
用 puppeteer 模拟人工实现网盘链接批量转存
需求分析
别人分享了很多网盘链接,自己每个手动去转存很浪费时间,而且,这些操作都是重复性劳动。与Pandownload的这个功能类似,不过pandownload由于一些原因无法使用了,所以只能自己实现。
思路
思路其实很简单,就是完全模拟人为操作,将网盘链接存起来。我们可以把网盘链接分为两种,第一种是没有提取码的,第二种是有提取码的。前者比后者少一个提交提取码的步骤。那么,我们
如何区分,访问一个网盘链接的时候,究竟是哪种呢?
可以通过访问页面的title来决定。
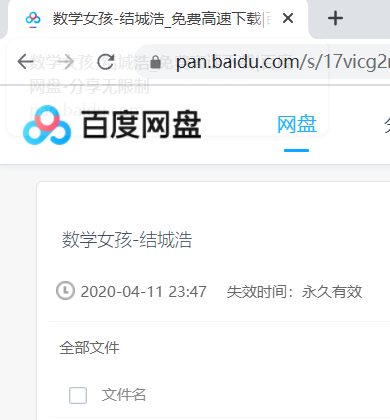
这种是无提取码的,后缀是无限制
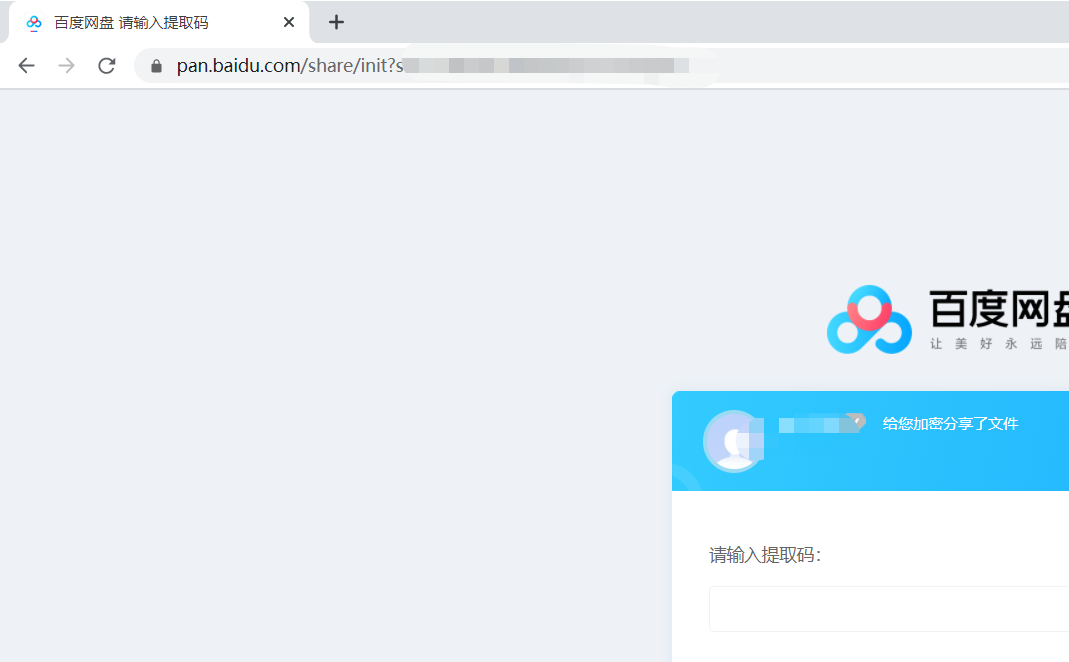
这种是需要填写提取码的,后缀是请输入提取码,写代码的时候,截取后三个字儿提取码即可
填写Cookie信息
批量转存的前提是,我们得登录,我这里实现的方案是直接从浏览器中获取到cookie信息,复制到代码中进行使用,查看网站的cookie信息可以用插件EditThisCookie
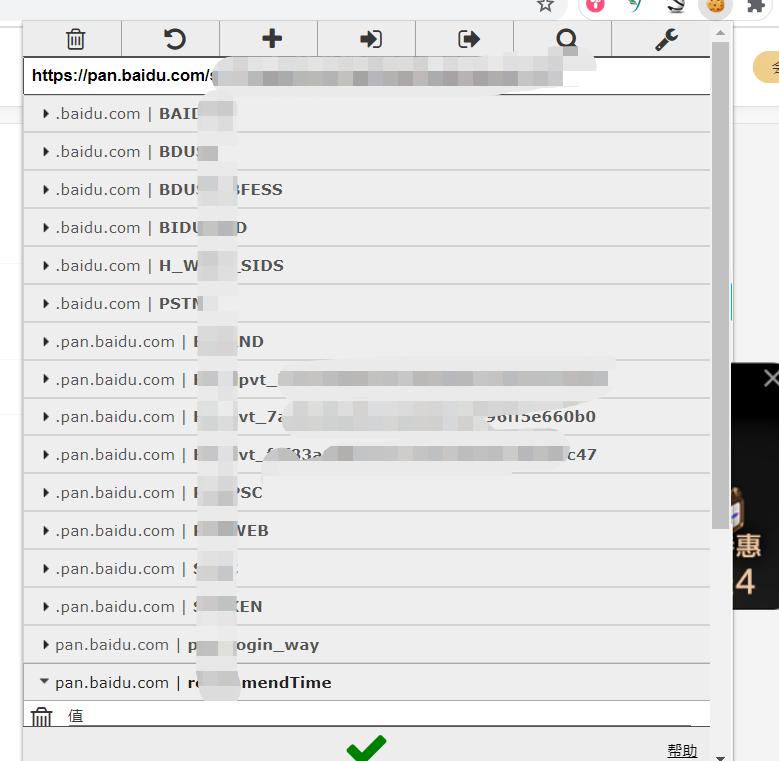
点击右上角导出Cookie,cookie就放在粘贴板中了,复制到代码中,然后使用循环,将所有cookie利用page.setCookie方法,将cookie放置到当前请求上下文中
填写提取码
等待页面加载完毕,找到输入提取码框的元素,找到其id,然后使用page.$$eval()方法获取并写入东西
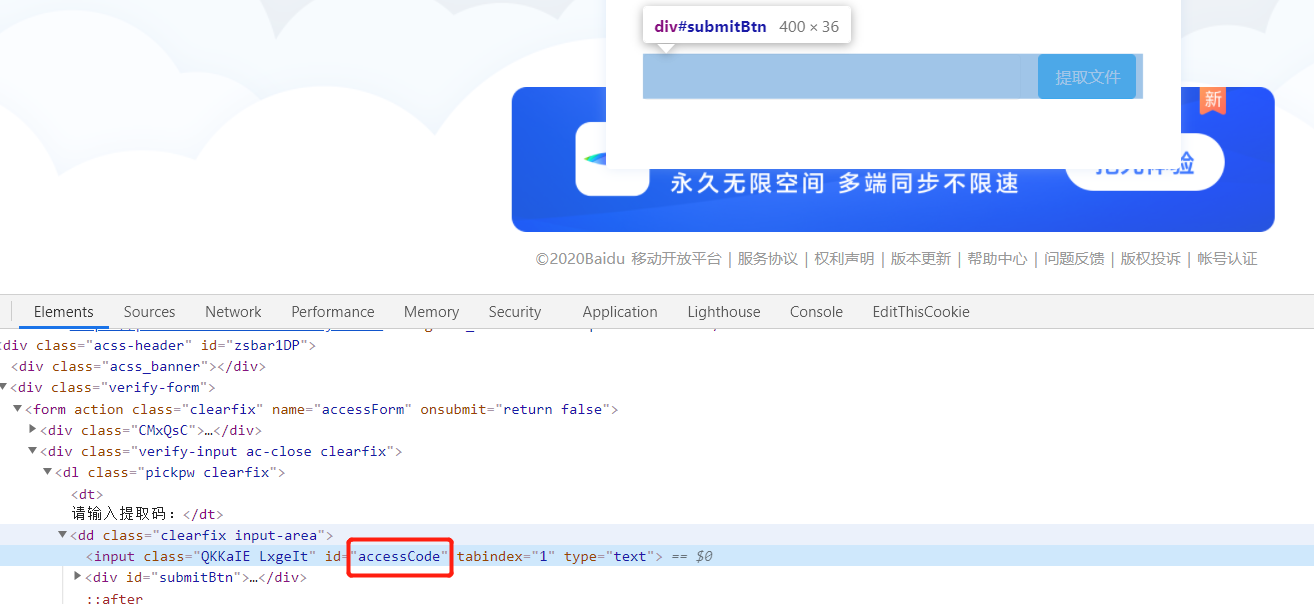
可以看见,这里的id为accessCode。所以我们只需要写
await page.$$eval('#accessCode', writeCode, code);
async function writeCode(nodes, code) {
for (let node of nodes) {
node.value = code;
}
}
就可以了。我这里是直接改的node.value,你也可以用puppeteer模拟人来填写。
提取文件
找到提取文件按钮,点击,然后等待跳转完毕。
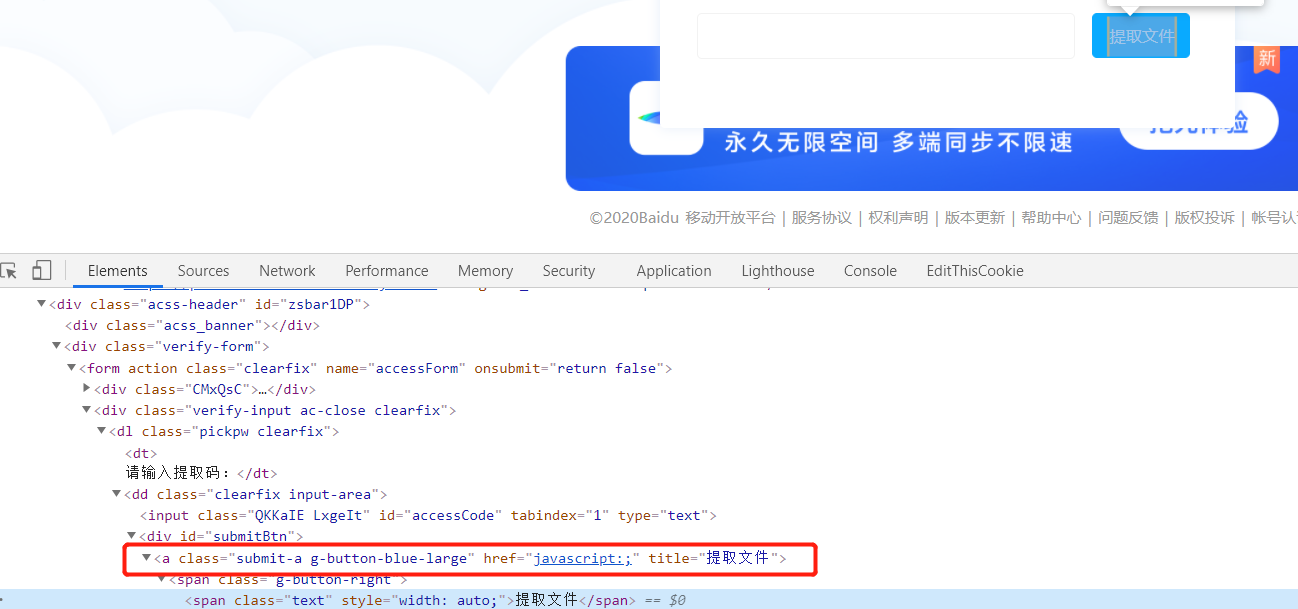
