gRPC in ASP.NET Core 3.0 -- Protocol Buffer(1)
现如今微服务很流行,而微服务很有可能是使用不同语言进行构建的。而微服务之间通常需要相互通信,所以微服务之间必须在以下几个方面达成共识:
- 需要使用某种API
- 数据格式
- 错误的模式
- 负载均衡
- 。。。
现在最流行的一种API风格可能是REST,它主要是通过HTTP协议来传输JSON数据。
但是现在我们可以看看gRPC(https://grpc.io/),它来自Google,并且支持众多主流的语言包括Go,Dart,C#,C/C++,Nodejs,Python等等。
下面就学习一下gRPC。
gRPC能解决哪些问题?
构建(Web)API是挺麻烦的,因为构建API时我们得考虑:
- 数据的格式是JSON、XML还是二进制的;
- 端点地址以及GET还是POST等;
- 如何调用API以及对异常的处理规则;
- API的效率:一次调用读取多少数据?是否太多了或太少了?太少的话可能会导致多次API的调用;
- 延迟;
- 扩展性,是否能支持成上千个客户端
- 负载均衡
- 与其他语言的互操作性
- 如何处理身份认证、监控、日志等等
以上这些问题据说gRPC都能解决。。😱
再次介绍一下gRPC
之前说了gRPC来自Google,它是一个开源的框架;它同时也是Cloud Native Computation基金会(CNCF)的一部分,就像Docker和Kubernetes一样。
gRPC允许你为RPC(Remote Procedure Call)定义请求和响应,然后gRPC会帮你处理一切剩余问题。
它速度快,执行效率高,基于HTTP/2构建,低延迟,支持流,与开发语言无关,并且可以很简单的插入身份认证、负载均衡、日志和监控等功能。
RPC是啥
RPC是(Remote Procedure Call)远程过程调用。
在客户端代码使用RPC调用的时候,就像直接调用了服务端的一个函数一样。
例如在服务器端代码是这样的:
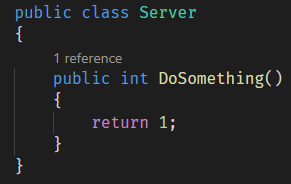
而在“遥远”的客户端它是这样调用服务器端的逻辑的,就像调用本地方法一样:
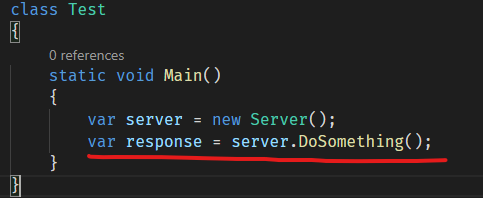
而实际上客户端在调用这个方法的时候,是要走网络通信的。
RPC它不是一个新的概念,很早它就出现了。但是它存在很多的问题。而gRPC它是对RPC一种非常简洁的实现并且解决了很多RPC的问题。

如何学习gRPC?
首先,你得学习Protocol Buffers(https://developers.google.com/protocol-buffers/),简单的说,它可以用来定义消息和服务。
然后,你只需要实现服务即可,剩余的gRPC代码将会自动为你生成。
.proto这个文件可以适用于十几种开发语言(包括服务端和客户端),并且它允许你使用同一个框架来支持每秒百万级以上的RPC调用。
gPRC使用的是合约优先的API开发模式,它默认使用Protocol buffers (protobuf) 作为接口设计语言(IDL),这个.proto文件包括两部分:
- gRPC服务的定义
- 服务端和客户端之间传递的消息
看一个官网的例子(protobuf):
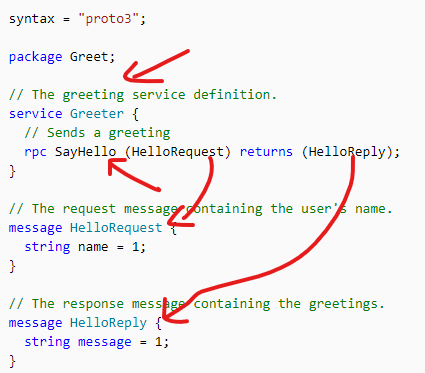
在这里定义了一个Greeter服务,它里面定义了一个SayHello的rpc调用。SayHello会发送HelloRequest这个消息,接收HelloReply这个消息。
为什么使用Protocol Buffers?
