


第二次作业
作业①
1.气象网页爬取实验
实验要求
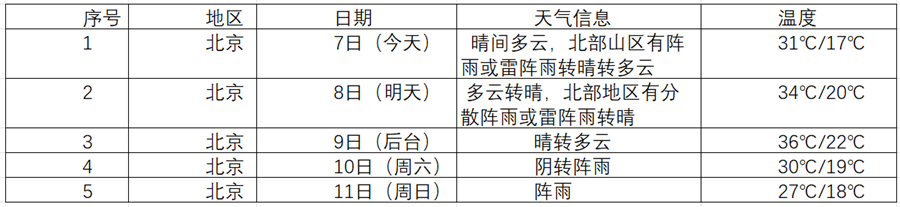
在中国气象网(http://www.weather.com.cn)给定城市集的7日天气预报,并保存在数据库。
核心代码
为了持久化存储爬取的天气信息,我使用sqlite3创建了一个WeatherDB类。它在初始化时会创建一个weathers表(如果不存在),并提供一个insert方法用于插入数据。
# 核心代码:1.py (get_images_from_page 方法)
def get_images_from_page(page_url):
try:
response = requests.get(page_url, headers=HEADERS, timeout=10)
soup = BeautifulSoup(response.text, 'lxml')
# 图片位于 <div class="zhengw"> 内
content_div = soup.find('div', class_='zhengw')
if not content_div:
return []
image_urls = []
# 提取并拼接完整URL
for img in content_div.find_all('img'):
src = img.get('src')
if src:
full_url = urljoin(page_url, src)
image_urls.append(full_url)
return image_urls
为了获取北京的天气数据,我构造了包含城市代码的URL。在请求时,必须添加User-Agent请求头来模拟浏览器,否则会请求失败。同时,由于网站编码可能在utf-8和gbk之间切换,我使用了UnicodeDammit来智能判断和转码,确保BeautifulSoup能正确解析。通过F12分析网页源码,我定位到所有7天的数据都在一个
- 标签(class='t clearfix')下的
- 标签中。
![image]()
# 核心代码:1.py (forecastCity 方法 - 解析部分) # 1. 定位到7个li标签 lis=soup.select("ul[class='t clearfix'] li") for li in lis: try: # 2. 分别提取日期和天气 date=li.select('h1')[0].text weather=li.select('p[class="wea"]')[0].text # 3. 处理复杂的温度数据 # 温度可能在span/i中,也可能只在p.tem中 temp_span = li.select_one('p[class="tem"] span') temp_i = li.select_one('p[class="tem"] i') if temp_span and temp_i: temp = temp_span.text + "/" + temp_i.text else: temp = li.select_one('p[class="tem"]').text.strip() # 4. 插入数据库 self.db.insert(city,date,weather,temp) except Exception as err: print(f"Error processing one day: {err}")实验结果
![image]()
2.心得体会
这个任务关键点在于:必须模拟浏览器User-Agent;要处理好gbk/utf-8的混合编码问题;BeautifulSoup解析时,对于结构不统一的标签(如温度)要写好if/else分支,保证程序的鲁棒性。
作业②
1.股票信息定向爬虫实验
实验要求
用requests和BeautifulSoup库方法定向爬取股票相关信息,并存储在数据库中。
![image]()
核心代码
打开东方财富网https://quote.eastmoney.com/center/gridlist.html#hs_a_board,按F12进入开发者工具,通过搜索某一个股票名找到存信息的js文件
![image]()
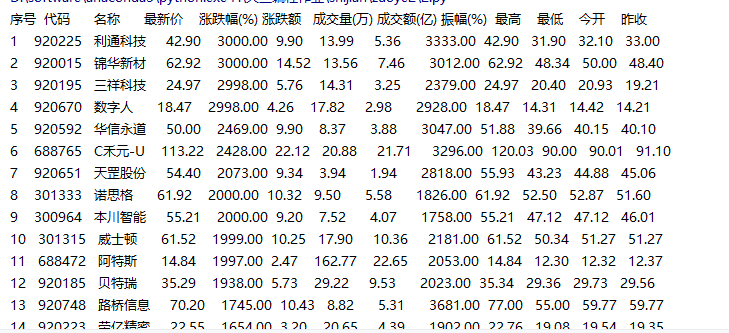
为了获取数据,我直接使用requests库请求这个API的URL,随后我使用正则表达式从响应文本中提取出括号内的{...}部分。def get_stock_data(page): # F12抓包获取的API地址,f...&pn={page}是关键参数 base_url = ( "[https://push2.eastmoney.com/api/qt/clist/get](https://push2.eastmoney.com/api/qt/clist/get)" "?np=1&fltt=1&invt=2" "&cb=jQuery371037061826685359867_1761721082041" # JSONP回调函数名 "&fs=m%3A0%2Bt%3A6%2Bf%3A!2%2Cm%3A0%2Bt%3A80%2Bf%3A!2" "&fields=f12%2Cf13%2Cf14%2Cf1%2Cf2%2Cf4%2Cf3%2Cf152%2Cf5%2Cf6%2Cf7%2Cf15%2Cf18%2Cf16%2Cf17%2Cf10%2Cf8%2Cf9%2Cf23" f"&pn={page}" # <--- 页码 "&pz=20&po=1" "&_=1761721082043" ) resp = requests.get(base_url) text = resp.text # 1. 