
第三次作业
作业①
1.气象网页爬取实验
实验要求
指定一个网站,爬取这个网站中的所有的所有图片,中国气象网(http://www.weather.com.cn)。实现单线程和多线程的方式爬取。
输出信息:将下载的图片保存在images子文件夹中
核心代码
为了从中国天气网的生活频道获取图片资源,我编写了get_images_from_page函数。利用BeautifulSoup解析网页后,通过分析DOM结构发现图片主要集中在class='zhengw'的div容器中。为了保证链接的可用性,我使用了urljoin将相对路径转换为绝对URL,并返回一个包含该页面所有图片链接的列表。
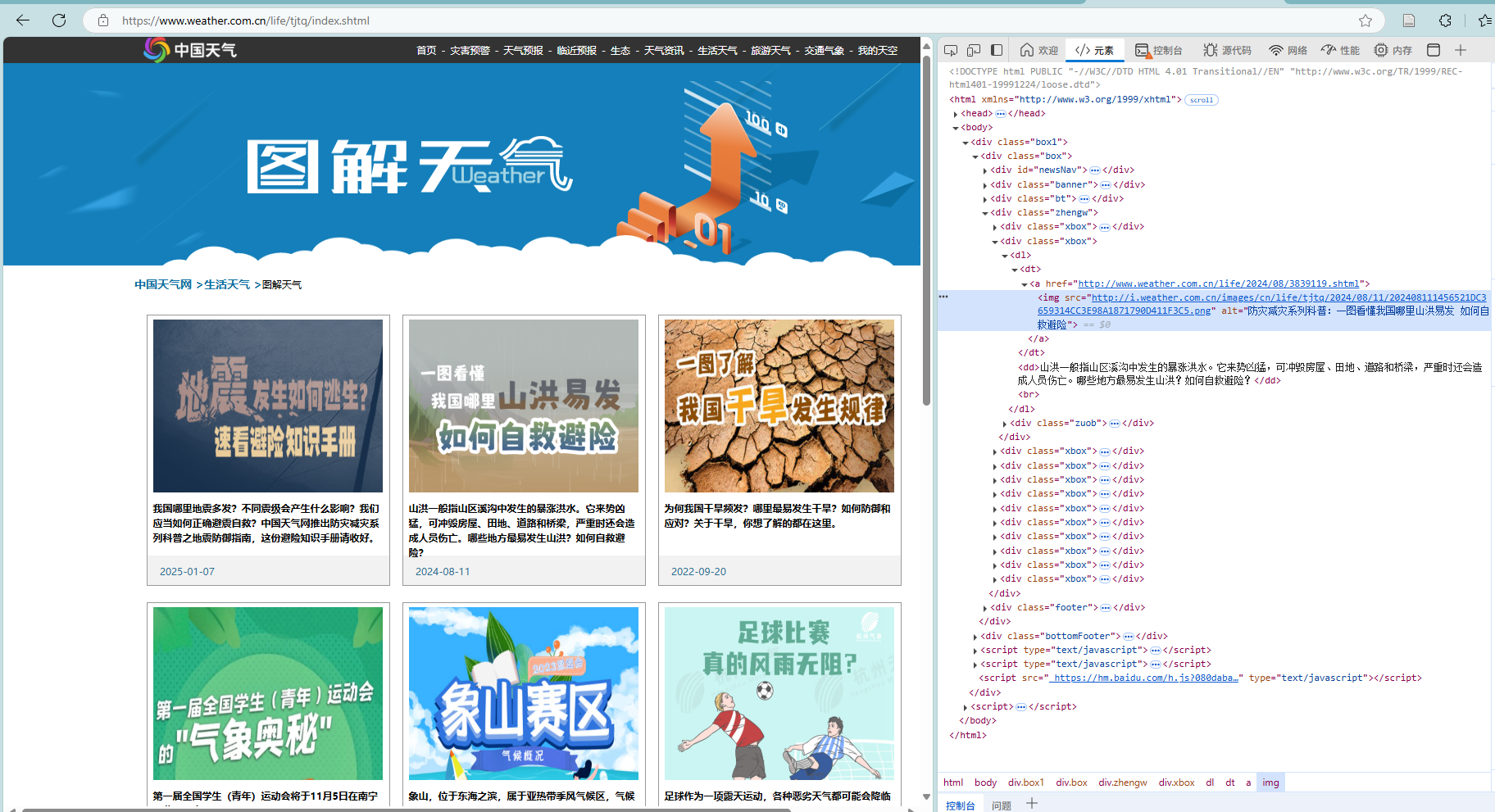
# 核心代码:1.py (WeatherDB 类)
import sqlite3
class WeatherDB:
def openDB(self):
self.con=sqlite3.connect("weathers.db")
self.cursor=self.con.cursor()
try:
# 建立一个以城市和日期为主键的表,防止数据重复
self.cursor.execute("create table weathers (wCity varchar(16),wDate varchar(16),wWeather varchar(64),wTemp varchar(32), constraint pk_weather primary key (wCity,wDate))")
except:
self.cursor.execute("delete from weathers")
def insert(self,city,date,weather,temp):
try:
self.cursor.execute("insert into weathers (wCity,wDate,wWeather,wTemp) values (?,?,?,?)" ,(city,date,weather,temp))
