Python爬取爱彼迎订房者评论信息
一、主题式网络爬虫设计方案(15分)
1.主题式网络爬虫名称
名称:爬取爱彼迎订房者评论信息
2.主题式网络爬虫爬取的内容与数据特征分析
本次爬虫主要爬取爱彼迎订房者相关信息
3.主题式网络爬虫设计方案概述(包括实现思路与技术难点)
本次设计方案主要使用request库和beautifulSoup库对网站访问,最后以”TXT“格式将数据保存在本地。
技术难点主要包括对爱彼迎页面的分析和采集。
二、主题页面的结构特征分析(15分)
例:airbnb.cn/users/show/85276582

可以分析一下页面。F12打开控制台调试,
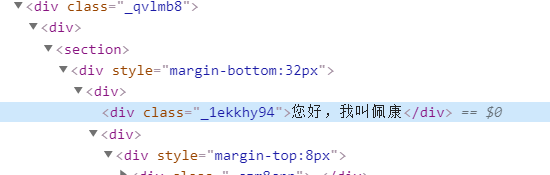
class = "_1ekkhy94" 对应的div容器有用户名
以此类推可以找到其他关键点
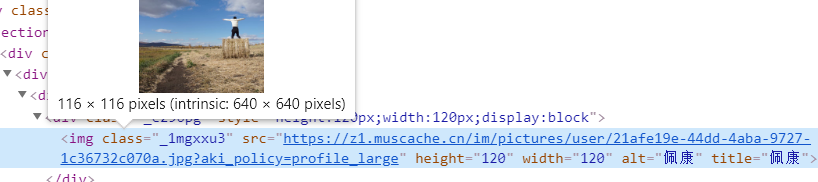
还可以通过用户头像这里(class="_1mgxxu3"),不仅可以获得头像图片的文件地址(src),也可以在这里获得用户名称(title/alt)
三、网络爬虫程序设计(60分)
爬虫程序主体要包括以下各部分,要附源代码及较详细注释,并在每部分程序后面提供输出结果的截图。
读取网页:

直接使用request库访问页面,获取网页数据
分析数据:
用beautifulSoup库分析html页面寻找之前找到的class点,获取我需要的信息

保存数据:
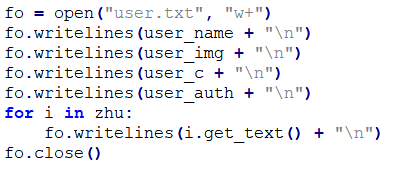
首先创建一个user.txt文件用于存储,代码作用为:
打开文件流,循环写入用户名称、用户头像文件地址、用户评论数、用户实名状态等,最后关闭文件流保存数据
完整程序代码:
1 import requests
2 from bs4 import BeautifulSoup
3
4 def getinfo(url):
5 try:
6 r = requests.get(url)
7 r.raise_for_status()
8 return r.text
9 except:
10 return "error"
11
12
13 def userinfo(html):
14 soup = BeautifulSoup(html, "html.parser")
15 title = soup.select("img._1mgxxu3")
16 user_name = title[0].get('title')
17 print("user:" + user_name)
18 user_img = title[0].get('src')
19 print("avatar:" + user_img)
20 reg_time = soup.select("div._11dqbld7")
21 user_c = reg_time[0].get_text()
22 print("talk:" + user_c)
23 user_auth = reg_time[1].get_text()
24 print("auth:" + user_auth)
25 zhu = soup.select("span._1nmdbudj")
26 for i in zhu:
27 print(i.get_text())
28 #保存数据
29 fo = open("user.txt", "w+")
30 fo.writelines(user_name + "\n")
31 fo.writelines(user_img + "\n")
32 fo.writelines(user_c + "\n")
33 fo.writelines(user_auth + "\n")
34 for i in zhu:
35 fo.writelines(i.get_text() + "\n")
36 fo.close()
37
38
39
40 # def main():
41 html = getinfo("https://www.airbnb.cn/users/show/85276582")
42 userinfo(html)
运行结果:
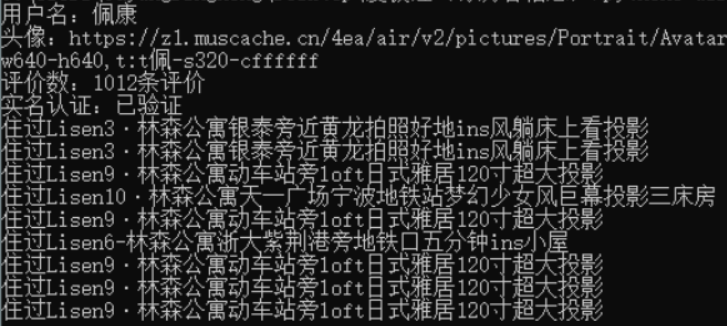
保存的数据文件:

四、结论(10分)
1.经过对主题数据的分析与可视化,可以得到哪些结论?
通过python可以快速获取自己想要的数据并保存在本地,可以节省很多工作量,提高效率。
2.对本次程序设计任务完成的情况做一个简单的小结。
通过这次任务,学会使用python获取自己需要的数据并且保存下来,很方便。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号