不平衡数据分类
不平衡数据分类问题
不平衡数据分类问题是机器学习领域内一个重要的研究课题,引起国内外学者的厂 泛关注。不平衡数据普遍存在干现实生活中,例如:基内表达数据、信用卡交易数据和医学数据等。现有分类器及其学习算法在解决不平衡数据分类问题时,由于只关注整体识别率而往往忽视少数类的识别率。如何改善类间样本的不平衡,增加少数类的识别率 同时兼顾多数类的准确度,是亟需解决的一个问题。
类别间样本不平衡有两种情形:一种是指大类样本的实际数量远大于小类样本的数量,即样本数不平衡:另一种是指两类样本数量相同,但大类样本的分布比较密集,即分布区域不平衡
针对于不平衡学习问题,国内外学者开展了大量研究工作,取得了很好的效果。目 前,这个领域内的研究主要集中在三个方面的改进:数据集、算法和评价标准。在数据集方面,主要是对教据预处理以改善数据集中各类样本之间数目的不平衡,比如:增加小类样本数,减少大类样本数等方法,从而消除各类之间样本数自不平衡对传统分类器性能的影响。在算法层面,研究不平衡数据集对原算法本身参数和结构的影响,通过修改经典算法或者设计新的算法使之更适应不平衡数据集的学习。在评价标准方面,针对目前以整体准确率为评价标准的分类器不适用于不平衡学习的现状,提出了一系列兼顾小类识别率的评价体系。

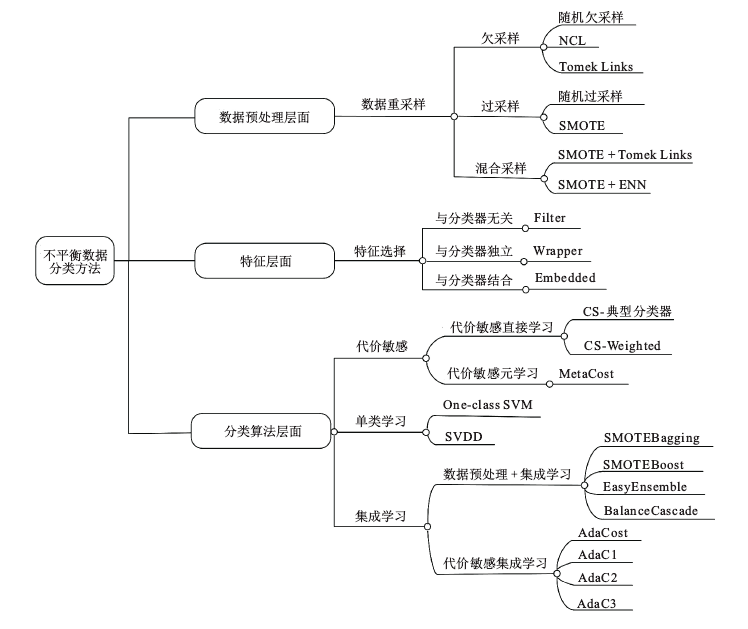
数据不平衡问题的研究另外一种划分
数据预处理层面、特征层面和分类算法层面,保证分类器对多数类和少数类的数据都具有较高的分类精度


 浙公网安备 33010602011771号
浙公网安备 33010602011771号