因为:
- 它和开发语言无关
- 可以生成所有主流开发语言的代码
- 数据是二进制格式的,串行化的效率高,Payload比较小
- 也很适合传递大量的数据
- 通过设定某些规则,是的API的进化也很简单
Protocol Buffer
开发环境:
- IDE: VSCode
- VSCode的扩展插件:vscode-proto3和Clang-Format这两个扩展
- Windows还需要安装Clang,Windows 64位系统的地址如下:Clang for Windows (64-bit);Mac:
brew install clang-format。
第一个例子
选个文件夹,建立一个名叫first.proto的文件:
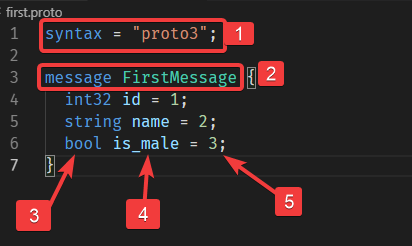
1. 这行代码表示我们使用的是语法是proto3,之前还有一个proto2;如果你不写这一行,那么protocol buffer编译器会认为你采用的是proto2。这个必须是文件的第一个非空非注释行。
2. 这里是定义了一个消息名称为FirstMessage,类型是message。它里面定义了三个字段,它们都是标量类型(Scalar Type),你也可以定义复合类型,这个以后再说。
3. 是指字段(Field)的类型
4. 字段的名称
5. 字段的数值(也叫Tag),这个数字是唯一的。它们是用来在信息格式里识别你的字段的,一旦该类型被使用了,那么这个数字就不要再改变了。
标量类型
数值型
数值型有很多种形式:double, float, int32, int64, uint32, uint64, sint32, sint64, fixed32, fixed64, sfixed32, sfixed64。
根据需要选择对应的数值类型。
布尔型
bool型可以有True和False两个值。
字符串
string表示任意长度的文本,但是它必须包含的是UTF-8编码或7位ASCII的文本,长度不可超过232。
字节型
bytes可表示任意的byte数组序列,但是长度也不可以超过232 ,最后是由你来决定如何解释这些bytes。例如你可以使用这个类型来表示一个图片。
做个例子
可以自己做一个例子,需求是这样的:这个信息表示的是一个人Person,使用proto3语法,字段如下:ID,姓名,身高,体重,头像,电子邮件,邮件是否已验证。
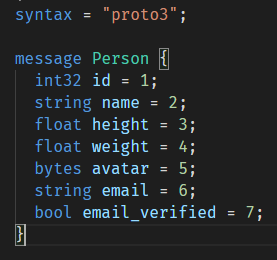
这个应该没有什么难度,不过要注意一下别忘记标点符号。
字段的数值(Tag)
在Protocol Buffers里面,字段的名其实没那么重要,但是写C#代码的时候,字段名还是很重要的。