使用正则从JSONP中提取JSON json_str = re.search(r'\(({.*})\)', text).group(1) # 2. 把字符串转成 python 字典 data = json.loads(json_str)为了得到和网页上一致的、易于阅读的数据 ,我遍历JSON中的data["data"]["diff"]列表。API返回的原始数据需要清洗:
1.缺失值用"-"表示,必须替换为0,否则float()会报错。
2.价格单位是“分”,需要/ 100。
3.成交量是“股”,需要/ 10000(万手)。
4.成交额是“元”,需要/ 100000000(亿)。page_rows = [] for item in data["data"]["diff"]: # 1. 清洗缺失值 for k in item: if item[k] == "-": item[k] = 0 # 2. 提取数据并进行单位换算 row = ( item.get('f12', ''), # 股票代码 item.get('f14', ''), # 股票名称 float(item.get('f2', 0)) / 100, # 最新价 (分 -> 元) float(item.get('f3', 0)), # 涨跌幅 (%) float(item.get('f4', 0)) / 100, # 涨跌额 float(item.get('f5', 0)) / 10000, # 成交量 (股 -> 万手) float(item.get('f6', 0)) / 100000000, # 成交额 (元 -> 亿) float(item.get('f7', 0)), # 振幅 (%) # ... 省略 high, low, open, prev_close ... ) page_rows.append(row) return page_rows实验结果
![image]()
2.心得体会
这个任务让我深刻体会到F12开发者工具的重要性。现代网页的数据和展示是分离的,爬虫不应该只盯着HTML,更应该去分析Network面板中的XHR请求。爬取API返回的JSON数据,比解析混乱的HTML要简单、高效得多。关键在于找到API、分析参数,并对返回数据进行清洗和单位换算。
作业③
1.爬取中国大学2021主榜实验
实验要求
爬取中国大学2021主榜(https://www.shanghairanking.cn/rankings/bcur/2021)所有院校信息。排名 学校名称 省市 学校类型 总分 1 清华大学 北京 综合 852.5 2 核心代码
https://www.shanghairanking.cn/_nuxt/static/1760667299/rankings/bcur/202011/payload.js这里含有我想要的全部信息。但是这份 JS 是 Nuxt 的 JSONP/IIFE,里面大量字段不是字面量,而是变量代号(如 eq、dj…)。最终思路是把 Nuxt 的 JSONP 拆开:形参–实参映射 → 找到 return{} → 抠出 data[] → 锚点定位每所学校对象 → 抽字段并替换变量。JS 里大量值是 变量代号(比如 eq、ef、nf…),必须先把 形参 ↔ 实参 对齐,再把对象里这些代号替换回真实值。之前“分数变成 ef/nf”的坑,就是忘了给 score 也做映射。
![屏幕录制 2025-10-29 194927]()
首先,先把 Nuxt 的 NUXT_JSONP(..., (function(a,b,c){...})( 实参... )) 里的形参和实参对上。我没有用re,而是“数括号 + 处理引号”,最后把实参段改成 Python 风格后一次性 literal_eval 成列表,避免被字符串里的逗号坑到。
import ast def slice_block(s, i, L, R): # 小括号/花括号配对工具 dep=0; ins=False; esc=False; l=i while i < len(s): ch = s[i] if ins: if esc: esc=False elif ch=="\\": esc=True elif ch=='"': ins=False else: if ch=='"': ins=True elif ch==L: dep+=1; l = l if dep!