GAN在seq2seq中的应用 Application to Sequence Generation
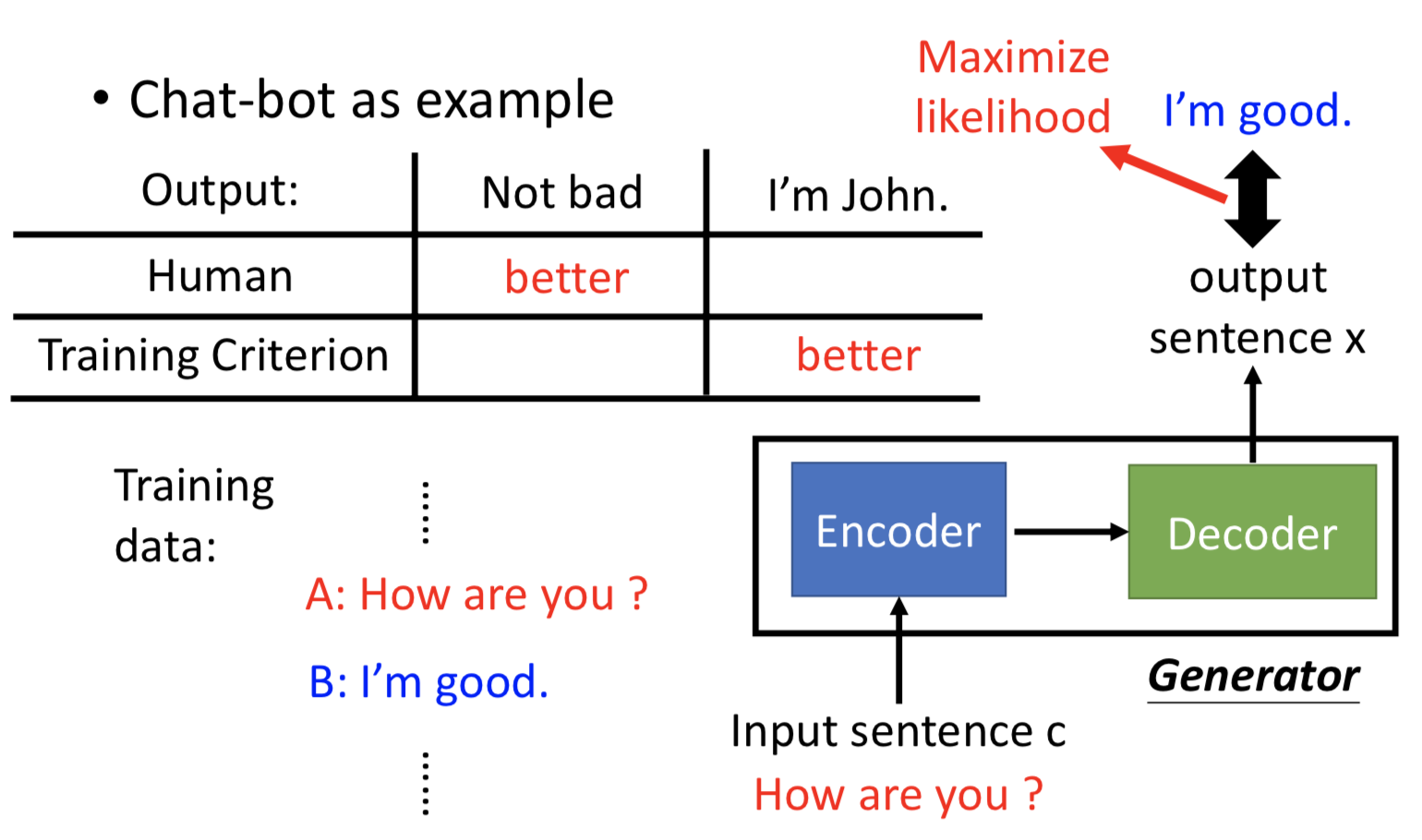
而 generator 其实就是典型的 seq2seq model ,可以把 GAN 应用到这个任务中。

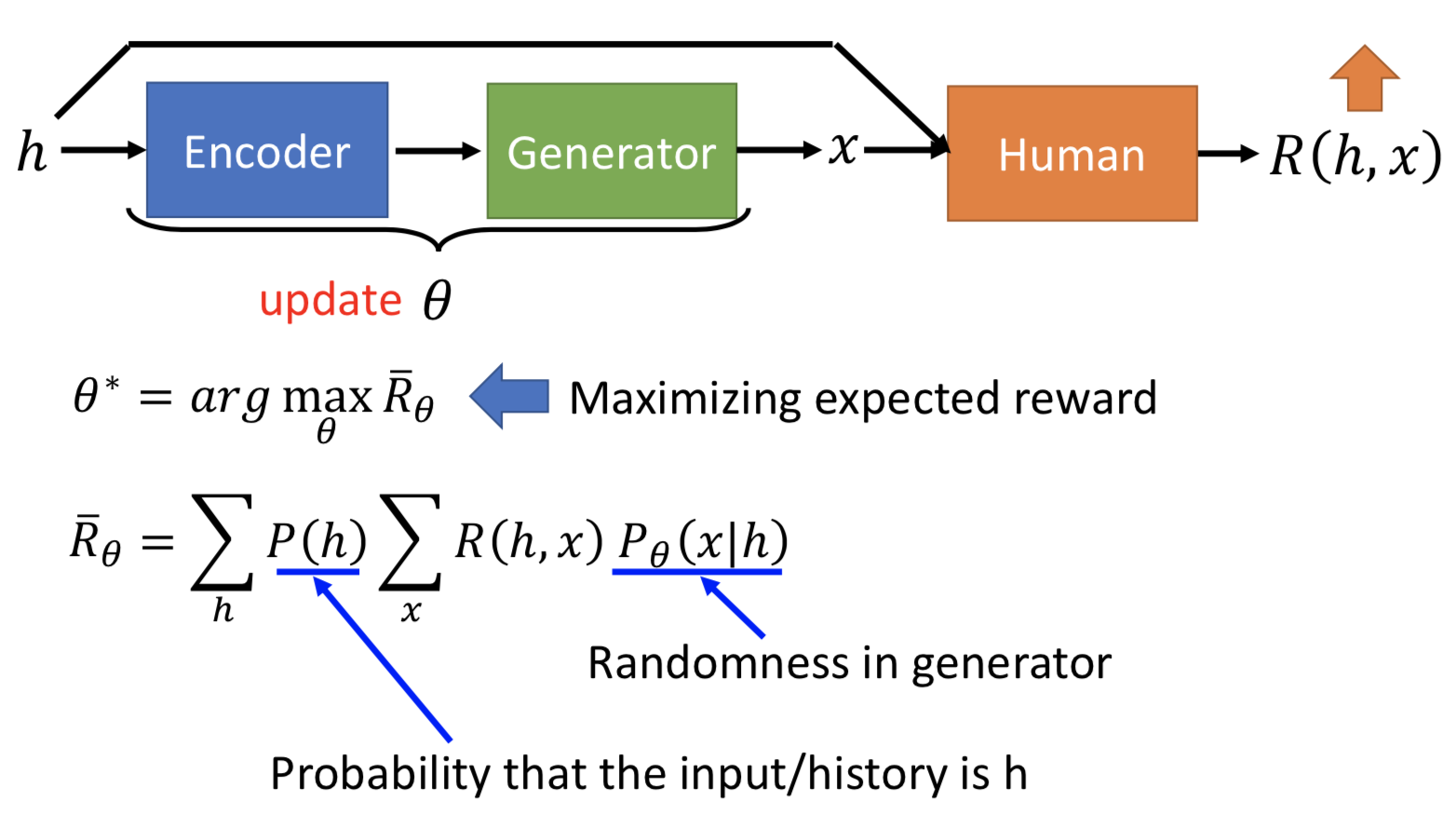
用 sampling 后求平均来近似求期望:

但是 R_θ 近似后并没有体现 θ(隐藏到 sampling 过程中去了),怎么算梯度?先对 P_θ (x | h) 求梯度,然后分子分母同乘 P_θ (x | h) ,而 grad(P_θ (x | h)) / P_θ (x | h) 就等于 grad(log P_θ (x | h)),所以就在 R_θ 原本的近似项上乘一个 grad(log P_θ (x | h))

如果是 positive 的 reward(R(hi, xi) > 0), 更新 θ 后 P_θ (xi | hi) 会增加;反之会减小(所以最好人类给的 reward 是有正有负的)
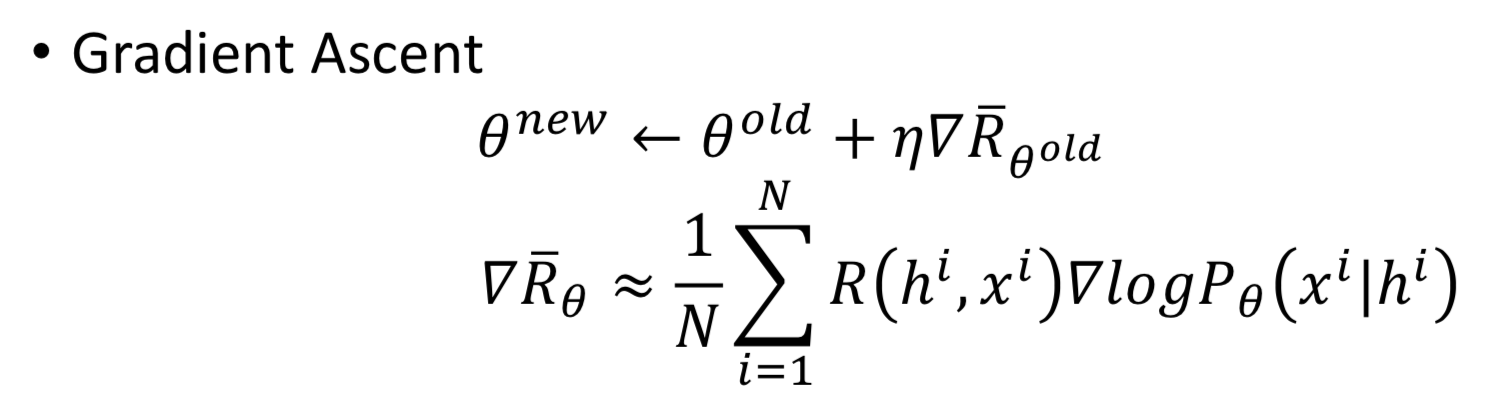
整个 implement 的过程就如下图所示,注意每次更新 θ 后,都要重新 sampling

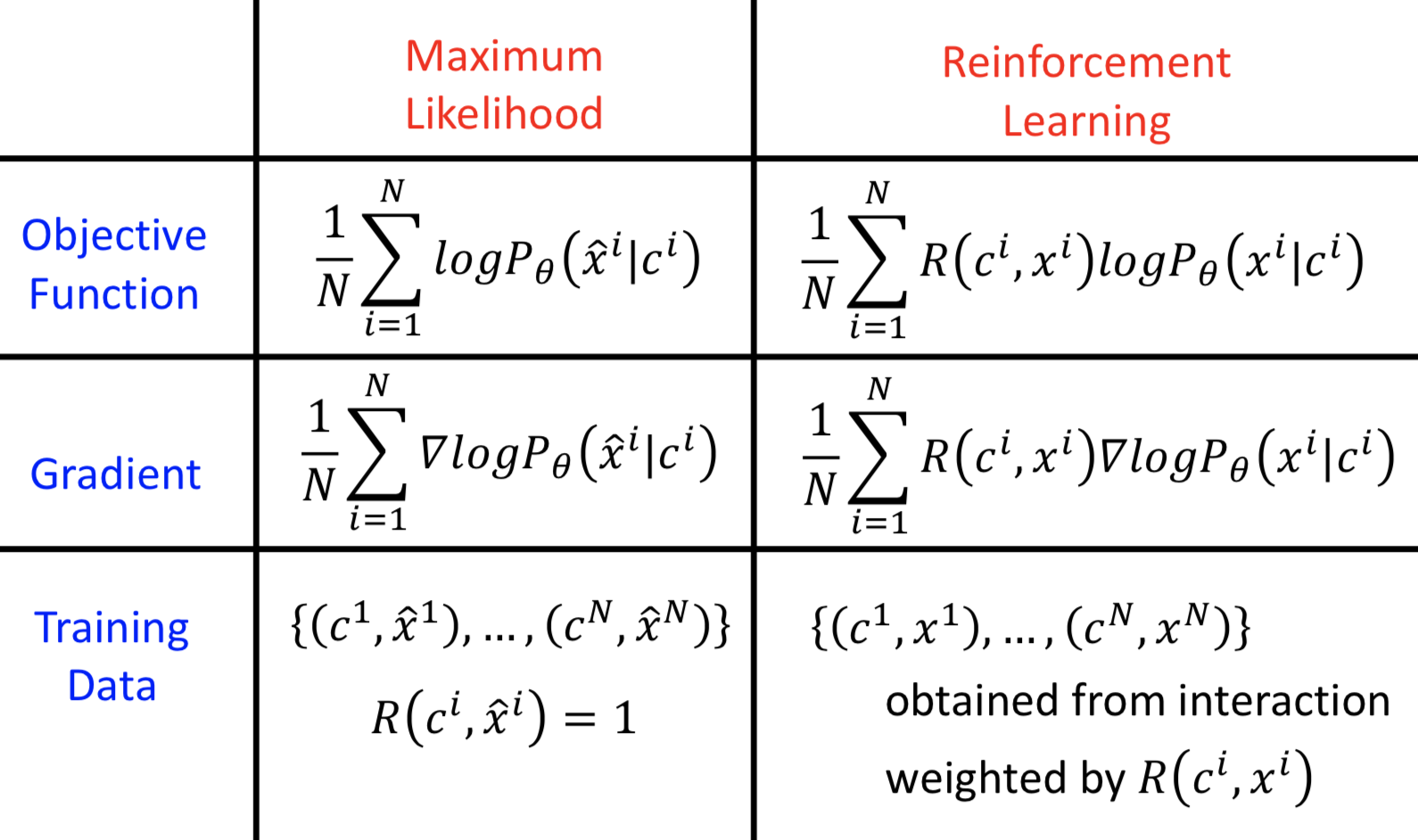
RL 的方法和之前所说的 seq2seq model (based on maximum likelihood)的区别