对于protobuf来说,这个tag是更为重要的。
可以使用的最小的tag数值是1,最大值是229 - 1, 或者 536,870,911。但是你不可以使用19000到19999之间的数,这部分数是保留的。
还有一点值得注意的是:
从1到15的Tag数只占用1个字节的空间,所以它们应该被用在频繁使用的字段上。而从16到2047,则占用两个字节,它们可以用在不频繁使用的字段上。
字段规则
protobuf的字段必须满足以下两个规则之一:
单数字段(Singular)
大概意思就是指这个字段只能出现0或1次(不能超过一次),这也是proto3的默认字段规则。
重复字段(Repeated)
与singular相对的就是repeated。如果你想做一个list或数组的话,你可以使用重复字段这个概念。这个list可以有任何数量(包括0)的元素。它里面的值的顺序将会得到保留。
Repeated Fields 例子
还是使用前面的Person这个例子,我们在里面添加一个repeated字段(电话号码):
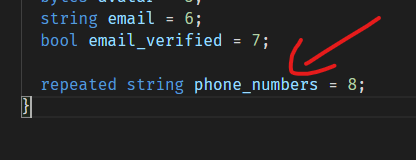
就是在前面加上repeated这个关键字即可。
在proto3里面,标量类型的repeated字段采用的是packed编码。
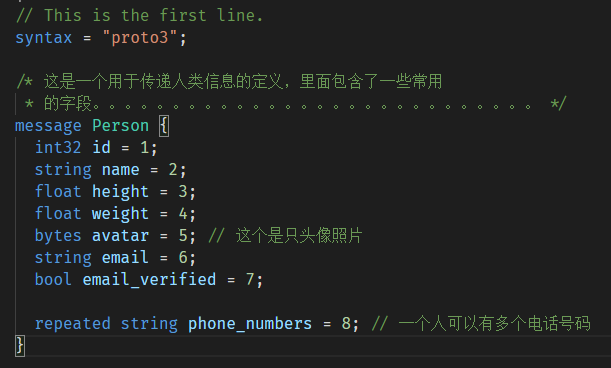
注释
proto文件里可以添加注释。它们通常被当作你定义的这些消息的文档。
注释很简单,还是两种形式,直接看代码就明白了:
保留的字段
如果你对你定义的消息类型进行了更新,例如删除某个字段或者注释掉某个字段,那么其它开发者在以后更新这个消息类型的时候可能会重新使用被你删除/注释掉的字段的数值(tag)。如果以后还需要使用这个消息类型的老版本的proto文件,那么这将会引起严重的问题,例如数据损坏、隐私漏洞等等。
那么一种避免此类事情发生的解决办法就是将你删除/注释掉的这些字段的数值(或/并且包括字段名,因为字段名可引起JSON序列化的问题)标记为reserved,如果其他人再使用这个数值作为字段标识符,那么编译器就会有错误提示:
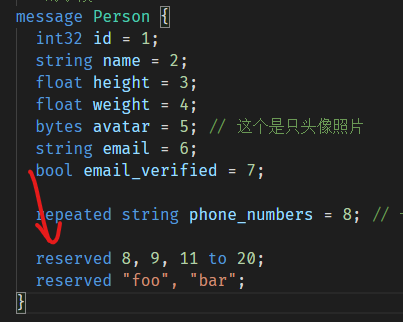
注意,不可以把reserved数值和字段名放在同一个reserved语句里。
字段的默认值
当消息被解析的时候,如果编码的消息里不含有特定的一个singular元素,那么在被解析对象里相应的字段就会被设为默认值。
常用类型的默认值如下:
- string:空字符串
- bytes:空的byte数组
