
第四次作业
作业①
1.东方财富网股票数据爬取实验
实验要求
熟练掌握 Selenium 查找 HTML 元素、爬取 Ajax 网页数据、等待 HTML 元素等内容。使用 Selenium 框架+ MySQL 数据库存储技术路线爬取“沪深 A 股”、“上证 A 股”、“深证 A 股”3 个板块的股票数据信息。
候选网站:东方财富网(http://quote.eastmoney.com/center/gridlist.html#hs_a_board)
输出信息:MYSQL 数据库存储,表头包含序号、股票代码、股票名称、最新报价、涨跌幅、涨跌额、成交量、成交额、振幅、最高、最低、今开、昨收等信息。
核心代码
本实验的核心在于使用 Selenium 模拟用户操作,实现自动切换“沪深 A 股”、“上证 A 股”、“深证 A 股”三个板块,并分页抓取表格数据。
我去网页找了板块的Xpath:
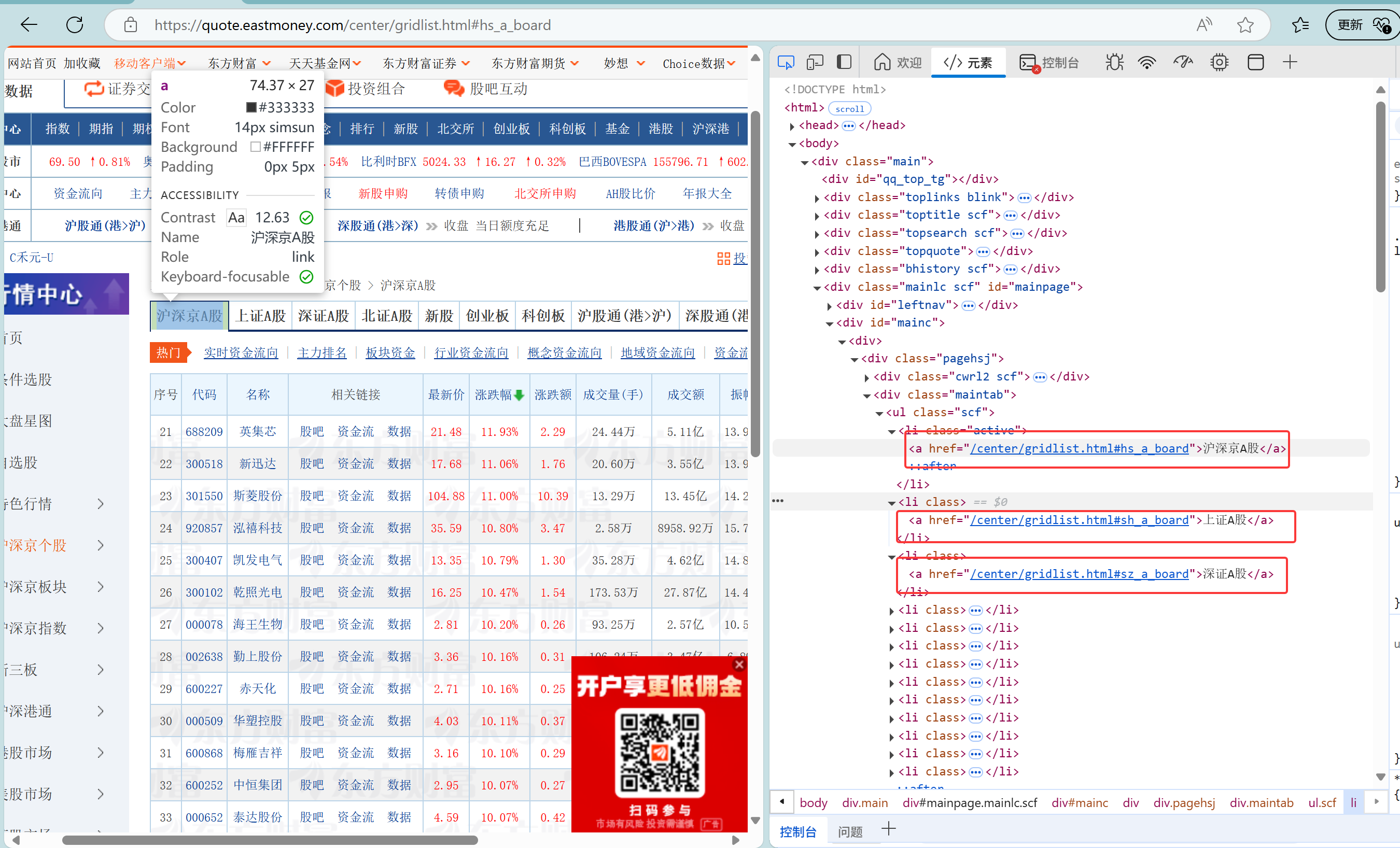
为了实现翻页功能,我又去找了按钮的Xpath
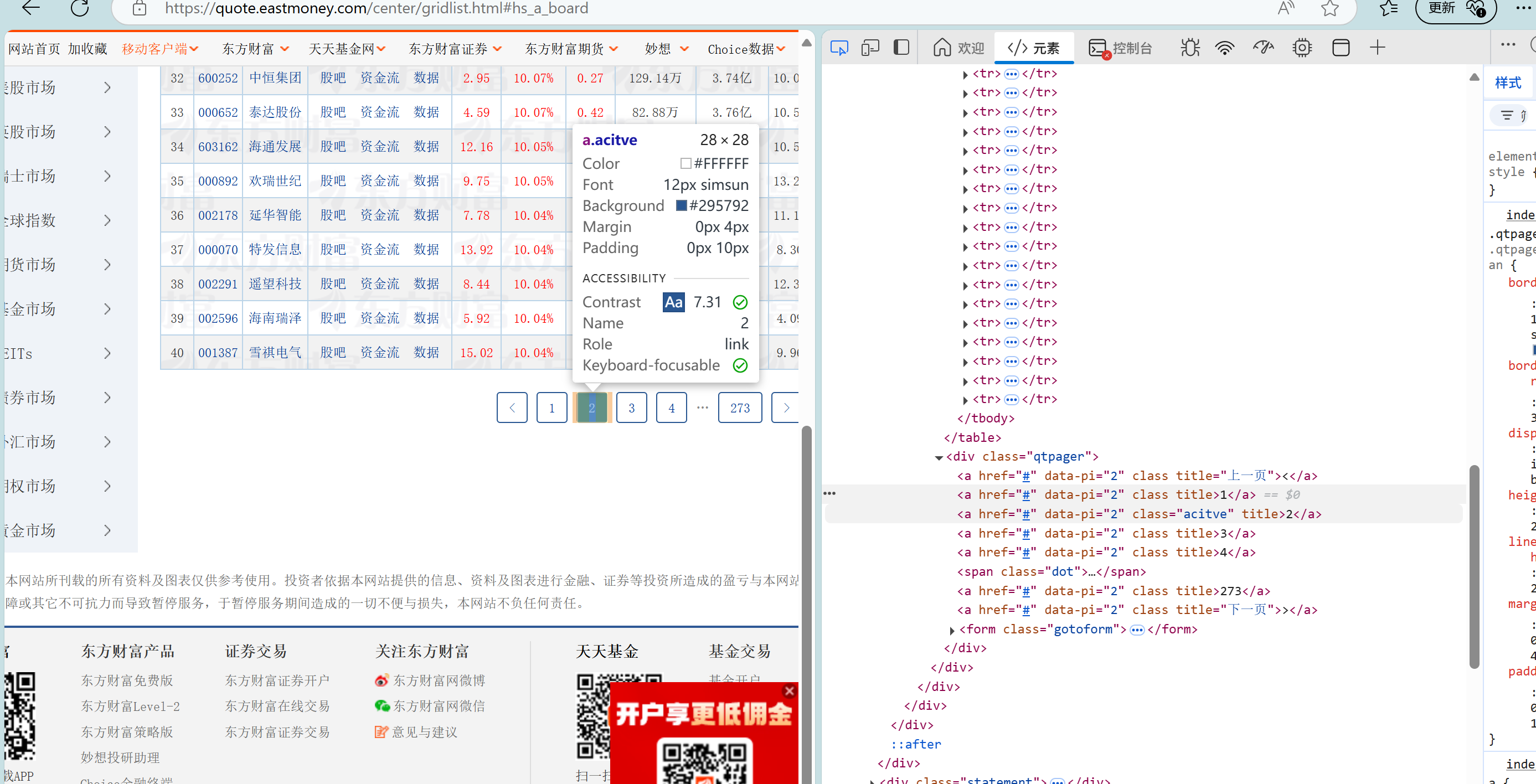
在寻找完Xpath后,我定义了三个板块与按钮的 XPath 列表,通过循环点击切换板块。在每个板块下,程序遍历前两页,解析表格行(tr)并提取单元格(td)文本,最后将清洗后的数据持久化存储。
from selenium import webdriver
from selenium.webdriver.common.by import By
import time
# 初始化浏览器
op = webdriver.ChromeOptions()
dr = webdriver.Chrome(options=op)