训练流程。训练 D 来分辨 <c, x> pair 到底是来自于 chatbot 还是人类的对话;训练 G 来使得固定的 D 给来自 chatbot 的 (c', x~) 高分。

仔细想一下,训练 G 的过程中是存在问题的,因为决定 LSTM 在每一个 time step 的 token 的时候实际上做了 sampling (或者取argmax),所以最后的 discriminator 的输出的梯度传不到 generator(不可微)。

怎么解决?
1. Gumbel-softmax https://casmls.github.io/general/2017/02/01/GumbelSoftmax.html
首先需要可以采样,使得离散的概率分布有意义而不是只能取 argmax。对于 n 维概率向量 π,其对应的离散随机变量 xπ 添加 Gumbel 噪声再采样。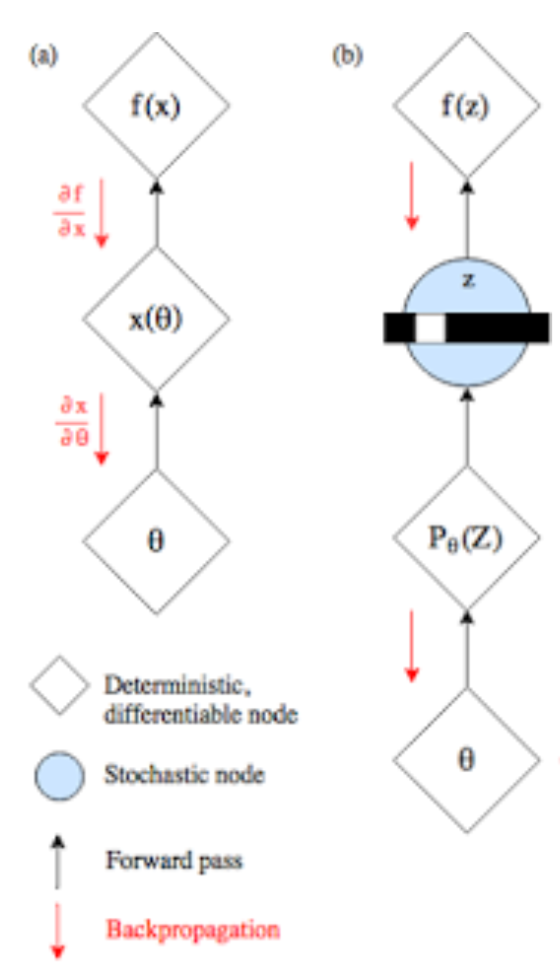

2. Continuous Input for Discriminator
避免 sampling 过程,直接把每一个 time step 的 word distribution 当作 discriminator 的输入。
