



第一次作业
作业①
1.大学排名动态网页爬取实验
实验要求
用requests和BeautifulSoup库方法定向爬取给定网址(http://www.shanghairanking.cn/rankings/bcur/2020 )的数据,屏幕打印爬取的大学排名信息。
| 排名 | 学校名称 | 省市 | 学校类型 | 总分 |
|---|---|---|---|---|
| 1 | 清华大学 | 北京 | 综合 | 852.5 |
| 2 |
核心代码
由于网站翻页url不会改变。且只能使用requests和BeautifulSoup(如果用模拟鼠标就需要用 Selenium),因此我最终发现https://www.shanghairanking.cn/_nuxt/static/1760667299/rankings/bcur/202011/payload.js这里含有我想要的全部信息。但是这份 JS 是 Nuxt 的 JSONP/IIFE,里面大量字段不是字面量,而是变量代号(如 eq、dj…)。最终思路是把 Nuxt 的 JSONP 拆开:形参–实参映射 → 找到 return{} → 抠出 data[] → 锚点定位每所学校对象 → 抽字段并替换变量。JS 里大量值是 变量代号(比如 eq、ef、nf…),必须先把 形参 ↔ 实参 对齐,再把对象里这些代号替换回真实值。之前“分数变成 ef/nf”的坑,就是忘了给 score 也做映射。
首先,先把 Nuxt 的 NUXT_JSONP(..., (function(a,b,c){...})( 实参... )) 里的形参和实参对上。我没有用re,而是“数括号 + 处理引号”,最后把实参段改成 Python 风格后一次性 literal_eval 成列表,避免被字符串里的逗号坑到。
import ast
def slice_block(s, i, L, R): # 小括号/花括号配对工具
dep=0; ins=False; esc=False; l=i
while i < len(s):
ch = s[i]
if ins:
if esc: esc=False
elif ch=="\\": esc=True
elif ch=='"': ins=False
else:
if ch=='"': ins=True
elif ch==L:
dep+=1; l = l if dep!=1 else i
elif ch==R:
dep-=1
if dep==0: return l, i
i += 1
raise ValueError("括号未配平")
def parse_params_args(js): # 形参与实参 → 映射表
h = js.find("(function(")
p_end = js.find(")", h+10)
params = [x.strip() for x in js[h+10:p_end].split(",") if x.strip()]
body_l = js.find("{", p_end) # 函数体 {...}
body_l, body_r = slice_block(js, body_l, "{", "}")
i = body_r + 1 # 紧跟的 ( 实参 )
while i < len(js) and js[i].isspace(): i += 1
if i < len(js) and js[i] == ')': i += 1
while i < len(js) and js[i].isspace(): i += 1
a_l, a_r = slice_block(js, i, "(", ")")
args_str = js[a_l+1:a_r]
