GAN生成的评价指标 Evaluation of GAN
传统方法中,如何衡量一个generator ?—— 用 generator 产生数据的 likelihood,越大越好。
但是 GAN 中的 generator 是隐式建模,所以只能从 P_G 中采样但没法根据 pdf 算 likelihood。
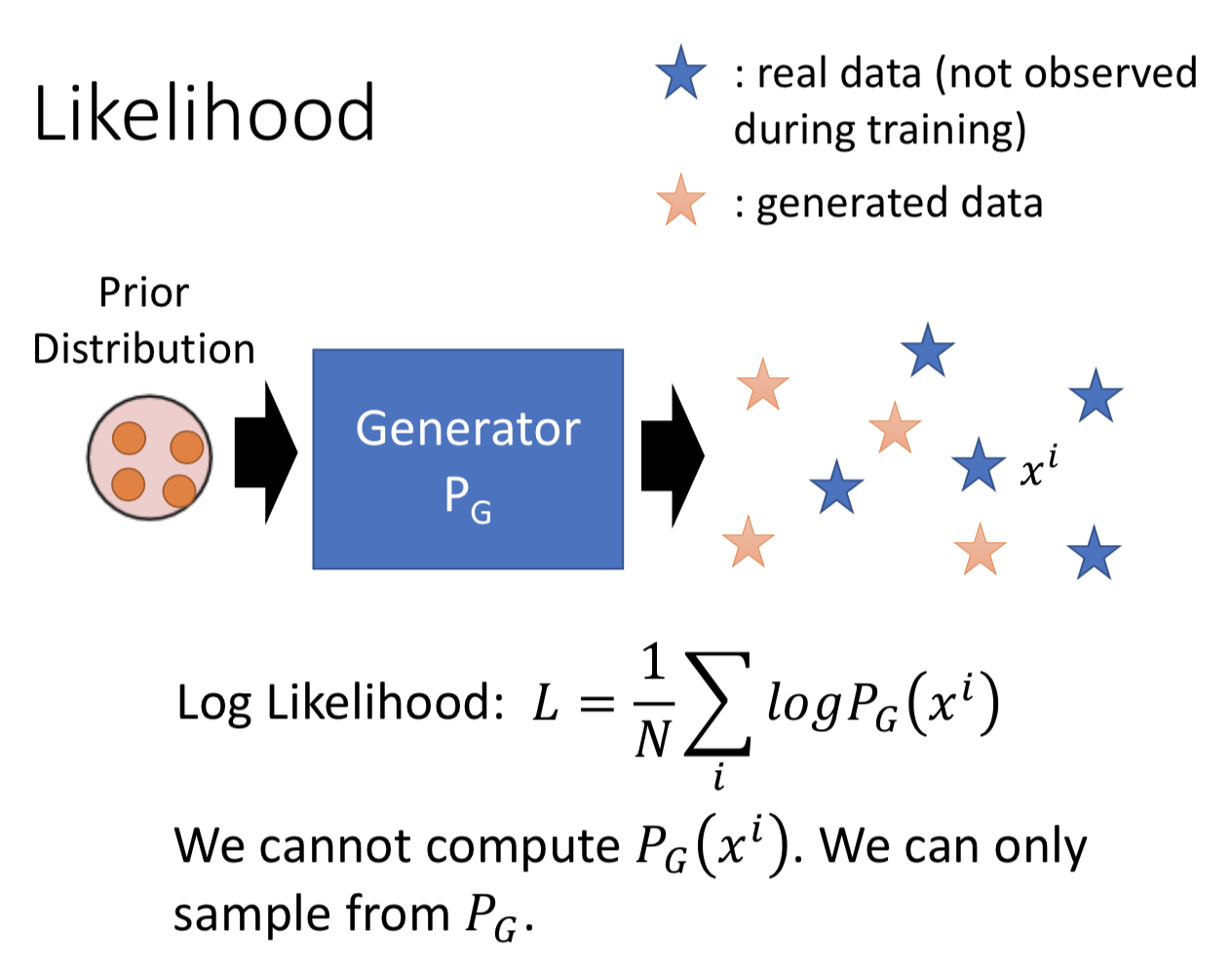
一个方法是把从 P_G 中采样得到的点当作是一个高斯分布的 mean,所有的 sample 都共享一样的 variance,然后就共同构成了 GMM 来估计 pdf ,然后就可以算 likelihood 了。困难是,要sample 几个点(要几个高斯)才估计的准?而且也不一定 likelihood 高,生成的质量就高。总之,这个方法问题还是很多的
比较客观的方法是,拿一个已经训练好的分类器来做判别

还需要从 diverse 的方向来衡量(避免发现不了 mode collapse 的问题),生成一组数据得到一组不同的 distributions,把它们平均起来。如果分布比较平均说明比较 diverse,不会太单一。
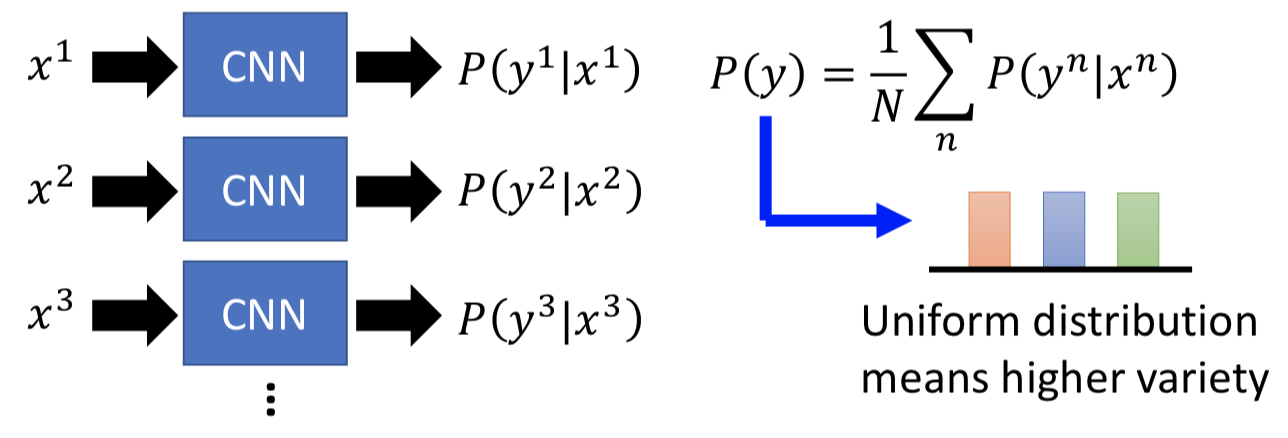
综合一下这两个原则,就得到了 inception score:把某个单一的生成数据喂给现成的分类器,属于某一类的概率越大越好;同时把所有的生成数据喂给现成的分类器,产生一堆 distribution 然后做平均,越平滑越好。

----想成为合格的算法工程师----

 浙公网安备 33010602011771号
浙公网安备 33010602011771号