dr.get('[https://quote.eastmoney.com/center/gridlist.html#hs_a_board](https://quote.eastmoney.com/center/gridlist.html#hs_a_board)')
# 定义三个板块的XPath,用于循环切换
bs = [
'//*[@id="mainc"]/div/div/div[2]/ul/li[1]/a',
'//*[@id="mainc"]/div/div/div[2]/ul/li[2]/a',
'//*[@id="mainc"]/div/div/div[2]/ul/li[3]/a'
]
for b in bs:
# 模拟点击切换板块
btn = dr.find_element(By.XPATH, b)
dr.execute_script("arguments[0].click();", btn)
time.sleep(3) # 等待页面Ajax数据加载完成
for p in range(2): # 遍历爬取前2页数据
# 定位当前页表格中的所有行
rs = dr.find_elements(By.XPATH, '//*[@id="mainc"]/div/div/div[4]/table/tbody/tr')
for r in rs:
tds = r.find_elements(By.TAG_NAME, 'td')
if len(tds) < 14: continue # 跳过非数据行
# 提取页面数据
v1 = tds[1].text # 股票代码
v2 = tds[2].text # 股票名称
v3 = tds[4].text
# ... (提取最新报价、涨跌幅等其余10项数据)
v12 = tds[13].text # 昨收
# 执行SQL插入操作
sql = "insert into stocks (stock_code, stock_name, ...) values (%s, %s, ...)"
