零拷贝
转自: https://www.pdai.tech/md/interview/x-interview.html#43-%E9%9B%B6%E6%8B%B7%E8%B4%9D
传统IO 存在什么问题? 为什么引入零拷贝?
如果服务端要提供文件传输的功能,我们能想到的最简单的方式是:将磁盘上的文件读取出来,然后通过网络协议发送给客户端。
传统 I/O 的工作方式是,数据读取和写入是从用户空间到内核空间来回复制,而内核空间的数据是通过操作系统层面的 I/O 接口从磁盘读取或写入。
代码通常如下,一般会需要两个系统调用:
read(file, tmp_buf, len);
write(socket, tmp_buf, len);
代码很简单,虽然就两行代码,但是这里面发生了不少的事情:
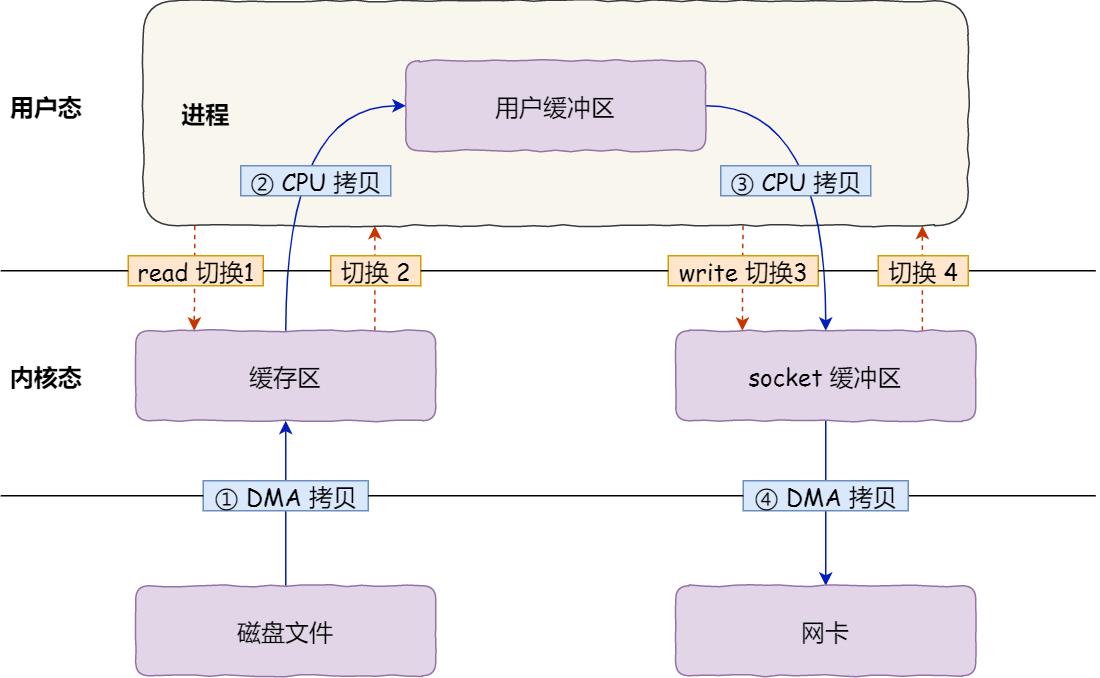
上下文切换的成本并不小,一次切换需要耗时几十纳秒到几微秒,虽然时间看上去很短,但是在高并发的场景下,这类时间容易被累积和放大,从而影响系统的性能。
其次,还发生了 4 次数据拷贝,其中两次是 DMA 的拷贝,另外两次则是通过 CPU 拷贝的,下面说一下这个过程:
第一次拷贝: 把磁盘上的数据拷贝到操作系统内核的缓冲区里, 这个拷贝的过程是通过 DMA 搬运的。
第二次拷贝: 把内核缓冲区的数据拷贝到用户的缓冲区里, 于是我们应用程序就可以使用这部分数据了,这个拷贝过程是由CPU完成的。
第三次拷贝: 把刚才拷贝到用户的缓冲区里面的数据,在拷贝到内核的 socket 的缓冲区里, 这个过程依然还是由 CPU 搬运的。
第四次拷贝: 把内核的 socket 缓冲区里的数据, 拷贝到网卡的缓冲区里, 这个过程是由DMA 搬运的。
我们回过头看这个文件传输的过程,我们只是搬运一份数据,结果却搬运了 4 次,过多的数据拷贝无疑会消耗 CPU 资源,大大降低了系统性能。
这种简单又传统的文件传输方式,存在冗余的上文切换和数据拷贝,在高并发系统里是非常糟糕的,多了很多不必要的开销,会严重影响系统性能。
所以,要想提高文件传输的性能,就需要减少「用户态与内核态的上下文切换」和「内存拷贝」的次数。
mmap + write 怎么实现的零拷贝?