- bool:false
- 数值型:0
- 枚举enum:枚举里定义的第一个枚举值,值必须是0
- repeated:通常是相应开发语言里的空list
- 还有个消息类型的字段,它的默认值和开发语言有关,这个以后再说。
枚举
之前说了,枚举里面定义的第一个值就是这个枚举的默认值。
Enum的tag必须从0开始,所以0就是枚举的数值默认值。
继续上个例子
我们对Person添加一个枚举类型的字段:性别 Gender:
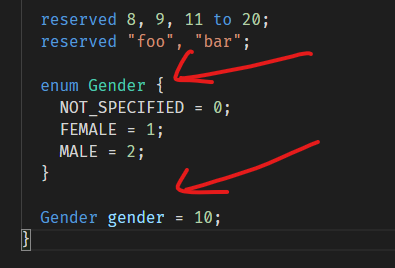
首先需要定义枚举类型,这里定义了一个枚举,名称是Gender,里面有3个值,默认值是NOT_SPECIFIED,数值默认值就是0。
然后使用这个枚举类型定义了一个字段,名称为gender,tag数为10。
为枚举值起别名
枚举值是可以起别名的,起别名的作用就是允许两个枚举值拥有同一个数值。
要想起别名,首先需要设置allow_alias这个option为true:
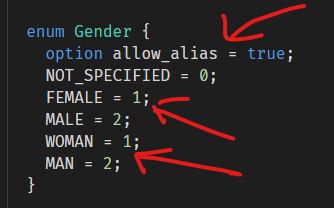
然后我们为FEMALE这个枚举值起了一个别名叫做WOMAN,它们的数值是一样的。同样的MAN是MALE的数值也是一样的。
枚举里面的常量的值必须不能超过32位整型的数值,不建议使用负数。
枚举可以定义在message里面,也可以在外边单独定义以便复用。如果另一个消息想使用Person里面这个Gender枚举,那么可以使用Person.Gender这种形式。
针对枚举值被删除/注释掉这种情况,它也可以使用reserved:
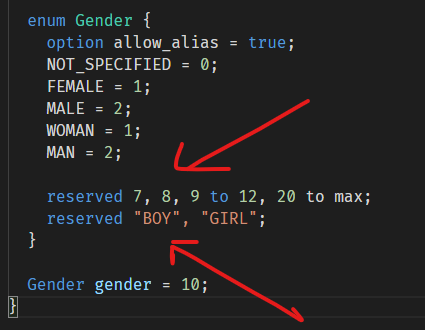
数值和常量名也必须分开使用两个reserved语句。
其中max表示可能的最大的值。
使用其它的信息类型
可以使用其它的信息类型作为字段的类型。
我们可以在同一个proto文件里定义多个信息类型(为了截图方便,我去掉了Person的一些字段):
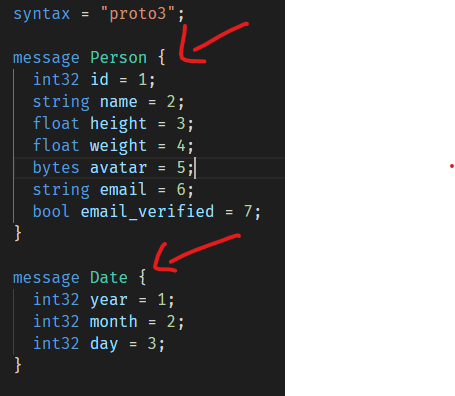
在这个文件里,除了Person信息类型外,我还定义了Date信息类型。
所以,我可以在Person里面使用Date作为它的字段类型:

引入定义
如果想要使用的信息类型已经在其它的proto文件定义好了呢?这个时候就需要引入信息类型的定义。
现在我把Date定义移动到了date.proto这个文件里面:
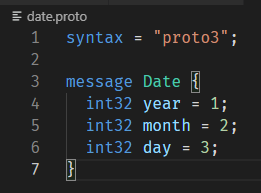
然后在person.proto里面我们可以引用date.proto:

嵌套类型