safe = (args_str.replace("true","True").replace("false","False")
.replace("null","None").replace("void 0","None"))
values = ast.literal_eval("[" + safe + "]")
n = min(len(params), len(values)) # 个别版本会差 1
return {params[i]: values[i] for i in range(n)}
我用 univNameCn 当锚点,向左回溯到 { 再匹配 },拿到这所学校的完整对象。
对象内部不用正则,自己读 key: value:字符串去引号,数字/变量名截到逗号/右花括号
def object_around(pos, text): # 锚点处向左回溯到“{”,取完整对象
i = pos
while i>0 and text[i] != '{': i -= 1
l, r = slice_block(text, i, "{", "}")
return text[l:r+1]
def read_after_colon(obj, key): # 读 key: value 的 value(字符串/数字/变量)
p = obj.find(key)
if p < 0: return None
c = obj.find(":", p); i = c + 1
while i < len(obj) and obj[i].isspace(): i += 1
if i >= len(obj): return None
if obj[i] in "\"'": # "字符串"
q = obj[i]; j = i+1; esc=False
while j < len(obj):
ch = obj[j]
if esc: esc=False
elif ch=="\\": esc=True
elif ch==q: return obj[i+1:j]
j += 1
return None
j = i # 数字/变量名
while j < len(obj) and obj[j] not in ",}\r\n\t ":
j += 1
return obj[i:j]
def resolve(token, mapping): # 变量名 → 真值;其它原样
if token is None: return ""
return str(mapping.get(token, token))
def is_number(s): # 不是数就别往下用了
try: float(s); return True
except: return False
其余只剩:requests.get() 把 payload.js 取回/落地;用 BeautifulSoup 初始化一下(满足“使用”要求);最后把 rows 按格式打印即可。
实验结果


2.心得体会
这题一开始卡得挺久:看到是 JS,我下意识想“正则一把梭”或者“整段转 JSON”。结果 Nuxt 的 JSONP 里全是变量代号,既 split 不开,也 parse 不成。后来换了思路:不和整段较劲,只把三段关键内容抠出来(形参与实参、return{}、data[]),其它都当成普通字符串处理。
两个坑印象最深:
字符串里的逗号会把实参切坏。解决是把整段实参改成 Python 风格后,一次性 literal_eval,就不用担心逗号在哪了。
一开始只给 ranking/省份/类型 做了映射,忘了给 score 也做,于是分数就变成了 ef/nf 这种变量名。后来把 score 一起走 resolve(),并且用 is_number() 把假分数过滤掉,输出就干净了。
作业②
1.商城商品比价定向爬虫实验