cur.execute(sql, (v1, v2, ... , v12))
# 翻页逻辑:点击“下一页”
if p < 1:
nxt = dr.find_element(By.XPATH, '/html/body/div[1]/div[7]/div[2]/div/div/div[4]/div/a[2]')
dr.execute_script("arguments[0].click();", nxt)
time.sleep(2)
此外,我在本机创建了数据库
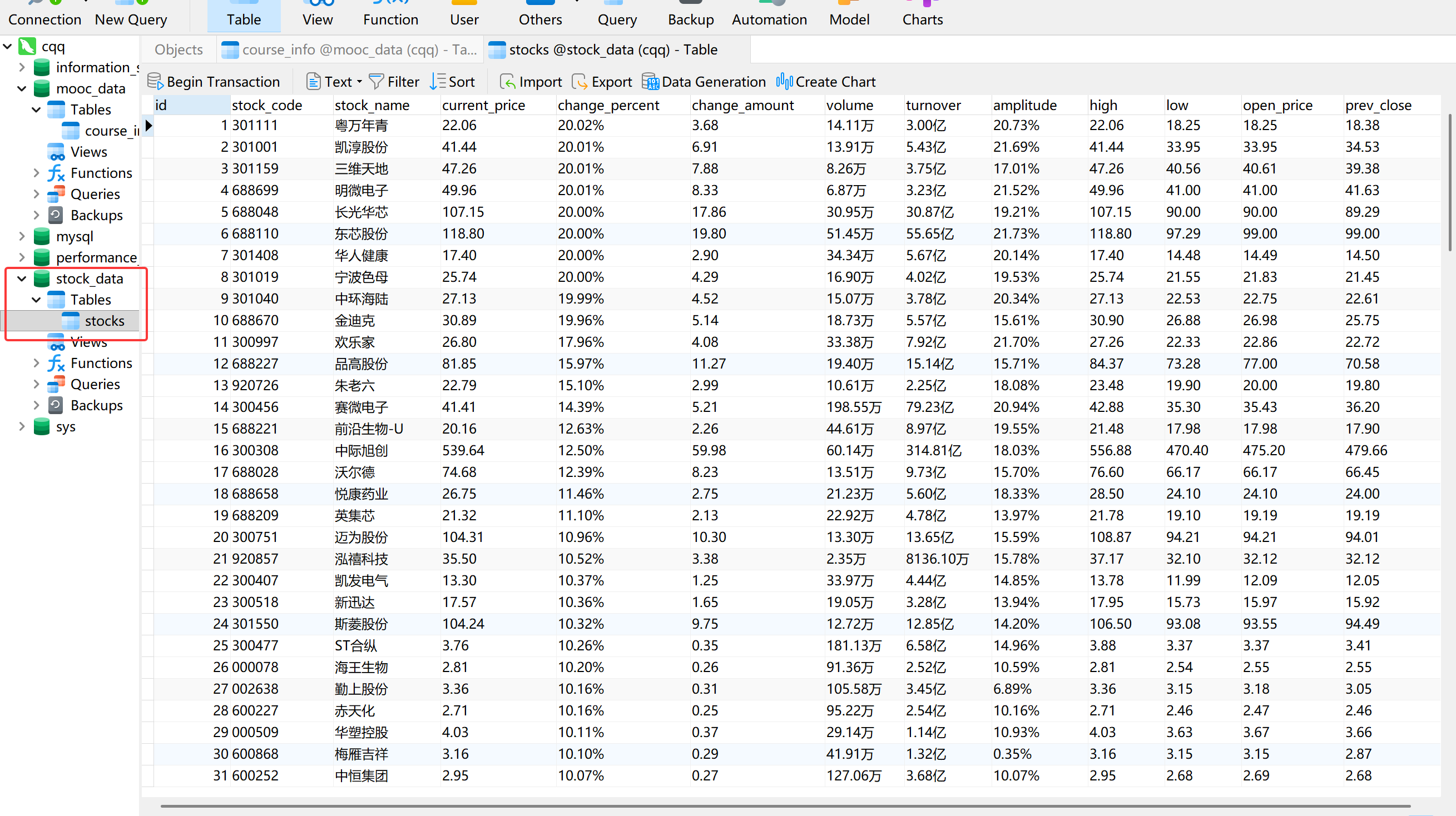
实验结果
2.心得体会
在本次实验中,通过使用 Selenium 爬取东方财富网的股票数据,我不仅巩固了动态网页爬取的技术,还解决了一些实际遇到的问题。首先,在访问目标网页时,我发现页面加载后会弹出广告窗口,遮挡页面并阻碍了后续的元素定位和操作。为了解决这个问题,我在代码中巧妙地加入了 input("去掉广告后回车") 语句。这使得程序在打开网页后暂停执行,给我留出时间手动关闭广告,确认页面干净后再回车继续运行,从而确保了自动化的稳定性。
其次,在分析表格数据结构时,我注意到 tr 标签下的 td 列表中,索引为 3 的元素(tds[3])实际上是一个包含图片的字段(通常表示“加自选”等图标),并非我所需要的文本数据。因此,在提取数据时,我特意跳过了 tds[3],代码中直接从 tds[2](股票名称)获取数据后,下一个字段直接取 tds[4](最新报价),从而保证了提取到的数据字段与数据库表结构的一一对应,提高了数据的准确性。