Protocol Buffer允许在信息类型里面定义其它的信息类型。
直接看例子:
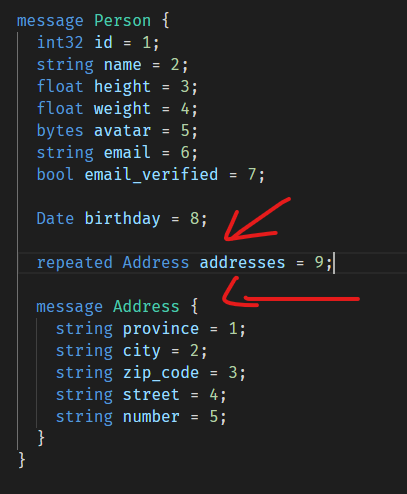
如果想在Person外边使用Address这个类型,那么就需要这样用:Person.Address。
打包
你可以向proto文件添加可选的打包(package)说明符,以避免消息类型间的名称冲突。
所以说打包是很必要的。
打包之后生成的C#代码就会使用命名空间来对应proto里面的package,但是命名方式会改为Pascal Case(每个单词首字母大写)。
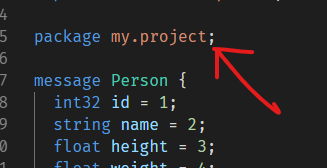
上面的代码在C#里面的情况就是:Person类在My.Project这个命名空间下。
但是如果你在proto文件里设置了option csharp_namespace这个选项,那么在C#里的命名空间就是该选项指定的命名空间了:
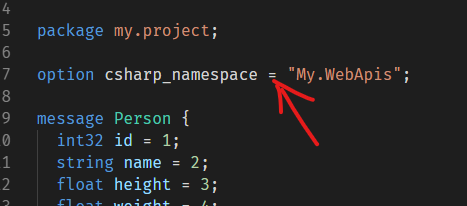
这时候,C#里面Perosn类的命名空间就是My.WebApis了,但是在proto文件里它的包还是my.project。
设置Protocol Buffers编译器
protoc编译器主要就是用来生成代码的,它的下载地址目前是:https://github.com/protocolbuffers/protobuf/releases/
在里面选择你使用的操作系统的版本: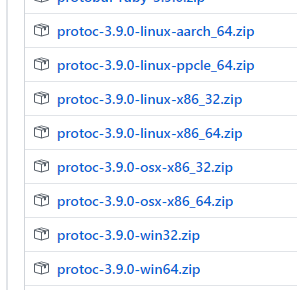
下载后解压缩到某个路径,然后把解压目录下的bin目录添加到系统的环境变量里。
然后打开命令行,输入protoc,如果有类似下面的东西出现,说明安装成功了:
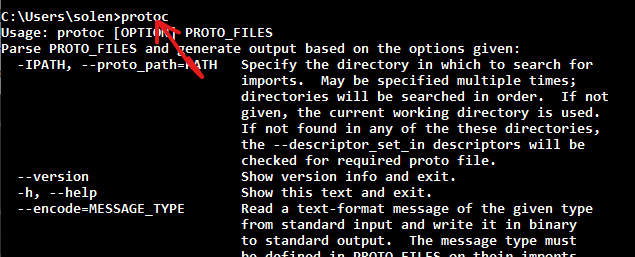
这里面的--proto_path=PATH这个参数比较常用,它用来指定到哪个文件见来查找引入。
再有就这个参数很常用:
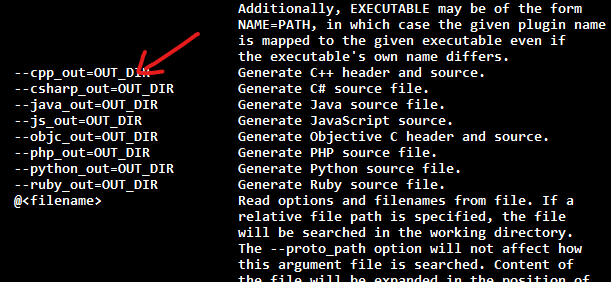
--csharp_out=OUT_DIR用来指定存放生成的C#代码的目录。
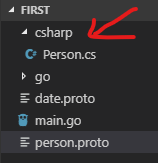
我们先试验一下,生成Person的C#代码:

执行成功后就没有任何提示,打开csharp目录,可以看到Person.cs这个文件:
而Person.cs文件里面的代码就比较多了:
千万不要去修改这个文件!
第一篇文章先到这。


 浙公网安备 33010602011771号
浙公网安备 33010602011771号