=1 else i elif ch==R: dep-=1 if dep==0: return l, i i += 1 raise ValueError("括号未配平") def parse_params_args(js): # 形参与实参 → 映射表 h = js.find("(function(") p_end = js.find(")", h+10) params = [x.strip() for x in js[h+10:p_end].split(",") if x.strip()] body_l = js.find("{", p_end) # 函数体 {...} body_l, body_r = slice_block(js, body_l, "{", "}") i = body_r + 1 # 紧跟的 ( 实参 ) while i < len(js) and js[i].isspace(): i += 1 if i < len(js) and js[i] == ')': i += 1 while i < len(js) and js[i].isspace(): i += 1 a_l, a_r = slice_block(js, i, "(", ")") args_str = js[a_l+1:a_r] safe = (args_str.replace("true","True").replace("false","False") .replace("null","None").replace("void 0","None")) values = ast.literal_eval("[" + safe + "]") n = min(len(params), len(values)) # 个别版本会差 1 return {params[i]: values[i] for i in range(n)}我用 univNameCn 当锚点,向左回溯到 { 再匹配 },拿到这所学校的完整对象。
对象内部不用正则,自己读 key: value:字符串去引号,数字/变量名截到逗号/右花括号def object_around(pos, text): # 锚点处向左回溯到“{”,取完整对象 i = pos while i>0 and text[i] != '{': i -= 1 l, r = slice_block(text, i, "{", "}") return text[l:r+1] def read_after_colon(obj, key): # 读 key: value 的 value(字符串/数字/变量) p = obj.find(key) if p < 0: return None c = obj.find(":", p); i = c + 1 while i < len(obj) and obj[i].isspace(): i += 1 if i >= len(obj): return None if obj[i] in "\"'": # "字符串" q = obj[i]; j = i+1; esc=False while j < len(obj): ch = obj[j] if esc: esc=False elif ch=="\\": esc=True elif ch==q: return obj[i+1:j] j += 1 return None j = i # 数字/变量名 while j < len(obj) and obj[j] not in ",}\r\n\t ": j += 1 return obj[i:j] def resolve(token, mapping): # 变量名 → 真值;其它原样 if token is None: return "" return str(mapping.get(token, token)) def is_number(s): # 不是数就别往下用了 try: float(s); return True except: return False其余只剩:requests.get() 把 payload.js 取回/落地;用 BeautifulSoup 初始化一下(满足“使用”要求);最后把 rows 按格式打印即可。
实验结果
![1]()
![1]()
2.心得体会
这题一开始卡得挺久:看到是 JS,我下意识想“正则一把梭”或者“整段转 JSON”。结果 Nuxt 的 JSONP 里全是变量代号,既 split 不开,也 parse 不成。后来换了思路:不和整段较劲,只把三段关键内容抠出来(形参与实参、return{}、data[]),其它都当成普通字符串处理。
两个坑印象最深:字符串里的逗号会把实参切坏。解决是把整段实参改成 Python 风格后,一次性 literal_eval,就不用担心逗号在哪了。
一开始只给 ranking/省份/类型 做了映射,忘了给 score 也做,于是分数就变成了 ef/nf 这种变量名。后来把 score 一起走 resolve(),并且用 is_number() 把假分数过滤掉,输出就干净了。
代码地址:https://gitee.com/changqianqi/2025_crawl-project/tree/master/2







 浙公网安备 33010602011771号
浙公网安备 33010602011771号