值得注意的是,我们点击的一定是A标签,其他标签需要进行过滤。
await page.$$eval('.g-button-blue-large', click);
await page.waitFor(1000);
async function click(nodes) {
for (let node of nodes) {
if (node.title === '提取文件') {
await node.click();
}
}
}
然后等待跳转即可
选择要保存的文件
这里简单实现为,选择全部文件,不过值得注意的是,如果是单文件,是不需要点击选择全部文件的。可以通过判断元素是否存在判断是否有复选框,是否需要进行点击
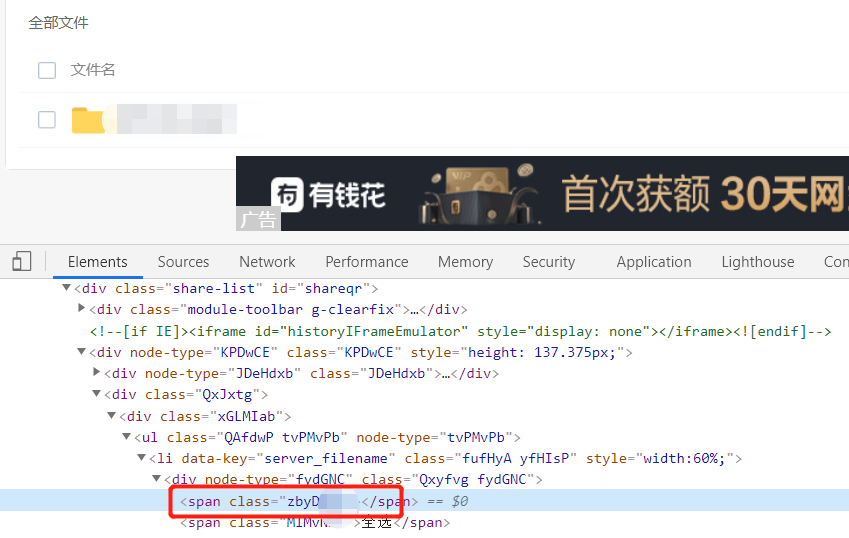
如图,不过这里奇怪的是,class的值是一个不可读的字符串,我不确定这个值是不是与用户有关,所以这里就打码了。
既然需要做的就是找到这个元素,点击就行了,那我们照着做就行
await page.$$eval('.zbyDdwb', selectAll);
async function selectAll(nodes) {
for (let node of nodes) {
await node.click();
break;
}
}
点击保存到网盘
与点击提取文件一样,找到目表按钮,然后点击就行,感兴趣的朋友,可以自己试试
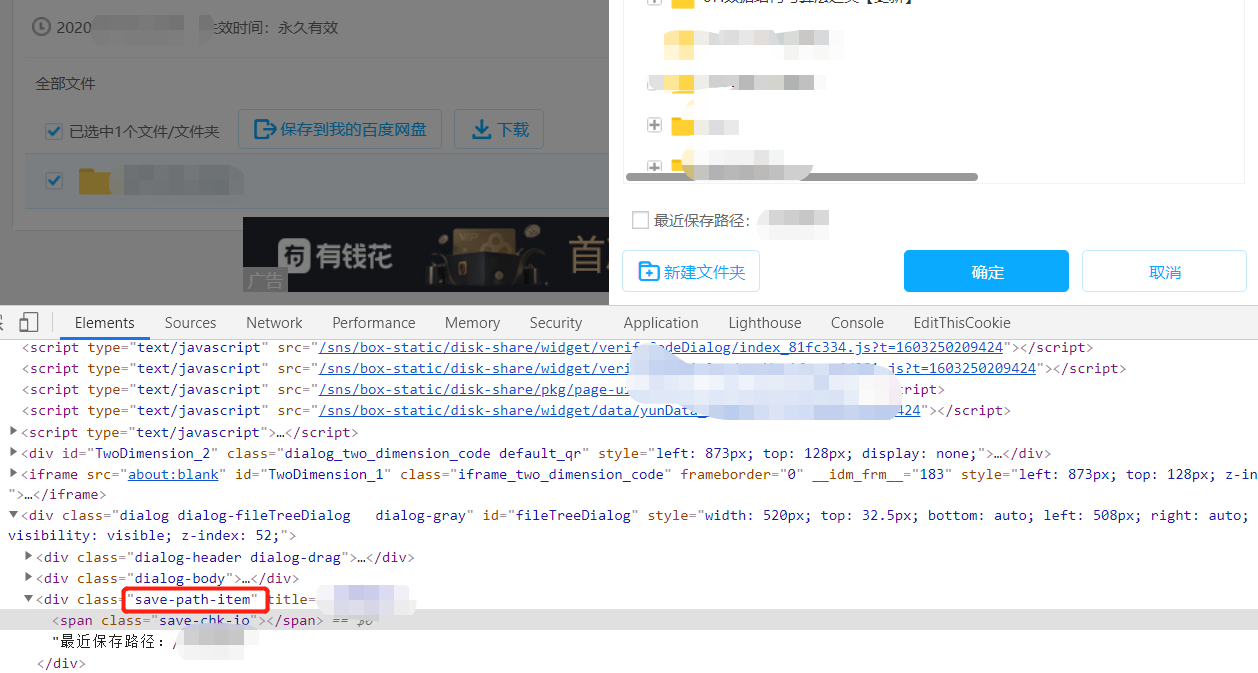
弹出框选择保存的文件路径
避免麻烦,这里写得比较简单,如果有选择跟上一次样的框,那么就点击选择跟上一次一样,如果没有,就直接存储在根目录下。(可以根据你想要的需求自己改)
选择前
选择后
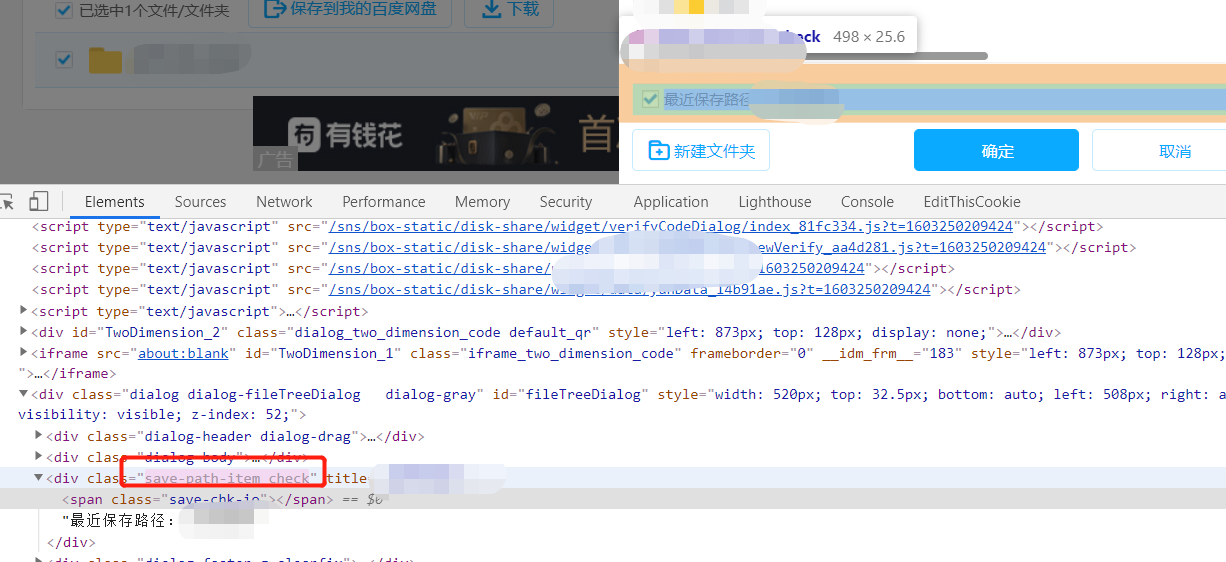
可以发现,仅仅是改变了Class的值,所以实现的时候,也改变一下值就行
await page.$$eval('.save-path-item', chooseLocation);
async function chooseLocation(nodes) {
for (let node of nodes) {
node.setAttribute('class', 'save-path-item check');
}
}
点击确定按钮
与之前几个按钮一样,我们只需要找到确认按钮,点击就行了。
