YOLOv2
引用:
https:- //zhuanlan.zhihu.com/p/35325884
- https://blog.csdn.net/qq_40716944/article/details/114822515

1.1 Batch Normalization
- 在YOLOv2中,每个卷积层后面都添加了Batch Normalization层,并且不再使用droput。使用Batch Normalization后,YOLOv2的mAP提升了2.4%。
1.2 High Resolution Classifier(finetune微调)
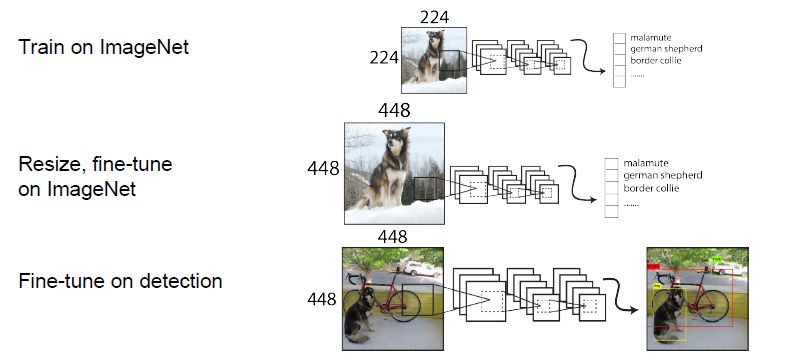
- 先使用224*224图像YOLOv2增加了在ImageNet数据集上使用 448大小图片输入来finetune分类网络这一中间过程(10 epochs),这可以使得模型在检测数据集上finetune之前已经适用高分辨率输入。即224大小图片训练分类网络->448大小图像训练分类部分网络->448大小图像训练检测网络。使用高分辨率分类器后,YOLOv2的mAP提升了约4%。
1.3 anchor boxes(预设置anchor,相对比v1可以有更多预测框)
- YOLOv1包含有全连接层,从而能直接预测Bounding Boxes的坐标值(由于对BB没有限制,会导致预测框在图里乱飘,难以回归)。YOLOv2借鉴Faster RCNN的做法,YOLOv2也尝试采用先验框(anchor)。在每个grid预先设定一组不同大小和宽高比的边框,来覆盖整个图像的不同位置和多种尺度,这些先验框作为预定义的候选区在神经网络中将检测其中是否存在对象,以及微调边框的位置。
- YOLOv1并没有采用先验框,并且每个grid只预测两个bounding box(中共最多772=98个框,导致可以预测的框很少,密集目标,小目标效果都不是很好),也就是整个图像只有98个bounding box。YOLOv2如果每个grid采用9个先验框,总共有13139=1521个先验框。
1.4 Dimension clusters(对框使用k-means,使用iou为衡量标准)
