


SWE-bench: 自动解决 GitHub issue 能力的评估方法
SWE-bench 数据集从 12 个流行的 Python 仓库中,收集了 2294 组 [Issue, PR] 对。相比之前的各个 benchmark,要么数据泄露要么训练阶段作弊,已经没办法很好辨别顶尖模型的优劣,SWE-bench 更能反应出语言模型在真实世界的应用。
paper:SWE-bench: Can Language Models Resolve Real-World GitHub Issues?
GitHub:SWE-bench
数据集:HF
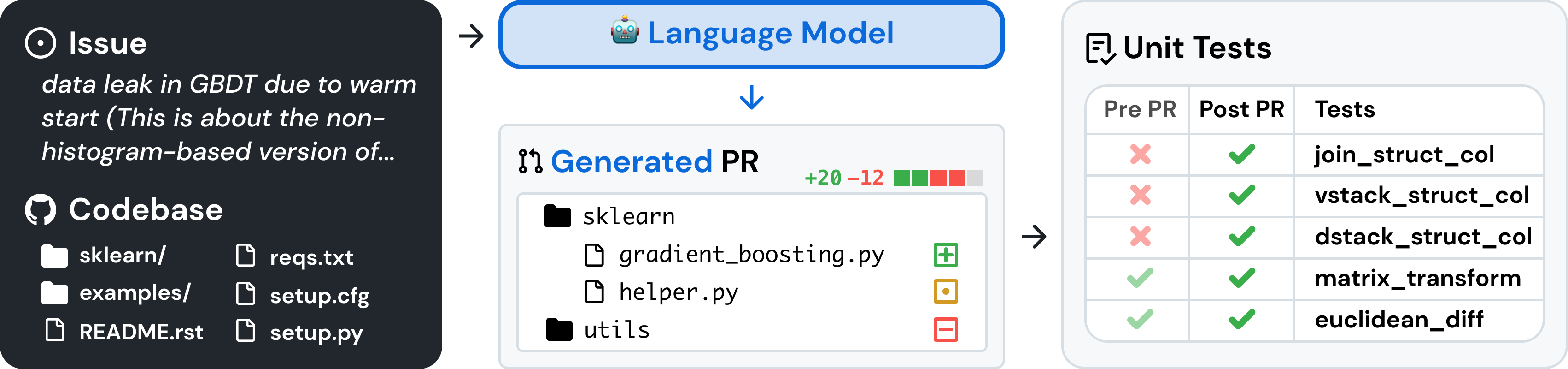
给定 codebase 和 issue,让语言模型生成对应的 patch。
评估过程
- 模型输入
任务的文本描述 + 完整的 codebase - 修改的代码以 patch(指定 codebase 中哪些行) 的形式生成
- 使用 unix 的 patch 命令将修改应用到代码库中,运行任务相关的单元测试和系统测试
- 如果 patch 执行成功、测试通过,则认为 issue 已解决

Data Instance
instance_id: (str) - A formatted instance identifier, usually as repo_owner__repo_name-PR-number.
patch: (str) - The gold patch, the patch generated by the PR (minus test-related code), that resolved the issue.
repo: (str) - The repository owner/name identifier from GitHub.
base_commit: (str) - The commit hash of the repository representing the HEAD of the repository before the solution PR is applied.
hints_text: (str) - Comments made on the issue prior to the creation of the solution PR’s first commit creation date.
created_at: (str) - The creation date of the pull request.
test_patch: (str) - A test-file patch that was contributed by the solution PR.
problem_statement: (str) - The issue title and body.
version: (str) - Installation version to use for running evaluation.
environment_setup_commit: (str) - commit hash to use for environment setup and installation.
FAIL_TO_PASS: (str) - A json list of strings that represent the set of tests resolved by the PR and tied to the issue resolution.
PASS_TO_PASS: (str) - A json list of strings that represent tests that should pass before and after the PR application.
SWE-bench Verified
openai 与 SWE-bench 作者合作开发,增加了专业软件开发人员的标注。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号