await page.$$eval('[title=确定]', confirm)
async function confirm(nodes) {
for (let node of nodes) {
console.log(node.tagName);
if (node.tagName === 'A') {
await node.click();
}
}
}
这样,整个逻辑就完成了。
完整代码
为了程序能正常运行,需要加入一些额外的waitFor等待,避免操作太快导致的诸如IP封禁,元素未加载出来等乱七八糟的问题。同时,我这里数据都是从数据库中出来的,所以里面有与更新数据库状态的代码。
const Pan = require('../model/Pan');
const {Cluster} = require('puppeteer-cluster');
const crawler = require('./crawler');
const cookies = [];
async function selectAll(nodes) {
console.log('selectAll',nodes.length);
for (let node of nodes) {
await node.click();
break;
}
}
async function click(nodes) {
console.log('click',nodes.length);
for (let node of nodes) {
if (node.title === '提取文件') {
await node.click();
}
}
}
async function writeCode(nodes, code) {
console.log('writeCode',nodes.length);
for (let node of nodes) {
node.value = code;
}
}
async function confirm(nodes) {
console.log(nodes.length);
for (let node of nodes) {
console.log(node.tagName);
if (node.tagName === 'A') {
await node.click();
}
}
}
async function clickSave(nodes) {
for (let node of nodes) {
if (node.tagName === 'A') {
await node.click();
break;
}
}
}
async function chooseLocation(nodes) {
for (let node of nodes) {
node.setAttribute('class', 'save-path-item check');
}
}
async function saveBaidu() {
const cluster = await Cluster.launch(crawler.clusterLanuchOptionsPan);
await cluster.task(async ({page, data}) => {
let {id, url, code} = data;
for (let i = 0; i < cookies.length; i++) {
await page.setCookie(cookies[i]);
}
await page.goto(url);
await page.waitForSelector('html');
await page.content();
let title = await page.title();
let codeWrong = false;
let used = true;
let needCodeButNone = false;
if (title.indexOf('提取码') !== -1) {
// todo 填写提取码
if (code === '-' || code === '+') {
needCodeButNone = true;
} else {
await page.$$eval('#accessCode', writeCode, code);
await page.$$eval('.g-button-blue-large', click);
await page.waitFor(1000);
let content = await page.content();
if (content.indexOf('验证码错误') !== -1) {
used = false;