except Exception as err:
print(err) # 打印错误,如主键冲突
在实现爬取方式上,我分别设计了单线程和多线程两种方案。
对于单线程下载存储:
在处理分页URL时,我特别注意了首页(index.shtml)与其他页码(index_num.shtml)的命名差异。程序按顺序解析每一页的HTML,提取图片链接后立即调用download_image函数进行下载,只有当前图片下载完成后才会处理下一张。
def download_image(image_url, save_path):
try:
response = requests.get(image_url, headers=HEADERS, stream=True, timeout=15)
response.raise_for_status()
os.makedirs(os.path.dirname(save_path), exist_ok=True)
with open(save_path, 'wb') as f:
for chunk in response.iter_content(8192):
f.write(chunk)
print(f"下载成功: {image_url}")
return True
except Exception as e:
print(f"下载失败: {image_url}, 原因: {e}")
return False
为了高效地完成140张图片的下载任务,我利用Python的concurrent.futures模块实现了多线程并发爬虫。与单线程不同,我将任务拆分为“URL收集”和“并发下载”两个阶段。首先循环翻页直至收集满140个目标URL,然后初始化一个包含10个工作线程的ThreadPoolExecutor线程池。
from concurrent.futures import ThreadPoolExecutor, as_completed
def multi_thread_scraper_140_images(max_workers=10):