代码地址:https://gitee.com/changqianqi/2025_crawl-project/blob/master/4/1.py
作业②
1.中国MOOC网课程数据爬取实验
实验要求
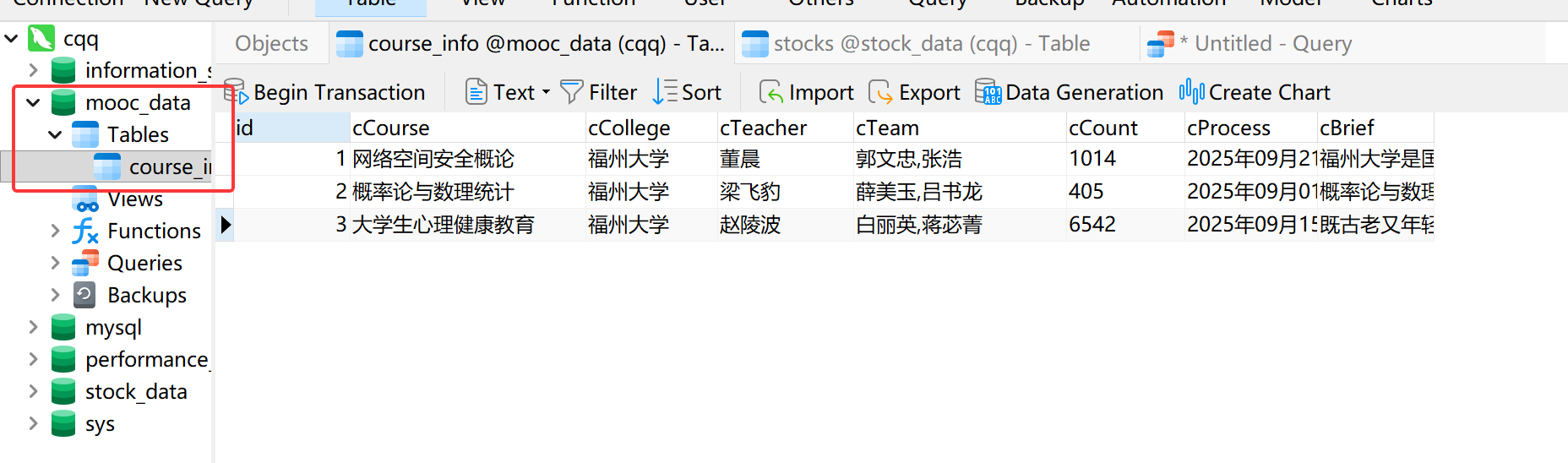
熟练掌握 Selenium 查找 HTML 元素、实现用户模拟登录、爬取 Ajax 网页数据等内容。使用 Selenium 框架+ MySQL 数据库存储技术路线爬取中国 MOOC 网课程资源信息(课程号、课程名称、学校名称、主讲教师、团队成员、参加人数、课程进度、课程简介)。
候选网站:中国 MOOC 网(https://www.icourse163.org)
输出信息:MYSQL 数据库存储和输出格式。
核心代码
本实验需要登录后获取个人课程信息,并深入每个课程的详情页抓取数据。
由于如果不登录到个人主页,就没有跳转课程详情的Xpath,我采用了“手动登录+自动爬取”的策略。程序启动后会暂停等待,登录完成后跳转至个人课程页。随后,程序提取所有课程详情页链接,利用 window.open 逐个打开新窗口,抓取课程名称、教师团队、进度及简介等详细字段。