} else if (content.indexOf('提取码错误') !== -1) {
codeWrong = true;
used = false;
} else {
await page.waitFor(2000);
}
}
}
if (used && !needCodeButNone) {
title = await page.title();
await page.waitFor(1000);
console.log(title);
if (title.indexOf('不存在') !== -1) {
} else {
// todo 找到title=保存到网盘的a标签并点击
let x = await page.$$('.zbyDdwb');
console.log(x.length);
if (!(x === null || x===undefined || x.length === 0)){
await page.$$eval('.zbyDdwb', selectAll);
}
await page.$$eval('[title=保存到网盘]', clickSave);
await page.$$eval('.save-path-item', chooseLocation);
await page.waitFor(2000);
await page.$$eval('[title=确定]', confirm);
}
}
await Pan.update({
used: used,
code_wrong: codeWrong,
need_code: needCodeButNone
}, {
where: {
id: id
}
});
await page.waitFor(3000);
});
let pans = await Pan.findAll({
where: {
site_id:12,
reachable: true,
used:false,
code_wrong:false
}
});
console.log(pans.length);
for (let i = 0; i < pans.length; i++) {
if (pans[i].url.startsWith('http://pan.baidu') || pans[i].url.startsWith('https://pan.baidu')) {
await cluster.queue({
id: pans[i].id,
url: pans[i].url,
code: pans[i].code
});
}
}
await cluster.idle();
}
(async () => {
await saveBaidu();
})();
// crawler.clusterLanuchOptionsPan 是启动配置项,如下
const launchOptions = {
headless: true,
ignoreHTTPSErrors: true, // 忽略证书错误
waitUntil: 'networkidle2',
defaultViewport: {
width: 1920,
height: 1080
},
args: [
'--disable-gpu',
'--disable-dev-shm-usage',
'--disable-web-security',
'--disable-xss-auditor', // 关闭 XSS Auditor
'--no-zygote',
'--no-sandbox',
'--disable-setuid-sandbox',
'--allow-running-insecure-content', // 允许不安全内容
'--disable-webgl',
'--disable-popup-blocking',
//'--proxy-server=http://127.0.0.1:8080' // 配置代理
],
executablePath: 'C:\\Program Files (x86)\\Google\\Chrome\\Application\\chrome.exe',
};
const clusterLanuchOptionsPan = {
concurrency: Cluster.CONCURRENCY_PAGE, // 单Chrome多tab模式
maxConcurrency: 1, // 并发的workers数
retryLimit: 2, // 重试次数
skipDuplicateUrls: true, // 不爬重复的url
monitor: false, // 显示性能消耗
puppeteerOptions: launchOptions,
};
本文由博客群发一文多发等运营工具平台 OpenWrite 发布