- 相对于ssd和faster rcnn,不再使用手动预先设置参数。YOLOv2的做法是对训练集中标注的边框进行K-means聚类分析,以寻找尽可能匹配样本的边框尺寸。如果用标准的欧式距离的k-means,尺寸大的框比小框产生更多的错误。因为我们的目的是提高IOU分数,这依赖于Box的大小,所以距离度量的使用:
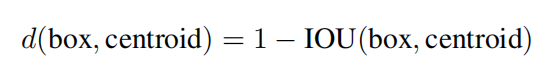
1.5 Direct location prediction (预测框位置限制)
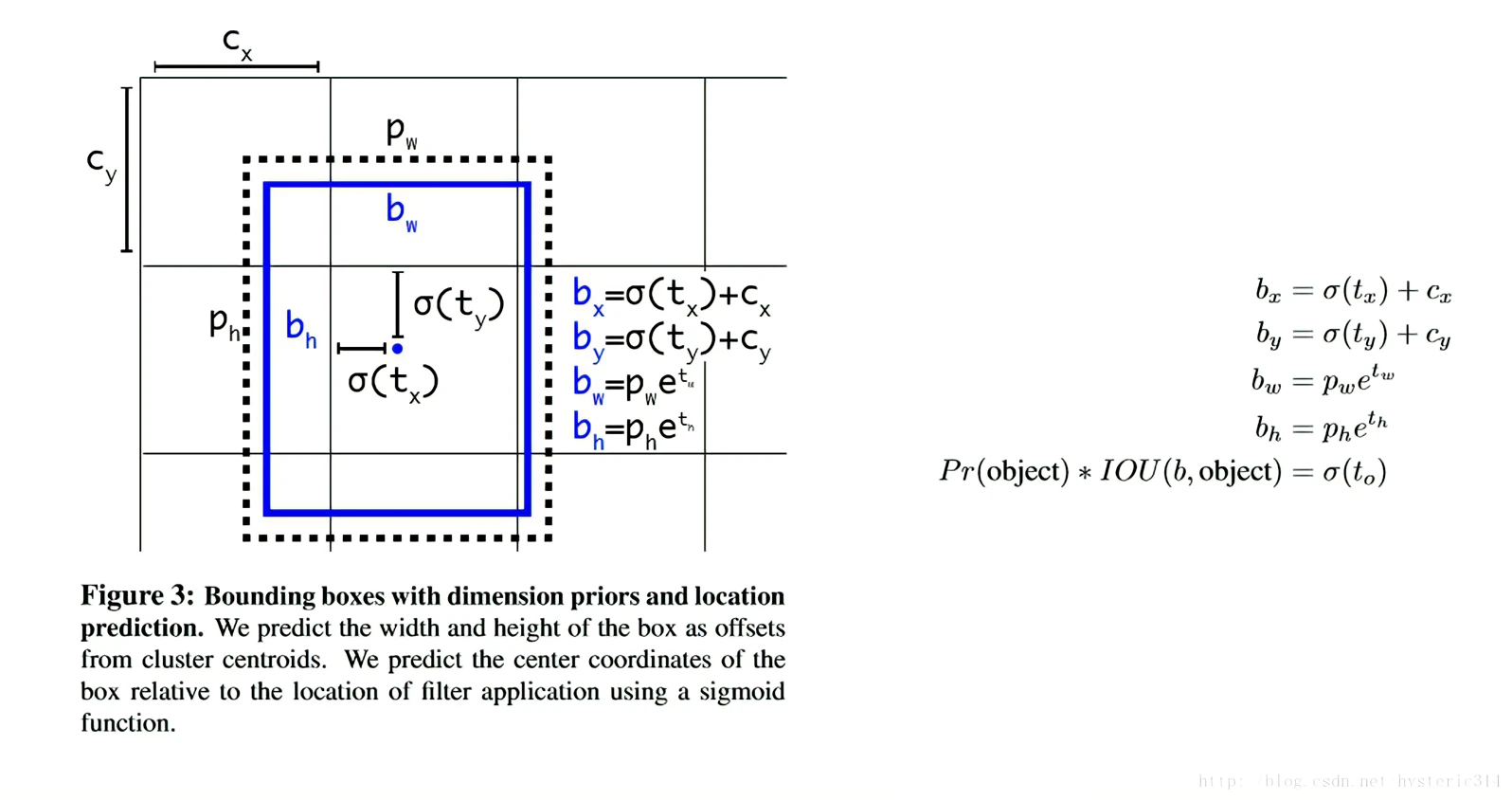
- 按照之前YOLOv1的方法,网络不会预测偏移量,而是根据YOLOv1中的网格单元的位置来直接预测坐标,这就让Ground Truth的值介于0到1之间。而为了让网络的结果能落在这一范围内,网络使用一个 Logistic Activation来对于网络预测结果进行限制,让结果介于0到1之间。 网络在每一个网格单元中预测出5个Bounding Boxes,每个Bounding Boxes有五个坐标值tx,ty,tw,th,t0,他们的关系见下图。假设一个网格单元对于图片左上角的偏移量是cx,cy,Bounding Boxes Prior的宽度和高度是pw,ph,那么预测的结果见下图右面的公式:
1.6 Fine-Grained Features
- YOLOv2引入一种称为passthrough层的方法在特征图中保留一些细节信息。具体来说,就是在最后一个pooling之前,特征图的大小是2626512,将其1拆4,直接传递(passthrough)到pooling后(并且又经过一组卷积)的特征图,两者叠加到一起作为输出的特征图。

具体怎样将1个特征图拆成4个特征图,见下图,图中示例的是1个44拆成4个22,因为深度不变,所以没有画出来。

1.7 多尺度训练策略
- YOLOv2每迭代几次都会改变网络参数。每10个Batch,网络会随机地选择一个新的图片尺寸,由于使用了下采样参数是32,所以不同的尺寸大小也选择为32的倍数{320,352…..608},最小320320,最大608608,网络会自动改变尺寸,并继续训练的过程。这一政策让网络在不同的输入尺寸上都能达到一个很好的预测效果,同一网络能在不同分辨率上进行检测。当输入图片尺寸比较小的时候跑的比较快,输入图片尺寸比较大的时候精度高.