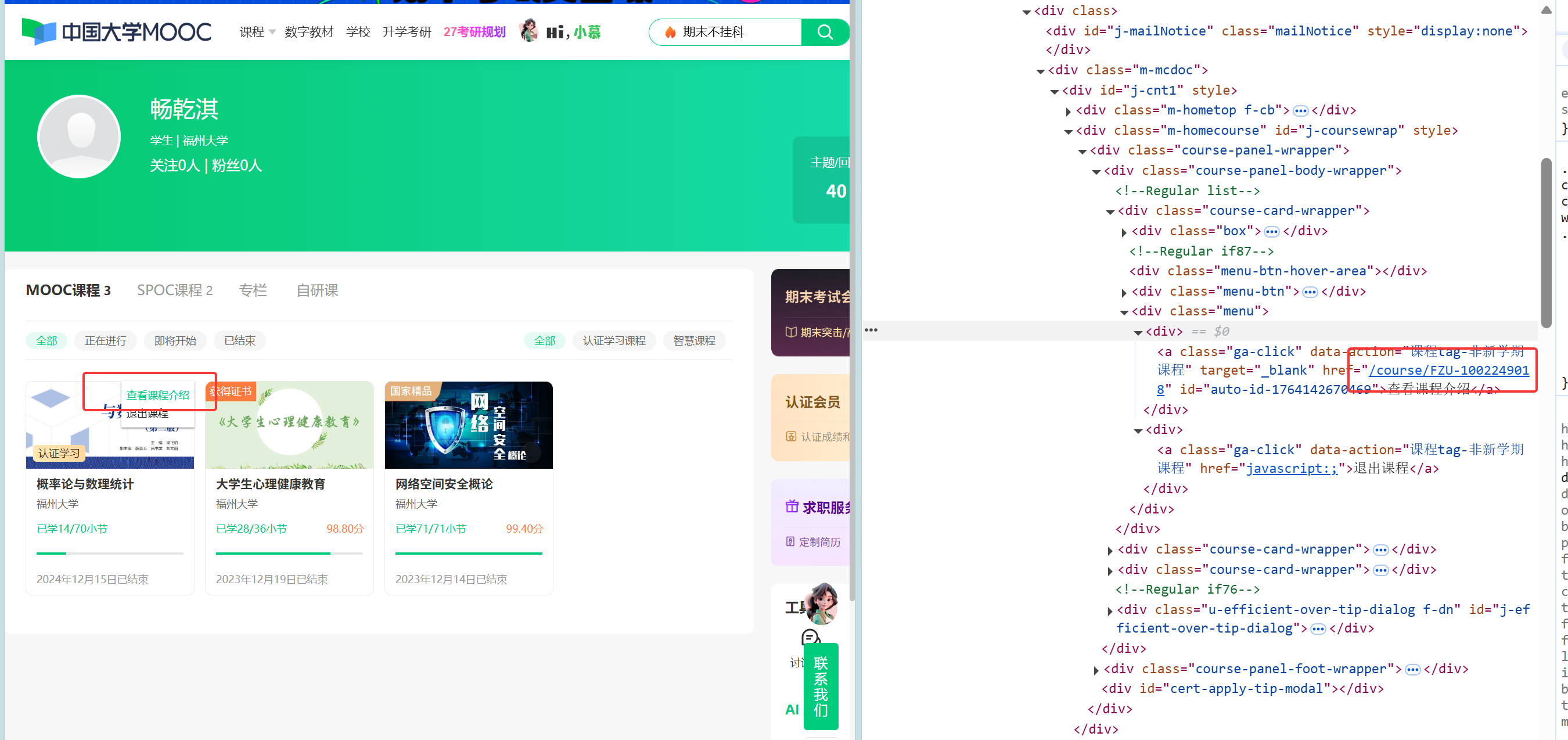
课程详细信息的Xpath:
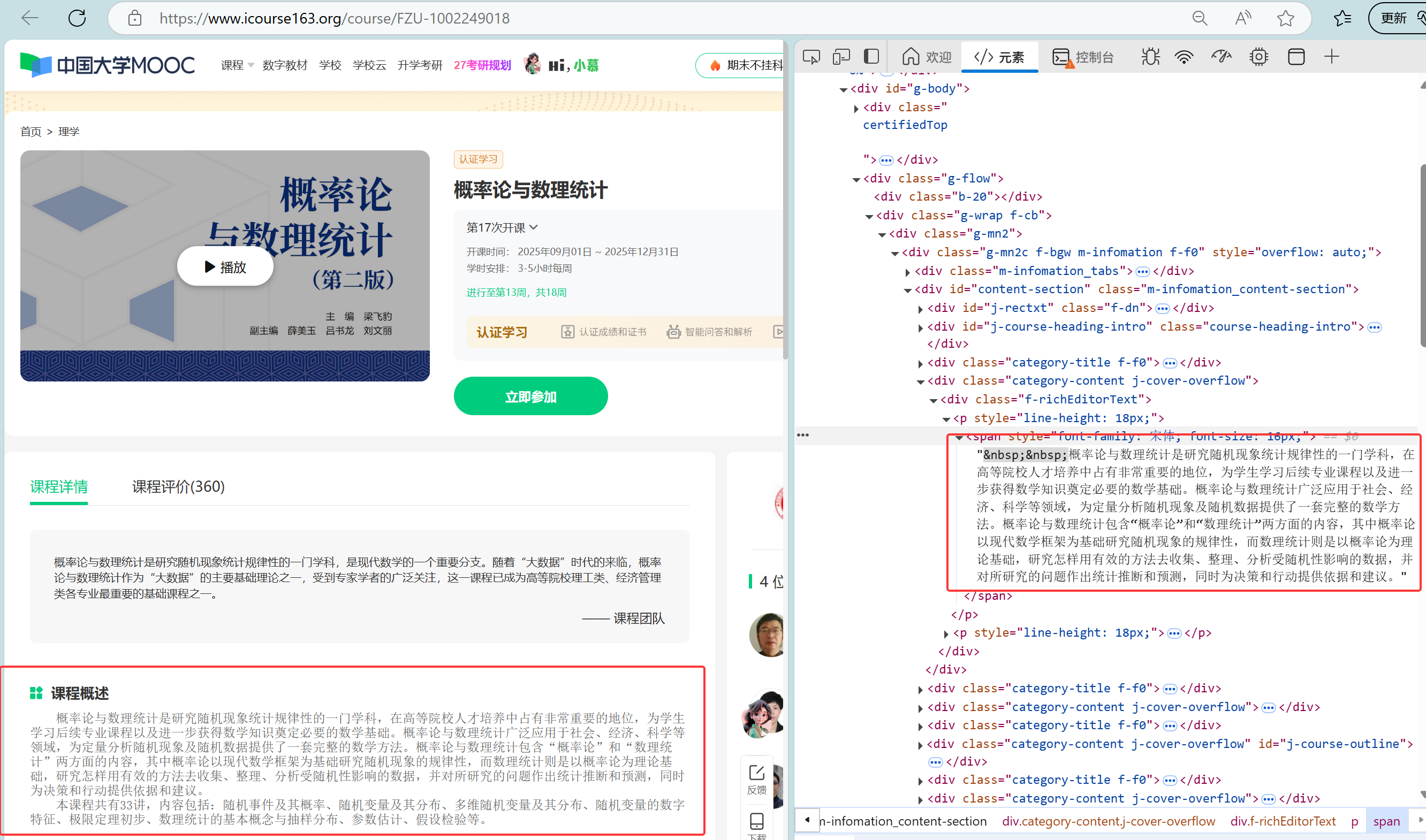
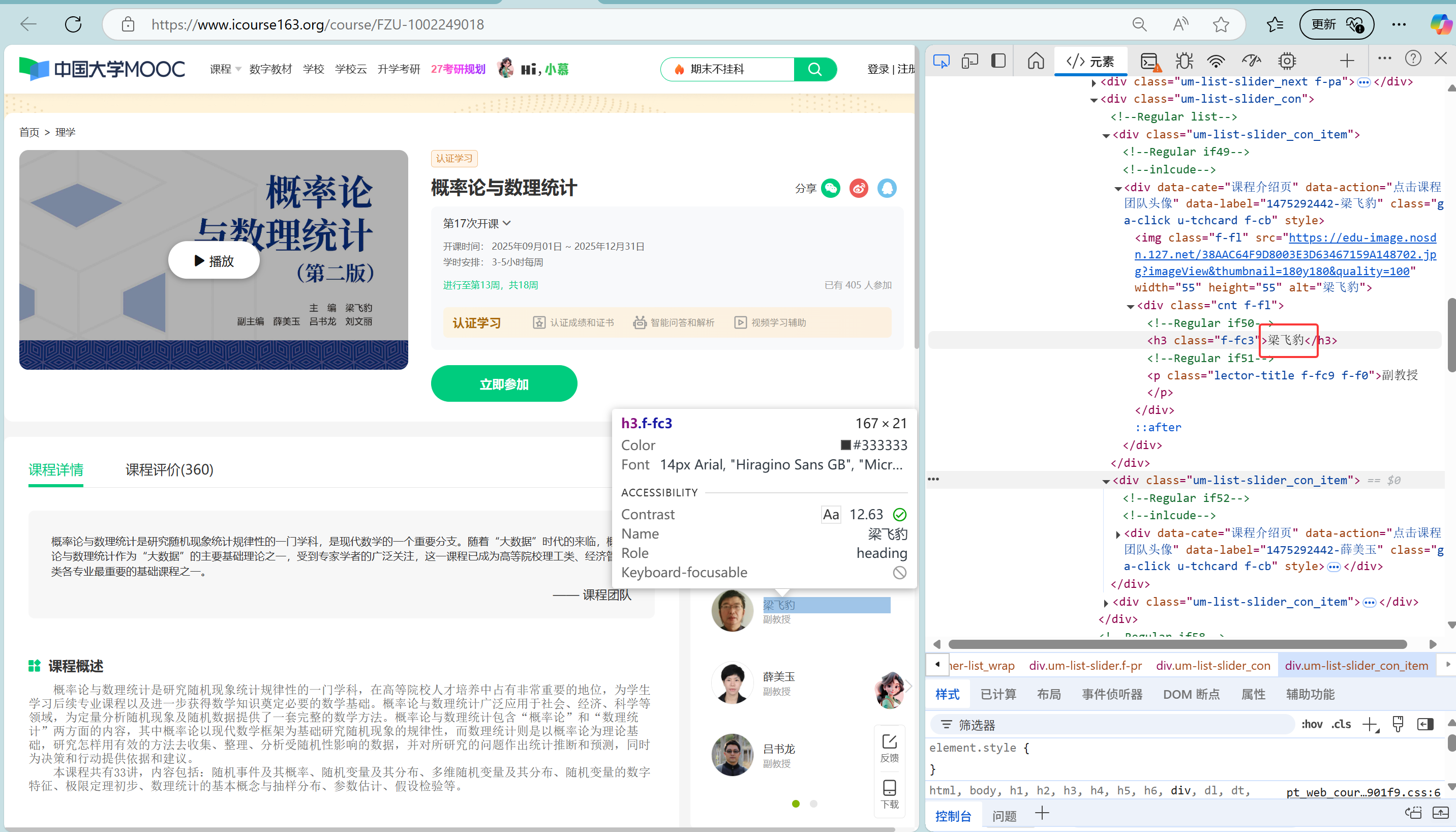
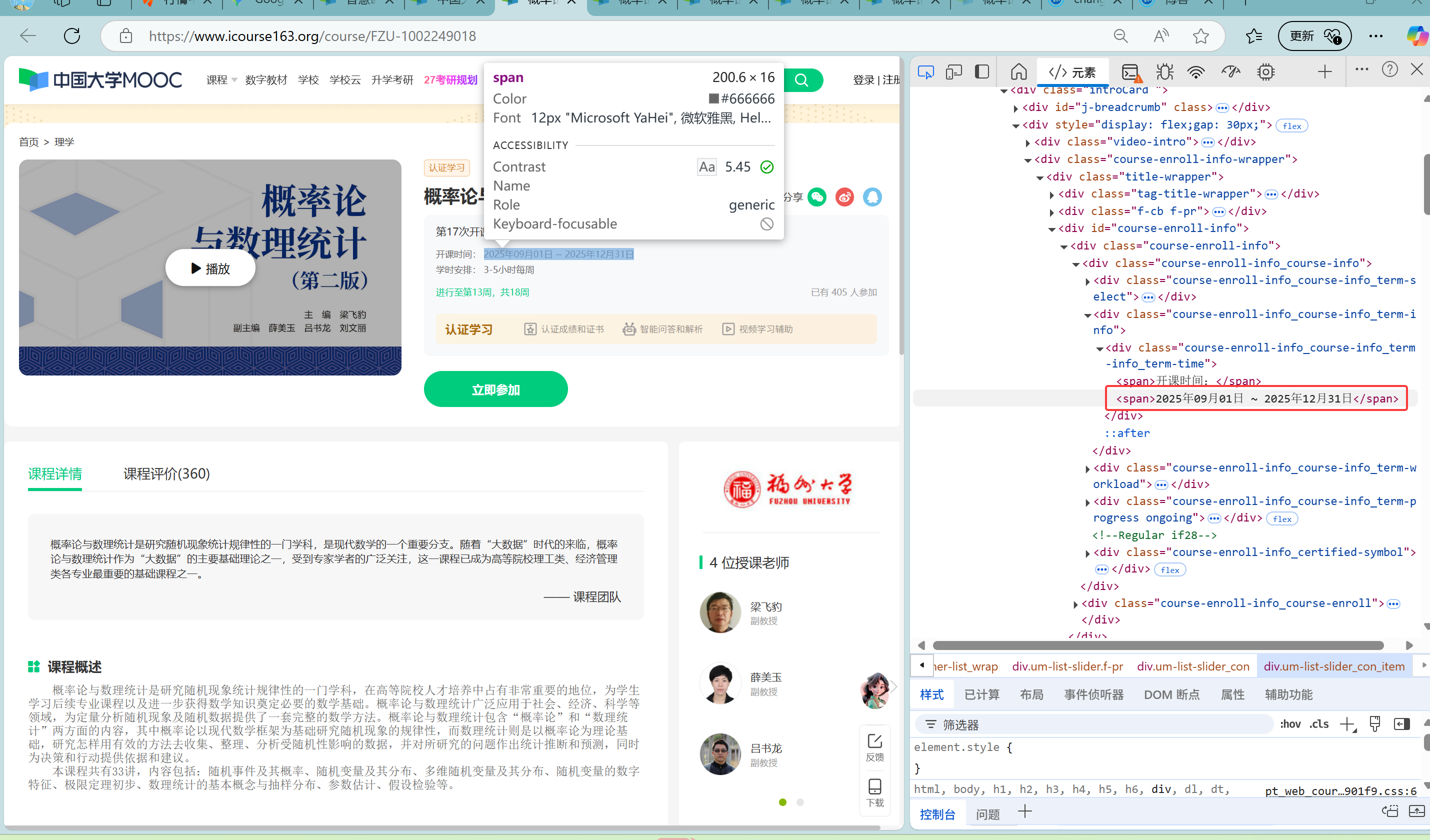
在代码中使用我找到的Xpath:
# 1. 打开首页并等待登录
dr.get("[https://www.icourse163.org/](https://www.icourse163.org/)")
input("登录完成后按回车键")
dr.get("[https://www.icourse163.org/home.htm?userId=1476512181#/home/course](https://www.icourse163.org/home.htm?userId=1476512181#/home/course)")
time.sleep(5)
# ... (滚动页面并提取所有“查看课程介绍”链接到 urls 列表)
for u in urls:
# 使用JS打开新窗口,避免覆盖当前列表页
dr.execute_script(f"window.open('{u}');")