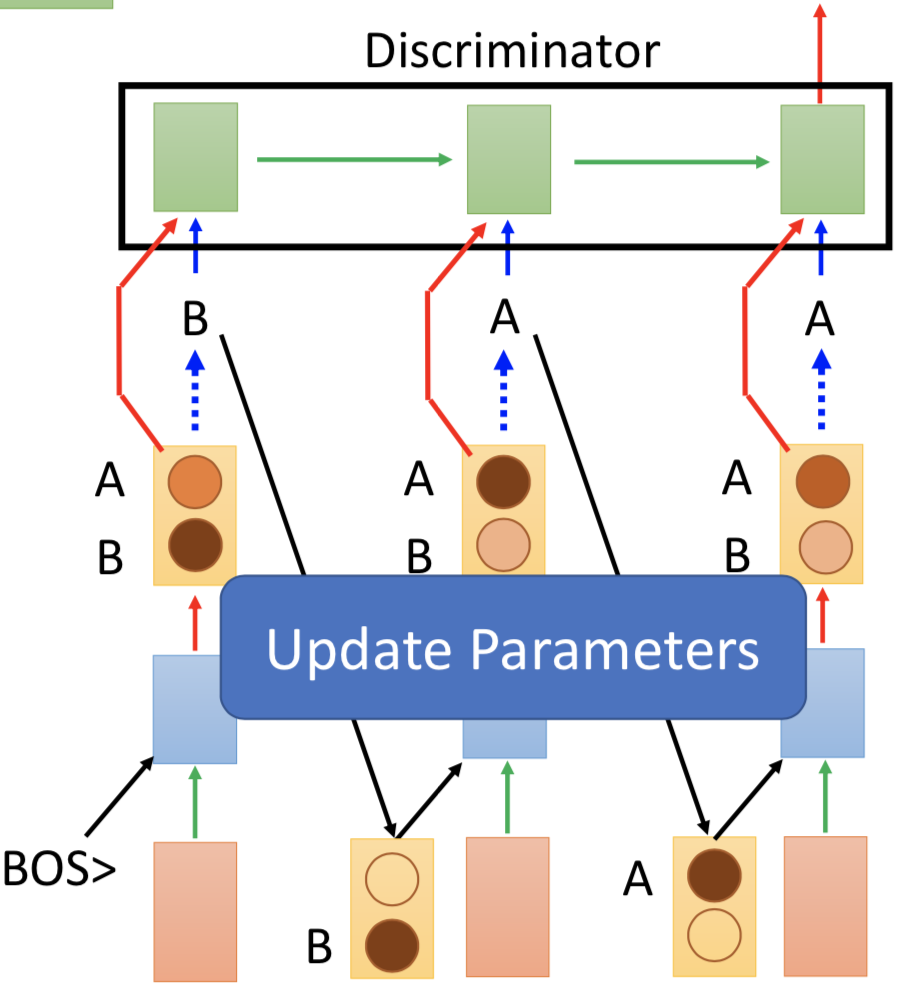
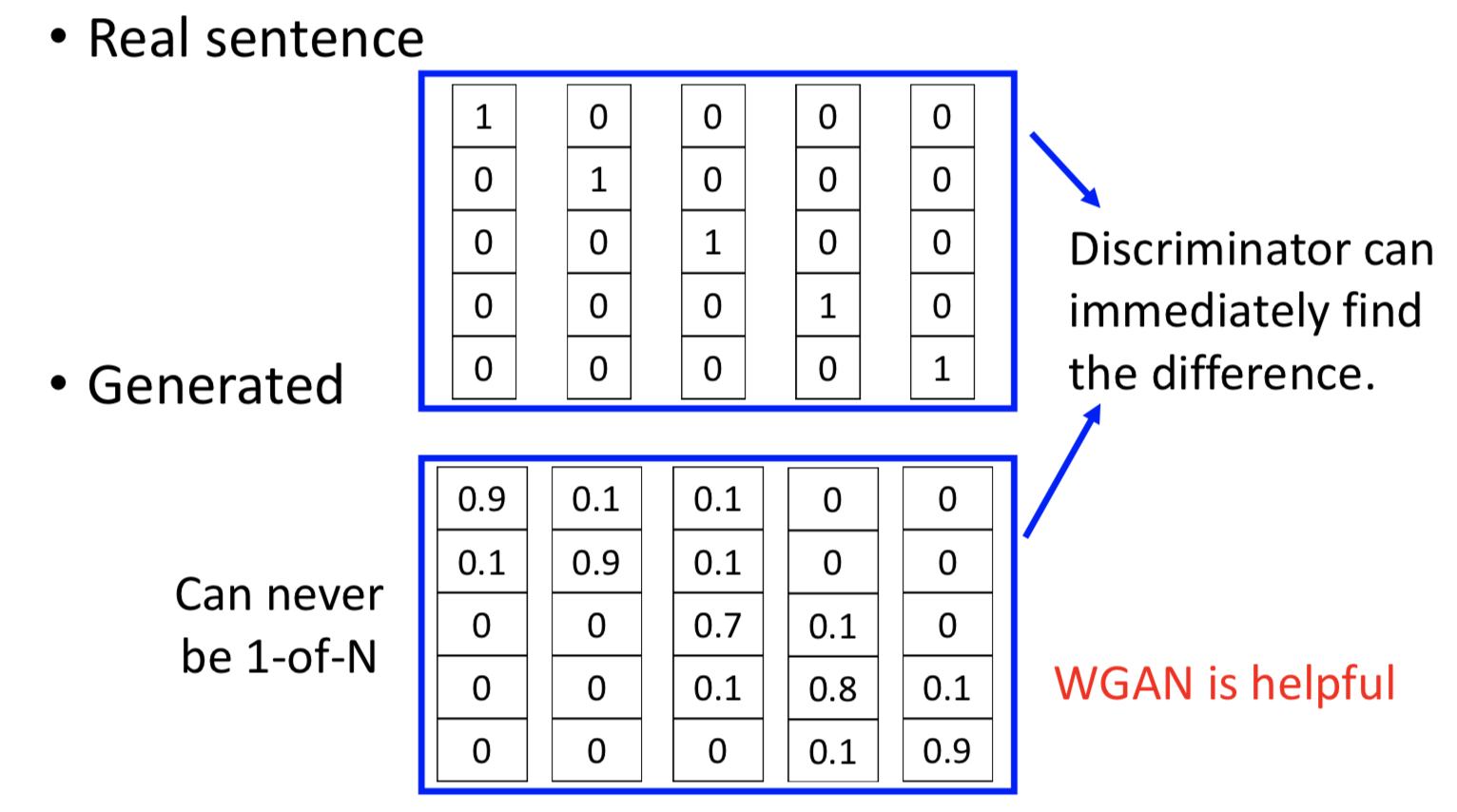
这样做有问题吗?明显有,real sentence 的 word distribution 就是每个词 one-hot 的,而 generated sentence 的 word distribution 本质上就不会是 1-of-N,这样 