实验要求
用requests和re库方法设计某个商城(自已选择)商品比价定向爬虫,爬取该商城,以关键词“书包”搜索页面的数据,爬取商品名称和价格。
| 序号 | 价格 | 商品名 |
|---|---|---|
| 1 | 65.00 | xxx |
| 2 |
核心代码
通过分析发现“没得比”商城的搜索结果页URL结构清晰(实则是淘宝,京东的反爬机制过于厉害导致容易黑号),适合直接用requests请求。数据提取则使用正则表达式完成。
def main():
"""
主函数,执行爬虫逻辑。
"""
#创建一个 Session 对象
session = requests.Session()
#模拟常见浏览器(防止被反爬取)
session.headers.update({
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/129.0.0.0 Safari/537.36',
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.7',
'Accept-Language': 'zh-CN,zh;q=0.9,en;q=0.8'
})
# 先访问一次首页
try:
print("正在初始化会话...")
session.get(base_url, timeout=10)
print("会话初始化成功。")
except requests.RequestException as e:
print(f"初始化会话失败: {e}")
return
all_products = []
current_page = 1
# 翻页循环:抓取前 5 页(不然不太友好)
while current_page <= 5:
# 构造分页 URL,观察目标站点的分页规则后拼接
url = f"{base_url}/Search?keyword={search_keyword}&p={current_page}"
print(f"正在爬取第 {current_page} 页... -> {url}")
try:
# 发送 GET 请求
response = session.get(url, timeout=10)
response.raise_for_status() # 若返回码非 2xx,会抛出 HTTPError 异常
# 编码处理:用 apparent_encoding 猜测编码,再据此解码为文本
response.encoding = response.apparent_encoding
html_content = response.text
except requests.RequestException as e:
print(f"请求错误: {e}")
break
为了能够匹配如图的商品信息,我使用以下的正则表达式
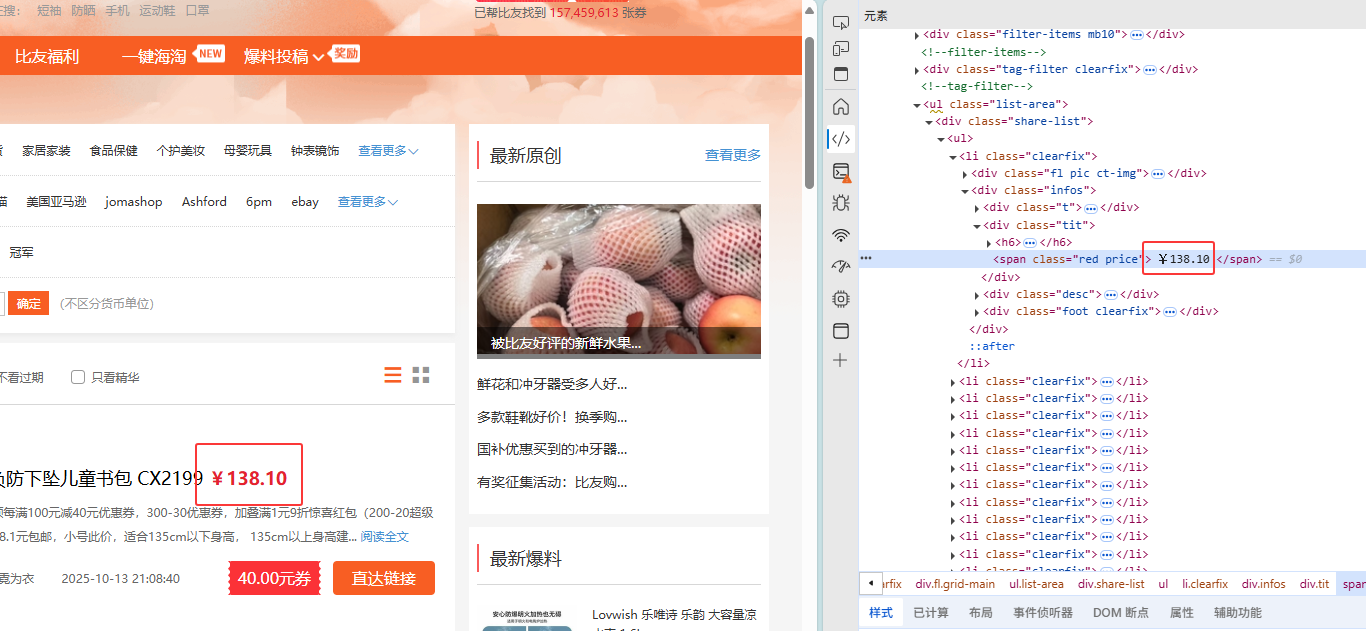
# 使用正则解析目标字段(价格与商品名)
product_regex = re.compile(
r'<li class="clearfix">.*?' # 商品块起点:每个商品在 <li class="clearfix"> 中
r'<span class="red price">\s*¥\s*([\d\.]+)\s*</span>.*?' # 价格:捕获 ¥ 后的数字(支持小数)
r'<h6><a href=".*?" target="_blank">(.*?)</a></h6>', # 商品名:位于 <h6><a> 的文本
re.S
)
products = product_regex.findall(html_content)
if not products:
# 页面中没有按照预期匹配到商品块,通常意味着:被反爬!
print(f"第 {current_page} 页没有找到更多商品,爬取结束。")
break
# 将当前页的结果追加到总列表
all_products.extend(products)
if 'class="next' not in html_content:
print("已到达最后一页,爬取结束。")
break
# 递增页码延时(绕过简单的反爬)
current_page += 1
time.sleep(1)
实验结果

2.心得体会
这个实验在编写正则表达式时,我遇到了几个关键点:首先,商品的价格和标题在HTML源码中相隔较远且包含换行,因此必须使用re.S标志,使.能够匹配包括换行符在内的任意字符。其次,为了防止匹配范围扩得太大,需要使用非贪婪匹配.*?。最后,通过括号()对需要提取的价格和商品名进行分组,findall函数就能直接返回一个包含元组的列表,大大简化了后续处理。
作业③
1.网页图片批量下载实验
实验要求
爬取一个给定网页(https://news.fzu.edu.cn/yxfd.htm)的所有JPEG、JPG或PNG格式图片文件
输出信息:将自选网页内的所有JPEG、JPG或PNG格式文件保存在一个文件夹中
核心代码
首先对页面进行解析
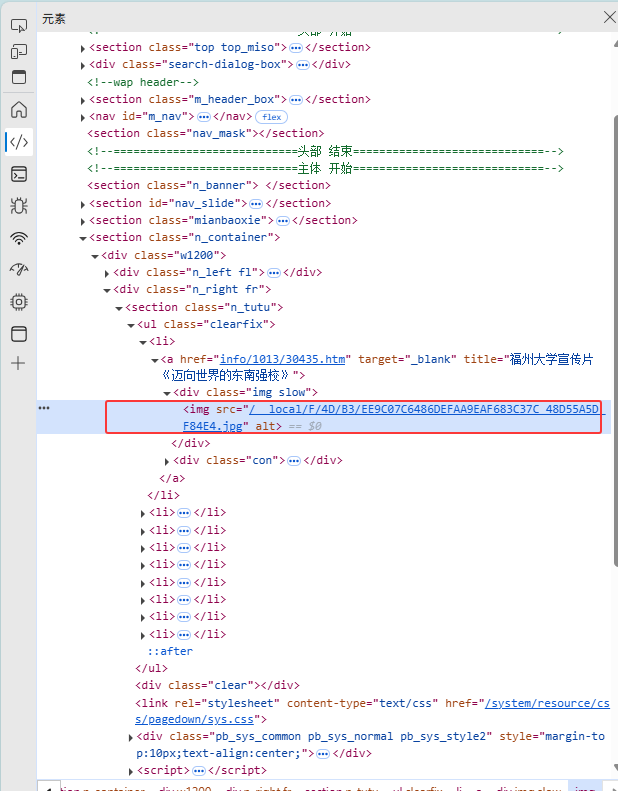
不难看出,img src内就是我们需要的内容
def main():
base_url = "[https://news.fzu.edu.cn/yxfd.htm](https://news.fzu.edu.cn/yxfd.htm)"
output_folder = "downloaded_images"
os.makedirs(output_folder, exist_ok=True)
# 设置请求头,模拟浏览器
headers = {
"User-Agent": "Mozilla/5.0",
"Referer": base_url
}
print(f"正在爬取: {base_url}")
try:
# 1. 获取网页HTML
req = urllib.request.Request(base_url, headers=headers)
with urllib.request.urlopen(req) as response:
html = response.read().decode("utf-8")