dr.switch_to.window(dr.window_handles[-1]) # 切换句柄到新窗口
time.sleep(3)
# 提取详情页数据
n = dr.find_element(By.XPATH, '//span[contains(@class,"course-title")]').text
# 处理复杂的教师团队字段
ts = dr.find_elements(By.XPATH, '//*[@id="j-teacher"]//h3')
t1 = ts[0].text # 主讲教师
c_ele = dr.find_element(By.XPATH, '//*[@id="course-enroll-info"]/div/div[1]/div[4]/span[2]')
cnt = c_ele.text.replace("已有", "").replace("人参加", "").strip()
# 入库
sql = "insert into course_info (cCourse, cCollege, cTeacher, cTeam, cCount, cProcess, cBrief) values (%s, %s, %s, %s, %s, %s, %s)"
cur.execute(sql, (n, s, t1, t2, cnt, proc, info))
# 关闭当前详情页,切回主窗口
dr.close()
dr.switch_to.window(dr.window_handles[0])
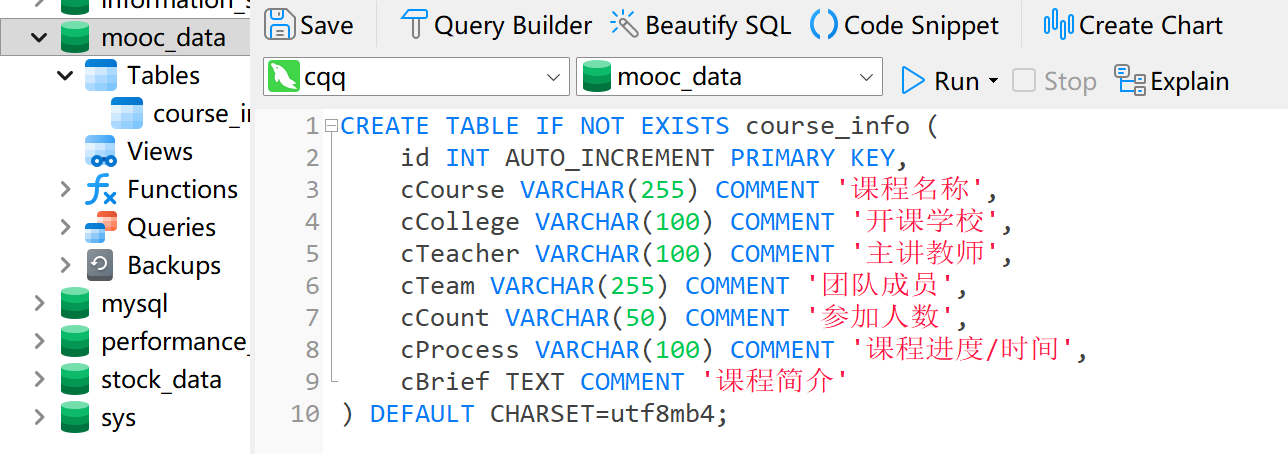
此外,类似的,我在mysql中创建对应的数据库
实验结果
2.心得体会
在进行中国 MOOC 网的爬取实验时,我主要攻克了模拟登录和多窗口管理两个难点。
首先,我发现如果不登录课程信息太多找不到隐藏的url,爬取难度极大,索性登录后发现显示出了自己的课程url,只需Xpath解析跳转即可。
其次,课程详情页的爬取需要在不丢失主列表页上下文的前提下进行。我利用 Selenium 的 window_handles 属性,配合 dr.switch_to.window() 方法,实现了在“课程列表页”与“课程详情页”之间的灵活切换。每爬取完一个详情页,我都会及时 dr.close() 并切回主句柄,这有效避免了浏览器开启过多标签页导致的资源耗尽问题。
代码地址:https://gitee.com/changqianqi/2025_crawl-project/blob/master/4/2.py
作业③
1.大数据实时分析处理实验
实验要求
掌握大数据相关服务,熟悉 Xshell 的使用。
完成华为云_大数据实时分析处理实验手册中的 Flume 日志采集任务
实验结果
环境搭建:开通 MapReduce 服务。
实时分析开发实战:编写 Python 脚本生成测试数据。