# ... (省略URL收集部分,假设urls_to_download已准备好) ...
# 核心:使用线程池并发下载
total_downloaded = 0
with ThreadPoolExecutor(max_workers=max_workers) as executor:
future_to_url = {}
for i, img_url in enumerate(urls_to_download):
filename = f"image_{i+1:03d}.jpg"
save_path = os.path.join(save_dir, filename)
# 异步提交任务到线程池
future = executor.submit(download_image, img_url, save_path)
future_to_url[future] = img_url
# 接收完成的任务结果
for future in as_completed(future_to_url):
if future.result():
total_downloaded += 1
实验结果
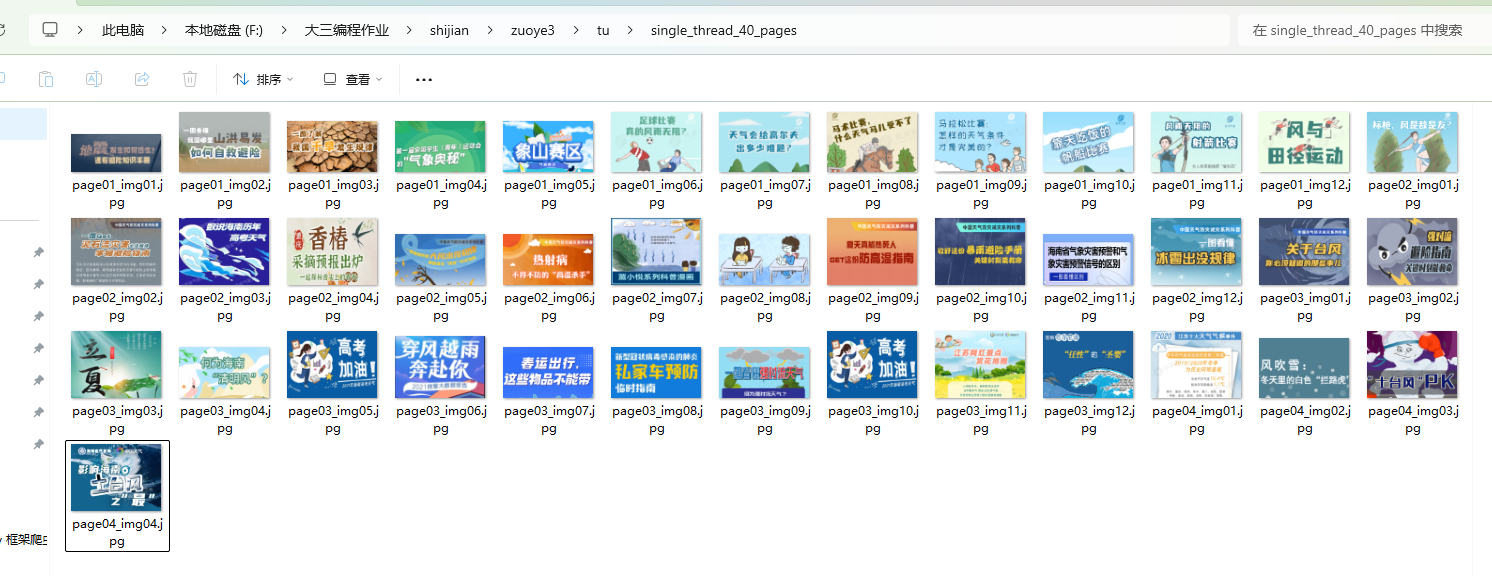
2.心得体会
与文本不同,图片属于二进制数据,写入文件时必须指定'wb'模式,并使用iter_content分块写入以保证内存安全;网页源码获取的图片链接是相对路径,必须使用urljoin将其转换为绝对URL才能有效访问。
作业②
1.股票信息定向爬虫实验
实验要求
熟练掌握 Scrapy 框架中 Item、Pipeline 数据的序列化与持久化输出方法。
掌握 Scrapy + 动态API分析 + SQLite 数据库存储的技术路线,爬取股票相关信息。
爬取东方财富网的股票列表信息,存入本地 stocks.db 数据库。
输出信息:数据库存储格式符合实验要求,表头使用英文命名(如 bStockNo)。
核心代码
在stock_spider.py中,start_requests方法负责循环构造5页的API请求URL。parse方法负责处理返回的JSON数据。由于返回数据并非标准JSON,需要先进行字符串切片处理,然后进行数据清洗(如将"-"替换为0)和单位换算(如价格除以100,成交额除以1亿),最后封装成StockScraperItem对象并yield到Pipeline。
# 核心代码:stock_spider.py
import json
from stock_scraper.items import StockScraperItem
class StockSpider(scrapy.Spider):
name = "stock"
def parse(self, response):
try:
# 1.切片处理
json_str = response.text[response.text.find('{'):response.text.rfind('}')+1]
data = json.loads(json_str)
except:
self.logger.error(f"无法解析JSON: {response.url}")
return
stock_list = data.get('data', {}).get('diff')
if not stock_list:
return
for item_data in stock_list:
# 处理空值
for k in item_data:
if item_data[k] == "-":
item_data[k] = 0
item = StockScraperItem()
# 填充Item并进行单位换算
item['bStockNo'] = item_data.get('f12')
item['bStockName'] = item_data.get('f14')
item['latestPrice'] = float(item_data.get('f2', 0)) / 100
item['volume'] = float(item_data.get('f5', 0)) / 10000
item['turnover'] = float(item_data.get('f6', 0)) / 100000000
