的局部信息提高性能
5.1.2. 本地链接学习
利用本地链路中的细粒度信息完善全局嵌入
为每个名称构建局部链路图(两个文档有较多相似特征则更有可能属于同一作者)
边为文档间的相似度,链接权重 W(Di, Dj) 为文档间共同特征的交集(共同特征的加权和)
如果 W 高于一个阈值,则建立边
使用无监督的自编码器从本地链路学习
自编码器
node encoder model
( Y 为D的嵌入矩阵,A 为图G 的邻接矩阵)
edge decoder model
(Z=[z1,z2...] 为节点嵌入矩阵,A 为预测的邻接矩阵
目标是最小化 A 和 A~ 之间的重构误差
使用图卷积网络(GCN)
( A 为对称的邻接矩阵,W0 W1分别是第一、二层的参数
解码器 g2
Di 和 Dj 间存在边的概率为
目标函数:最小化交叉熵
我们采用 Z=[z1,z2,...] 作为文档新的嵌入表示,包含来自全局和本地的信息
5.2. 簇估计
聚类大小估计
X-means缺点:
1. 基于预定义的测量方式(如贝叶斯信息准则)评分聚类质量--不能够处理复杂信息的融合,聚类数量较大时容易过拟合
2. 基于对潜在信息的拆分(数据集较大时不够高效)
因此提出 end-to-end 模型:
输入:文档集
输出:直接估计实体数量
方法
使用分层凝聚聚类(HAC) 作为主要聚类方法
本方法采用 RNN 作为编码器,尝试将一组嵌入向量映射到集合的真正簇数
递归神经网络在离散序列和数据集建模中的应用:
将 RNN 作为编码器,尝试将一组嵌入向量映射到分类簇中
挑战:
1. 输入集合变化范围是 1~nw
虽然 RNN 可通过填充或截断处理可变大小的输入,但也会引入偏差
2. 难构建一套训练集
手动标记不可行
解决-伪训练数据生成策略:
使用一种抽样策略构建伪训练集
设 C={C1, C2...} 是一组干净的簇(每个集群中仅包含单个作者的文档)
- 对每个第t步的训练,首先在[Kmin, Kmax] 间选取簇数 kt
- 从 C 中选取 Kt个集群构建伪候选集 Ct
- DCt:表示 C 中所有文档
- z: 表示固定样本大小
- 从DCt 中采样 z 个文档 Dt进行替换
- Dt 可能包含重复文档且 Dt 的顺序是任意的
- 通过此方式可从 C 中构建无数的训练集
- 使用一个神经网络框架使得 h(Dt)-->r
使用双向 LSTM 作为编码器,和一维全连接层作为解码器
输入:每篇文章的行特征嵌入
优化均方差 Lh
5.3. 连续集成
持续集成--如何处理不断增长的数据
本文以流媒体方式集成新文章
时间成本:主要来自本地链接的学习,聚类,及从数据库中抽取相关文档的 io
实时更新(使用最简单的KNN):
- 将新文档以下列方式贪婪的分配给现有的配置文件:
- 根据作者姓名和关联在系统中到排序搜索一组配置文件,每个配置文件对应一篇文章
- 如果有多个匹配,检索文档列表 Di 的全局嵌入 yi,并构建一个本地 KNN 分类器用于查找每个 Ck 的最佳分配
- 每一个 Ck 是一个类别, {(yi,}是一组带有标签的数据点
此策略能够实时更新文档,尽管可能为次优赋值,但可通过下次聚类重新计算的迭代进行校正
数据一致性
如何保证每次迭代更新之间的一致性
重新计算聚类后,可能结果与上次不一致
获取新的聚类后,搜索其与先前版本的最佳匹配
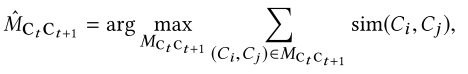
使用 Kuhn-Munkres 算法寻找最佳的映射
5.4. 利用人工注释
允许用户和注释根据聚类结果进行反馈,支持:
- 删除
- 删除文档
- 插入
- 将文档Di 添加到 Ck
- 拆分
- 注释为过度合并并请求聚类
- 合并
- 将 Ck 与 Ck‘ 合并
- 创建
- 确认
为在算法中利用反馈,根据等式1 将个体约束 Si 转换为成对约束 Sp,用到两个学习嵌入阶段
在全局嵌入中
从 Sp 中选取的训练集步骤如下
- 从Sp基于采样约束(Di,Dj,yij)
- 如果 yij = 0 则基于约束(Di,Dl,1)从 Sp 中采样,并生成三元组(Di,Dl,Dj)
- 否则,从整个文档空间中随机采样并生成三元组
本地链路学习中
基于 Sp 改善本地链路,添加边(Di,Dj)如果满足:

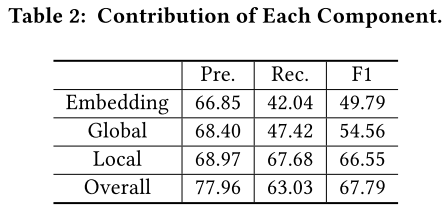
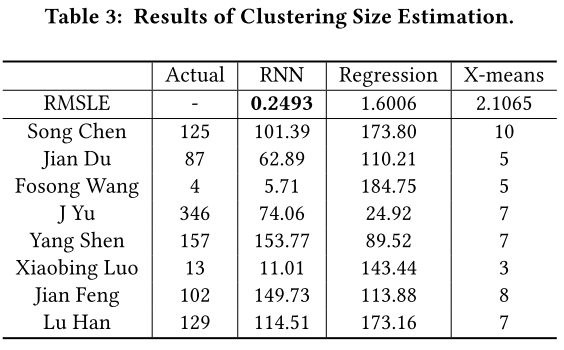
6. 效果

如果您认为本文对得起您所阅读所花的时间,欢迎点击右下角↘ 推荐。您的支持是我继续写作最大的动力,谢谢 (●'◡'●)
字节跳动职位长期内推,如有需求可发送简历至 lichaoran.cr@bytedance.com

 浙公网安备 33010602011771号
浙公网安备 33010602011771号