ssh远程连接
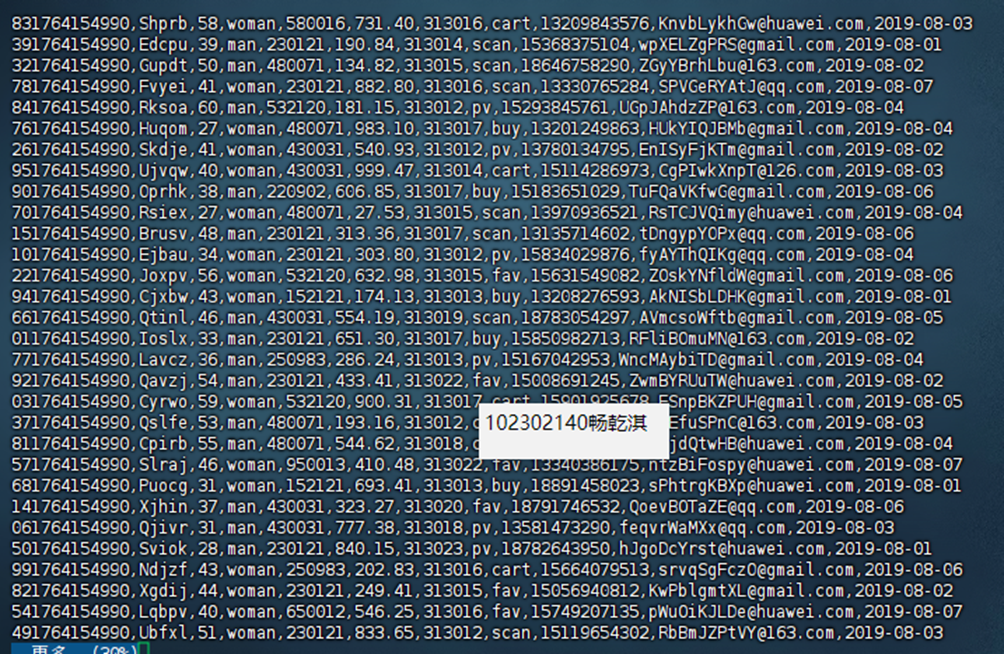
生成数据
配置 Kafka。
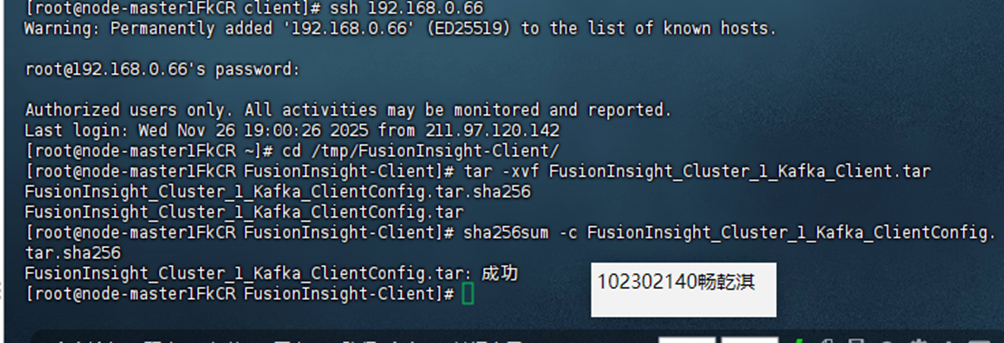
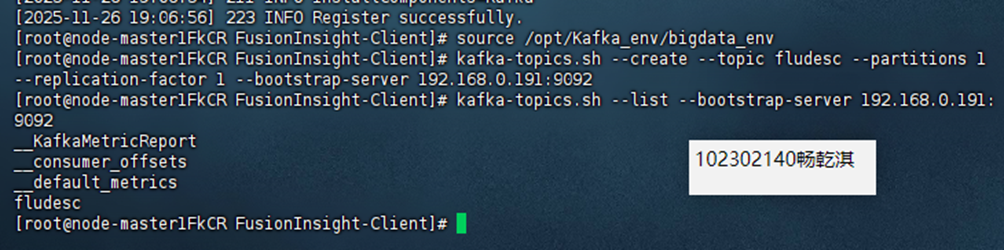
安装 Flume 客户端。
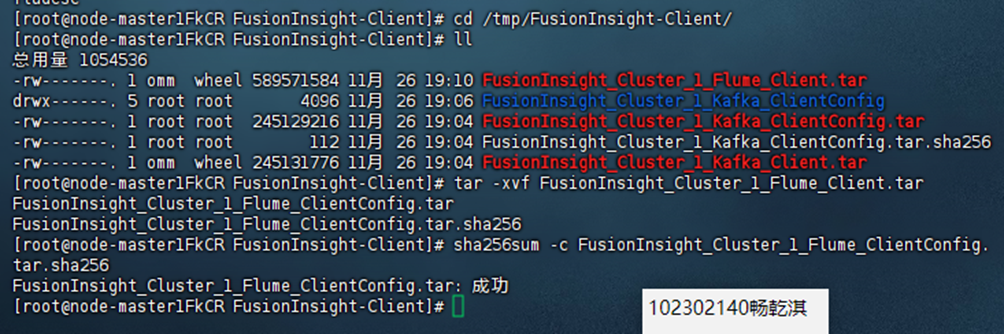
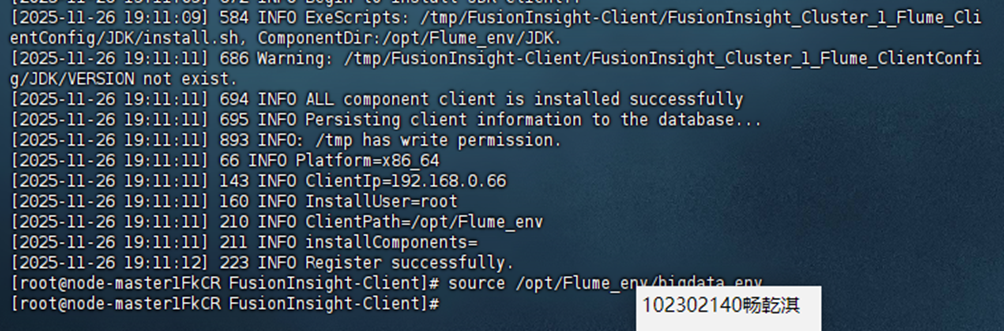
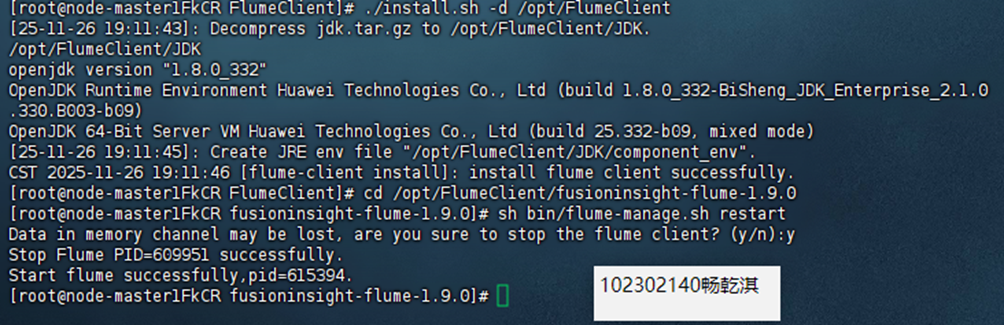
配置 Flume 采集数据。
2.心得体会
本次实验让我对大数据实时处理流程有了更直观的认识。在实验过程中,我首先通过 Xshell 连接到华为云 MRS 节点,体验了真实的云端开发环境。最开始在配置 Flume 时,由于对配置文件参数(IP 地址)填写错误,用了client的ip,导致 Flume 启动后无法连接 Kafka,报错 "Failed to deliver event"。通过查阅手册解决问题。
代码地址:https://gitee.com/changqianqi/2025_crawl-project/tree/master/4

 浙公网安备 33010602011771号
浙公网安备 33010602011771号