yield item
在pipelines.py中,定义了SqlitePipeline类,用于处理Spider提交的Item。在爬虫启动时,它会自动连接(或创建)stocks.db数据库,执行CREATE TABLE IF NOT EXISTS来确保表结构存在,并使用DELETE FROM清空旧数据。对于接收到的每一个Item(process_item),它会执行参数化的INSERT语句,将数据安全地存入数据库。
# Pipeline的数据存储
def open_spider(self, spider):
self.db = sqlite3.connect('stocks.db')
self.cursor = self.db.cursor()
# 启动时建表并清空
self.cursor.execute("""
CREATE TABLE IF NOT EXISTS stocks (
id INTEGER PRIMARY KEY AUTOINCREMENT,
bStockNo TEXT UNIQUE,
bStockName TEXT,
latestPrice REAL,
...
);
""")
self.cursor.execute("DELETE FROM stocks;")
self.db.commit()
def process_item(self, item, spider):
insert_sql = """
INSERT INTO stocks (bStockNo, bStockName, latestPrice, changePercent,
changeAmount, volume, turnover, amplitude, high,
low, openPrice, prevClose)
VALUES (?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?)
"""
data = (
item['bStockNo'], item['bStockName'], item['latestPrice'],
item['changePercent'], item['changeAmount'], item['volume'],
item['turnover'], item['amplitude'], item['high'],
item['low'], item['openPrice'], item['prevClose']
)
# 插入
try:
self.cursor.execute(insert_sql, data)
self.db.commit()
except sqlite3.Error as e:
self.db.rollback()
return item
实验结果
执行scrapy crawl stock命令后,爬虫成功抓取了东方财富网的前5页股票数据。
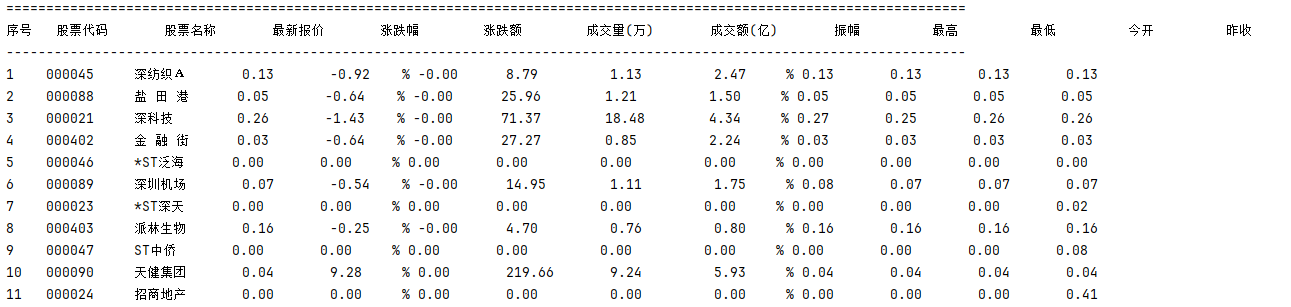
2.心得体会
本实验让我了解到如何create 一个 scrapy project项目以及Scrapy 框架的解耦思想,即 Spider 负责“爬取”,Item 负责“定义”,Pipeline 负责“处理”。
作业③
1.爬取外汇数据网站
实验要求
熟练掌握 Scrapy 中 Item、Pipeline 数据的序列化输出方法。
使用 Scrapy 框架 + Xpath + 数据库存储技术路线(本实验采用 SQLite),爬取中国银行外汇牌价网站数据。
候选网站:中国银行外汇牌价 (https://www.boc.cn/sourcedb/whpj/)
输出信息:将爬取的数据存储在数据库中,表头包含:Currency (货币名称), TBP (现汇买入价), CBP (现钞买入价), TSP (现汇卖出价), CSP (现钞卖出价), Time (发布时间)。
核心代码
- Items 定义 (数据模型) 首先定义数据结构,包含货币名称、四种价格及发布时间,与数据库表结构对应。
# 核心代码:items.py
class BocScraperItem(scrapy.Item):