在前面我们知道,read() 系统调用的过程中会把内核缓冲区的数据拷贝到用户的缓冲区里,于是为了减少这一步开销,我们可以用 mmap() 替换 read() 系统调用函数。
buf = mmap(file, len);
write(sockfd, buf, len);
mmap() 系统调用函数会直接把内核缓冲区里的数据「映射」到用户空间,这样,操作系统内核与用户空间就不需要再进行任何的数据拷贝操作。
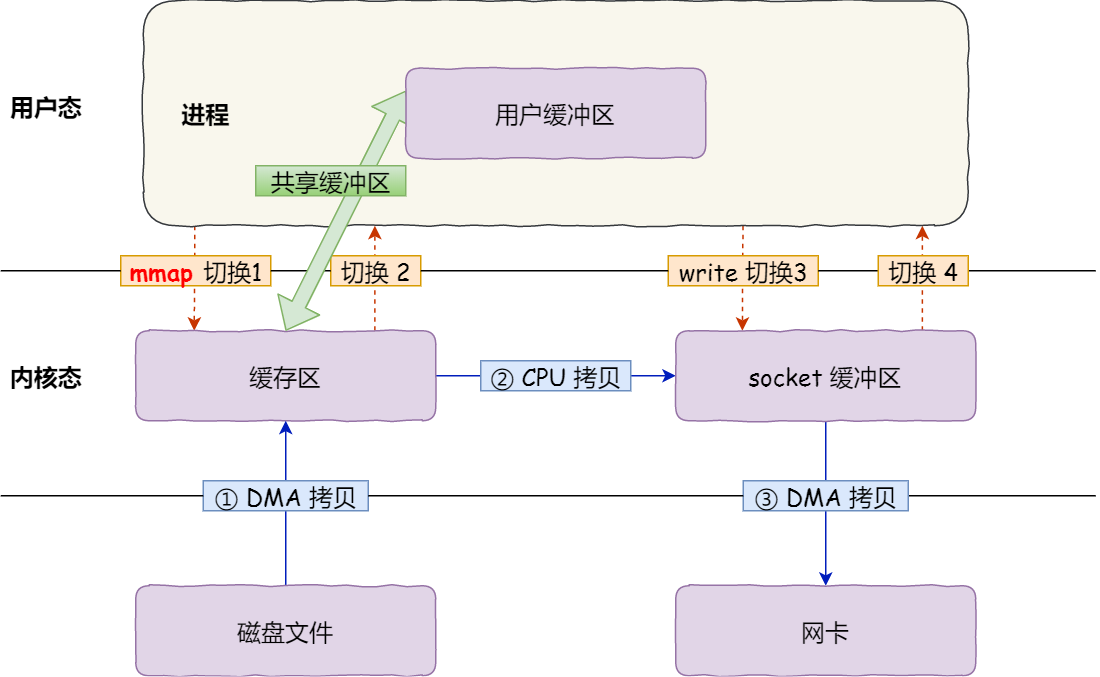
具体过程如下:
1、 应用进程调用了 mmap() 后, DMA 会把磁盘的数据拷贝到内核的缓冲区里。 接着, 应用进程跟操作系统内核「共享」这个缓冲区;
2、应用进程再调用 write(),操作系统直接将内核缓冲区的数据拷贝到 socket 缓冲区中,这一切都发生在内核态,由 CPU 来搬运数据
3、最后,把内核的 socket 缓冲区里的数据,拷贝到网卡的缓冲区里,这个过程是由 DMA 搬运的。
我们可以得知,通过使用 mmap() 来代替 read(), 可以减少一次数据拷贝的过程。
但这还不是最理想的零拷贝,因为仍然需要通过 CPU 把内核缓冲区的数据拷贝到 socket 缓冲区里,而且仍然需要 4 次上下文切换,因为系统调用还是 2 次
sendfile 怎么实现的零拷贝?