1.8 损失函数
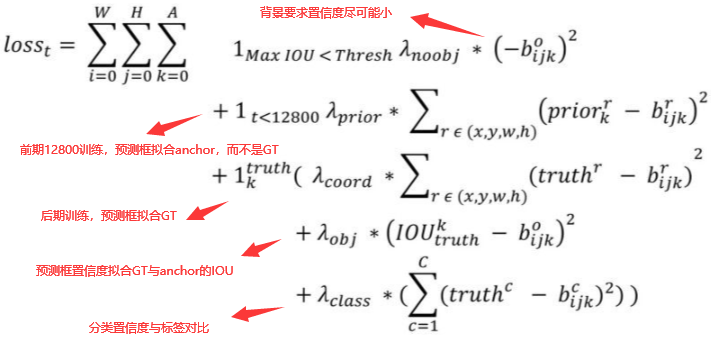
- 第一项loss是计算background的置信度误差,但是哪些预测框来预测背景呢,需要先计算各个预测框和所有ground truth的IOU值,并且取最大值Max_IOU,如果该值小于一定的阈值(YOLOv2使用的是0.6),那么这个预测框就标记为background,需要计算noobj的置信度误差。
- 第二项是计算先验框与预测宽的坐标误差,但是只在前12800个iterations间计算,我觉得这项应该是在训练前期使预测框快速学习到先验框的形
状。 - 第三大项计算与某个ground truth匹配的预测框各部分loss值,包括坐标误差、置信度误差以及分类误差。
- 匹配原则
对于某个ground truth,首先要确定其中心点要落在哪个cell上,然后计算这个cell的5个先验框与ground truth的IOU值(YOLOv2中bias_match=1),计算IOU值时不考虑坐标,只考虑形状,所以先将先验框与ground truth的中心点都偏移到同一位置(原点),然后计算出对应的IOU值,IOU值最大的那个先验框与ground truth匹配,对应的预测框用来预测这个ground truth。
对于那些没有与ground truth匹配的先验框(与预测框对应),除去那些Max_IOU低于阈值的,其它的就全部忽略,不计算任何误差。这点在YOLOv3论文中也有相关说明:YOLO中一个ground truth只会与一个先验框匹配(IOU值最好的),对于那些IOU值超过一定阈值的先验框,其预测结果就忽略了。这和SSD与RPN网络的处理方式有很大不同,因为它们可以将一个ground truth分配给多个先验框。
在计算boxes的 W 和 H 误差时,YOLOv1中采用的是平方根以降低boxes的大小对误差的影响,而YOLOv2是直接计算,但是根据ground truth的大小对权重系数进行修正:l.coord_scale(2-truth.wtruth.h)(这里w和h都归一化到(0,1)),这样对于尺度较小的boxes其权重系数会更大一些,可以放大误差,起到和YOLOv1计算平方根相似的效果(参考YOLO v2 损失函数源码分析)。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号