currency = scrapy.Field() # 货币名称
tbp = scrapy.Field() # 现汇买入价
cbp = scrapy.Field() # 现钞买入价
tsp = scrapy.Field() # 现汇卖出价
csp = scrapy.Field() # 现钞卖出价
time = scrapy.Field() # 发布时间
在boc_spider.py中,为了应对网页结构可能的变化,使用normalize-space清洗HTML中的空白字符,并实现了自动翻页逻辑。
def parse(self, response):
# 定位包含表头“货币名称”的 table
table = response.xpath("//th[contains(normalize-space(.), '货币名称')]/ancestor::table[1]")
rows = table.xpath(".//tr[position()>1]")
for row in rows:
item = BocScraperItem()
item['currency'] = row.xpath("normalize-space(.//td[1])").get()
item['tbp'] = row.xpath("normalize-space(.//td[2])").get()
item['time'] = row.xpath("normalize-space(.//td[8])").get()
yield item
next_page_url = response.xpath("//a[contains(normalize-space(.), '下一页')]/@href").get()
if next_page_url:
yield scrapy.Request(response.urljoin(next_page_url), callback=self.parse)
在pipelines.py中,我使用sqlite3实现了数据的存储。process_item方法中增加了对空值(None或空字符串)的处理,将其转换为0.0,防止插入数据库时报错或数据格式错误。
# 核心代码:pipelines.py (SqlitePipeline类)
def process_item(self, item, spider):
insert_sql = """
INSERT INTO exchange_rates (currency, tbp, cbp, tsp, csp, time)
VALUES (?, ?, ?, ?, ?, ?)
"""
# 若爬取值为None则存为0.0
data = (
item.get('currency'),
float(item.get('tbp') or 0.0),
float(item.get('cbp') or 0.0),
float(item.get('tsp') or 0.0),
float(item.get('csp') or 0.0),
item.get('time')
)
try:
self.cursor.execute(insert_sql, data)
self.db.commit()
except sqlite3.Error as e:
self.db.rollback()
return item
实验结果
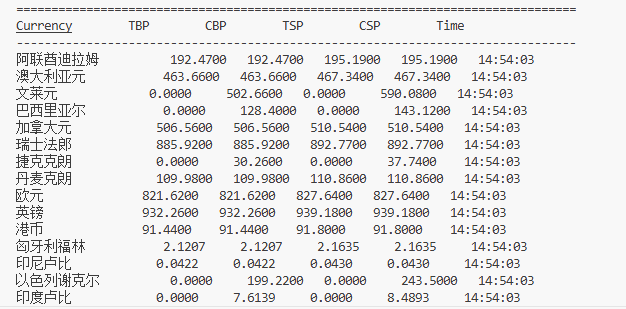
2.心得体会
本次实验最大的收获在于提升了XPath定位的鲁棒性。在分析中国银行网页时,发现表格嵌套较多,单纯使用 /table/tr 容易定位错误,因此我使用 //th[contains(...)]/ancestor::table 这种基于内容的相对定位法。此外,在数据入库环节,我意识到实际网页中经常存在某些币种“现钞买入价”为空的情况,如果在 Pipeline 中不进行 or 0.0 的空值预处理,直接进行 float() 转换会导致程序崩溃。
代码地址:https://gitee.com/changqianqi/2025_crawl-project/tree/master/3

 浙公网安备 33010602011771号
浙公网安备 33010602011771号