# 2. 正则表达式查找所有图片链接
img_urls_relative = re.findall(r'<img[^>]+src="([^"]+\.(?:jpg|jpeg|png))"', html, re.I)
# 3. 拼接、下载
for i, relative_url in enumerate(img_urls_relative):
# 将相对路径转换为绝对路径
absolute_url = urljoin(base_url, relative_url)
filename = os.path.join(output_folder, f"image_{i+1}.jpg")
print(f" -> 正在下载: {absolute_url}")
img_req = urllib.request.Request(absolute_url, headers=headers)
with urllib.request.urlopen(img_req) as img_response, open(filename, "wb") as f:
f.write(img_response.read())
print(f"\n下载完成!共 {len(img_urls_relative)} 张图片已保存至 {output_folder} 文件夹。")
except Exception as e:
print(f"发生错误: {e}")
实验结果
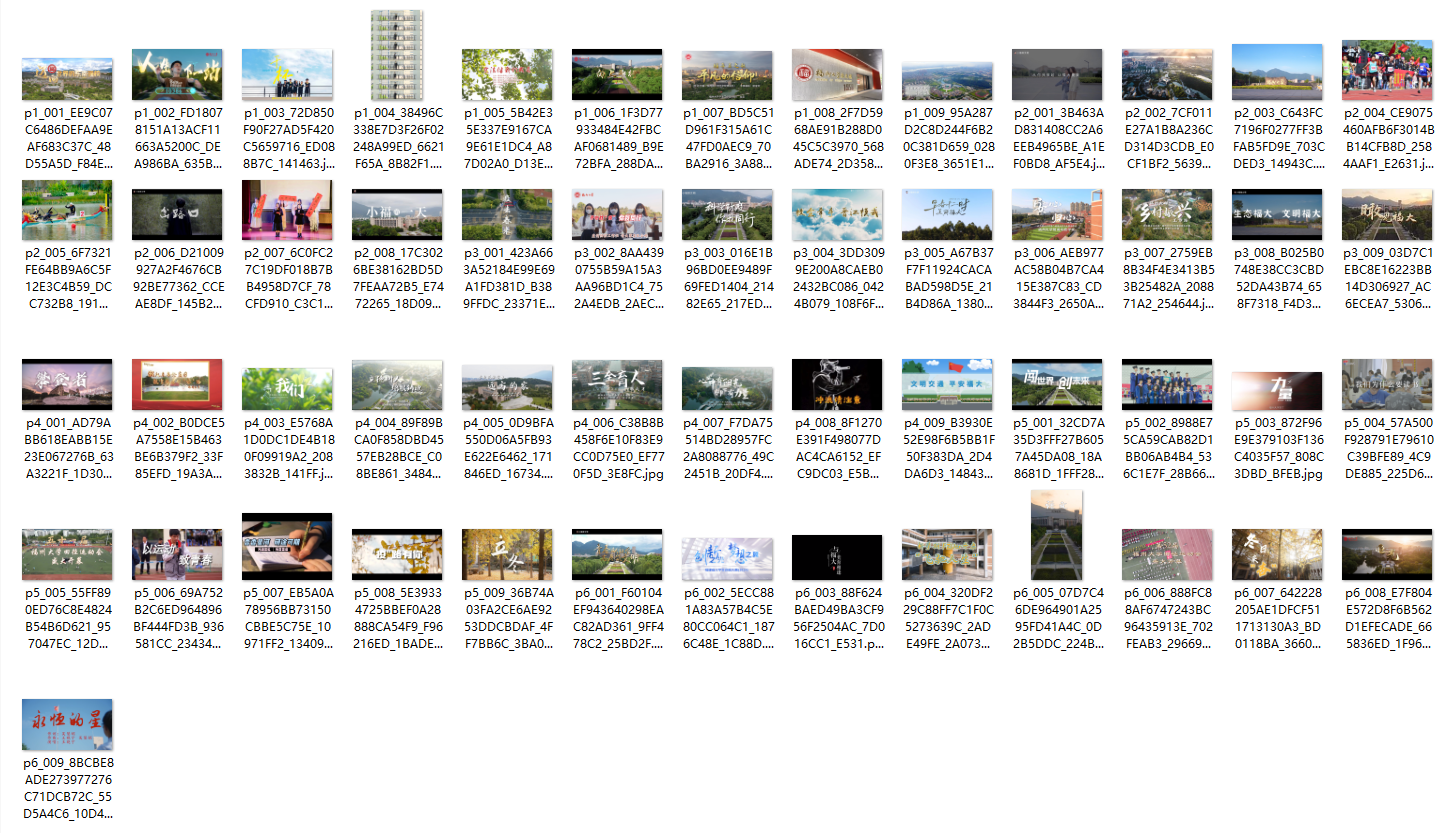
2.心得体会
在完成图片下载任务时,我遇到了HTTP 403 Forbidden错误.解决办法是在下载图片的请求头里,手动加入"Referer": "来源网页的URL",模拟是从该网页点击图片链接进行访问的。此外,我还学到了使用urllib.parse.urljoin来处理URL。网页上的图片链接可能是相对路径(如../images/a.jpg),urljoin可以安全地将这些相对路径和页面本身的URL拼接成一个完整的绝对URL,代码健壮性更强。此外,有些同学把gif也爬进来了,其实在正则化查找时就可以过滤掉。
代码地址:https://gitee.com/changqianqi/2025_crawl-project/tree/master/1

 浙公网安备 33010602011771号
浙公网安备 33010602011771号