在 Linux 内核版本 2.1 中,提供了一个专门发送文件的系统调用函数 sendfile(),函数形式如下:
#include <sys/socket.h> ssize_t sendfile(int out_fd, int in_fd, off_t *offset, size_t count);
它的前两个参数分别是目的端和源端的文件描述符,后面两个参数是源端的偏移量和复制数据的长度,返回值是实际复制数据的长度.
首先,它可以替代前面的 read() 和 write() 这两个系统调用,这样就可以减少一次系统调用,也就减少了 2 次上下文切换的开销。
其次,该系统调用,可以直接把内核缓冲区里的数据拷贝到 socket 缓冲区里,不再拷贝到用户态,这样就只有 2 次上下文切换,和 3 次数据拷贝。如下图:

$ ethtool -k eht0 | grep scatter-gather scatter-gather: on
于是,从 Linux 内核 2.4 版本开始起,对于支持网卡支持 SG-DMA 技术的情况下, sendfile() 系统调用的过程发生了点变化,具体过程如下:
第一步: 通过DMA 将磁盘上的数据拷贝到内核缓冲区里;
第二步: 缓冲区描述符和数据长度传到 socket 缓冲区, 这样网卡的 SG-DMA 控制器就可以直接将内核缓存中的数据拷贝到网卡的缓冲区里, 此过程不需要将数据从操作系统内核缓冲区拷贝到 socket 缓冲区中, 这样就减少了一次数据拷贝;
所以,在这个过程中,只进行了2次数据拷贝: 如下图:
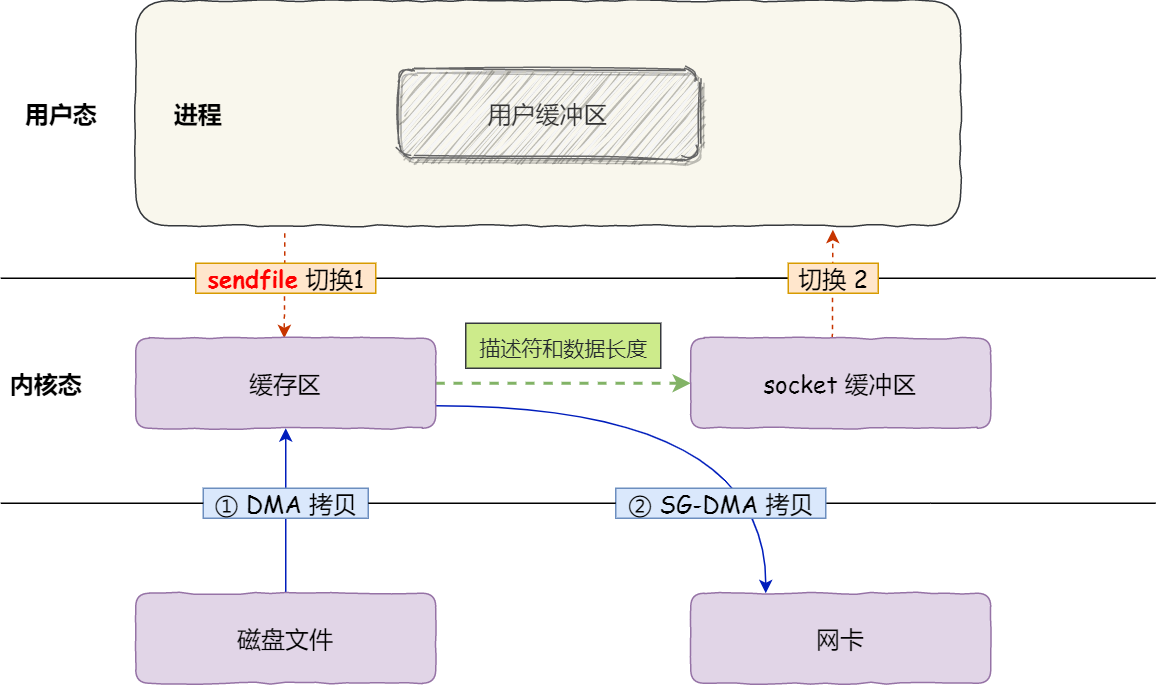
这就是所谓的零拷贝(Zero-copy)技术,因为我们没有在内存层面去拷贝数据,也就是说全程没有通过 CPU 来搬运数据,所有的数据都是通过 DMA 来进行传输的。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号