discriminator 很容易就能分辨了,而且判断准则没有在考虑语义了(直接看是不是 one-hot 就行了)。
3. Reinforcement Learning

把 discriminator 的 output 看作是 reward:
• Update generator to increase discriminator = to get maximum reward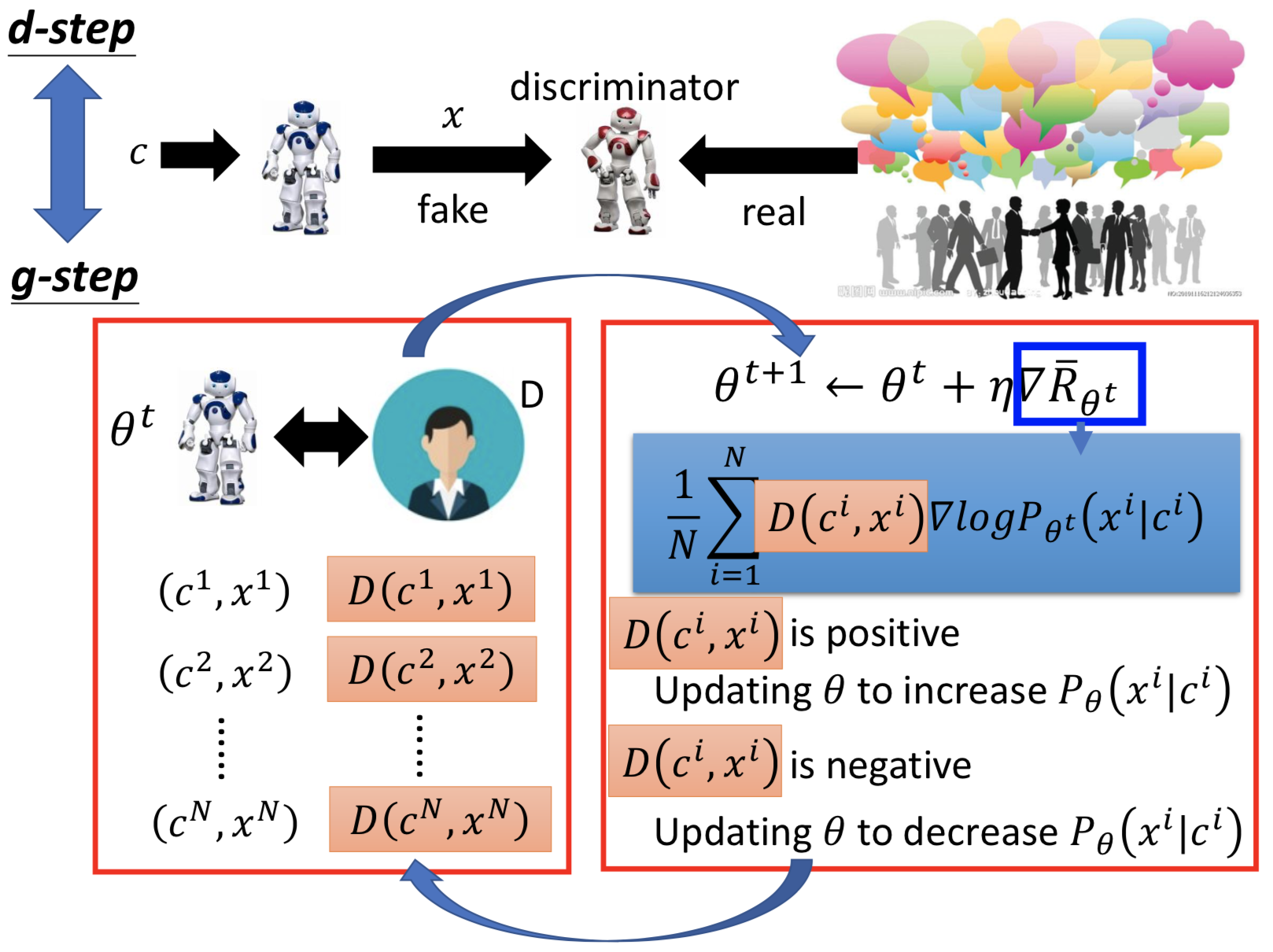
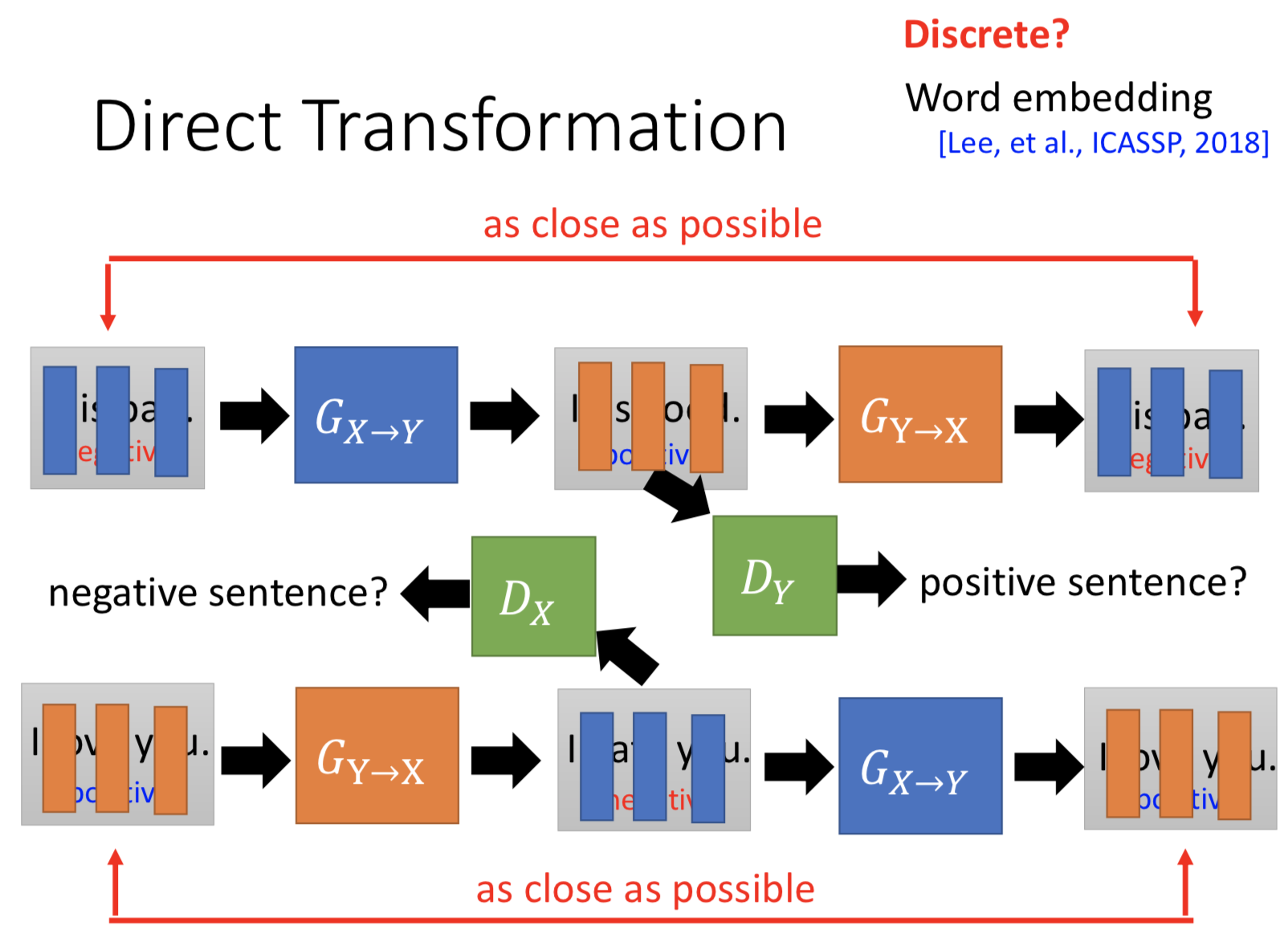
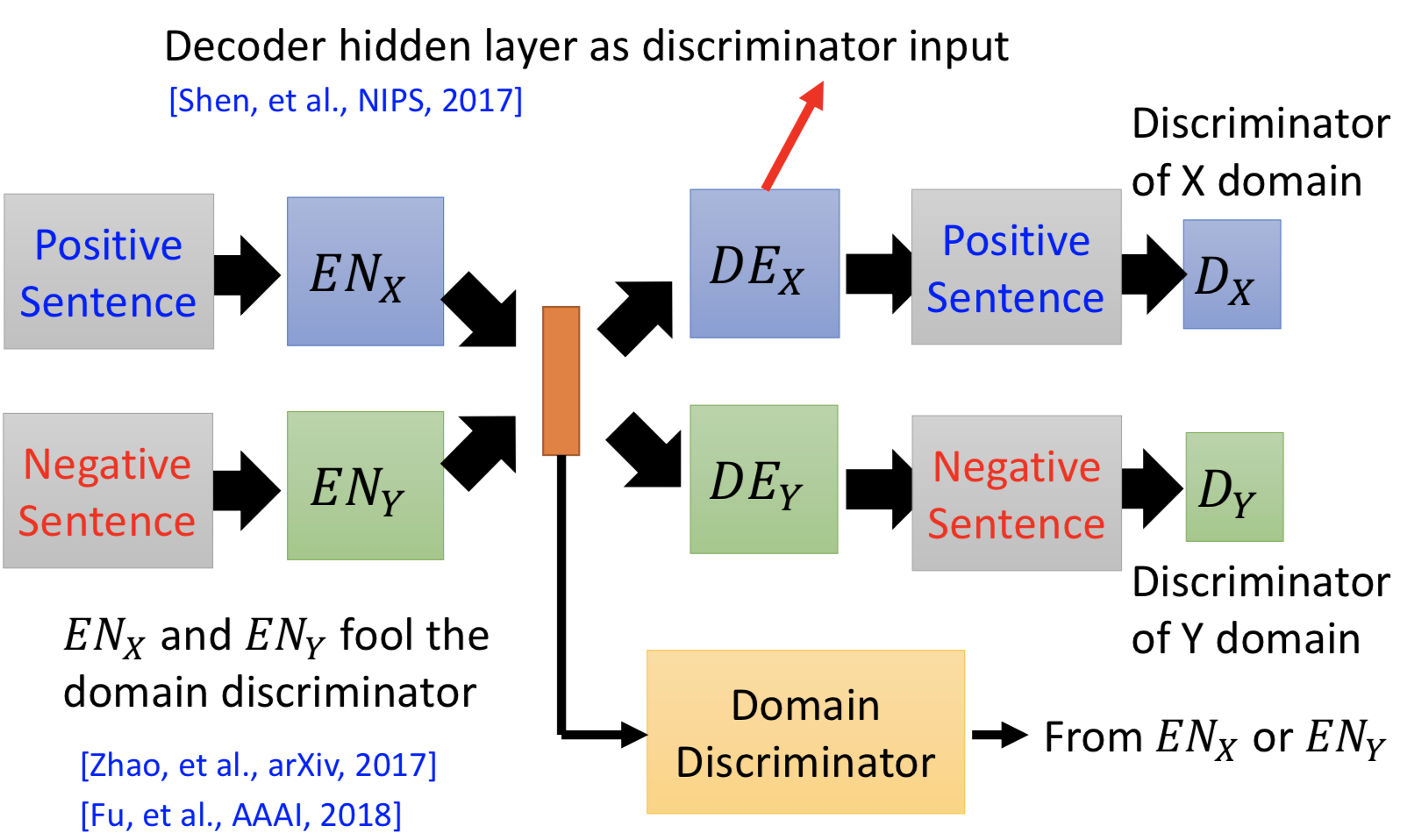
也可以用映射到 common space 的方法,sampling 后离散化的问题,可以用一个新的技巧解决:把 decoder LSTM 的 hidden layer 当作 discriminator 的输入,就是连续的了。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号